第三次作业
作业①:
要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
输出信息:
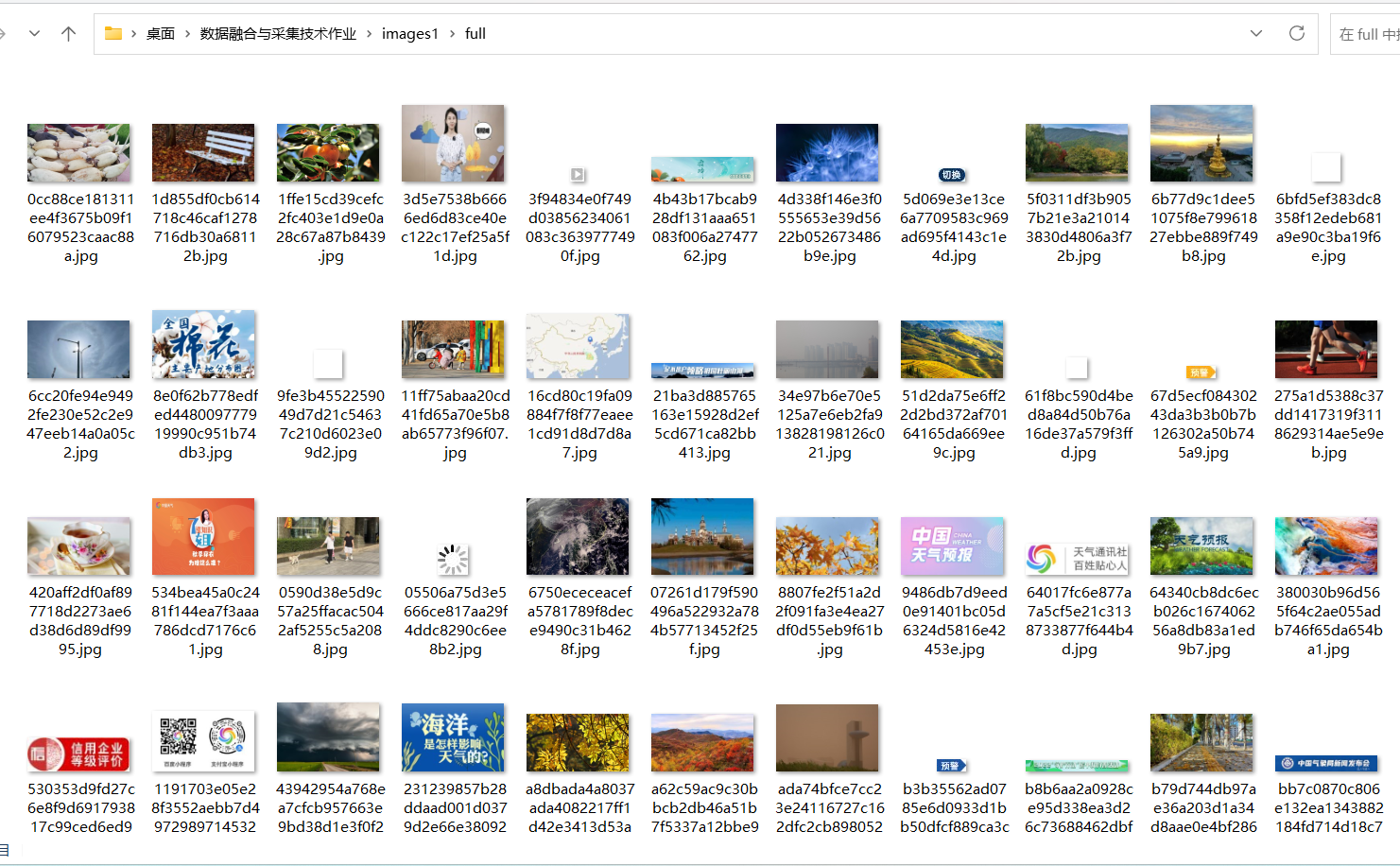
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
Weather_Spider.py的代码如下:
import scrapy
class Weather_Spider(scrapy.Spider):
name = 'Weather_Spider'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
# 提取图片URL
img_urls = response.css('img::attr(src)').extract()
for img_url in img_urls:
if img_url: # 检查URL是否为空
img_url = response.urljoin(img_url) # 转换为绝对URL
print(f"Downloading Image: {img_url}") # 输出URL信息
yield {'image_urls': [img_url]} # 生成item
在setting.py中添加代码如下,用于确定网页图片的下载路径:
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
}
IMAGES_STORE = r'C:\Users\佘培强\Desktop\数据融合与采集技术作业\images1'
在setting.py中添加CONCURRENT_REQUESTS的值可以实现多线程:
CONCURRENT_REQUESTS = 16
运行代码打印出图片的url:
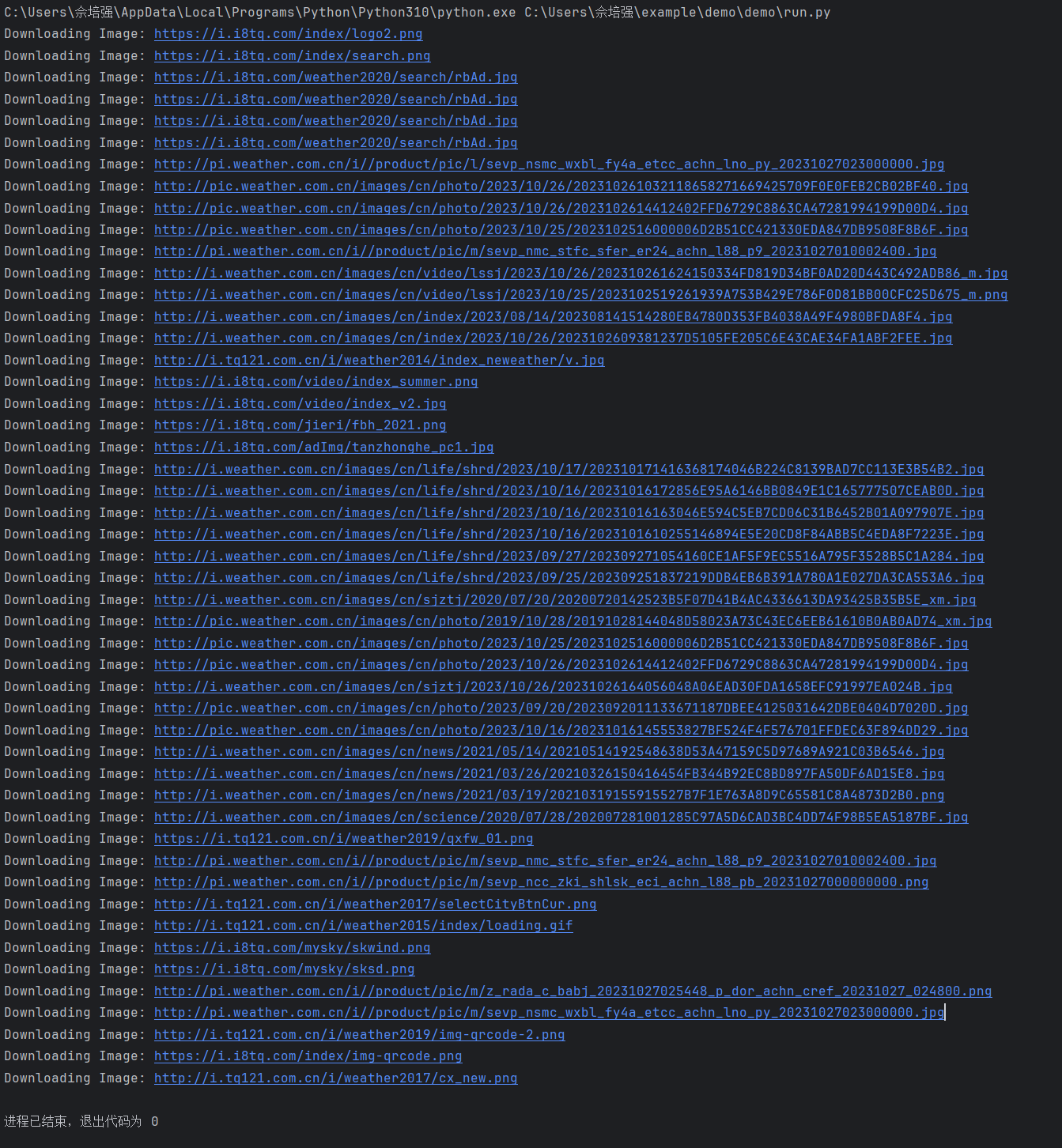
在指定的文件夹中部分图片结果如下:
心得体会:
本来不知道多线程相较于单线程而言要怎么处理,经过查阅资料后发现scrapy爬取数据设置多线程只要在setting.py中进行相应的配置即可完成,除外本题依旧是如之前一样先找到网页中图片的url,然后将其爬取出。
作业②:
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
输出信息:MySQL数据库存储和输出格式如下:
表头英文命名例如:序号id,股票代码:bStockNo……

stock_spider.py的代码如下:
import scrapy
import json
from job1.items import Job1Item
class stock_spider(scrapy.Spider):
name = 'stock_spider'
start_urls = [
'http://54.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124024635353550527928_1697698971058&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697698971059'
]
def parse(self, response):
jsonp = response.text
json_text = jsonp[jsonp.find('(') + 1: jsonp.rfind(')')]
json_data = json.loads(json_text)
for stock_info in json_data['data']['diff']:
item = Job1Item()
item['股票代码'] = stock_info['f12']
item['股票名称'] = stock_info['f14']
item['最新价'] = stock_info['f2']
item['涨跌幅'] = stock_info['f3']
item['涨跌额'] = stock_info['f4']
item['成交量'] = stock_info['f5']
item['成交额'] = stock_info['f6']
item['振幅'] = stock_info['f7']
item['最高'] = stock_info['f15']
item['最低'] = stock_info['f16']
item['今开'] = stock_info['f17']
yield item
items.py的代码如下:
import scrapy
class Job1Item(scrapy.Item):
股票代码 = scrapy.Field()
股票名称 = scrapy.Field()
最新价 = scrapy.Field()
涨跌幅 = scrapy.Field()
涨跌额 = scrapy.Field()
成交量 = scrapy.Field()
成交额 = scrapy.Field()
振幅 = scrapy.Field()
最高 = scrapy.Field()
最低 = scrapy.Field()
今开 = scrapy.Field()
Pipelines.py的代码如下(创建并且连接数据库,将爬取得到的数据传入到数据库中):
import pymysql
class MySQLPipeline:
def open_spider(self, spider):
self.conn = pymysql.connect(host='localhost', user='root', password='123456', charset='utf8')
self.cursor = self.conn.cursor()
# 创建数据库
self.cursor.execute("CREATE DATABASE IF NOT EXISTS stock_db CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;")
self.conn.commit()
# 选择数据库
self.cursor.execute("USE stock_db")
# 创建表格
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS stocks (
股票代码 VARCHAR(10),
股票名称 VARCHAR(50),
最新价 DECIMAL(10, 2),
涨跌幅 DECIMAL(5, 2),
涨跌额 DECIMAL(10, 2),
成交量 BIGINT,
成交额 BIGINT,
振幅 DECIMAL(5, 2),
最高 DECIMAL(10, 2),
最低 DECIMAL(10, 2),
今开 DECIMAL(10, 2)
) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
""")
self.conn.commit()
def close_spider(self, spider):
self.conn.commit()
self.conn.close()
def process_item(self, item, spider):
sql = 'INSERT INTO stocks (股票代码, 股票名称, 最新价, 涨跌幅, 涨跌额, 成交量, 成交额, 振幅, 最高, 最低, 今开) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)'
values = (item['股票代码'], item['股票名称'], item['最新价'], item['涨跌幅'], item['涨跌额'], item['成交量'], item['成交额'], item['振幅'], item['最高'], item['最低'], item['今开'])
self.cursor.execute(sql, values)
self.conn.commit()
return item
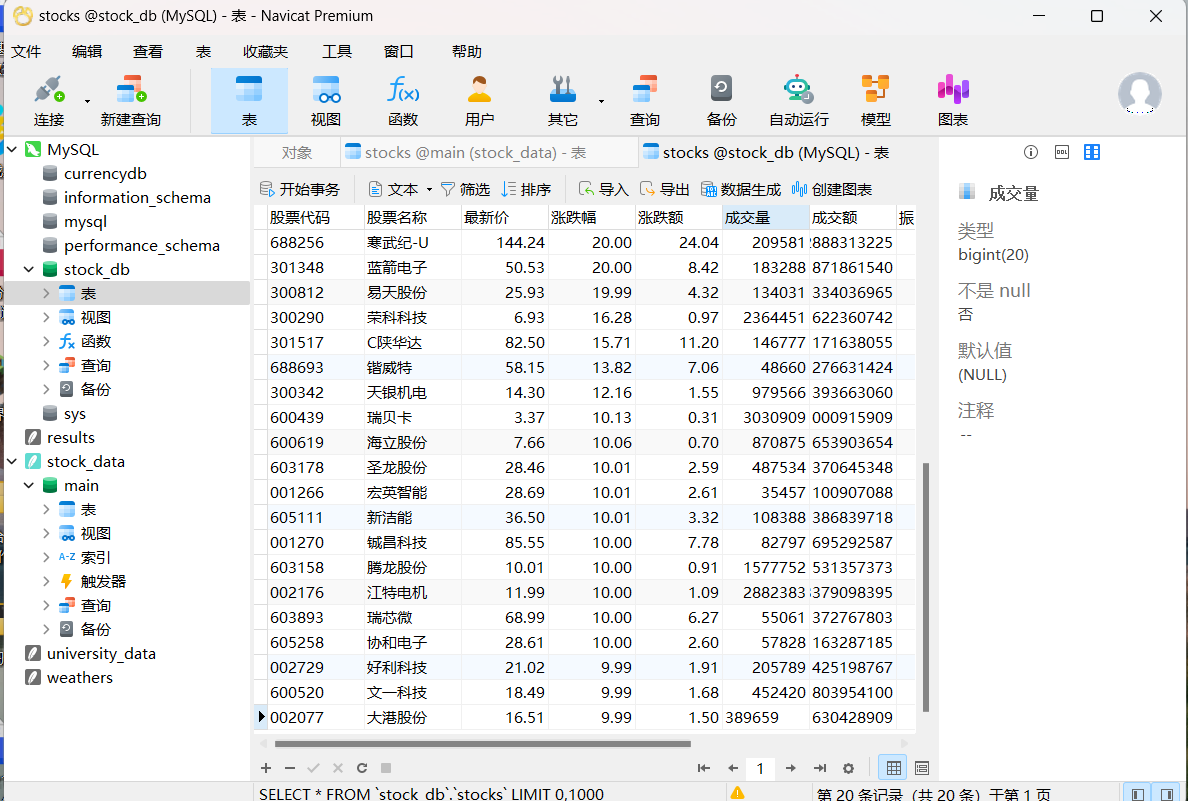
存储在数据库中的数据(采用Navicate可视化并且查看):
心得体会:
这题依旧和之前一样使用json包来处理爬取出数据,不一样的是这题采用了scrapy的方法来爬取出数据,相似的题目采取不同的做法使我对于scrapy相应的知识有了更深的体会,scrapy更需要注重各方面的配置,因此在使用scrapy时必须要检查好各项配置再执行
作业③:
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
输出信息:

bank_spider.py的代码如下所示:
import scrapy
from job2.items import Job2Item
class bank_spider(scrapy.Spider):
name = 'bank_spider'
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
rows = response.xpath('//table[@align="left"]/tr')
count=1
for row in rows[1:]:
item = Job2Item()
item['count']=count
item['currency'] = row.xpath('td[1]/text()').get()
item['tbp'] = row.xpath('td[2]/text()').get()
item['cbp'] = row.xpath('td[3]/text()').get()
item['tsp'] = row.xpath('td[4]/text()').get()
item['csp'] = row.xpath('td[5]/text()').get()
item['time'] = row.xpath('td[7]/text()').get()
count+=1
print(item)
yield item
items.py的代码如下所示:
import scrapy
class Job2Item(scrapy.Item):
count = scrapy.Field()
currency = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
time = scrapy.Field()
Pipelines.py的代码如下所示(创建并且连接数据库,并将爬取的数据传入到数据库中):
class Job2Pipeline(object):
def __init__(self):
self.conn = pymysql.connect(
host='localhost',
db='currencydb',
user='root',
password='123456',
port=3306
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
# 将Item数据插入到MySQL数据库
insert_sql = """
INSERT INTO currency_data (id, currency, tbp, cbp, tsp, csp, time)
VALUES (%s, %s, %s, %s, %s, %s, %s)
"""
values = (
item['count'],
item['currency'],
item['tbp'],
item['cbp'],
item['tsp'],
item['csp'],
item['time']
)
try:
self.cursor.execute(insert_sql, values)
self.conn.commit()
except Exception as e:
self.conn.rollback()
raise e
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
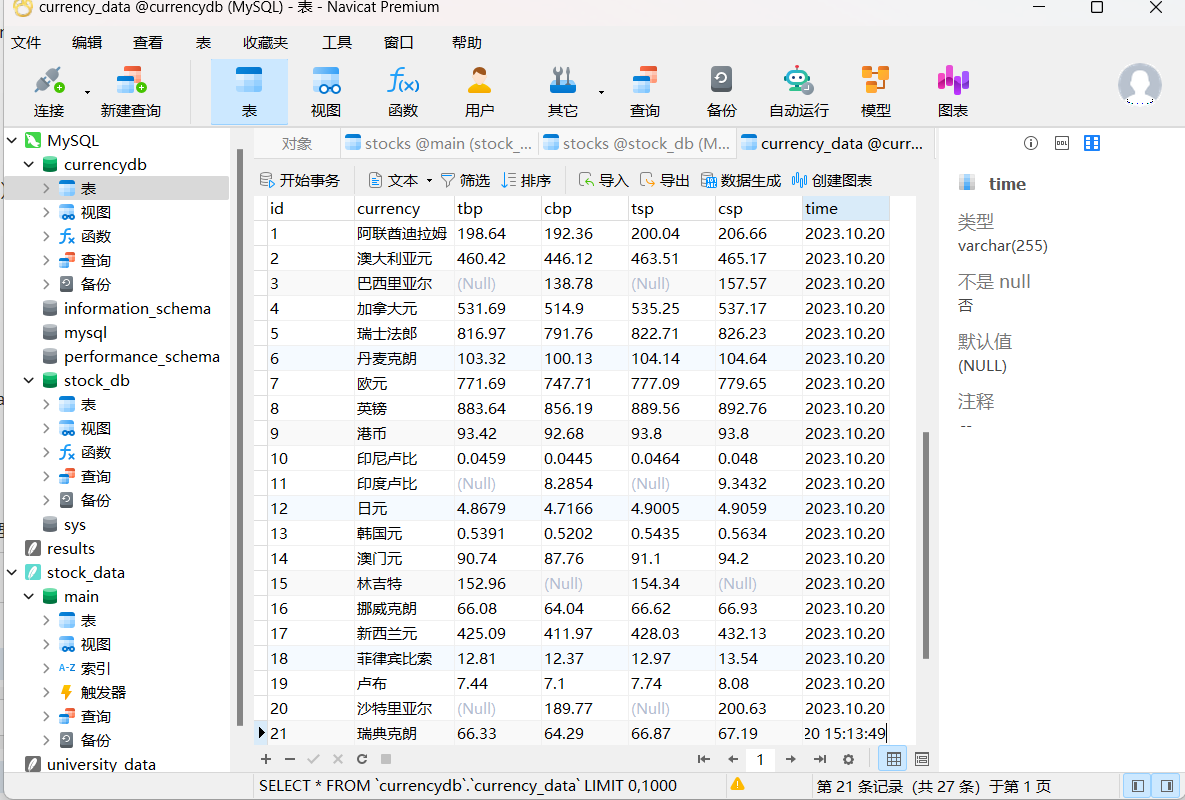
存储在数据库中的数据(采用Navicate可视化并且查看):
心得体会:
本题刚开始数据库中一直解析不了currency这一列的数据,无法将这一列的数据传入,后来在数据库中设置新的编码:utf8mb4,就可以成功解析出来结果