策略梯度呢,顾名思义,策略就是一个状态或者是action的分布,梯度就是我们的老朋友,梯度上升或者梯度下降。
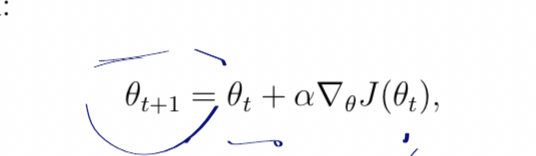

就是说,J函数的自变量是西塔,然后对J求梯度,进而去更新西塔,比如说,J西塔,是一个该策略下预测状态值,也可以说是策略值,那么我们当然希望这个策略值越大越好,于是就要使用梯度上升,来不断更新自变量,然后那个V(pai)ba,就是一个状态值的分布,你每个状态肯定都拥有一个状态值,然后他就是看看哪个状态分布的比较多
不仅可以求状态均值最值,而且还可以。。。

先看看普通的r(pai)S,这个就是某个状态下,记住,某个状态,下的奖励均值,奖励的一个分布,对所有(S,a)某个特定S对应的无数a的奖励求期望,这个是基础,先记住,OK接下来上强度


r(Π)ba,就是等于某个状态奖励预测值,乘上,状态的分布,然后就成为了一个期望值,当然,这个分布就是策略Π,就是一个权重,而权重的自变量就是θ,所以运用梯度上升或者下降更新的就是θ,然后reward期望和state期望它们是成正比的,没错,正比,而不是正相关

然后捏,接下来就是对Q(s,a),求一个期望,还是按照上面老套路,一层套一层

就求完梯度,如第一个公式所示,当然,为了简化,可以化简成第二个公式,S服从η分布,行为A服从Π分布,然后自变量就是θ
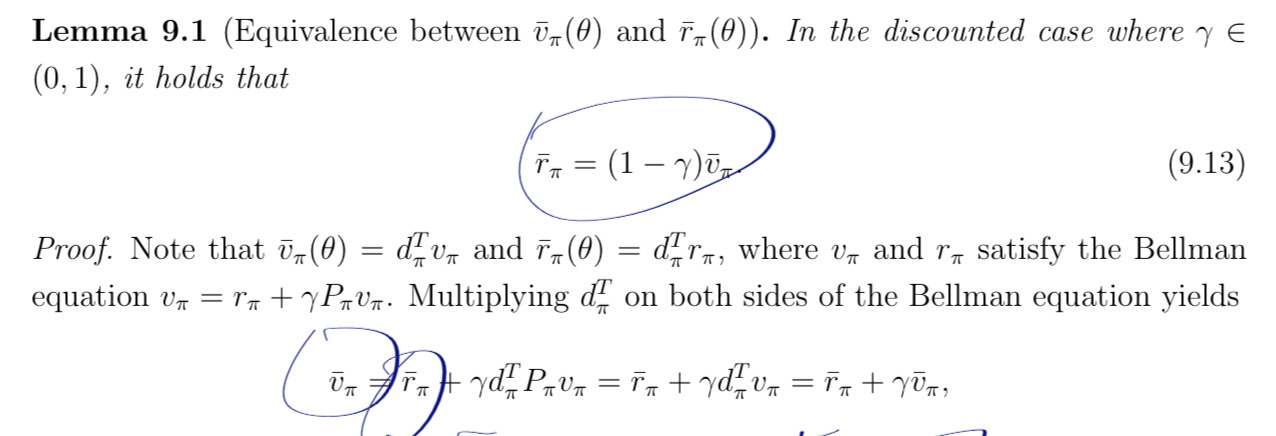
然后温故知新一下贝尔曼方程

然后其实没太搞懂为什么它要减去rba
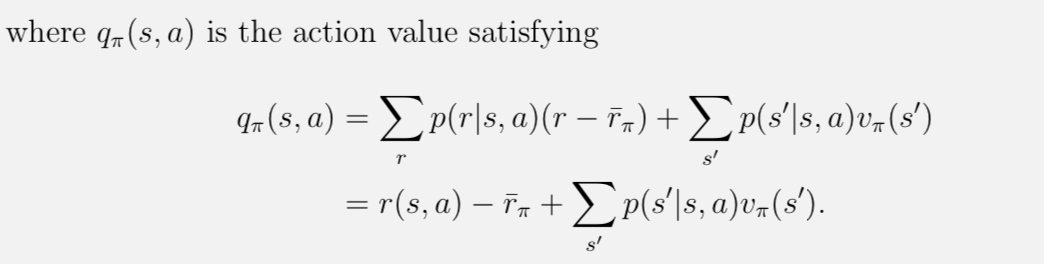
接下来,有个很重要的就是
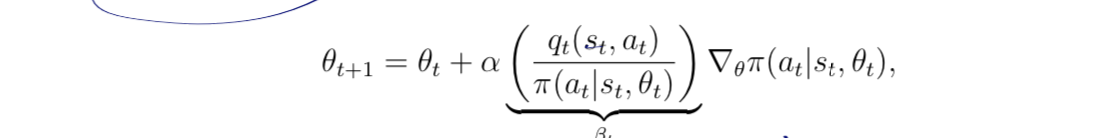
引入了一个β比值,分母就是q(s,a),q(s,a)越大,那么步长就越大,就是该策略下,这个动作的出现概率越大,,而分母就是,这个动作越稀有,步长越大,下次出现的机会越大,这样去做一个探索,然后分子分母去做一个平衡,致力于发现并发展宝藏选手,至于为什么θ更新后该策略下该动作出现概率会增加,涉及到线性代数的知识,我还没学,会尽快

就到这吧,感觉有些不会的点都是受限于数学知识的积累,那我尽量数学也学快点吧,数学好才能好好做科研啊,终于要到演员评论家了