笨叔:ARM64体系结构与编程之cache必修课(上)

第三季视频课程ARM64体系结构与编程之cache基础知识(1)
为什么系统软件人员要深入了解cache?
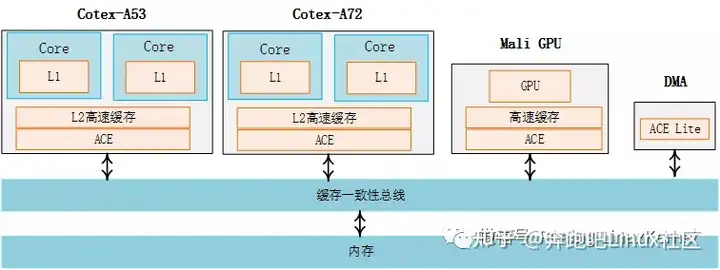
在一个系统中,cache无处不在,对于一个系统编程人员来说,你无法躲藏。下图是一个经典的ARM64系统的架构图,由Corte-A72和Cortex-53组成了大小核架构,每个CPU核心都有L1 cache,每个cluster里共享一个L2 cache,另外还有Mali GPU和DMA外设。
对于系统软件人员,下面几个常常疑惑的问题:
- cache的内部组织架构是怎么样的?能否画出一个cache的layout图?什么是set,way?
- 直接映射,全关联和组相联之间有什么区别?优缺点是啥?
- 重名问题是怎么发生的?
- 同名问题是怎么发生的?
- VIPT会不会发生重名问题?
- 什么是inner shareability 和outer shareability?怎么区分?
- 什么是PoU?什么是PoC?
- 什么是cache一致性?业界解决cache一致性都有哪些方法?
- MESI状态转换图,我看不懂。
- 什么cache伪共享?怎么发生的,如何避免?
- DMA和cache为啥会有cache一致性问题?
- 网卡通过DMA收数据和发数据,应该怎么操作cache?
- 对于self-modifying code,怎么保证data cache和指令cache的一致性问题?
所以,Cache这个玩意,对我们系统编程人员来说,非常重要。Cache没有理解好,或者没有完全搞透了,对系统编程影响很大,有时候我们在编程的时候,一行代码小小的改动可能会影响整个系统的性能,所以,我是建议系统程序员有必要把cache这玩意好好系统的学一学。
笨系列文章主要源自第三季《arm64体系结构与编程》视频课程,大概会有上下两篇:
上篇:介绍cache相关的背景知识,例如什么是cache,cache的layout结构图,cache的层级,VIPT/PIPT/VIVT,cache的重名和同名问题,cache的策略等。
下篇:主要介绍cache的一致性问题,cluster核间的一致性问题,系统间的cache一致性问题,DMA和cache之间的cache一致性问题,self-modifying code导致的I-cache和D-cache的一致性问题,cache伪共享等问题。对了,还会重点介绍如何看MESI状态转换图哟!
cache背景知识
大家应该都知道,为啥我们的CPU内部需要cache这么一个单元了,主要的原因是CPU的速度和内存的速度之间严重不匹配,Cpu快,而访问内存慢,那怎么解决这个问题,CPU设计人员就想到了缓存这么一个概念,就是在CPU和内存之间建立一个缓冲区。可能有的人要问了,建立缓冲器有啥好处,假设CPU和内存之间没有缓冲区,那么CPU每次访问内存,都要从慢速的内存中读取,如果CPU和内存之间有一个高速的缓冲区的话,虽然第一次读,都是要从内存中读取,但是第一次读完成之后,我可以把数据放到这个高速缓冲区里,那第二次读,我就直接从高速缓冲区里取数据就行,这个高速缓存区的速度基本上是和CPU匹配的,比内存速度快很多很多。这样的,cpu第2次,第3次去读这个数据的时候,就得到加速的效果了。这个也是设计cache的最初的初衷。
cache一般是集成在CPU内部的RAM,相对于外部的内存颗粒来说造价昂贵,因此一般cache是很小的RAM,但是访问速度和CPU是匹配的。还有一点,如果访问数据在cache命中的话,不仅仅能提速,提高程序的性能,还能减低功耗。有的小伙伴就蒙圈了,为啥cache命中率高,功耗就减低了呢?其实cache命中的话,说明不需要去访问外部的内存部件,当然会减低一点点功耗了。
经典的cache架构
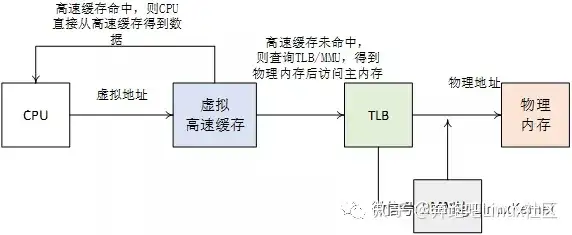
下面来介绍一下经典的cache架构图,在图的上面是CPU发出的虚拟地址。CPU在访问内存的时候,会把这个虚拟地址发送给TLB和cache。TLB是一个用于存储虚拟地址到物理地址转换的小缓存,处理器先使用EPN(effective page number,有效页帧号)在TLB中进行查找最终的RPN(Real Page Number,实际页帧号)。如果这期间发生TLB未命中(TLB Miss),将会带来一系列严重的系统惩罚,处理器需要访问MMU并且查询页表。假设这里TLB 命中(TLB Hit),此时很快获得合适的RPN,并得到相应的物理地址(Physical Address,PA)。
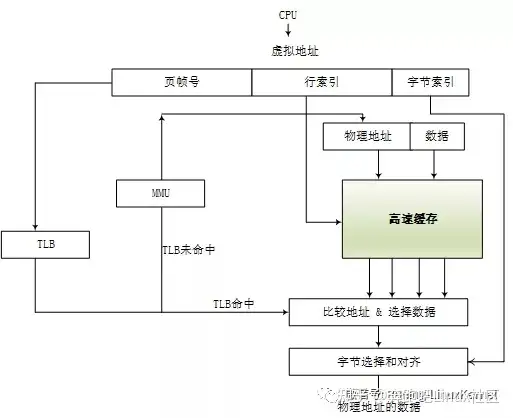
同时,处理器通过高速缓存编码地址的索引域(Index)可以很快找到相应的高速缓存行对应的组。但是这里的高速缓存行的数据不一定是处理器所需要的,因此有必要进行一些检查,将高速缓存行中存放的标记域和通过虚实地址转换得到的物理地址的标记域进行比较。如果相同并且状态位匹配,那么就会发生高速缓存命中(cache hit),处理器经过字节选择与对齐(byte select and align)部件,最终就可以获取所需要的数据。如果发生高速缓存 未命中(cache miss),处理器需要用物理地址进一步访问主存储器来获得最终数据,数据也会填充到相应的高速缓存行中。上述描述的是VIPT(Virtual Index Physical Tag)的高速缓存组织方式。这个也是经典的cache运行模式了。
Cache内部结构图
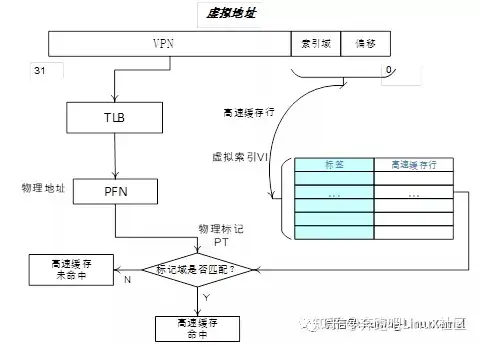
我们来看一下cache内部的架构图。首先,CPU访问cache,cache控制器会把cpu发给他的地址分成几段来看,比如这张图,地址分成了分成3个部分,分别是偏移量(offset)域、索引(index)域和标记(tag)域。
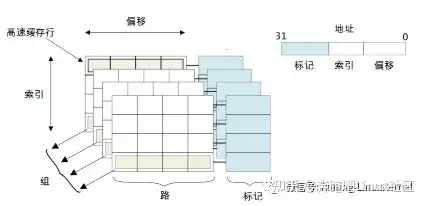
这三个域都是不同的作用的。cache的组织结构,通常现在的cache都是组相连的方式,就是cache分成了多个路(way),这里路是由英文way这个词之间翻译过来的,应该翻译成块比较合理,其实就是把cach分成了几个块。然后在每个块上,有多个cache line。一个cache的,它的cache line大小是固定的,比如32字节,64字节。那么当你知道了一个块有多大,一个cache line大小,那么你就知道一个块里,有多少个cache line了。然后地址中的索引域,就是用来索引这个块里的cache line,这个过程非常类似页表的访问过程。我们可以把 块 看成是一个 数组,数组的成员就是cache line,那么这个索引值,就是数组的下标。这样大家容易理解一些。
好,我们来看组的概念,组是英文单词set直接翻译过来的。我们刚才讲了cache分成几个大块,比如4大块,那么就有4个大小相同的数组。那么对于一个地址来说,从它的索引域可以找到 4个cache line,每个数组一个,那么这4个cache line就组成了一个组。一个组的cache line,他们的索引值都是一样的。大家可能会疑问,为啥要有组的概念,其实如果我们把cache不分成4个大块,只分成一个大块,那么这个cache就变成了一个数组。那一个索引值只能对应一个cache line。如果这时候cpu访问两个地址,他们的索引值都是一样的,那么cache就要把 前面那个cache line给踢出去,然后读进来新的数据,如果cpu在一段时间里频繁读这两个地址,那么这个cache line就会被频繁踢来踢去,造成性能低下,这个叫做 颠簸。这也是为什么现在的cache 都要分 组的原因,如果一个组里有4个cache line,那么刚才那个场景,就不会出现 颠簸的现象。因为一个组里有4个cache line,足够存放两个不同的地址的访问,不需要把cache line踢来踢去。
刚才讲了路和组还有索引,还有一个东西没讲,那就是标记(tag):高速缓存地址编码的一部分,通常是高速缓存地址的高位部分,用来判断高速缓存行缓存数据的地址是否和处理器寻址地址一致。
偏移(offset):高速缓存行中的偏移。处理器可以按字(word)或者字节(Byte)来寻址高速缓存行的内容。
Cache映射方式 – 直接映射
直接映射的方式比较简单,就是说,我们把cache只分成一个块,那么一个组只有一个cache line,这种映射方式叫做直接映射方式。我们来看一下左边那个图,这个图,假设cache只有4个cache line。那么直接映射的结果就是0x0地址到0x30,这段内存地址直接映射到cache里。如果cpu要访问0x40到0x70,这段内存,那么又把数据会直接映射到cache里,这时候的映射,大家可以想一想,之前的0x0~0x30这段内存地址的数据在cache里是不是要被踢出去,否则后面的没办法映射。
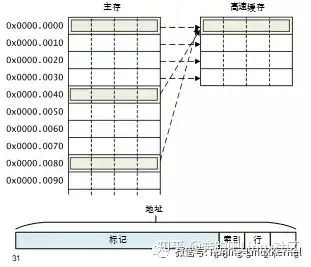
好,我们来看一个简单的例子。假设在下面的代码片段中,result、data1和data2分别指向0x00、0x40和0x80地址,它们都会使用同一个高速缓存行。大家可以想想有啥后果。
void add_array(int *data1, int *data2, int *result, int size)
{
int i;
for (i=0 ; i<size ; i++) {
result[i] = data1[i] + data2[i];
}
}当第一次读data1即0x40地址时,因为不在高速缓存里面,所以读取从0x40到0x4f地址的数据填充到高速缓存行中。
- 当读data2即0x80地址的数据时,数据不在高速缓存行中,需要把从0x80到0x8f地址的数据填充到高速缓存行中,因为地址0x80和0x40映射到同一个高速缓存行,所以高速缓存行发生替换操作。
- result写入0x00地址时,同样发生了高速缓存行替换操作。
- 所以这个代码片段发生严重的高速缓存颠簸,性能会很糟糕。
Cache映射方式 – 全关联
当cache只有一个组,即主存中只有一个地址与n个cache line对应,称为全关联,这又是一个极端的映射方式。刚才直接映射不要把cache分成几大块,而全关联,正好是另外一个极端,就是把cache分成n多个大块,每个大块的大小只有一个cache line那么大。换句话说,这个cache只有一个组,这个组里有n多个cache line。
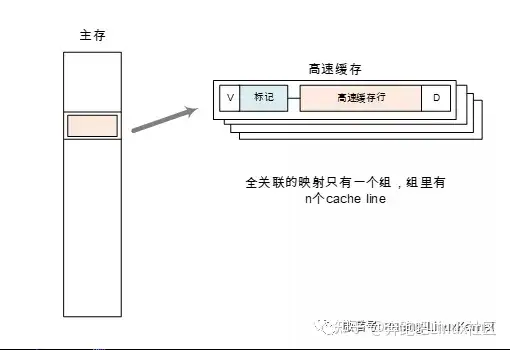
这种方式和直接映射来对比,都是两种极端。
Cache映射方式 –组相联
为了解决直接映射高速缓存中的高速缓存颠簸问题,组相联(set associative)的高速缓存结构在现代处理器中得到广泛应用。
下面以一个2路组相联的高速缓存为例,每一路包括4个高速缓存行,那么每个组有两个高速缓存行可以提供高速缓存行替换。
地址0x00、0x40或者0x80的数据可以映射到同一个组中任意一个高速缓存行。当高速缓存行要发生替换操作时,就有50%的概率可以不被替换,从而减小了高速缓存颠簸。
我们举一个例子来说明,怎么去看组相联的cache内部是怎么layout的。
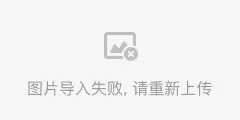
32KB大小的4路组相联的cache,其中cache line为32字节,请画出cache的映射结构图。
高速缓存的总大小为32KB,并且是4路(way),所以每一路的大小为8KB:
way_size = 32 / 4 = 8(KB)
高速缓存行的大小为32字节,所以每一路包含的高速缓存行数量为:
num_cache_line = 8KB/32B = 256
所以在高速缓存编码地址Address中,Bit[4:0]用于选择高速缓存行中的数据,其中Bit [4:2]可以用于寻址8个字,Bit [1:0]可以用于寻址每个字中的字节。Bit [12:5]用于索引域(Index)选择每一路上高速缓存行,其余的Bit [31:13]用作标记域(Tag)。
虚拟cache与物理cache
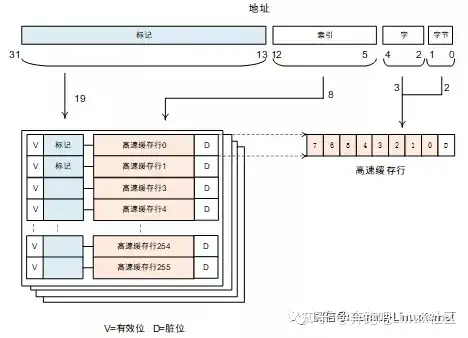
物理cache
当处理器查询MMU和TLB得到物理地址之后,使用物理地址去查询高速缓存,我们称为物理高速缓存。使用物理高速缓存的缺点就是处理器在查询MMU和TLB后才能访问高速缓存,增加了流水线的延迟。这张图是物理高速缓存的工作流程。
虚拟cache
CPU使用虚拟地址来寻址高速缓存,我们称为虚拟高速缓存。处理器在寻址时,首先把虚拟地址发送到高速缓存中,若在高速缓存里找到需要的数据,那么就不再需要访问TLB和物理内存。
CPU使用虚拟地址来寻址高速缓存,我们称为虚拟高速缓存。处理器在寻址时,首先把虚拟地址发送到高速缓存中,若在高速缓存里找到需要的数据,那么就不再需要访问TLB和物理内存。
cache的分类
高速缓存在查询时使用了索引域和标记域,那么查询高速缓存 组是用虚拟地址还是物理地址的索引(index)域呢?当找到高速缓存 组时,我们是用虚拟地址还是物理地址的标记(tag)域来匹配高速缓存行呢?
高速缓存可以设计成通过虚拟地址或者物理地址来访问,这个在处理器设计时就确定下来了,并且对高速缓存的管理有很大的影响。高速缓存可以分成如下3类。
- VIVT(Virtual Index Virtual Tag):使用虚拟地址的索引域和虚拟地址的标记域,相当于是虚拟高速缓存。
- PIPT(Physical Index Physical Tag):使用物理地址索引域和物理地址的标记域,相当于是物理高速缓存。
- VIPT(Virtual Index Physical Tag):使用虚拟地址索引域和物理地址的标记域。
在早期的ARM处理器中(比如ARM9处理器)采用VIVT的方式,不用经过MMU的翻译,直接使用虚拟地址的索引域和标记域来查找高速缓存行,这种方式会导致高速缓存别名(cache alias)问题。例如一个物理地址的内容可以出现在多个高速缓存行中,当系统改变了虚拟地址到物理地址映射时,需要清洗(clean)和无效(invalidate)这些高速缓存,导致系统性能下降。
VIPT工作原理
现在很多cortex系列的处理器的L1 data cache采用VIPT方式,即处理器输出的虚拟地址同时会发送到TLB/MMU单元进行地址翻译,以及在高速缓存中进行索引和查询高速缓存。在TLB/MMU单元里,会把虚拟页帧号(VPN)翻译成物理页帧号(PFN),以此同时,虚拟地址的索引域和偏移会用来查询高速缓存。这样高速缓存和TLB/MMU可以同时工作,当TLB/MMU完成地址翻译后,再用物理标记域来匹配高速缓存行。采用VIPT方式的好处之一是在多任务操作系统中,修改了虚拟地址到物理地址映射关系,不需要把相应的高速缓存进行无效(invalidate)操作。
重名和同名问题
虚拟高速缓存会引入不少的问题,一个是重名问题,另一个是同名问题。
重名(别名)问题
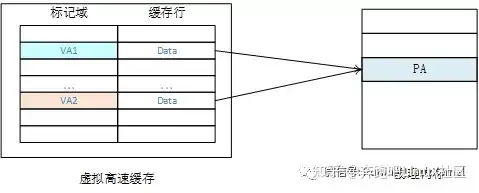
重名问题是怎么产生的呢?我们知道,在操作系统中,多个不同的虚拟地址有可能映射相同的物理地址。由于采用虚拟高速缓存架构,那么这些不同的虚拟地址会占用高速缓存中不同的高速缓存行,但是它们对应的是相同的物理地址。这样会引发问题,第一,浪费了高速缓存空间,造成高速缓存等效容量的减少,减低整体性能。第二,当执行写操作时,只更新了其中一个虚拟地址对应的高速缓存,而其他虚拟地址对应的高速缓存并没有更新。那么处理器访问其他虚拟地址可能得到旧数据。
我们举个例子,假设我们的cache系统是虚拟高速缓存,VA1映射到PA,VA2也映射到PA,那么在虚拟高速缓存结构中有可能同时缓存了VA1和VA2。当程序往VA1写入数据时,虚拟高速缓存中VA1对应的高速缓存行以及PA的内容会被更改,但是VA2对应的cache还保存着旧数据。这样一个物理地址在虚拟高速缓存中就保存了两份数据,这样会产生歧义。
同名问题
同名问题是怎么产生的呢?同名问题指的是相同的虚拟地址对应着不同的物理地址,因为操作系统中不同的进程会存在很多相同的虚拟地址,而这些相同的虚拟地址在经过MMU转换后得到不同的物理地址,这就产生了同名问题。
同名问题最常见的地方是进程切换。当一个进程切换到另外一个进程时,新进程使用虚拟地址来访问高速缓存的话,新进程会访问到旧进程遗留下来的高速缓存,这些高速缓存数据对于新进程来说是错误和没用的。解决办法是在进程切换时把旧进程遗留下来的高速缓存都置为无效,这样就能保证新进程执行时得到一个干净的虚拟高速缓存。同样,TLB也需要设置为无效,因为新进程在切换后得到一个旧进程使用的TLB,里面存放了旧进程的虚拟地址到物理地址的转换结果,这对于新进程来说是无用的,因此也需要把TLB清空。
这个是在ASID等这些技术还没有enable的时候,需要把整个TLB给清空。
我们简单做一个总结,重名问题实际上是多个虚拟地址映射到同一个物理地址引发的歧义问题,而同名问题是一个虚拟地址可能因为进程切换等原因映射到不同的物理地址而引发的问题。
VIPT的别名问题
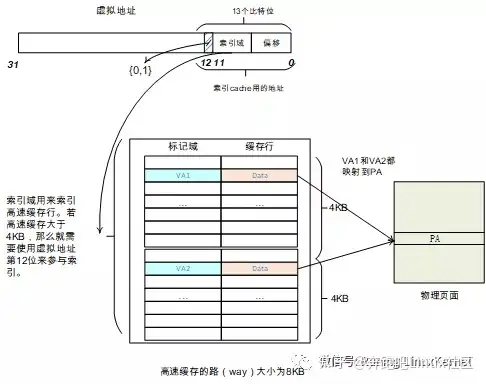
采用VIPT方式也有可能导致高速缓存别名的问题。在VIPT中,使用虚拟地址的索引域来查找高速缓存的cache line,这时有可能导致多个高速缓存组映射到同一个物理地址上。以Linux 内核为例,它是以4KB大小为一个页面进行管理的,那么对于一个页来说,虚拟地址和物理地址的低12位(Bit [11:0])是一样的。因此,不同的虚拟地址映射到同一个物理地址,这些虚拟页面的低12位是一样的。
如果索引域位于Bit [11:0]范围内,那么就不会发生高速缓存重名问题,因为那相当于在一个页面内的地址。那什么情况下索引域会在Bit [11:0]范围内呢?我们知道索引域是用来在一个高速缓存路(way)中查找高速缓存行的,当一个高速缓存路(块)的大小在4KB范围内,那么索引域必然在Bit [11:0]范围内。例如,高速缓存行是32字节,那么数据偏移域offset占5位,有128个高速缓存组,那么索引域占7位,这种情况下刚好不会发生重名。
下面我来举一个发生别名的问题的例子。假设高速缓存的路(way)的大小是8KB,并且两个虚拟页面Page1和Page2同时映射到同一个物理页面中。因为cache的路是8KB,所以索引域的范围会在Bit[12:0]。

我们研究其中的虚拟地址VA1和VA2,这两个虚拟地址的第12位有可能是0,也有可能是1。当VA1的第12位为0,VA2的第12位为1时,在高速缓存中会有两个不同的地方同时存储了同一个物理地址PA的值,这样就产生了重名问题,当修改虚拟地址VA1的内容后,访问虚拟地址VA2会得到一个旧值,导致错误发生。
cache的层级
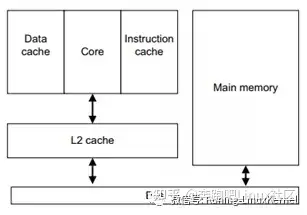
我们前面聊的都是L1 cache的一些背景知识,接下来给大家看看多级cache,现在系统至少都有2级cache了。这个图的左边是一个两级cache的框图。大家可以看到,CPU核心会内置了L1 的data cache和L1的指令cache,然后在外面会有一个L2的cache。L2的cache连接到系统总线上。
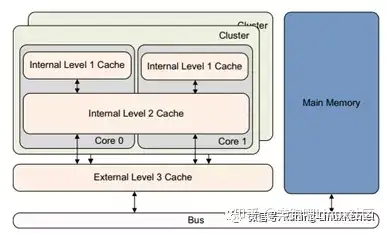
这个图是三级cache的情况。这个图是arm一个经典的多cluster架构图,每个cluster里有多个core,比如这个图上,一个cluster里有两个core,core0和core1,每个core都有自己独立的L1 cache。Core0和core1共享L2 cache。然后两个cluster还共享一个external Level 3 cache。L3 cache连接到系统总线上。包括内存DDR也是连接到系统总线上。
cache的访问延时
我们了解多级cache,有一个重要的观察点,大家需要知道,那就是站在CPU的角度来看,各级cache的访问时间。越靠近cpu那边,访问速度是越快的,越靠近内存那边,访问速度是越慢。这里这个表格是我从网上资料找到的,是intel 至强服务器兴趣的一个测试数据,我没有找到arm相关的数据,不过这个不重要,重要的是我们去理解多级cache访问延迟的一个概念。
我们来看一下这张表,如果L1 cache命中的话,CPU访问大概4个时钟周期。如果L2 cache命中的话,大约10个时钟周期,从这可以看出,L2 cache比L1 cache慢一倍以上。如果L3 cache命中,这里还分了好几种情况,基本上是更加MESI协议来分的,比如cache line没有共享,那就是独占状态,那么大约40个时钟周期,如果cache line和其他CPU共享,那么需要65个时钟周期,如果cache line被其他CPU修改过,那么需要75个时钟周期,因为MESI协议需要消耗一部分 总线带宽。如果访问远端的L3 cache,这里远端指的是远端NUMA节点的L3 cache,大概要100~300时钟周期。如果访问本地内存ddr,大约需要60纳秒。所以,你可以对比一下,如果访问一个数据,L1 cache命中和直接访问内存之间的速度的差距,相差好多。最后一行,访问远端NUMA节点的延迟更长。
cache的策略
Cache策略一般是包括 这个内存地址是否支持cache,比如你可以设置为cacheable,你也可以关闭cache,变成non-cacheable。
Cache的write/read allocate
如果支持cache的话,你还可以继续细分,比如是read allocate还是write allocate,这个cache line分配策略,read allocate的意思是读cache line的时候发现没有空闲的cache line去分配一个新的cache line,而write allocate则是写一个cache line的时候发现没有空闲的cache line,然后去分配一个新的cache line。Write-Back,write-through 主要讲的是回写的策略。Shareability主要讲的cache的共享属性和范围,比如后面讲到的inner share,outer share,POC和POU等概念。
通常,cache的相关策略是在MMU页表里进行配置的。还有一点很重要就是只有normal的内存才能被cacheable。
Cache回写策略
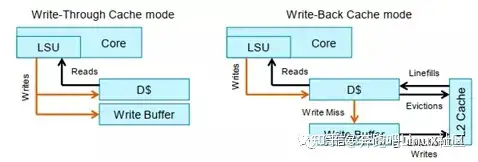
Cache回写策略,一般cache有两种回写策略,一个是write back,另外一个是write throuhgt,Write-back: 回写操作仅仅更新到cache,并没有马上更新会内存。(cache line is marked as dirty),Write through:回写操作会直接更新cache和内存。
我们先来看WT写直通模式。进行写操作时,数据同时写入当前的高速缓存、下一级高速缓存或主存储器中。直写模式可以降低高速缓存一致性的实现难度,其最大的缺点是消耗比较多的总线带宽。
对于arm处理器来说,把WT模式看成Non-cacheable。因为在内部实现来看,里面有一个write buffer的部件,WT模式相当于把write buffer部件给disable了。
回写模式:在进行写操作时,数据直接写入当前高速缓存,而不会继续传递,当该高速缓存行被替换出去时,被改写的数据才会更新到下一级高速缓存或主存储器中。该策略增加了高速缓存一致性的实现难度,但是有效降低了总线带宽需求。
ARM64视频课程
现在就业市场和职场的压力越来越大,和我一样二本毕业的同学,如果在职场不努力的话,就会没饭吃,好吃的饭都给985/211毕业的同学抢走了,他们天资聪慧,还勤奋努力。来吧,给自己一个继续深入学习和进步的理由,来与笨叔一起学习ARM64,一起玩树莓派,一起做实验,一起进步吧!
全球原创的arm64实验,全球首个手把手解读armv8手册的视频课程,您值得拥有!
点击“阅读原文”进入微店订阅吧!
