重点监控指标
指标分类
-
健康状态
-
USE 方法(系统)
-
使用率
-
饱和度
-
错误
-
-
RED 方法(应用)
-
请求速率
-
错误率
-
延迟
-
| 指标分类 | 指标 | 释义 |
|---|---|---|
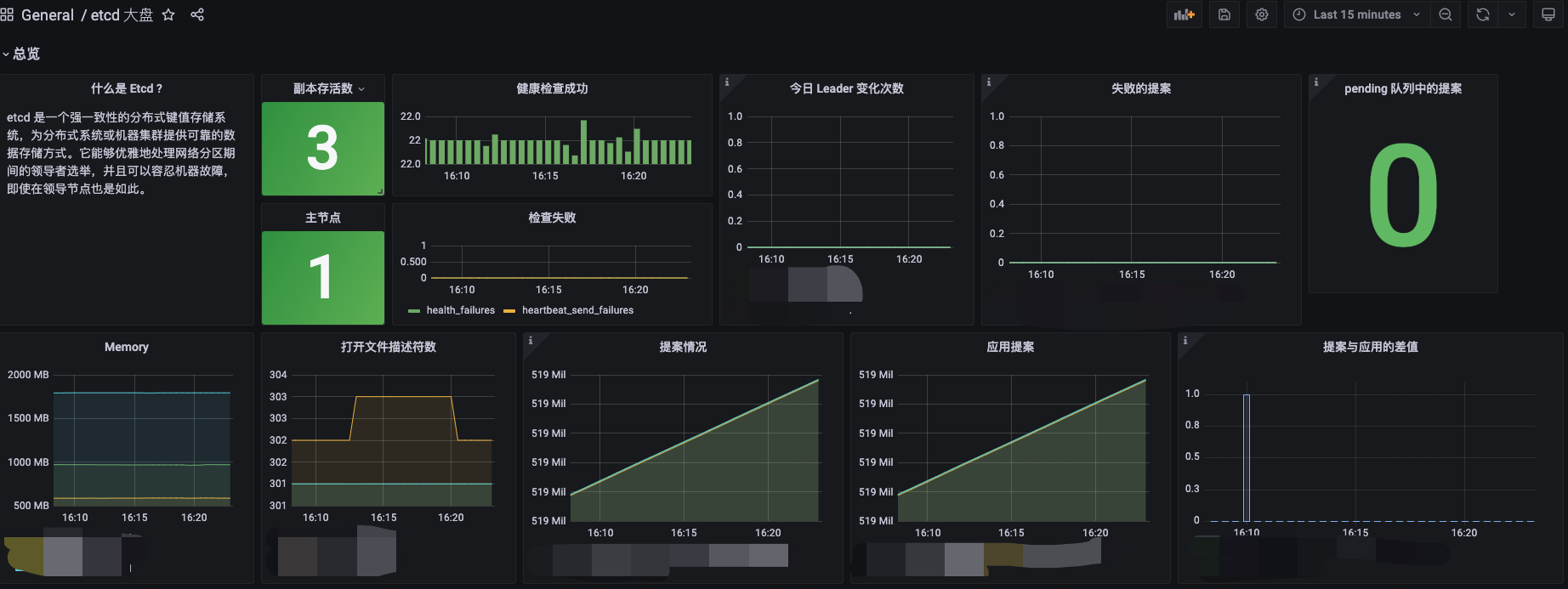
| 健康状态 | 实例健康状态 | etcd是一个分布式系统,由多个成员节点组成。监控etcd成员节点的状态可以帮助你了解集群中节点的健康状况,发现掉线或者异常节点。 |
| 健康状态 | 主从状态 | |
| 健康状态 | etcd leader切换统计 | 频繁的领导者变更会严重影响 etcd 的性能。这也意味着领导者不稳定,可能是由于网络连接问题或对 etcd 集群施加的过载负荷导致的。 |
| 健康状态 | 心跳 | etcd集群中的节点通过发送心跳来保持彼此之间的连接。监控丢失的心跳可以帮助你发现etcd节点之间的通信问题或者网络延迟。 |
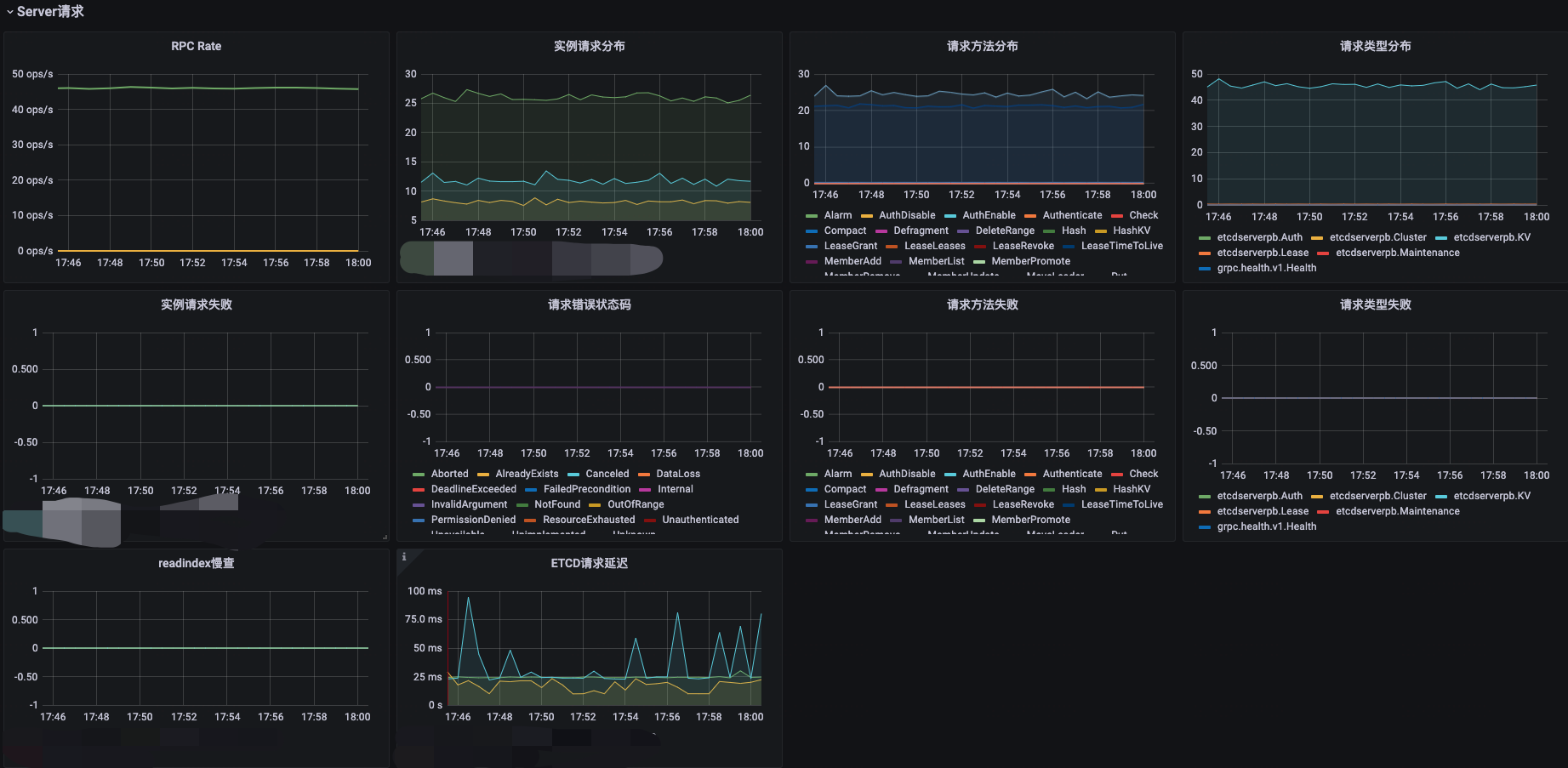
| RED 方法 | QPS | |
| RED 方法 | 请求错误率 | 监控etcd的错误率可以帮助你发现etcd操作中的潜在问题。高错误率可能表明集群遇到了故障或其他异常情况。 |
| RED 方法 | 请求延迟 | 监控etcd的请求延迟可以帮助你了解API请求的处理时间。较高的延迟可能表明etcd正面临负载压力或性能问题。 |
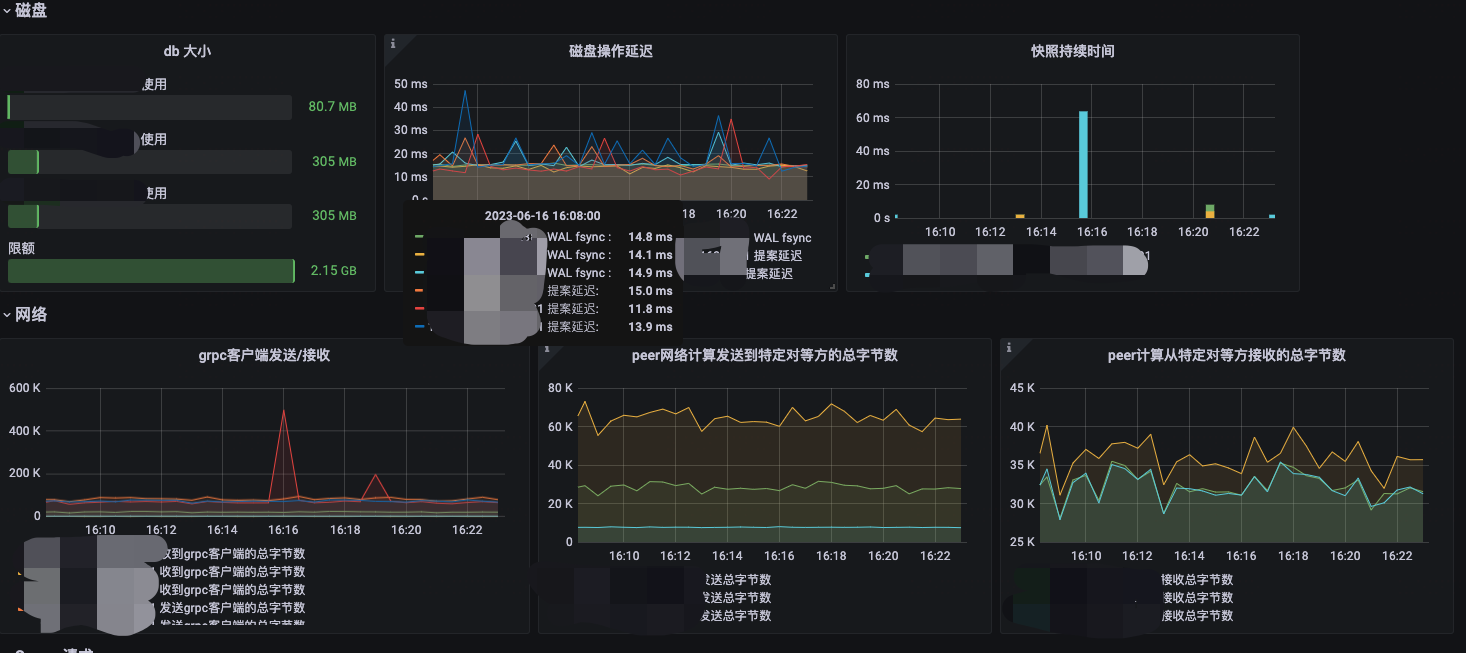
| RED 方法 | 磁盘同步(WAL/DB fsync)耗时 | 高磁盘操作延迟(wal_fsync_duration_seconds或backend_commit_duration_seconds)通常表示磁盘问题。它可能会导致高请求延迟或使群集不稳定。 |
| RED 方法 | 同步延迟 | 如果集群正常运行,已提交的提案应该随着时间的推移而增加。重要的是要在集群的所有成员中监控这个指标;如果单个成员与其领导节点之间存在持续较大的滞后,这表明该成员运行缓慢或存在异常。 |
| RED 方法 | 提案失败次数 | 失败的提案通常与两个问题相关:与领导选举相关的暂时性故障或由于集群丧失法定人数而导致的较长时间的停机。 |
| RED 方法 | 快照处理时间 | etcd定期创建快照以备份数据。监控快照处理时间可以帮助你了解etcd备份的性能,确保备份任务能够及时完成。 |
| RED 方法 | watcher 数量 | 监控etcd集群当前连接到etcd的客户端数量。如果连接数过高,可能需要调整etcd的配置或者增加集群的容量。 |
| USE 方法 | CPU 使用率 | |
| USE 方法 | 内存使用量 | |
| USE 方法 | 打开文件数 | |
| USE 方法 | 存储空间使用率 | 监控etcd存储空间的使用率可以帮助你确保etcd有足够的空间存储配置数据。如果使用率接近或达到上限,可能需要考虑扩展存储容量或者清理无用的数据。 |
使用 kube-prometheus 收集 etcd 指标
http 模式(推荐)
修改--listen-metrics-urls
#- --listen-metrics-urls=http://127.0.0.1:2381
部署
helm install monitoring -n cattle-prometheus --set kubeEtcd.service.port=2381 --set kubeEtcd.service.targetPort=2381 --set prometheusOperator.admissionWebhooks.patch.image.sha=null ./
https 模式
新增 etcd secret
kubectl create secret generic etcd-certs -n cattle-prometheus --from-file=/etc/kubernetes/pki/etcd/ca.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key
部署
helm install monitoring -n cattle-prometheus --set kubeEtcd.serviceMonitor.scheme=https --set kubeEtcd.serviceMonitor.caFile=/etc/prometheus/secrets/etcd-certs/ca.crt --set kubeEtcd.serviceMonitor.certFile=/etc/prometheus/secrets/etcd-certs/healthcheck-client.crt --set kubeEtcd.serviceMonitor.keyFile=/etc/prometheus/secrets/etcd-certs/healthcheck-client.key --set prometheus.prometheusSpec.secrets={etcd-certs} --set prometheusOperator.admissionWebhooks.patch.image.sha=null ./
大盘展示
Grafana 大盘: https://github.com/clay-wangzhi/grafana-dashboard/blob/master/etcd/etcd-dash.json 导入即可
巡检
完成集群部署、了解成员管理、构建好监控及告警体系并添加好定时备份策略后,这时终于可以放心给业务使用了。然而在后续业务使用过程中,你可能会遇到各类问题,而这些问题很可能是metrics监控无法发现的,比如如下:
-
etcd集群因重启进程、节点等出现数据不一致;
-
业务写入大 key-value 导致 etcd 性能骤降;
-
业务异常写入大量key数,稳定性存在隐患;
这时就需要巡检。
参考ServiceMonitor和EtcdBackup机制,同样可以通过CRD的方式描述此巡检任务,然后通过相应的Operator实现此巡检任务。
参考链接: