K8S实战集训第一课 Ansible自动化部署k8s、弹性伸缩、Helm包管理、k8s网络模型介绍
Ansible自动化部署K8S集群
一、Ansible自动化部署K8S集群
1.1 Ansible介绍
Ansible是一种IT自动化工具。它可以配置系统,部署软件以及协调更高级的IT任务,例如持续部署,滚动更新。Ansible适用于管理企业IT基础设施,从具有少数主机的小规模到数千个实例的企业环境。Ansible也是一种简单的自动化语言,可以完美地描述IT应用程序基础结构。
具备以下三个特点:
- 简单:减少学习成本
- 强大:协调应用程序生命周期
- 无代理:可预测,可靠和安全
使用文档: https://docs.ansible.com/
安装Ansible:yum install ansible -y
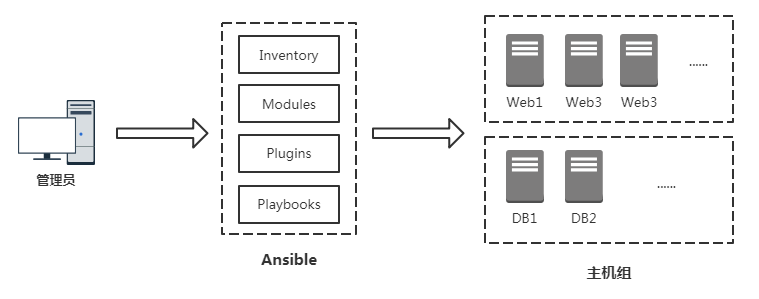
- Inventory:Ansible管理的主机信息,包括IP地址、SSH端口、账号、密码等
- Modules:任务均有模块完成,也可以自定义模块,例如经常用的脚本。
- Plugins:使用插件增加Ansible核心功能,自身提供了很多插件,也可以自定义插件。例如connection插件,用于连接目标主机。
- Playbooks:“剧本”,模块化定义一系列任务,供外部统一调用。Ansible核心功能。
1.2 主机清单
[webservers]
alpha.example.org
beta.example.org
192.168.1.100
www[001:006].example.com
[dbservers]
db01.intranet.mydomain.net
db02.intranet.mydomain.net
10.25.1.56
10.25.1.57
db-[99:101]-node.example.com- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
1.3 命令行使用
ad-hoc命令可以输入内容,快速执行某个操作,但不希望留存记录。
ad-hoc命令是理解Ansible和在学习playbooks之前需要掌握的基础知识。
一般来说,Ansible的真正能力在于剧本。
1、连接远程主机认证
SSH密码认证:
[webservers]
192.168.1.100:22 ansible_ssh_user=root ansible_ssh_pass=’123456’
192.168.1.101:22 ansible_ssh_user=root ansible_ssh_pass=’123456’- 1
- 2
- 3
SSH密钥对认证:
[webservers]
10.206.240.111:22 ansible_ssh_user=root ansible_ssh_key=/root/.ssh/id_rsa
10.206.240.112:22 ansible_ssh_user=root
也可以ansible.cfg在配置文件中指定:
[defaults]
private_key_file = /root/.ssh/id_rsa # 默认路径- 1
- 2
- 3
- 4
- 5
- 6
- 7
2、常用选项
| 选项 | 描述 |
|---|---|
| -C, --check | 运行检查,不执行任何操作 |
| -e EXTRA_VARS,–extra-vars=EXTRA_VARS | 设置附加变量 key=value |
| -u REMOTE_USER, --user=REMOTE_USER | SSH连接用户,默认None |
| -k, --ask-pass | SSH连接用户密码 |
| -b, --become | 提权,默认root |
| -K, --ask-become-pass | 提权密码 |
3、命令行使用
ansible all -m ping
ansible all -m shell -a "ls /root" -u root -k
ansible webservers -m copy –a "src=/etc/hosts dest=/tmp/hosts"- 1
- 2
- 3
1.4 常用模块
ansible-doc –l 查看所有模块
ansible-doc –s copy 查看模块文档
模块文档:https://docs.ansible.com/ansible/latest/modules/modules_by_category.html
1、shell
在目标主机执行shell命令。
- name: 将命令结果输出到指定文件
shell: somescript.sh >> somelog.txt
- name: 切换目录执行命令
shell:
cmd: ls -l | grep log
chdir: somedir/
- name: 编写脚本
shell: |
if [ 0 -eq 0 ]; then
echo yes > /tmp/result
else
echo no > /tmp/result
fi
args:
executable: /bin/bash- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2、copy
将文件复制到远程主机。
- name: 拷贝文件
copy:
src: /srv/myfiles/foo.conf
dest: /etc/foo.conf
owner: foo
group: foo
mode: u=rw,g=r,o=r
# mode: u+rw,g-wx,o-rwx
# mode: '0644'
backup: yes- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3、file
管理文件和文件属性。
- name: 创建目录
file:
path: /etc/some_directory
state: directory
mode: '0755'
- name: 删除文件
file:
path: /etc/foo.txt
state: absent
- name: 递归删除目录
file:
path: /etc/foo
state: absent- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
present,latest:表示安装
absent:表示卸载
4、yum
软件包管理。
- name: 安装最新版apache
yum:
name: httpd
state: latest
- name: 安装列表中所有包
yum:
name:
- nginx
- postgresql
- postgresql-server
state: present
- name: 卸载apache包
yum:
name: httpd
state: absent
- name: 更新所有包
yum:
name: '*'
state: latest
- name: 安装nginx来自远程repo
yum:
name: http://nginx.org/packages/rhel/7/x86_64/RPMS/nginx-1.14.0-1.el7_4.ngx.x86_64.rpm
# name: /usr/local/src/nginx-release-centos-6-0.el6.ngx.noarch.rpm
state: present
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
5、service/systemd
管理服务。
- name: 服务管理
service:
name: etcd
state: started
#state: stopped
#state: restarted
#state: reloaded
- name: 设置开机启动
service:
name: httpd
enabled: yes- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- name: 服务管理
systemd:
name=etcd
state=restarted
enabled=yes
daemon_reload=yes- 1
- 2
- 3
- 4
- 5
- 6
6、unarchive
- name: 解压
unarchive:
src=test.tar.gz
dest=/tmp- 1
- 2
- 3
- 4
7、debug
执行过程中打印语句。
- debug:
msg: System {{ inventory_hostname }} has uuid {{ ansible_product_uuid }}
- name: 显示主机已知的所有变量
debug:
var: hostvars[inventory_hostname]
verbosity: 4- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.5 Playbook
Playbooks是Ansible的配置,部署和编排语言。他们可以描述您希望在远程机器做哪些事或者描述IT流程中一系列步骤。使用易读的YAML格式组织Playbook文件。
如果Ansible模块是您工作中的工具,那么Playbook就是您的使用说明书,而您的主机资产文件就是您的原材料。
与adhoc任务执行模式相比,Playbooks使用ansible是一种完全不同的方式,并且功能特别强大。
https://docs.ansible.com/ansible/latest/user_guide/playbooks.html
---
- hosts: webservers
vars:
http_port: 80
server_name: www.ctnrs.com
remote_user: root
gather_facts: false
tasks:
- name: 安装nginx最新版
yum: pkg=nginx state=latest
- name: 写入nginx配置文件
template: src=/srv/httpd.j2 dest=/etc/nginx/nginx.conf
notify:
- restart nginx
- name: 确保nginx正在运行
service: name=httpd state=started
handlers:
- name: restart nginx
service: name=nginx state=reloaded- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
1、主机和用户
- hosts: webservers
remote_user: lizhenliang
become: yes
become_user: root- 1
- 2
- 3
- 4
ansible-playbook nginx.yaml -u lizhenliang -k -b -K
2、定义变量
变量是应用于多个主机的便捷方式; 实际在主机执行之前,变量会对每个主机添加,然后在执行中引用。
-
命令行传递
-e VAR=VALUE- 1
-
主机变量与组变量
在Inventory中定义变量。
[webservers]
192.168.1.100 ansible_ssh_user=root hostname=web1
192.168.1.100 ansible_ssh_user=root hostname=web2
[webservers:vars]
ansible_ssh_user=root hostname=web1- 1
- 2
- 3
- 4
- 5
- 6
- 单文件存储
Ansible中的首选做法是不将变量存储在Inventory中。
除了将变量直接存储在Inventory文件之外,主机和组变量还可以存储在相对于Inventory文件的单个文件中。
组变量:
group_vars 存放的是组变量
group_vars/all.yml 表示所有主机有效,等同于[all:vars]
grous_vars/etcd.yml 表示etcd组主机有效,等同于[etcd:vars]
# vi /etc/ansible/group_vars/all.yml
work_dir: /data
# vi /etc/ansible/host_vars/webservers.yml
nginx_port: 80- 1
- 2
- 3
- 4
- 在Playbook中定义
- hosts: webservers
vars:
http_port: 80
server_name: www.ctnrs.com- 1
- 2
- 3
- 4
- Register变量
- shell: /usr/bin/uptime
register: result
- debug:
var: result- 1
- 2
- 3
- 4
3、任务列表
每个play包含一系列任务。这些任务按照顺序执行,在play中,所有主机都会执行相同的任务指令。play目的是将选择的主机映射到任务。
tasks:
- name: 安装nginx最新版
yum: pkg=nginx state=latest- 1
- 2
- 3
4、语法检查与调试
语法检查:ansible-playbook --check /path/to/playbook.yaml
测试运行,不实际操作:ansible-playbook -C /path/to/playbook.yaml
debug模块在执行期间打印语句,对于调试变量或表达式,而不必停止play。与’when:'指令一起调试更佳。
- debug: msg={{group_names}}
- name: 主机名
debug:
msg: "{{inventory_hostname}}"- 1
- 2
- 3
- 4
5、任务控制
如果你有一个大的剧本,那么能够在不运行整个剧本的情况下运行特定部分可能会很有用。
tasks:
- name: 安装nginx最新版
yum: pkg=nginx state=latest
tags: install
- name: 写入nginx配置文件
template: src=/srv/httpd.j2 dest=/etc/nginx/nginx.conf
tags: config- 1
- 2
- 3
- 4
- 5
- 6
- 7
使用:
ansible-playbook example.yml --tags "install"
ansible-playbook example.yml --tags "install,config"
ansible-playbook example.yml --skip-tags "install"- 1
- 2
- 3
6、流程控制
条件:
tasks:
- name: 只在192.168.1.100运行任务
debug: msg="{{ansible_default_ipv4.address}}"
when: ansible_default_ipv4.address == '192.168.1.100'- 1
- 2
- 3
- 4
循环:
tasks:
- name: 批量创建用户
user: name={{ item }} state=present groups=wheel
with_items:
- testuser1
- testuser2- 1
- 2
- 3
- 4
- 5
- 6
- name: 解压
copy: src={{ item }} dest=/tmp
with_fileglob:
- "*.txt"- 1
- 2
- 3
- 4
常用循环语句:
| 语句 | 描述 |
|---|---|
| with_items | 标准循环 |
| with_fileglob | 遍历目录文件 |
| with_dict | 遍历字典 |
7、模板
vars:
domain: "www.ctnrs.com"
tasks:
- name: 写入nginx配置文件
template: src=/srv/server.j2 dest=/etc/nginx/conf.d/server.conf- 1
- 2
- 3
- 4
- 5
# server.j2
{% set domain_name = domain %}
server {
listen 80;
server_name {{ domain_name }};
location / {
root /usr/share/html;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在jinja里使用ansible变量直接 {{ }}引用。使用ansible变量赋值jinja变量不用{{ }}引用。
定义变量:
{% set local_ip = inventory_hostname %}- 1
条件和循环:
{% set list=['one', 'two', 'three'] %}
{% for i in list %}
{% if i == 'two' %}
-> two
{% elif loop.index == 3 %}
-> 3
{% else %}
{{i}}
{% endif %}
{% endfor %}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
例如:生成连接etcd字符串
{% for host in groups['etcd'] %}
https://{{ hostvars[host].inventory_hostname }}:2379
{% if not loop.last %},{% endif %}
{% endfor %}- 1
- 2
- 3
- 4
里面也可以用ansible的变量。
1.6 Roles
Roles是基于已知文件结构自动加载某些变量文件,任务和处理程序的方法。按角色对内容进行分组,适合构建复杂的部署环境。
1、定义Roles
Roles目录结构:
site.yml
webservers.yml
fooservers.yml
roles/
common/
tasks/
handlers/
files/
templates/
vars/
defaults/
meta/
webservers/
tasks/
defaults/
meta/- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
tasks-包含角色要执行的任务的主要列表。handlers-包含处理程序,此角色甚至在此角色之外的任何地方都可以使用这些处理程序。defaults-角色的默认变量vars-角色的其他变量files-包含可以通过此角色部署的文件。templates-包含可以通过此角色部署的模板。meta-为此角色定义一些元数据。请参阅下面的更多细节。
通常的做法是从tasks/main.yml文件中包含特定于平台的任务:
# roles/webservers/tasks/main.yml
- name: added in 2.4, previously you used 'include'
import_tasks: redhat.yml
when: ansible_facts['os_family']|lower == 'redhat'
- import_tasks: debian.yml
when: ansible_facts['os_family']|lower == 'debian'
# roles/webservers/tasks/redhat.yml
- yum:
name: "httpd"
state: present
# roles/webservers/tasks/debian.yml
- apt:
name: "apache2"
state: present- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2、使用角色
# site.yml
- hosts: webservers
roles:
- common
- webservers
定义多个:
- name: 0
gather_facts: false
hosts: all
roles:
- common
- name: 1
gather_facts: false
hosts: all
roles:
- webservers- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
3、角色控制
- name: 0.系统初始化
gather_facts: false
hosts: all
roles:
- common
tags: common- 1
- 2
- 3
- 4
- 5
- 6
1.7 自动化部署K8S(离线版)
1、 熟悉二进制部署K8S步骤
- 服务器规划
| 角色 | IP | 组件 |
| ----------------------- | ---------------------------------- | ------------------------------------------------------------ |
| k8s-master1 | 192.168.31.61 | kube-apiserver kube-controller-manager kube-scheduler etcd |
| k8s-master2 | 192.168.31.62 | kube-apiserver kube-controller-manager kube-scheduler |
| k8s-node1 | 192.168.31.63 | kubelet kube-proxy docker etcd |
| k8s-node2 | 192.168.31.66 | kubelet kube-proxy docker etcd |
| Load Balancer(Master) | 192.168.31.61 192.168.31.60 (VIP) | nginx keepalived |
| Load Balancer(Backup) | 192.168.31.62 | nginx keepalived | - 系统初始化
- 关闭selinux,firewalld
- 关闭swap
- 时间同步
- 写hosts
- Etcd集群部署
- 生成etcd证书
- 部署三个etcd集群
- 查看集群状态
- 部署Master
- 生成apiserver证书
- 部署apiserver、controller-manager和scheduler组件
- 启动TLS Bootstrapping
- 部署Node
- 安装Docker
- 部署kubelet和kube-proxy
- 在Master上允许为新Node颁发证书
- 授权apiserver访问kubelet
- 部署插件(准备好镜像)
- Flannel
- Web UI
- CoreDNS
- Ingress Controller
- Master高可用
- 增加Master节点(与Master1一致)
- 部署Nginx负载均衡器
- Nginx+Keepalived高可用
- 修改Node连接VIP
2、Roles组织K8S各组件部署解析
编写建议:
- 梳理流程和Roles结构
- 如果配置文件有不固定内容,使用jinja渲染
- 人工干预改动的内容应统一写到一个文件中
3、下载所需文件
确保所有节点系统时间一致
下载Ansible部署文件:
git clone https://github.com/lizhenliang/ansible-install-k8s
cd ansible-install-k8s- 1
- 2
下载软件包并解压:
云盘地址:https://pan.baidu.com/s/1lTXolmlcCJbei9HY2BJRPQ
tar zxf binary_pkg.tar.gz- 1
4、修改Ansible文件
修改hosts文件,根据规划修改对应IP和名称。
vi hosts- 1
修改group_vars/all.yml文件,修改软件包目录和证书可信任IP。
vim group_vars/all.yml
software_dir: '/root/binary_pkg'
...
cert_hosts:
k8s:
etcd:- 1
- 2
- 3
- 4
- 5
- 6
5、一键部署
架构图
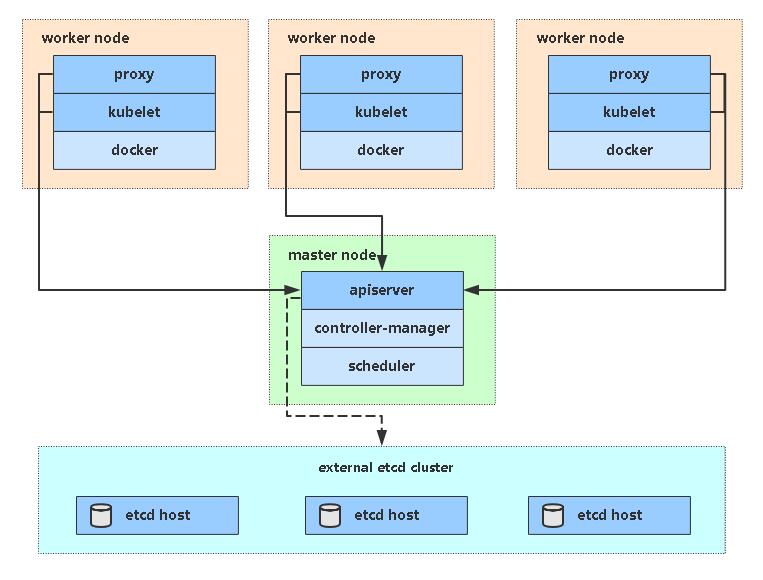
单Master架构
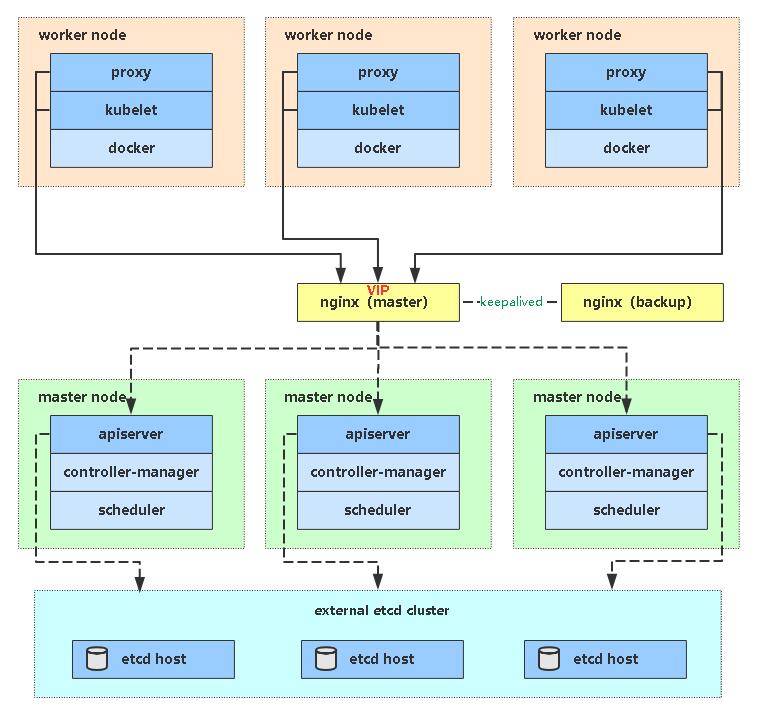
多Master架构
部署命令
单Master版:
ansible-playbook -i hosts single-master-deploy.yml -uroot -k- 1
多Master版:
ansible-playbook -i hosts multi-master-deploy.yml -uroot -k- 1
6、部署控制
如果安装某个阶段失败,可针对性测试.
例如:只运行部署插件
ansible-playbook -i hosts single-master-deploy.yml -uroot -k --tags addons- 1
示例参考:https://github.com/ansible/ansible-examples
二、弹性伸缩
2.1 传统弹性伸缩的困境
从传统意义上,弹性伸缩主要解决的问题是容量规划与实践负载的矛盾。
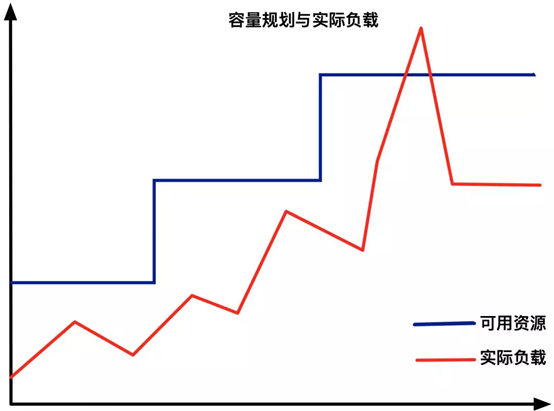
<图片来自网络>
蓝色水位线表示集群资源容量随着负载的增加不断扩容,红色曲线表示集群资源实际负载变化。
弹性伸缩就是要解决当实际负载增大,而集群资源容量没来得及反应的问题。
1、Kubernetes中弹性伸缩存在的问题
常规的做法是给集群资源预留保障集群可用,通常20%左右。这种方式看似没什么问题,但放到Kubernetes中,就会发现如下2个问题。
-
机器规格不统一造成机器利用率百分比碎片化
在一个Kubernetes集群中,通常不只包含一种规格的机器,假设集群中存在4C8G与16C32G两种规格的机器,对于10%的资源预留,这两种规格代表的意义是完全不同的。

<图片来自网络>
特别是在缩容的场景下,为了保证缩容后集群稳定性,我们一般会一个节点一个节点从集群中摘除,那么如何判断节点是否可以摘除其利用率百分比就是重要的指标。此时如果大规则机器有较低的利用率被判断缩容,那么很有可能会造成节点缩容后,容器重新调度后的争抢。如果优先缩容小规则机器,则可能造成缩容后资源的大量冗余。
-
机器利用率不单纯依靠宿主机计算
在大部分生产环境中,资源利用率都不会保持一个高的水位,但从调度来讲,调度应该保持一个比较高的水位,这样才能保障集群稳定性,又不过多浪费资源。
2、弹性伸缩概念的延伸
不是所有的业务都存在峰值流量,越来越细分的业务形态带来更多成本节省和可用性之间的跳转。
- 在线负载型:微服务、网站、API
- 离线任务型:离线计算、机器学习
- 定时任务型:定时批量计算
不同类型的负载对于弹性伸缩的要求有所不同,在线负载对弹出时间敏感,离线任务对价格敏感,定时任务对调度敏感。
2.2 kubernetes 弹性伸缩布局
在 Kubernetes 的生态中,在多个维度、多个层次提供了不同的组件来满足不同的伸缩场景。
有三种弹性伸缩:
-
CA(Cluster Autoscaler):Node级别自动扩/缩容
cluster-autoscaler组件
-
HPA(Horizontal Pod Autoscaler):Pod个数自动扩/缩容
-
VPA(Vertical Pod Autoscaler):Pod配置自动扩/缩容,主要是CPU、内存
addon-resizer组件
如果在云上建议 HPA 结合 cluster-autoscaler 的方式进行集群的弹性伸缩管理。
2.3 Node 自动扩容/缩容
1、Cluster AutoScaler
**扩容:**Cluster AutoScaler 定期检测是否有充足的资源来调度新创建的 Pod,当资源不足时会调用 Cloud Provider 创建新的 Node。
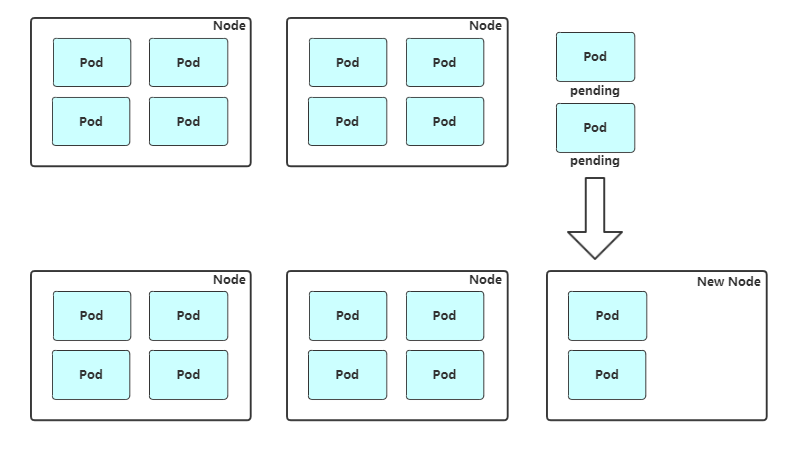
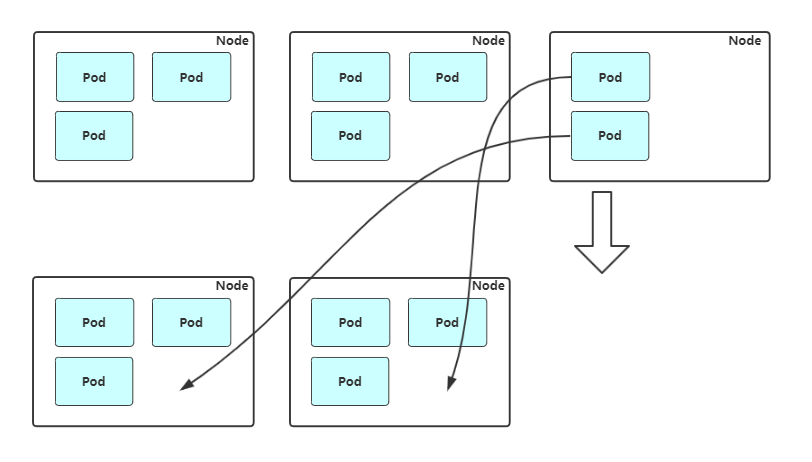
**缩容:**Cluster AutoScaler 也会定期监测 Node 的资源使用情况,当一个 Node 长时间资源利用率都很低时(低于 50%)自动将其所在虚拟机从云服务商中删除。此时,原来的 Pod 会自动调度到其他 Node 上面。
支持的云提供商:
- 阿里云:https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/alicloud/README.md
- AWS: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/aws/README.md
- Azure: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/cloudprovider/azure/README.md
3.2 Ansible扩容Node

- 触发新增Node
- 调用Ansible脚本部署组件
- 检查服务是否可用
- 调用API将新Node加入集群或者启用Node自动加入
- 观察新Node状态
- 完成Node扩容,接收新Pod
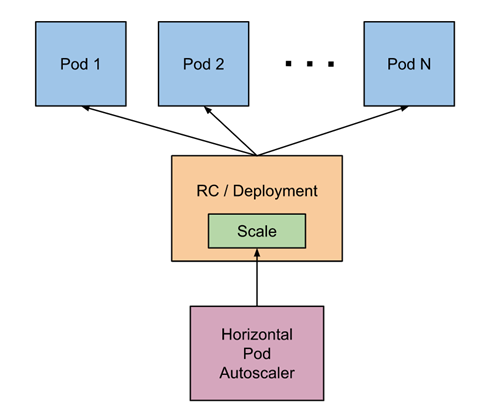
2.4 Pod自动扩容/缩容(HPA)
Horizontal Pod Autoscaler(HPA,Pod水平自动伸缩),根据资源利用率或者自定义指标自动调整replication controller, deployment 或 replica set,实现部署的自动扩展和缩减,让部署的规模接近于实际服务的负载。HPA不适于无法缩放的对象,例如DaemonSet。
1、HPA基本原理
Kubernetes 中的 Metrics Server 持续采集所有 Pod 副本的指标数据。HPA 控制器通过 Metrics Server 的 API(Heapster 的 API 或聚合 API)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标 Pod 副本数量。当目标 Pod 副本数量与当前副本数量不同时,HPA 控制器就向 Pod 的副本控制器(Deployment、RC 或 ReplicaSet)发起 scale 操作,调整 Pod 的副本数量,完成扩缩容操作。如图所示。

在弹性伸缩中,冷却周期是不能逃避的一个话题, 由于评估的度量标准是动态特性,副本的数量可能会不断波动。有时被称为颠簸, 所以在每次做出扩容缩容后,冷却时间是多少。
在 HPA 中,默认的扩容冷却周期是 3 分钟,缩容冷却周期是 5 分钟。
可以通过调整kube-controller-manager组件启动参数设置冷却时间:
- –horizontal-pod-autoscaler-downscale-delay :扩容冷却
- –horizontal-pod-autoscaler-upscale-delay :缩容冷却
2、HPA的演进历程
目前 HPA 已经支持了 autoscaling/v1、autoscaling/v1beta1和autoscaling/v1beta2 三个大版本 。
目前大多数人比较熟悉是autoscaling/v1,这个版本只支持CPU一个指标的弹性伸缩。
而autoscaling/v1beta1增加了支持自定义指标,autoscaling/v1beta2又额外增加了外部指标支持。
而产生这些变化不得不提的是Kubernetes社区对监控与监控指标的认识认识与转变。从早期Heapster到Metrics Server再到将指标边界进行划分,一直在丰富监控生态。
示例:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
kind: AverageUtilization
averageUtilization: 50
- type: Pods
pods:
metric:
name: packets-per-second
targetAverageValue: 1k
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: extensions/v1beta1
kind: Ingress
name: main-route
target:
kind: Value
value: 10k- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2.5 基于CPU指标缩放
1、 Kubernetes API Aggregation
在 Kubernetes 1.7 版本引入了聚合层,允许第三方应用程序通过将自己注册到kube-apiserver上,仍然通过 API Server 的 HTTP URL 对新的 API 进行访问和操作。为了实现这个机制,Kubernetes 在 kube-apiserver 服务中引入了一个 API 聚合层(API Aggregation Layer),用于将扩展 API 的访问请求转发到用户服务的功能。
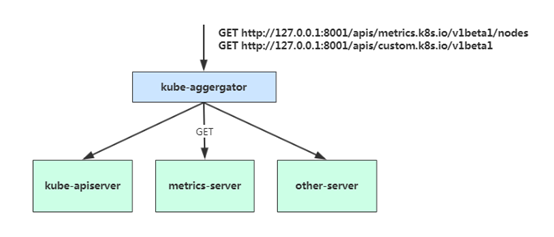
当你访问 apis/metrics.k8s.io/v1beta1 的时候,实际上访问到的是一个叫作 kube-aggregator 的代理。而 kube-apiserver,正是这个代理的一个后端;而 Metrics Server,则是另一个后端 。通过这种方式,我们就可以很方便地扩展 Kubernetes 的 API 了。
如果你使用kubeadm部署的,默认已开启。如果你使用二进制方式部署的话,需要在kube-APIServer中添加启动参数,增加以下配置:
# vi /opt/kubernetes/cfg/kube-apiserver.conf
...
--requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \
--proxy-client-cert-file=/opt/kubernetes/ssl/server.pem \
--proxy-client-key-file=/opt/kubernetes/ssl/server-key.pem \
--requestheader-allowed-names=kubernetes \
--requestheader-extra-headers-prefix=X-Remote-Extra- \
--requestheader-group-headers=X-Remote-Group \
--requestheader-username-headers=X-Remote-User \
--enable-aggregator-routing=true \
...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在设置完成重启 kube-apiserver 服务,就启用 API 聚合功能了。
2、部署 Metrics Server
Metrics Server是一个集群范围的资源使用情况的数据聚合器。作为一个应用部署在集群中。
Metric server从每个节点上Kubelet公开的摘要API收集指标。
Metrics server通过Kubernetes聚合器注册在Master APIServer中。
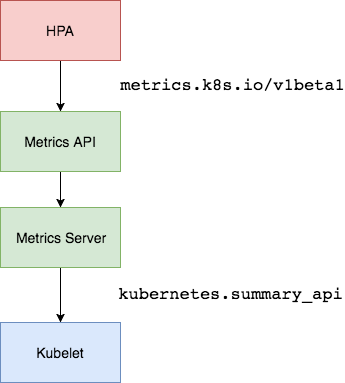
# git clone https://github.com/kubernetes-incubator/metrics-server
# cd metrics-server/deploy/1.8+/
# vi metrics-server-deployment.yaml # 添加2条启动参数
...
containers:
- name: metrics-server
image: lizhenliang/metrics-server-amd64:v0.3.1
command:
- /metrics-server
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
...
# kubectl create -f .- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
可通过Metrics API在Kubernetes中获得资源使用率指标,例如容器CPU和内存使用率。这些度量标准既可以由用户直接访问(例如,通过使用kubectl top命令),也可以由集群中的控制器(例如,Horizontal Pod Autoscaler)用于进行决策。
测试:
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes
kubectl top node- 1
- 2
3、autoscaling/v1(CPU指标实践)
autoscaling/v1版本只支持CPU一个指标。
首先部署一个应用:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 1
selector:
matchLabels:
app: nginx-php
template:
metadata:
labels:
app: nginx-php
spec:
containers:
- image: lizhenliang/nginx-php
name: java
resources:
requests:
memory: "300Mi"
cpu: "250m"
---
apiVersion: v1
kind: Service
metadata:
name: web
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx-php- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
创建HPA策略:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: web
spec:
maxReplicas: 5
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web
targetCPUUtilizationPercentage: 60- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
scaleTargetRef:表示当前要伸缩对象是谁
targetCPUUtilizationPercentage:当整体的资源利用率超过50%的时候,会进行扩容。
开启压测:
yum install httpd-tools
ab -n 100000 -c 100 http://10.1.206.176/status.php- 1
- 2
10.0.0.147 为ClusterIP。
检查扩容状态:
kubectl get hpa
kubectl top pods
kubectl get pods- 1
- 2
- 3
关闭压测,过一会检查缩容状态。
4、autoscaling/v2beta2(多指标)
为满足更多的需求, HPA 还有 autoscaling/v2beta1和 autoscaling/v2beta2两个版本。
这两个版本的区别是 autoscaling/v1beta1支持了 Resource Metrics(CPU)和 Custom Metrics(应用程序指标),而在 autoscaling/v2beta2的版本中额外增加了 External Metrics的支持。
kubectl get hpa.v2beta2.autoscaling -o yaml > /tmp/hpa-v2.yaml- 1
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: web
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web
minReplicas: 1
maxReplicas: 10
metrics:
- resource:
type: Resource
name: cpu
target:
averageUtilization: 60
type: Utilization- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
与上面v1版本效果一样,只不过这里格式有所变化。
v2还支持其他另种类型的度量指标,:Pods和Object。
type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k- 1
- 2
- 3
- 4
- 5
- 6
- 7
type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 2k- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
metrics中的type字段有四种类型的值:Object、Pods、Resource、External。
-
Resource:指的是当前伸缩对象下的pod的cpu和memory指标,只支持Utilization和AverageValue类型的目标值。
-
Object:指的是指定k8s内部对象的指标,数据需要第三方adapter提供,只支持Value和AverageValue类型的目标值。
-
Pods:指的是伸缩对象Pods的指标,数据需要第三方的adapter提供,只允许AverageValue类型的目标值。
-
External:指的是k8s外部的指标,数据同样需要第三方的adapter提供,只支持Value和AverageValue类型的目标值。
# hpa-v2.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: web
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
- type: Pods
pods:
metric:
name: packets-per-second
target:
type: AverageValue
averageValue: 1k
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
name: main-route
target:
type: Value
value: 10k- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
2.6 基于Prometheus自定义指标缩放
资源指标只包含CPU、内存,一般来说也够了。但如果想根据自定义指标:如请求qps/5xx错误数来实现HPA,就需要使用自定义指标了,目前比较成熟的实现是 Prometheus Custom Metrics。自定义指标由Prometheus来提供,再利用k8s-prometheus-adpater聚合到apiserver,实现和核心指标(metric-server)同样的效果。
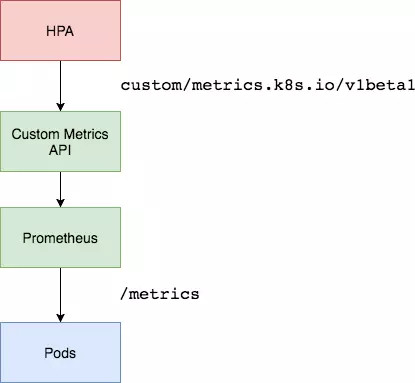
1、部署Prometheus
Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016年加入云原生云计算基金会(CNCF),成为继Kubernetes之后的第二个托管项目。
Prometheus 特点:
-
多维数据模型:由度量名称和键值对标识的时间序列数据
-
PromSQL:一种灵活的查询语言,可以利用多维数据完成复杂的查询
-
不依赖分布式存储,单个服务器节点可直接工作
-
基于HTTP的pull方式采集时间序列数据
-
推送时间序列数据通过PushGateway组件支持
-
通过服务发现或静态配置发现目标
-
多种图形模式及仪表盘支持(grafana)
Prometheus组成及架构:

-
Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
-
ClientLibrary:客户端库
-
Push Gateway:短期存储指标数据。主要用于临时性的任务
-
Exporters:采集已有的第三方服务监控指标并暴露metrics
-
Alertmanager:告警
-
Web UI:简单的Web控制台
部署:
# cd prometheus-k8s
# kubectl apply -f .
# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
kube-state-metrics-7f7cfc4f54-xjnk7 2/2 Running 0 10m
metrics-server-7dbbcf4c7-8m8x9 1/1 Running 0 10m
prometheus-0 2/2 Running 0 10m
# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-state-metrics ClusterIP 10.1.243.160 <none> 8080/TCP,8081/TCP 3d6h
metrics-server ClusterIP 10.1.56.84 <none> 443/TCP 13h
prometheus NodePort 10.1.36.8 <none> 9090:30090/TCP 10m- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
访问Prometheus UI:http://NdeIP:30090
2、 部署 Custom Metrics Adapter
但是prometheus采集到的metrics并不能直接给k8s用,因为两者数据格式不兼容,还需要另外一个组件(k8s-prometheus-adpater),将prometheus的metrics 数据格式转换成k8s API接口能识别的格式,转换以后,因为是自定义API,所以还需要用Kubernetes aggregator在主APIServer中注册,以便直接通过/apis/来访问。
https://github.com/DirectXMan12/k8s-prometheus-adapter
该 PrometheusAdapter 有一个稳定的Helm Charts,我们直接使用。
先准备下helm环境:
wget https://get.helm.sh/helm-v3.0.0-linux-amd64.tar.gz
tar zxvf helm-v3.0.0-linux-amd64.tar.gz
mv linux-amd64/helm /usr/bin/
helm repo add stable http://mirror.azure.cn/kubernetes/charts
helm repo update
helm repo list- 1
- 2
- 3
- 4
- 5
- 6
部署prometheus-adapter,指定prometheus地址:
# helm install prometheus-adapter stable/prometheus-adapter --namespace kube-system --set prometheus.url=http://prometheus.kube-system,prometheus.port=9090
# helm list -n kube-system- 1
- 2
# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
prometheus-adapter-77b7b4dd8b-ktsvx 1/1 Running 0 9m- 1
- 2
- 3
验证,确保适配器注册到APIServer:
# kubectl get apiservices |grep custom
# kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1"- 1
- 2
3、基于QPS指标实践
部署一个应用:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: metrics-app
name: metrics-app
spec:
replicas: 3
selector:
matchLabels:
app: metrics-app
template:
metadata:
labels:
app: metrics-app
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "80"
prometheus.io/path: "/metrics"
spec:
containers:
- image: lizhenliang/metrics-app
name: metrics-app
ports:
- name: web
containerPort: 80
resources:
requests:
cpu: 200m
memory: 256Mi
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 3
periodSeconds: 5
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 3
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: metrics-app
labels:
app: metrics-app
spec:
ports:
- name: web
port: 80
targetPort: 80
selector:
app: metrics-app- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
该metrics-app暴露了一个Prometheus指标接口,可以通过访问service看到:
# curl 10.1.181.193/metrics
# HELP http_requests_total The amount of requests in total
# TYPE http_requests_total counter
http_requests_total 115006
# HELP http_requests_per_second The amount of requests per second the latest ten seconds
# TYPE http_requests_per_second gauge
http_requests_per_second 0.5- 1
- 2
- 3
- 4
- 5
- 6
- 7
创建HPA策略:
# vi app-hpa-v2.yml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: metrics-app-hpa
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: metrics-app
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: http_requests_per_second
target:
type: AverageValue
averageValue: 800m # 800m 即0.8个/秒- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
这里使用Prometheus提供的指标测试来测试自定义指标(QPS)的自动缩放。
4、配置适配器收集特定的指标
当创建好HPA还没结束,因为适配器还不知道你要什么指标(http_requests_per_second),HPA也就获取不到Pod提供指标。
ConfigMap在default名称空间中编辑prometheus-adapter ,并seriesQuery在该rules: 部分的顶部添加一个新的:
# kubectl edit cm prometheus-adapter -n kube-system
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: prometheus-adapter
chart: prometheus-adapter-v0.1.2
heritage: Tiller
release: prometheus-adapter
name: prometheus-adapter
data:
config.yaml: |
rules:
- seriesQuery: 'http_requests_total{kubernetes_namespace!="",kubernetes_pod_name!=""}'
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}
name:
matches: "^(.*)_total"
as: "${1}_per_second"
metricsQuery: 'sum(rate(<<.Series>>{<<.LabelMatchers>>}[2m])) by (<<.GroupBy>>)'
...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
该规则将http_requests在2分钟的间隔内收集该服务的所有Pod的平均速率。
测试API:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests_per_second"- 1
压测:
ab -n 100000 -c 100 http://10.1.181.193/metrics- 1
查看HPA状态:
kubectl get hpa
kubectl describe hpa metrics-app-hpa- 1
- 2
小结
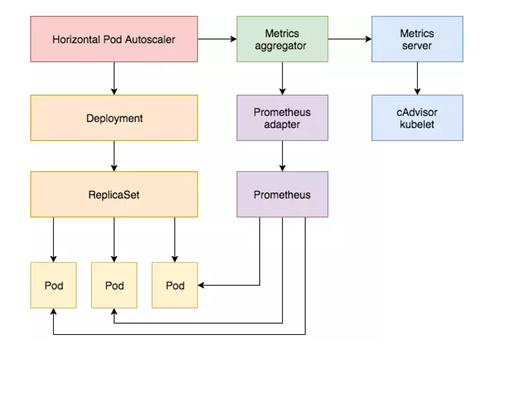
- 通过/metrics收集每个Pod的http_request_total指标;
- prometheus将收集到的信息汇总;
- APIServer定时从Prometheus查询,获取request_per_second的数据;
- HPA定期向APIServer查询以判断是否符合配置的autoscaler规则;
- 如果符合autoscaler规则,则修改Deployment的ReplicaSet副本数量进行伸缩。
三、Helm应用包管理器
3.1 为什么需要Helm?
K8S上的应用对象,都是由特定的资源描述组成,包括deployment、service等。都保存各自文件中或者集中写到一个配置文件。然后kubectl apply –f 部署。

如果应用只由一个或几个这样的服务组成,上面部署方式足够了。
而对于一个复杂的应用,会有很多类似上面的资源描述文件,例如微服务架构应用,组成应用的服务可能多达十个,几十个。如果有更新或回滚应用的需求,可能要修改和维护所涉及的大量资源文件,而这种组织和管理应用的方式就显得力不从心了。
且由于缺少对发布过的应用版本管理和控制,使Kubernetes上的应用维护和更新等面临诸多的挑战,主要面临以下问题:
- 如何将这些服务作为一个整体管理
- 这些资源文件如何高效复用
- 不支持应用级别的版本管理
3.2 Helm 介绍
Helm是一个Kubernetes的包管理工具,就像Linux下的包管理器,如yum/apt等,可以很方便的将之前打包好的yaml文件部署到kubernetes上。
Helm有两个重要概念:
-
**helm:**一个命令行客户端工具,主要用于Kubernetes应用chart的创建、打包、发布和管理。
-
**Chart:**应用描述,一系列用于描述 k8s 资源相关文件的集合。
-
**Release:**基于Chart的部署实体,一个 chart 被 Helm 运行后将会生成对应的一个 release;将在k8s中创建出真实运行的资源对象。
3.3 Helm v3 变化
2019年11月13日, Helm团队发布 Helm v3 的第一个稳定版本。
该版本主要变化如下:
1、 架构变化
最明显的变化是 Tiller 的删除
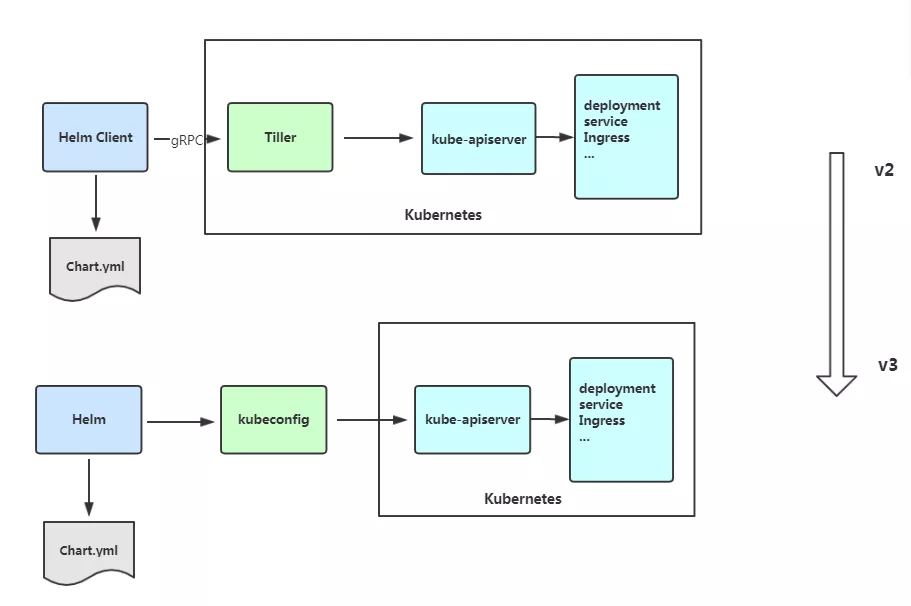
2、Release名称可以在不同命名空间重用
3、支持将 Chart 推送至 Docker 镜像仓库中
4、使用JSONSchema验证chart values
5、其他
1)为了更好地协调其他包管理者的措辞 Helm CLI 个别更名
helm delete` 更名为 `helm uninstall
helm inspect` 更名为 `helm show
helm fetch` 更名为 `helm pull- 1
- 2
- 3
但以上旧的命令当前仍能使用。
2)移除了用于本地临时搭建 Chart Repository 的 helm serve 命令。
3)自动创建名称空间
在不存在的命名空间中创建发行版时,Helm 2创建了命名空间。Helm 3遵循其他Kubernetes对象的行为,如果命名空间不存在则返回错误。
4) 不再需要requirements.yaml, 依赖关系是直接在chart.yaml中定义。
3.4 Helm客户端
1、部署Helm客户端
Helm客户端下载地址:https://github.com/helm/helm/releases
解压移动到/usr/bin/目录即可。
wget https://get.helm.sh/helm-v3.0.0-linux-amd64.tar.gz
tar zxvf helm-v3.0.0-linux-amd64.tar.gz
mv linux-amd64/helm /usr/bin/- 1
- 2
- 3
2、Helm常用命令
| 命令 | 描述 |
|---|---|
| create | 创建一个chart并指定名字 |
| dependency | 管理chart依赖 |
| get | 下载一个release。可用子命令:all、hooks、manifest、notes、values |
| history | 获取release历史 |
| install | 安装一个chart |
| list | 列出release |
| package | 将chart目录打包到chart存档文件中 |
| pull | 从远程仓库中下载chart并解压到本地 # helm pull stable/mysql --untar |
| repo | 添加,列出,移除,更新和索引chart仓库。可用子命令:add、index、list、remove、update |
| rollback | 从之前版本回滚 |
| search | 根据关键字搜索chart。可用子命令:hub、repo |
| show | 查看chart详细信息。可用子命令:all、chart、readme、values |
| status | 显示已命名版本的状态 |
| template | 本地呈现模板 |
| uninstall | 卸载一个release |
| upgrade | 更新一个release |
| version | 查看helm客户端版本 |
3、配置国内Chart仓库
- 微软仓库(http://mirror.azure.cn/kubernetes/charts/)这个仓库强烈推荐,基本上官网有的chart这里都有。
- 阿里云仓库(https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts )
- 官方仓库(https://hub.kubeapps.com/charts/incubator)官方chart仓库,国内有点不好使。
添加存储库:
helm repo add stable http://mirror.azure.cn/kubernetes/charts
helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
helm repo update- 1
- 2
- 3
查看配置的存储库:
helm repo list
helm search repo stable- 1
- 2
一直在stable存储库中安装charts,你可以配置其他存储库。
删除存储库:
helm repo remove aliyun- 1
3.5 Helm基本使用
主要介绍三个命令:
-
chart install
-
chart update
-
chart rollback
1、使用chart部署一个应用
查找chart:
# helm search repo
# helm search repo mysql- 1
- 2
为什么mariadb也在列表中?因为他和mysql有关。
查看chart信息:
# helm show chart stable/mysql- 1
安装包:
# helm install db stable/mysql- 1
查看发布状态:
# helm status db- 1
2、安装前自定义chart配置选项
上面部署的mysql并没有成功,这是因为并不是所有的chart都能按照默认配置运行成功,可能会需要一些环境依赖,例如PV。
所以我们需要自定义chart配置选项,安装过程中有两种方法可以传递配置数据:
- –values(或-f):指定带有覆盖的YAML文件。这可以多次指定,最右边的文件优先
- –set:在命令行上指定替代。如果两者都用,–set优先级高
–values使用,先将修改的变量写到一个文件中
# helm show values stable/mysql
# cat config.yaml
persistence:
enabled: true
storageClass: "managed-nfs-storage"
accessMode: ReadWriteOnce
size: 8Gi
mysqlUser: "k8s"
mysqlPassword: "123456"
mysqlDatabase: "k8s"
# helm install db -f config.yaml stable/mysql
# kubectl get pods
NAME READY STATUS RESTARTS AGE
db-mysql-57485b68dc-4xjhv 1/1 Running 0 8m51s- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
以上将创建具有名称的默认MySQL用户k8s,并授予此用户访问新创建的k8s数据库的权限,但将接受该图表的所有其余默认值。
命令行替代变量:
# helm install db --set persistence.storageClass="managed-nfs-storage" stable/mysql- 1
也可以把chart包下载下来查看详情:
# helm pull stable/mysql --untar- 1
values yaml与set使用:

该helm install命令可以从多个来源安装:
- chart存储库
- 本地chart存档(helm install foo-0.1.1.tgz)
- chart目录(helm install path/to/foo)
- 完整的URL(helm install https://example.com/charts/foo-1.2.3.tgz)
3、构建一个Helm Chart
先给学员自动生成目录讲解,然后再手动给学员创建目录和各个文件。
# helm create mychart
Creating mychart
# tree mychart/
mychart/
├── charts
├── Chart.yaml
├── templates
│ ├── deployment.yaml
│ ├── _helpers.tpl
│ ├── ingress.yaml
│ ├── NOTES.txt
│ └── service.yaml
└── values.yaml- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- Chart.yaml:用于描述这个 Chart的基本信息,包括名字、描述信息以及版本等。
- values.yaml :用于存储 templates 目录中模板文件中用到变量的值。
- Templates: 目录里面存放所有yaml模板文件。
- charts:目录里存放这个chart依赖的所有子chart。
- NOTES.txt :用于介绍Chart帮助信息, helm install 部署后展示给用户。例如:如何使用这个 Chart、列出缺省的设置等。
- _helpers.tpl:放置模板助手的地方,可以在整个 chart 中重复使用
创建Chart后,接下来就是将其部署:
helm install web mychart/- 1
也可以打包推送的charts仓库共享别人使用。
# helm package mychart/
mychart-0.1.0.tgz- 1
- 2
4、升级、回滚和删除
发布新版本的chart时,或者当您要更改发布的配置时,可以使用该helm upgrade 命令。
# helm upgrade --set imageTag=1.17 web mychart
# helm upgrade -f values.yaml web mychart- 1
- 2
如果在发布后没有达到预期的效果,则可以使用helm rollback 回滚到之前的版本。
例如将应用回滚到第一个版本:
# helm rollback web 2- 1
卸载发行版,请使用以下helm uninstall命令:
# helm uninstall web- 1
查看历史版本配置信息
# helm get --revision 1 web- 1
3.6 Chart模板
Helm最核心的就是模板,即模板化的K8S manifests文件。
它本质上就是一个Go的template模板。Helm在Go template模板的基础上,还会增加很多东西。如一些自定义的元数据信息、扩展的库以及一些类似于编程形式的工作流,例如条件语句、管道等等。这些东西都会使得我们的模板变得更加丰富。
1、模板
有了模板,我们怎么把我们的配置融入进去呢?用的就是这个values文件。这两部分内容其实就是chart的核心功能。
# rm -rf mychart/templates/*
# vi templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1.16
name: nginx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
实际上,这已经是一个可安装的Chart包了,通过 helm install命令来进行安装:
# helm install web mychart- 1
这样部署,其实与直接apply没什么两样。
然后使用如下命令可以看到实际的模板被渲染过后的资源文件:
# helm get manifest web- 1
可以看到,这与刚开始写的内容是一样的,包括名字、镜像等,我们希望能在一个地方统一定义这些会经常变换的字段,这就需要用到Chart的模板了。
# vi templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1.16
name: nginx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这个deployment就是一个Go template的模板,这里定义的Release模板对象属于Helm内置的一种对象,是从values文件中读取出来的。这样一来,我们可以将需要变化的地方都定义变量。
再执行helm install chart 可以看到现在生成的名称变成了web-deployment,证明已经生效了。也可以使用命令helm get manifest查看最终生成的文件内容。
2、调试
Helm也提供了--dry-run --debug调试参数,帮助你验证模板正确性。在执行helm install时候带上这两个参数就可以把对应的values值和渲染的资源清单打印出来,而不会真正的去部署一个release。
比如我们来调试上面创建的 chart 包:
# helm install web2 --dry-run /root/mychart- 1
3、内置对象
刚刚我们使用 {{.Release.Name}}将 release 的名称插入到模板中。这里的 Release 就是 Helm 的内置对象,下面是一些常用的内置对象:
| Release.Name | release 名称 |
|---|---|
| Release.Time | release 的时间 |
| Release.Namespace | release 的 namespace(如果清单未覆盖) |
| Release.Service | release 服务的名称 |
| Release.Revision | 此 release 的修订版本号,从1开始累加 |
| Release.IsUpgrade | 如果当前操作是升级或回滚,则将其设置为 true。 |
| Release.IsInstall | 如果当前操作是安装,则设置为 true。 |
4、Values
Values对象是为Chart模板提供值,这个对象的值有4个来源:
-
chart 包中的 values.yaml 文件
-
父 chart 包的 values.yaml 文件
-
通过 helm install 或者 helm upgrade 的
-f或者--values参数传入的自定义的 yaml 文件 -
通过
--set参数传入的值
chart 的 values.yaml 提供的值可以被用户提供的 values 文件覆盖,而该文件同样可以被 --set提供的参数所覆盖。
这里我们来重新编辑 mychart/values.yaml 文件,将默认的值全部清空,然后添加一个副本数:
# cat values.yaml
replicas: 3
image: "nginx"
imageTag: "1.17"
# cat templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-deployment
spec:
replicas: {{ .Values.replicas }}
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: {{ .Values.image }}:{{ .Values.imageTag }}
name: nginx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
查看渲染结果:
# helm install --dry-run web ../mychart/- 1
values 文件也可以包含结构化内容,例如:
# cat values.yaml
...
label:
project: ms
app: nginx
# cat templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-deployment
spec:
replicas: {{ .Values.replicas }}
selector:
matchLabels:
project: {{ .Values.label.project }}
app: {{ .Values.label.app }}
template:
metadata:
labels:
project: {{ .Values.label.project }}
app: {{ .Values.label.app }}
spec:
containers:
- image: {{ .Values.image }}:{{ .Values.imageTag }}
name: nginx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
查看渲染结果:
# helm install --dry-run web ../mychart/- 1
5、管道与函数
前面讲的模块,其实就是将值传给模板引擎进行渲染,模板引擎还支持对拿到数据进行二次处理。
例如从.Values中读取的值变成字符串,可以使用quote函数实现:
# vi templates/deployment.yaml
app: {{ quote .Values.label.app }}
# helm install --dry-run web ../mychart/
project: ms
app: "nginx"- 1
- 2
- 3
- 4
- 5
quote .Values.label.app 将后面的值作为参数传递给quote函数。
模板函数调用语法为:functionName arg1 arg2…
另外还会经常使用一个default函数,该函数允许在模板中指定默认值,以防止该值被忽略掉。
例如忘记定义,执行helm install 会因为缺少字段无法创建资源,这时就可以定义一个默认值。
# cat values.yaml
replicas: 2
# cat templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-deployment- 1
- 2
- 3
- 4
- 5
- 6
- 7
- name: {{ .Values.name | default "nginx" }}- 1
其他函数:
缩进:{{ .Values.resources | indent 12 }}
大写:{{ upper .Values.resources }}
首字母大写:{{ title .Values.resources }}
6、流程控制
流程控制是为模板提供了一种能力,满足更复杂的数据逻辑处理。
Helm模板语言提供以下流程控制语句:
if/else条件块with指定范围range循环块
if
if/else块是用于在模板中有条件地包含文本块的方法,条件块的基本结构如下:
{{ if PIPELINE }}
# Do something
{{ else if OTHER PIPELINE }}
# Do something else
{{ else }}
# Default case
{{ end }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
条件判断就是判断条件是否为真,如果值为以下几种情况则为false:
-
一个布尔类型的
假 -
一个数字
零 -
一个
空的字符串 -
一个
nil(空或null) -
一个空的集合(
map、slice、tuple、dict、array)
除了上面的这些情况外,其他所有条件都为 真。
例如,如果.Values.env.hello值为world,则值为hello: true
# cat values.yaml
replicas: 2
label:
project: ms
app: product
env:
hello: "world"- 1
- 2
- 3
- 4
- 5
- 6
- 7
# cat templates/deploymemt.yaml
env:
{{ if eq .Values.env.hello "world" }}
- name: hello
value: 123
{{ end }}- 1
- 2
- 3
- 4
- 5
- 6
其中运算符 eq是判断是否相等的操作,除此之外,还有 ne、 lt、 gt、 and、 or等运算符。
通过模板引擎来渲染一下,会得到如下结果:
# helm install --dry-run web ../mychart/
...
env:
- name: hello
value: 123- 1
- 2
- 3
- 4
- 5
- 6
可以看到渲染出来会有多余的空行,这是因为当模板引擎运行时,会将控制指令删除,所有之前占的位置也就空白了,需要使用{{- if …}} 的方式消除此空行:
# cat templates/deploymemt.yaml
...
env:
{{- if eq .Values.env.hello "world" }}
- name: hello
value: 123
{{- end }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
现在是不是没有多余的空格了,如果使用-}}需谨慎,比如上面模板文件中:
# cat templates/deploymemt.yaml
...
env:
{{- if eq .Values.env.hello "world" -}}
- hello: true
{{- end }}- 1
- 2
- 3
- 4
- 5
- 6
这会渲染成:
env:- hello: true- 1
因为-}}它删除了双方的换行符。
with
with :控制变量作用域。
其语法和一个简单的 if语句比较类似:
{{ with PIPELINE }}
# restricted scope
{{ end }}- 1
- 2
- 3
with语句可以允许将当前范围 .设置为特定的对象,比如我们前面一直使用的 .Values.label,我们可以使用 with来将 .范围指向 .Values.label:
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Values.name | default "web" }}
spec:
replicas: {{ .Values.replicas }}
selector:
matchLabels:
project: {{ .Values.label.project }}
app: {{ .Values.label.app }}
template:
metadata:
labels:
project: {{ .Values.label.project }}
app: {{ .Values.label.app }}
{{- with .Values.label }}
project: {{ .project }}
app: {{ .app }}
{{- end }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
上面增加了一个{{- with .Values.label }} xxx {{- end }}的一个块,这样的话就可以在当前的块里面直接引用 .project和 .app了。
需要注意的在 with声明的范围内,将无法从父范围访问到其他对象了,比如:
{{- with .Values.label }}
project: {{ .project }}
app: {{ .app }}
{{ .Release.Name }}
{{- end }}- 1
- 2
- 3
- 4
- 5
range
在 Helm 模板语言中,使用 range关键字来进行循环操作。
我们在 values.yaml文件中添加上一个变量列表:
# cat values.yaml
replicas: 2
label:
project: ms
app: product
env:
hello: "world"
test: "yes"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
循环打印该列表:
env:
{{- range .Values.env }}
{{ . }}
{{- end }}- 1
- 2
- 3
- 4
循环内部我们使用的是一个 .,这是因为当前的作用域就在当前循环内,这个 .引用的当前读取的元素。
但结果并不是我们所期望的:
env:
- name: world
value: world- 1
- 2
- 3
3.6 Chart模板
Helm最核心的就是模板,即模板化的K8S manifests文件。
它本质上就是一个Go的template模板。Helm在Go template模板的基础上,还会增加很多东西。如一些自定义的元数据信息、扩展的库以及一些类似于编程形式的工作流,例如条件语句、管道等等。这些东西都会使得我们的模板变得更加丰富。
1、模板
有了模板,我们怎么把我们的配置融入进去呢?用的就是这个values文件。这两部分内容其实就是chart的核心功能。
接下来,部署nginx应用,熟悉模板使用,先把templates 目录下面所有文件全部删除掉,这里我们自己来创建模板文件:
# rm -rf mychart/templates/*
# vi templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1.16
name: nginx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
实际上,这已经是一个可安装的Chart包了,通过 helm install命令来进行安装:
# helm install web mychart- 1
这样部署,其实与直接apply没什么两样。
然后使用如下命令可以看到实际的模板被渲染过后的资源文件:
# helm get manifest web- 1
可以看到,这与刚开始写的内容是一样的,包括名字、镜像等,我们希望能在一个地方统一定义这些会经常变换的字段,这就需要用到Chart的模板了。
# vi templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1.16
name: nginx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这个deployment就是一个Go template的模板,这里定义的Release模板对象属于Helm内置的一种对象,是从values文件中读取出来的。这样一来,我们可以将需要变化的地方都定义变量。
再执行helm install chart 可以看到现在生成的名称变成了web-deployment,证明已经生效了。也可以使用命令helm get manifest查看最终生成的文件内容。
2、调试
Helm也提供了--dry-run --debug调试参数,帮助你验证模板正确性。在执行helm install时候带上这两个参数就可以把对应的values值和渲染的资源清单打印出来,而不会真正的去部署一个release。
比如我们来调试上面创建的 chart 包:
# helm install web2 --dry-run /root/mychart- 1
3、内置对象
刚刚我们使用 {{.Release.Name}}将 release 的名称插入到模板中。这里的 Release 就是 Helm 的内置对象,下面是一些常用的内置对象:
| Release.Name | release 名称 |
|---|---|
| Release.Name | release 名字 |
| Release.Namespace | release 命名空间 |
| Release.Service | release 服务的名称 |
| Release.Revision | release 修订版本号,从1开始累加 |
4、Values
Values对象是为Chart模板提供值,这个对象的值有4个来源:
-
chart 包中的 values.yaml 文件
-
父 chart 包的 values.yaml 文件
-
通过 helm install 或者 helm upgrade 的
-f或者--values参数传入的自定义的 yaml 文件 -
通过
--set参数传入的值
chart 的 values.yaml 提供的值可以被用户提供的 values 文件覆盖,而该文件同样可以被 --set提供的参数所覆盖。
这里我们来重新编辑 mychart/values.yaml 文件,将默认的值全部清空,然后添加一个副本数:
# cat values.yaml
replicas: 3
image: "nginx"
imageTag: "1.17"
# cat templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-deployment
spec:
replicas: {{ .Values.replicas }}
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: {{ .Values.image }}:{{ .Values.imageTag }}
name: nginx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
查看渲染结果:
# helm install --dry-run web ../mychart/- 1
values 文件也可以包含结构化内容,例如:
# cat values.yaml
...
label:
project: ms
app: nginx
# cat templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-deployment
spec:
replicas: {{ .Values.replicas }}
selector:
matchLabels:
project: {{ .Values.label.project }}
app: {{ .Values.label.app }}
template:
metadata:
labels:
project: {{ .Values.label.project }}
app: {{ .Values.label.app }}
spec:
containers:
- image: {{ .Values.image }}:{{ .Values.imageTag }}
name: nginx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
查看渲染结果:
# helm install --dry-run web ../mychart/- 1
5、管道与函数
前面讲的模块,其实就是将值传给模板引擎进行渲染,模板引擎还支持对拿到数据进行二次处理。
例如从.Values中读取的值变成字符串,可以使用quote函数实现:
# vi templates/deployment.yaml
app: {{ quote .Values.label.app }}
# helm install --dry-run web ../mychart/
project: ms
app: "nginx"- 1
- 2
- 3
- 4
- 5
quote .Values.label.app 将后面的值作为参数传递给quote函数。
模板函数调用语法为:functionName arg1 arg2…
另外还会经常使用一个default函数,该函数允许在模板中指定默认值,以防止该值被忽略掉。
例如忘记定义,执行helm install 会因为缺少字段无法创建资源,这时就可以定义一个默认值。
# cat values.yaml
replicas: 2
# cat templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-deployment- 1
- 2
- 3
- 4
- 5
- 6
- 7
- name: {{ .Values.name | default "nginx" }}- 1
其他函数:
缩进:{{ .Values.resources | indent 12 }}
大写:{{ upper .Values.resources }}
首字母大写:{{ title .Values.resources }}
6、流程控制
流程控制是为模板提供了一种能力,满足更复杂的数据逻辑处理。
Helm模板语言提供以下流程控制语句:
if/else条件块with指定范围range循环块
if
if/else块是用于在模板中有条件地包含文本块的方法,条件块的基本结构如下:
{{ if PIPELINE }}
# Do something
{{ else if OTHER PIPELINE }}
# Do something else
{{ else }}
# Default case
{{ end }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例:
# cat values.yaml
devops: k8
# cat templates/deployment.yaml
...
template:
metadata:
labels:
app: nginx
{{ if eq .Values.devops "k8s" }}
devops: 123
{{ else }}
devops: 456
{{ end }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
在上面条件语句使用了eq运算符判断是否相等,除此之外,还支持ne、 lt、 gt、 and、 or等运算符。
通过模板引擎来渲染一下,会得到如下结果:
# helm install --dry-run web ../mychart/
...
labels:
app: nginx
devops: 456- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看到渲染出来会有多余的空行,这是因为当模板引擎运行时,会将控制指令删除,所有之前占的位置也就空白了,需要使用{{- if …}} 的方式消除此空行:
# cat templates/deploymemt.yaml
...
env:
{{- if eq .Values.env.hello "world" }}
- name: hello
value: 123
{{- end }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
现在是不是没有多余的空格了,如果使用-}}需谨慎,比如上面模板文件中:
# cat templates/deploymemt.yaml
...
env:
{{- if eq .Values.env.hello "world" -}}
- hello: true
{{- end }}- 1
- 2
- 3
- 4
- 5
- 6
这会渲染成:
env:- hello: true- 1
因为-}}它删除了双方的换行符。
条件判断就是判断条件是否为真,如果值为以下几种情况则为false:
-
一个布尔类型的
假 -
一个数字
零 -
一个
空的字符串 -
一个
nil(空或null) -
一个空的集合(
map、slice、tuple、dict、array)
除了上面的这些情况外,其他所有条件都为 真。
例如,判断一个空的数组
# cat values.yaml
resources: {}
# limits:
# cpu: 100m
# memory: 128Mi
# requests:
# cpu: 100m
# memory: 128Mi- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
# cat templates/deploymemt.yaml
...
spec:
containers:
- image: nginx:1.16
name: nginx
{{- if .Values.resources }}
resources:
{{ toYaml .Values.resources | indent 10 }}
{{- end }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
例如,判断一个布尔值
# cat values.yaml
service:
type: ClusterIP
port: 80
ingress:
enabled: true
host: example.ctnrs.com
# cat templates/ingress.yaml
{{- if .Values.ingress.enabled -}}
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: {{ .Release.Name }}-ingress
spec:
rules:
- host: {{ .Values.ingress.host }}
http:
paths:
- path: /
backend:
serviceName: {{ .Release.Name }}
servicePort: {{ .Values.service.port }}
{{ end }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
with
with :控制变量作用域。
还记得之前我们的 {{.Release.xxx}}或者 {{.Values.xxx}}吗?其中的 .就是表示对当前范围的引用, .Values就是告诉模板在当前范围中查找 Values对象的值。而 with语句就可以来控制变量的作用域范围,其语法和一个简单的 if语句比较类似:
{{ with PIPELINE }}
# restricted scope
{{ end }}- 1
- 2
- 3
with语句可以允许将当前范围 .设置为特定的对象,比如我们前面一直使用的 .Values.label,我们可以使用 with来将 .范围指向 .Values.label:
# cat values.yaml
...
replicas: 3
label:
project: ms
app: nginx
# cat templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
{{- with .Values.nodeSelector }}
nodeSelector:
team: {{ .team }}
gpu: {{ .gpu }}
{{- end }}
containers:
- image: nginx:1.16
name: nginx- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
优化后:
{{- with .Values.nodeSelector }}
nodeSelector:
{{- toYaml . | nindent 8 }}
{{- end }}- 1
- 2
- 3
- 4
上面增加了一个{{- with .Values.label }} xxx {{- end }}的一个块,这样的话就可以在当前的块里面直接引用 .team和 .gpu了。
with是一个循环构造。使用**.Values.nodeSelector中**的值:将其转换为Yaml。
toYaml之后的点是循环中**.Values.nodeSelector**的当前值
range
在 Helm 模板语言中,使用 range关键字来进行循环操作。
我们在 values.yaml文件中添加上一个变量列表:
# cat values.yaml
test:
- 1
- 2
- 3- 1
- 2
- 3
- 4
- 5
循环打印该列表:
apiVersion: v1
kind: ConfigMap
metadata:
name: {{ .Release.Name }}
data:
test: |
{{- range .Values.test }}
{{ . }}
{{- end }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
循环内部我们使用的是一个 .,这是因为当前的作用域就在当前循环内,这个 .引用的当前读取的元素。
7、变量
接下来学习一个语言中基本的概念:变量,在模板中,使用变量的场合不多,但我们将看到如何使用它来简化代码,并更好地利用with和range。
问题1:获取列表键值
# cat ../values.yaml
env:
NAME: "gateway"
JAVA_OPTS: "-Xmx1G"
# cat deployment.yaml
...
env:
{{- range $k, $v := .Values.env }}
- name: {{ $k }}
value: {{ $v | quote }}
{{- end }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
结果如下:
env:
- name: JAVA_OPTS
value: "-Xmx1G"
- name: NAME
value: "gateway"- 1
- 2
- 3
- 4
- 5
上面在 range循环中使用 $key和 $value两个变量来接收后面列表循环的键和值。
问题2:with中不能使用内置对象
with语句块内不能再 .Release.Name对象,否则报错。
我们可以将该对象赋值给一个变量可以来解决这个问题:
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-deployment
spec:
replicas: {{ .Values.replicas }}
template:
metadata:
labels:
project: {{ .Values.label.project }}
app: {{ quote .Values.label.app }}
{{- with .Values.label }}
project: {{ .project }}
app: {{ .app }}
release: {{ .Release.Name }}
{{- end }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
上面会出错。
{{- $releaseName := .Release.Name -}}
{{- with .Values.label }}
project: {{ .project }}
app: {{ .app }}
release: {{ $releaseName }}
# 或者可以使用$符号,引入全局命名空间
release: {{ $.Release.Name }}
{{- end }}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可以看到在 with语句上面增加了一句 {{-$releaseName:=.Release.Name-}},其中 $releaseName就是后面的对象的一个引用变量,它的形式就是 $name,赋值操作使用 :=,这样 with语句块内部的 $releaseName变量仍然指向的是 .Release.Name
8、命名模板
命名模板:使用define定义,template引入,在templates目录中默认下划线_开头的文件为公共模板(_helpers.tpl)
# cat _helpers.tpl
{{- define "demo.fullname" -}}
{{- .Chart.Name -}}-{{ .Release.Name }}
{{- end -}}
# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ template "demo.fullname" . }}
...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
template指令是将一个模板包含在另一个模板中的方法。但是,template函数不能用于Go模板管道。为了解决该问题,增加include功能。
# cat _helpers.tpl
{{- define "demo.labels" -}}
app: {{ template "demo.fullname" . }}
chart: "{{ .Chart.Name }}-{{ .Chart.Version }}"
release: "{{ .Release.Name }}"
{{- end -}}
# cat deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ include "demo.fullname" . }}
labels:
{{- include "demo.labels" . | nindent 4 }}
...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
上面包含一个名为 demo.labels 的模板,然后将值 . 传递给模板,最后将该模板的输出传递给 nindent 函数。
3.7 开发自己的Chart:Java应用为例
-
先创建模板
helm create demo- 1
-
修改Chart.yaml,Values.yaml,添加常用的变量
-
在templates目录下创建部署镜像所需要的yaml文件,并变量引用yaml里经常变动的字段
3.8 使用Harbor作为Chart仓库
1、启用Harbor的Chart仓库服务
# ./install.sh --with-chartmuseum- 1
启用后,默认创建的项目就带有helm charts功能了。
2、安装push插件
https://github.com/chartmuseum/helm-push
helm plugin install https://github.com/chartmuseum/helm-push- 1
3、添加repo
helm repo add --username admin --password Harbor12345 myrepo http://192.168.31.70/chartrepo/library- 1
4、推送与安装Chart
# helm push mysql-1.4.0.tgz --username=admin --password=Harbor12345 http://192.168.31.70/chartrepo/library
# helm install web --version 1.4.0 myrepo/demo- 1
- 2
四、K8S集群网络
4.1 网络基础知识
1、公司网络架构
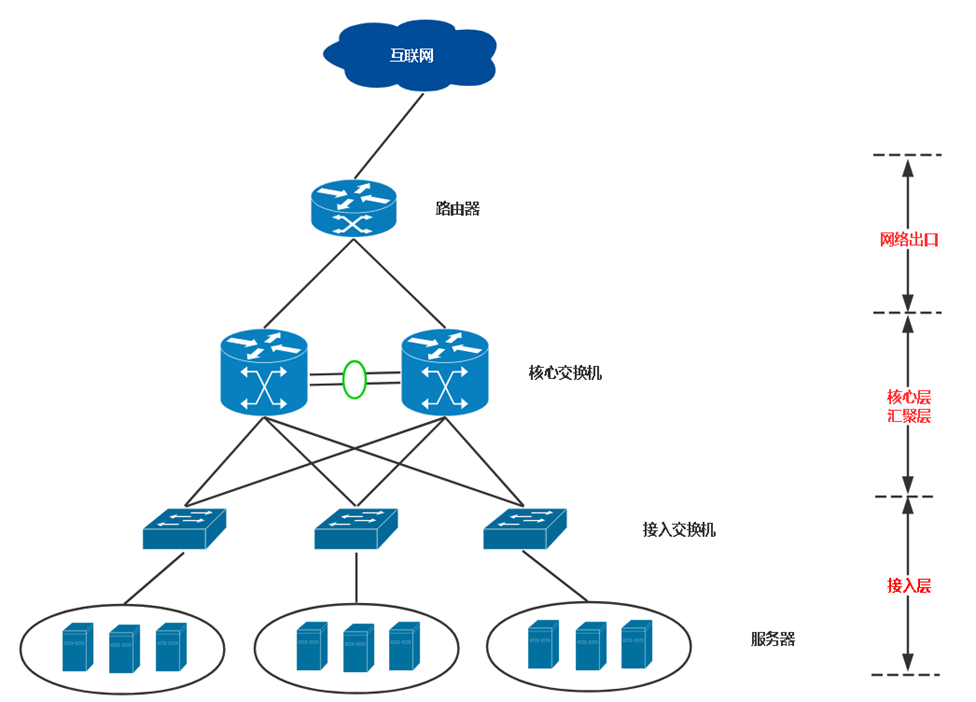
- **路由器:**网络出口
- **核心层:**主要完成数据高效转发、链路备份等
- **汇聚层:**网络策略、安全、工作站交换机的接入、VLAN之间通信等功能
- **接入层:**工作站的接入
2、交换技术
有想过局域网内主机怎么通信的?主机访问外网又是怎么通信的?
想要搞懂这些问题得从交换机、路由器讲起。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kYlgXCTS-1653875525408)(https://s2.loli.net/2022/05/30/6tkSxp7l2a58isM.png)]
交换机工作在OSI参考模型的第二次,即数据链路层。交换机拥有一条高带宽的背部总线交换矩阵,在同一时间可进行多个端口对之间的数据传输。
交换技术分为2层和3层:
-
2层:主要用于小型局域网,仅支持在数据链路层转发数据,对工作站接入。
-
3层:三层交换技术诞生,最初是为了解决广播域的问题,多年发展,三层交换机书已经成为构建中大型网络的主要力量。
广播域
交换机在转发数据时会先进行广播,这个广播可以发送的区域就是一个广播域。交换机之间对广播帧是透明的,所以交换机之间组成的网络是一个广播域。
路由器的一个接口下的网络是一个广播域,所以路由器可以隔离广播域。
ARP(地址解析协议,在IPV6中用NDP替代)
发送这个广播帧是由ARP协议实现,ARP是通过IP地址获取物理地址的一个TCP/IP协议。
三层交换机
前面讲的二层交换机只工作在数据链路层,路由器则工作在网络层。而功能强大的三层交换机可同时工作在数据链路层和网络层,并根据 MAC地址或IP地址转发数据包。
VLAN(Virtual Local Area Network):虚拟局域网
VLAN是一种将局域网设备从逻辑上划分成一个个网段。
一个VLAN就是一个广播域,VLAN之间的通信是通过第3层的路由器来完成的。VLAN应用非常广泛,基本上大部分网络项目都会划分vlan。
VLAN的主要好处:
- 分割广播域,减少广播风暴影响范围。
- 提高网络安全性,根据不同的部门、用途、应用划分不同网段
3、路由技术

路由器主要分为两个端口类型:LAN口和WAN口
-
WAN口:配置公网IP,接入到互联网,转发来自LAN口的IP数据包。
-
LAN口:配置内网IP(网关),连接内部交换机。
路由器是连接两个或多个网络的硬件设备,将从端口上接收的数据包,根据数据包的目的地址智能转发出去。
路由器的功能:
- 路由
- 转发
- 隔离子网
- 隔离广播域
路由器是互联网的枢纽,是连接互联网中各个局域网、广域网的设备,相比交换机来说,路由器的数据转发很复杂,它会根据目的地址给出一条最优的路径。那么路径信息的来源有两种:动态路由和静态路由。
**静态路由:**指人工手动指定到目标主机的地址然后记录在路由表中,如果其中某个节点不可用则需要重新指定。
动态路由:则是路由器根据动态路由协议自动计算出路径永久可用,能实时地适应网络结构的变化。
常用的动态路由协议:
-
RIP( Routing Information Protocol ,路由信息协议)
-
OSPF(Open Shortest Path First,开放式最短路径优先)
-
BGP(Border Gateway Protocol,边界网关协议)
4、OSI七层模型
OSI(Open System Interconnection)是国际标准化组织(ISO)制定的一个用于计算机或通信系统间互联的标准体系,一般称为OSI参考模型或七层模型。
| 层次 | 名称 | 功能 | 协议数据单元(PDU) | 常见协议 |
|---|---|---|---|---|
| 7 | 应用层 | 为用户的应用程序提供网络服务,提供一个接口。 | 数据 | HTTP、FTP、Telnet |
| 6 | 表示层 | 数据格式转换、数据加密/解密 | 数据单元 | ASCII |
| 5 | 会话层 | 建立、管理和维护会话 | 数据单元 | SSH、RPC |
| 4 | 传输层 | 建立、管理和维护端到端的连接 | 段/报文 | TCP、UDP |
| 3 | 网络层 | IP选址及路由选择 | 分组/包 | IP、ICMP、RIP、OSPF |
| 2 | 数据链路层 | 硬件地址寻址,差错效验等。 | 帧 | ARP、WIFI |
| 1 | 物理层 | 利用物理传输介质提供物理连接,传送比特流。 | 比特流 | RJ45、RJ11 |
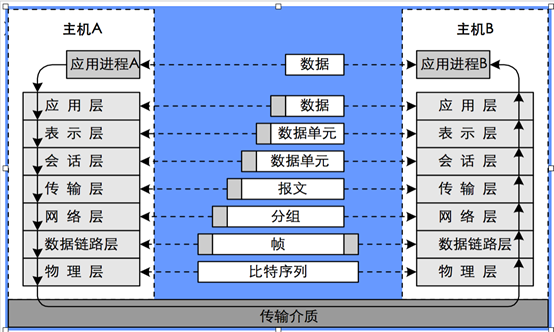
5、TCP/UDP协议
TCP(Transmission Control Protocol,传输控制协议),面向连接协议,双方先建立可靠的连接,再发送数据。适用于传输数据量大,可靠性要求高的应用场景。
UDP(User Data Protocol,用户数据报协议),面向非连接协议,不与对方建立连接,直接将数据包发送给对方。适用于一次只传输少量的数据,可靠性要求低的应用场景。相对TCP传输速度快。
4.2 Kubernetes网络模型
Kubernetes 要求所有的网络插件实现必须满足如下要求:
- 一个Pod一个IP
- 所有的 Pod 可以与任何其他 Pod 直接通信,无需使用 NAT 映射
- 所有节点可以与所有 Pod 直接通信,无需使用 NAT 映射
- Pod 内部获取到的 IP 地址与其他 Pod 或节点与其通信时的 IP 地址是同一个。
1、Docker容器网络模型
先看下Linux网络名词:
-
**网络的命名空间:**Linux在网络栈中引入网络命名空间,将独立的网络协议栈隔离到不同的命令空间中,彼此间无法通信;Docker利用这一特性,实现不同容器间的网络隔离。
-
**Veth设备对:**Veth设备对的引入是为了实现在不同网络命名空间的通信。
-
**Iptables/Netfilter:**Docker使用Netfilter实现容器网络转发。
-
**网桥:**网桥是一个二层网络设备,通过网桥可以将Linux支持的不同的端口连接起来,并实现类似交换机那样的多对多的通信。
-
**路由:**Linux系统包含一个完整的路由功能,当IP层在处理数据发送或转发的时候,会使用路由表来决定发往哪里。
Docker容器网络示意图如下:

2、Pod 网络
**问题:**Pod是K8S最小调度单元,一个Pod由一个容器或多个容器组成,当多个容器时,怎么都用这一个Pod IP?
**实现:**k8s会在每个Pod里先启动一个infra container小容器,然后让其他的容器连接进来这个网络命名空间,然后其他容器看到的网络试图就完全一样了。即网络设备、IP地址、Mac地址等。这就是解决网络共享的一种解法。在Pod的IP地址就是infra container的IP地址。
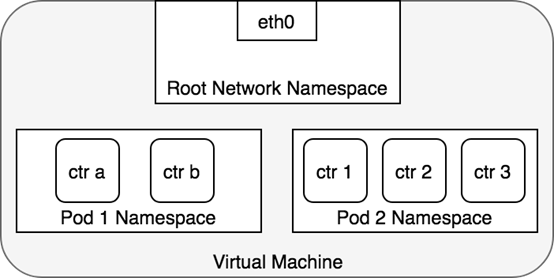
在 Kubernetes 中,每一个 Pod 都有一个真实的 IP 地址,并且每一个 Pod 都可以使用此 IP 地址与 其他 Pod 通信。
Pod之间通信会有两种情况:
- 两个Pod在同一个Node上
- 两个Pod在不同Node上
先看下第一种情况:两个Pod在同一个Node上
同节点Pod之间通信道理与Docker网络一样的,如下图:
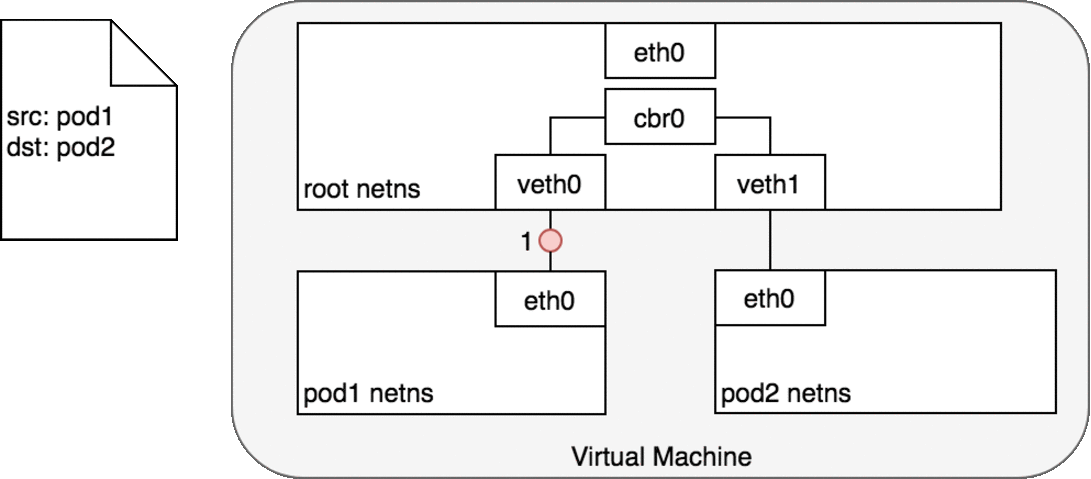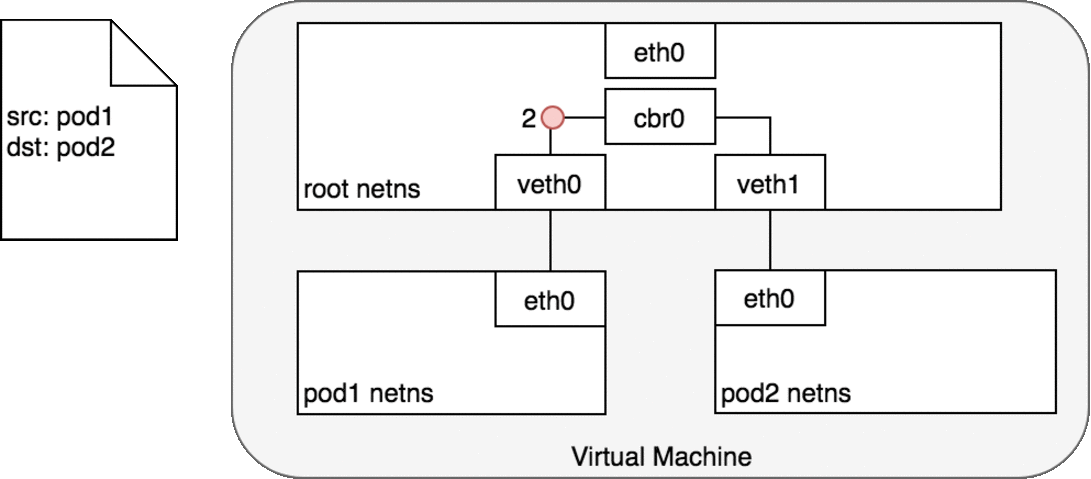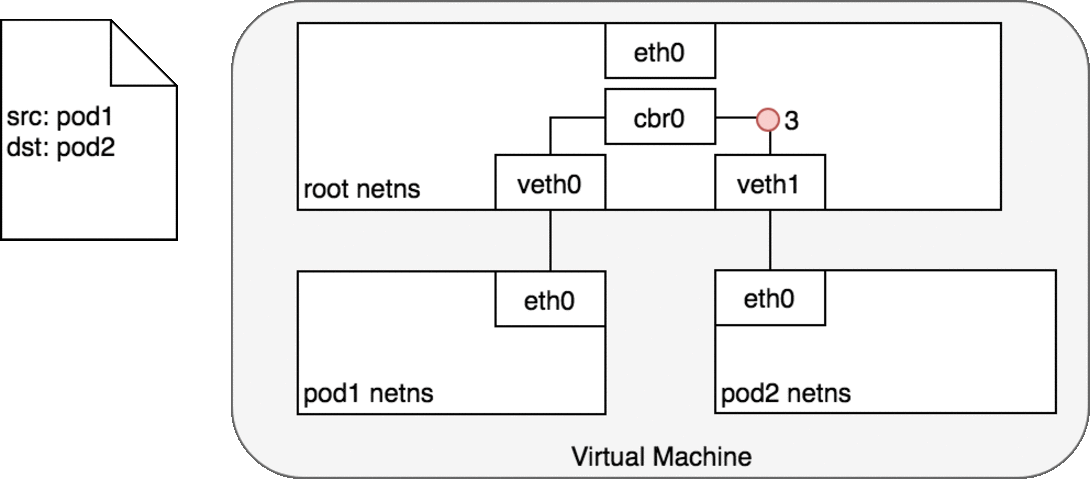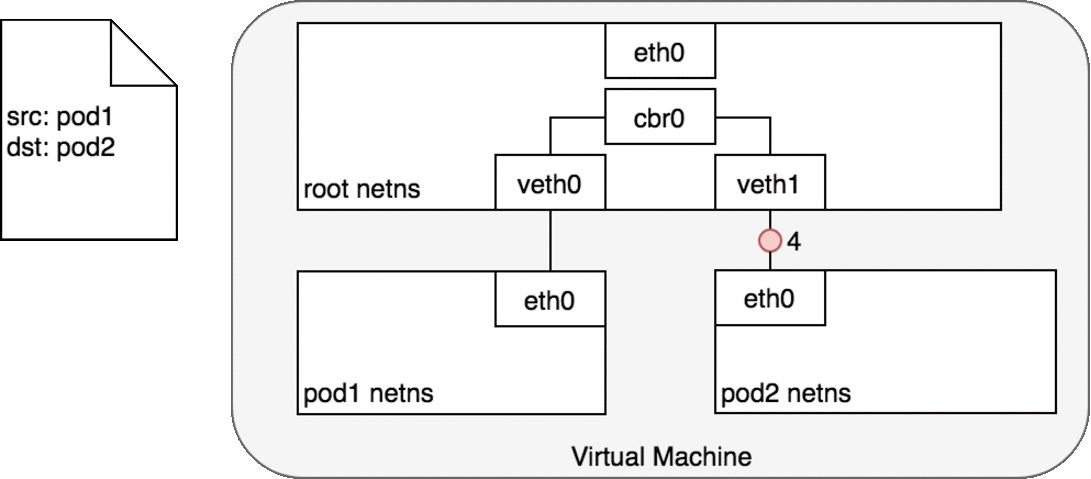
- 对 Pod1 来说,eth0 通过虚拟以太网设备(veth0)连接到 root namespace;
- 网桥 cbr0 中为 veth0 配置了一个网段。一旦数据包到达网桥,网桥使用ARP 协议解析出其正确的目标网段 veth1;
- 网桥 cbr0 将数据包发送到 veth1;
- 数据包到达 veth1 时,被直接转发到 Pod2 的 network namespace 中的 eth0 网络设备。
再看下第二种情况:两个Pod在不同Node上
K8S网络模型要求Pod IP在整个网络中都可访问,这种需求是由第三方网络组件实现。

3、CNI(容器网络接口)
CNI(Container Network Interface,容器网络接口):是一个容器网络规范,Kubernetes网络采用的就是这个CNI规范,CNI实现依赖两种插件,一种CNI Plugin是负责容器连接到主机,另一种是IPAM负责配置容器网络命名空间的网络。
CNI插件默认路径:
# ls /opt/cni/bin/- 1
地址:https://github.com/containernetworking/cni
当你在宿主机上部署Flanneld后,flanneld 启动后会在每台宿主机上生成它对应的CNI 配置文件(它其实是一个 ConfigMap),从而告诉Kubernetes,这个集群要使用 Flannel 作为容器网络方案。
CNI配置文件路径:
/etc/cni/net.d/10-flannel.conflist- 1
当 kubelet 组件需要创建 Pod 的时候,先调用dockershim它先创建一个 Infra 容器。然后调用 CNI 插件为 Infra 容器配置网络。
这两个路径在kubelet启动参数中定义:
--network-plugin=cni \
--cni-conf-dir=/etc/cni/net.d \
--cni-bin-dir=/opt/cni/bin- 1
- 2
- 3
4.3 Kubernetes网络组件之 Flannel
Flannel是CoreOS维护的一个网络组件,Flannel为每个Pod提供全局唯一的IP,Flannel使用ETCD来存储Pod子网与Node IP之间的关系。flanneld守护进程在每台主机上运行,并负责维护ETCD信息和路由数据包。
1、Flannel 部署
https://github.com/coreos/flannel
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml- 1
2、 Flannel工作模式及原理
Flannel支持多种数据转发方式:
- UDP:最早支持的一种方式,由于性能最差,目前已经弃用。
- VXLAN:Overlay Network方案,源数据包封装在另一种网络包里面进行路由转发和通信
- Host-GW:Flannel通过在各个节点上的Agent进程,将容器网络的路由信息刷到主机的路由表上,这样一来所有的主机都有整个容器网络的路由数据了。
VXLAN
# kubeadm部署指定Pod网段
kubeadm init --pod-network-cidr=10.244.0.0/16
# 二进制部署指定
cat /opt/kubernetes/cfg/kube-controller-manager.conf
--allocate-node-cidrs=true \
--cluster-cidr=10.244.0.0/16 \- 1
- 2
- 3
- 4
- 5
- 6
- 7
# kube-flannel.yml
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
为了能够在二层网络上打通“隧道”,VXLAN 会在宿主机上设置一个特殊的网络设备作为“隧道”的两端。这个设备就叫作 VTEP,即:VXLAN Tunnel End Point(虚拟隧道端点)。下图flannel.1的设备就是VXLAN所需的VTEP设备。示意图如下:

如果Pod 1访问Pod 2,源地址10.244.1.10,目的地址10.244.2.10 ,数据包传输流程如下:
-
**容器路由:**容器根据路由表从eth0发出
/ # ip route default via 10.244.0.1 dev eth0 10.244.0.0/24 dev eth0 scope link src 10.244.0.45 10.244.0.0/16 via 10.244.0.1 dev eth0- 1
- 2
- 3
- 4
-
**主机路由:**数据包进入到宿主机虚拟网卡cni0,根据路由表转发到flannel.1虚拟网卡,也就是,来到了隧道的入口。
# ip route default via 192.168.31.1 dev ens33 proto static metric 100 10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1 10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink 10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink- 1
- 2
- 3
- 4
- 5
-
**VXLAN封装:**而这些VTEP设备(二层)之间组成二层网络必须要知道目的MAC地址。这个MAC地址从哪获取到呢?其实在flanneld进程启动后,就会自动添加其他节点ARP记录,可以通过ip命令查看,如下所示:
# ip neigh show dev flannel.1 10.244.1.0 lladdr ca:2a:a4:59:b6:55 PERMANENT 10.244.2.0 lladdr d2:d0:1b:a7:a9:cd PERMANENT- 1
- 2
- 3
-
**二次封包:**知道了目的MAC地址,封装二层数据帧(容器源IP和目的IP)后,对于宿主机网络来说这个帧并没有什么实际意义。接下来,Linux内核还要把这个数据帧进一步封装成为宿主机网络的一个普通数据帧,好让它载着内部数据帧,通过宿主机的eth0网卡进行传输。

-
**封装到UDP包发出去:**现在能直接发UDP包嘛?到目前为止,我们只知道另一端的flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。
flanneld进程也维护着一个叫做FDB的转发数据库,可以通过bridge fdb命令查看:
- 1
bridge fdb show dev flannel.1
d2:d0:1b:a7:a9:cd dst 192.168.31.61 self permanent
ca:2a:a4:59:b6:55 dst 192.168.31.63 self permanent
可以看到,上面用的对方flannel.1的MAC地址对应宿主机IP,也就是UDP要发往的目的地。使用这个目的IP进行封装。
6. **数据包到达目的宿主机:**Node1的eth0网卡发出去,发现是VXLAN数据包,把它交给flannel.1设备。flannel.1设备则会进一步拆包,取出原始二层数据帧包,发送ARP请求,经由cni0网桥转发给container。
#### Host-GW
host-gw模式相比vxlan简单了许多, 直接添加路由,将目的主机当做网关,直接路由原始封包。
下面是示意图:
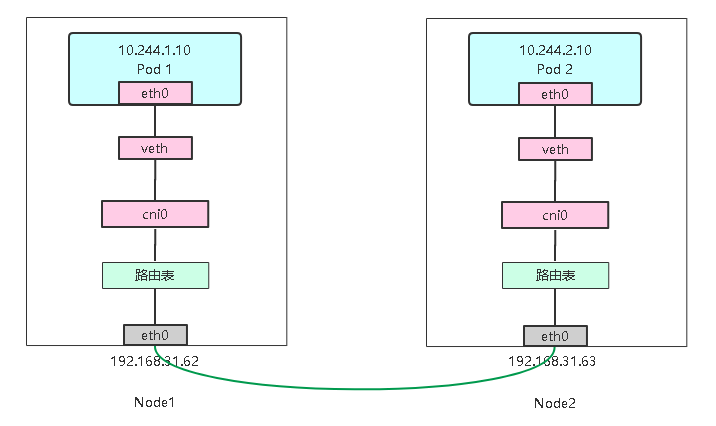- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
kube-flannel.yml
net-conf.json: |
{
“Network”: “10.244.0.0/16”,
“Backend”: {
“Type”: “host-gw”
}
}
当你设置flannel使用host-gw模式,flanneld会在宿主机上创建节点的路由表:- 1
- 2
ip route
default via 192.168.31.1 dev ens33 proto static metric 100
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
10.244.1.0/24 via 192.168.31.63 dev ens33
10.244.2.0/24 via 192.168.31.61 dev ens33
192.168.31.0/24 dev ens33 proto kernel scope link src 192.168.31.62 metric 100
目的 IP 地址属于 10.244.1.0/24 网段的 IP 包,应该经过本机的 eth0 设备发出去(即:dev eth0);并且,它下一跳地址是 192.168.31.63(即:via 192.168.31.63)。
一旦配置了下一跳地址,那么接下来,当 IP 包从网络层进入链路层封装成帧的时候,eth0 设备就会使用下一跳地址对应的 MAC 地址,作为该数据帧的目的 MAC 地址。
而 Node 2 的内核网络栈从二层数据帧里拿到 IP 包后,会“看到”这个 IP 包的目的 IP 地址是 10.244.1.20,即 container-2 的 IP 地址。这时候,根据 Node 2 上的路由表,该目的地址会匹配到第二条路由规则(也就是 10.244.1.0 对应的路由规则),从而进入 cni0 网桥,进而进入到 container-2 当中。- 1
- 2
- 3
- 4
- 5
- 6
二进制部署指定
cat /opt/kubernetes/cfg/kube-controller-manager.conf
–allocate-node-cidrs=true
–cluster-cidr=10.244.0.0/16 \
- 1
- 2
- 3
kube-flannel.yml
net-conf.json: |
{
“Network”: “10.244.0.0/16”,
“Backend”: {
“Type”: “vxlan”
}
}
为了能够在二层网络上打通“隧道”,VXLAN 会在宿主机上设置一个特殊的网络设备作为“隧道”的两端。这个设备就叫作 VTEP,即:VXLAN Tunnel End Point(虚拟隧道端点)。下图flannel.1的设备就是VXLAN所需的VTEP设备。示意图如下:
[外链图片转存中...(img-NzuRm4u8-1653875525416)]
如果Pod 1访问Pod 2,源地址10.244.1.10,目的地址10.244.2.10 ,数据包传输流程如下:
1. **容器路由:**容器根据路由表从eth0发出- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
/ # ip route
default via 10.244.0.1 dev eth0
10.244.0.0/24 dev eth0 scope link src 10.244.0.45
10.244.0.0/16 via 10.244.0.1 dev eth0
2. **主机路由:**数据包进入到宿主机虚拟网卡cni0,根据路由表转发到flannel.1虚拟网卡,也就是,来到了隧道的入口。
```
# ip route
default via 192.168.31.1 dev ens33 proto static metric 100
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink
```
3. **VXLAN封装:**而这些VTEP设备(二层)之间组成二层网络必须要知道目的MAC地址。这个MAC地址从哪获取到呢?其实在flanneld进程启动后,就会自动添加其他节点ARP记录,可以通过ip命令查看,如下所示:
```
# ip neigh show dev flannel.1
10.244.1.0 lladdr ca:2a:a4:59:b6:55 PERMANENT
10.244.2.0 lladdr d2:d0:1b:a7:a9:cd PERMANENT
```
4. **二次封包:**知道了目的MAC地址,封装二层数据帧(容器源IP和目的IP)后,对于宿主机网络来说这个帧并没有什么实际意义。接下来,Linux内核还要把这个数据帧进一步封装成为宿主机网络的一个普通数据帧,好让它载着内部数据帧,通过宿主机的eth0网卡进行传输。
[外链图片转存中...(img-HZ7UYl3b-1653875525417)]
5. **封装到UDP包发出去:**现在能直接发UDP包嘛?到目前为止,我们只知道另一端的flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。
flanneld进程也维护着一个叫做FDB的转发数据库,可以通过bridge fdb命令查看:- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
# bridge fdb show dev flannel.1
d2:d0:1b:a7:a9:cd dst 192.168.31.61 self permanent
ca:2a:a4:59:b6:55 dst 192.168.31.63 self permanent- 1
- 2
- 3
- 4
- 5
- 6
可以看到,上面用的对方flannel.1的MAC地址对应宿主机IP,也就是UDP要发往的目的地。使用这个目的IP进行封装。
- **数据包到达目的宿主机:**Node1的eth0网卡发出去,发现是VXLAN数据包,把它交给flannel.1设备。flannel.1设备则会进一步拆包,取出原始二层数据帧包,发送ARP请求,经由cni0网桥转发给container。
Host-GW
host-gw模式相比vxlan简单了许多, 直接添加路由,将目的主机当做网关,直接路由原始封包。
下面是示意图:
[外链图片转存中…(img-oQPpCLGr-1653875525418)]
# kube-flannel.yml
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "host-gw"
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
当你设置flannel使用host-gw模式,flanneld会在宿主机上创建节点的路由表:
# ip route
default via 192.168.31.1 dev ens33 proto static metric 100
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
10.244.1.0/24 via 192.168.31.63 dev ens33
10.244.2.0/24 via 192.168.31.61 dev ens33
192.168.31.0/24 dev ens33 proto kernel scope link src 192.168.31.62 metric 100- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
目的 IP 地址属于 10.244.1.0/24 网段的 IP 包,应该经过本机的 eth0 设备发出去(即:dev eth0);并且,它下一跳地址是 192.168.31.63(即:via 192.168.31.63)。
一旦配置了下一跳地址,那么接下来,当 IP 包从网络层进入链路层封装成帧的时候,eth0 设备就会使用下一跳地址对应的 MAC 地址,作为该数据帧的目的 MAC 地址。
而 Node 2 的内核网络栈从二层数据帧里拿到 IP 包后,会“看到”这个 IP 包的目的 IP 地址是 10.244.1.20,即 container-2 的 IP 地址。这时候,根据 Node 2 上的路由表,该目的地址会匹配到第二条路由规则(也就是 10.244.1.0 对应的路由规则),从而进入 cni0 网桥,进而进入到 container-2 当中。