基于机器学习的卫星图像分类
一.选题背景
过去几年见证了遥感(RS)图像解释及其广泛应用的巨大进展。随着 RS 图像变得比以往任何时候都更容易访问,对这些图像的自动解释的需求也在不断增加。在这种情况下,基准数据集是开发和测试智能解释算法的基本先决条件。在回顾了RS图像解释研究界现有的基准数据集之后,本文讨论了如何有效地为RS图像解释准备合适的基准数据集的问题。具体来说,我们首先分析了通过文献计量学研究开发用于RS图像解释的智能算法的当前挑战。然后,我们介绍了以有效方式创建基准数据集的一般指南。根据提供的指南,我们还提供了一个构建 RS 图像数据集的示例,即 Million-AID,这是一个新的大规模基准数据集,其中包含一百万个用于 RS 图像场景分类的实例。最后讨论了RS图像标注中的几个挑战和观点,以促进基准数据集构建的研究。我们希望本文能为 RS 社区提供一个构建大规模和实用图像数据集的整体视角,以便进一步研究,尤其是数据驱动的数据集。
二.大数据分析设计方案
方案的主要内容步骤:
用于RS图像解释的注释数据集 RS图像的解释
在各种各样的应用中发挥着越来越重要的作用,因此引起了显着的研究关注。因此,已经建立了各种数据集来推进RS图像解释算法的开发。结合过去十年发表的文献,我们对现有的RS图像数据集进行了系统综述,涉及当前主流的RS图像解释任务,包括场景分类,对象检测,语义分割和变化检测。
灵感:人工智能、计算机视觉、图像处理、深度学习、卫星图像、遥感
1.导入库:当链接Windows程序以产生一个可执行文件时,您必须链接由编程环境提供的专门的导入库,这些导入库包含了动态链接库的名称和所有windowss函数调用的引用信息
2.创建测试和验证目录:在库中创建代码命令来测试和验证主题的目录
3.数据拆分:整理出原始数据后,将这些原始数据进行拆分,这些拆分可以根据你最想要的,来进行拆分
4.图像预处理:图像预处理的主要目的是消除图像中无关的信息,恢复有用的真实信息,增强有关信息的可检测性、最大限度地简化数据,从而改进特征提取、图像分割、匹配和识别的可靠性
5.图像可视化:可视化(Visualization)是利用计算机图形学和图像处理技术,将数据转换成图形或图像在屏幕上显示出来,并进行交互处理的理论、方法和技术
6.进行可视化查看分类前后的数据
7.模型创建:创建一个模型
8.模型训练:在前面的模型创建中进行模型训练
9.绘制训练和验证精度
1.导入库
import numpy as np
import tensorflow as tf
from tensorflow import keras
from keras import layers
from keras.preprocessing.image import ImageDataGenerator
from shutil import copyfile
import matplotlib.pyplot as plt
import shutil
import os
import random
2.创建测试和验证目录
root_dir = '/kaggle/working/data'
# Empty directory to prevent FileExistsError is the function is run several times
if os.path.exists(root_dir):
shutil.rmtree(root_dir)
def create_train_val_dirs(root_path):
os.mkdir(root_path)
training = os.path.join(root_path, 'training/')
validation = os.path.join(root_path, 'validation/')
train_cloudy = os.path.join(training, 'cloudy')
train_desert = os.path.join(training, 'desert')
train_green_area = os.path.join(training, 'green_area')
train_water = os.path.join(training, 'water')
valid_cloudy = os.path.join(validation, 'cloudy')
valid_desert = os.path.join(validation, 'desert')
valid_green_area = os.path.join(validation, 'green_area')
valid_water = os.path.join(validation, 'water')
os.mkdir(training)
os.mkdir(validation)
os.mkdir(train_cloudy)
os.mkdir(train_desert)
os.mkdir(train_green_area)
os.mkdir(train_water)
os.mkdir(valid_cloudy)
os.mkdir(valid_desert)
os.mkdir(valid_green_area)
os.mkdir(valid_water)
try:
create_train_val_dirs(root_path=root_dir)
except FileExistsError:
print(FileExistsError)
3.数据拆分
def split_data(SOURCE_DIR, TRAINING_DIR, VALIDATION_DIR, SPLIT_SIZE):
source_files = os.listdir(SOURCE_DIR)
source_files_to_copy_train = random.sample(source_files, int(len(source_files) * SPLIT_SIZE))
for file in source_files_to_copy_train:
if os.path.getsize(os.path.join(SOURCE_DIR,file)) > 0:
shutil.copy(SOURCE_DIR+file, TRAINING_DIR+file)
else:
print(f'{file} is zero length, so ignoring.')
for file in source_files:
if file not in source_files_to_copy_train:
if os.path.getsize(os.path.join(SOURCE_DIR,file)) > 0:
shutil.copy(SOURCE_DIR+file, VALIDATION_DIR+file)
else:
print(f'{file} is zero length, so ignoring.')
training = "/kaggle/working/data/training/"
validation = "/kaggle/working/data/validation/"
CLOUDY_SOURCE_DIR = '/kaggle/input/satellite-image-classification/data/cloudy/'
DESERT_SOURCE_DIR = '/kaggle/input/satellite-image-classification/data/desert/'
GREEN_AREA_SOURCE_DIR = '/kaggle/input/satellite-image-classification/data/green_area/'
WATER_SOURCE_DIR = '/kaggle/input/satellite-image-classification/data/water/'
TRAINING_CLOUDY_DIR = os.path.join(training, "cloudy/")
VALIDATION_CLOUDY_DIR = os.path.join(validation, "cloudy/")
TRAINING_DESERT_DIR = os.path.join(training, 'desert/')
VALIDATION_DESERT_DIR = os.path.join(validation, 'desert/')
TRAINING_GREEN_AREA_DIR = os.path.join(training, 'green_area/')
VALIDATION_GREEN_AREA_DIR = os.path.join(validation, 'green_area/')
TRAINING_WATER_DIR = os.path.join(training, 'water/')
VALIDATION_WATER_DIR = os.path.join(validation, 'water/')
split_size = 0.9
split_data(CLOUDY_SOURCE_DIR, TRAINING_CLOUDY_DIR, VALIDATION_CLOUDY_DIR, split_size)
split_data(DESERT_SOURCE_DIR, TRAINING_DESERT_DIR, VALIDATION_DESERT_DIR, split_size)
split_data(GREEN_AREA_SOURCE_DIR, TRAINING_GREEN_AREA_DIR, VALIDATION_GREEN_AREA_DIR, split_size)
split_data(WATER_SOURCE_DIR, TRAINING_WATER_DIR, VALIDATION_WATER_DIR, split_size)
4.图像预处理
def train_val_generators(TRAINING_DIR, VALIDATION_DIR):
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=180,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range = 0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# Pass in the appropriate arguments to the flow_from_directory method
train_generator = train_datagen.flow_from_directory(directory=TRAINING_DIR,
class_mode='categorical',
target_size=(100, 100))
# Instantiate the ImageDataGenerator class (don't forget to set the rescale argument)
validation_datagen = ImageDataGenerator(rescale=1./255)
# Pass in the appropriate arguments to the flow_from_directory method
validation_generator = validation_datagen.flow_from_directory(directory=VALIDATION_DIR,
class_mode='categorical',
target_size=(100, 100))
return train_generator, validation_generator
train_generator, validation_generator = train_val_generators(training, validation)

5.图像可视化
x_train = []
y_train = []
c = 0
for feature, label in train_generator:
x_train.append(np.array(feature))
y_train.append(np.array(label))
c += 1
if c == 1:
break
x_train = np.array(x_train)
print(x_train.shape)
x_train = np.reshape(x_train, (32, 100, 100, 3))
print(x_train.shape)

fig, ax = plt.subplots(4, 4, figsize=(30, 30))
for i in range(0, 16):
ax[int(i / 4), (i % 4)].imshow(x_train[i])

6.进行可视化查看分类前后的数据
fig, (ax1,ax2) = plt.subplots(figsize=[15,15], nrows=1,ncols=2)
show(rs, cmap='gray', vmin=vmin, vmax=vmax, ax=ax1)
show(img_cl, ax=ax2)
ax1.set_axis_off()
ax2.set_axis_off()
fig.savefig("pred.png", bbox_inches='tight')
plt.show()

7.模型创建
def create_model():
model = keras.models.Sequential([
layers.Conv2D(32, (2,2), activation='relu', input_shape=(100, 100, 3)),
layers.MaxPooling2D(2,2),
layers.Conv2D(64, (2,2), activation='relu'),
layers.MaxPooling2D(2,2),
layers.Conv2D(64, (3,3), activation='relu'),
layers.MaxPooling2D(2,2),
# Flatten the results to feed into a DNN
layers.Flatten(),
# 512 neuron hidden layer
layers.Dropout(0.1),
layers.Dense(512, activation='relu'),
layers.Dropout(0.1),
layers.Dense(4, activation='softmax')
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
8.模型训练
# Get the untrained model
model = create_model()
# Train the model
# Note that this may take some time.
history = model.fit(train_generator,
epochs=11,
verbose=1,
validation_data=validation_generator)

9.绘制训练和验证精度
acc=history.history['accuracy']
val_acc=history.history['val_accuracy']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=range(len(acc)) # Get number of epochs
#------------------------------------------------
# Plot training and validation accuracy per epoch
#------------------------------------------------
plt.plot(epochs, acc, 'r')
plt.plot(epochs, val_acc, 'b')
plt.title('Training and validation accuracy')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend(['Training', 'Validation'])
plt.show()
print("")
#------------------------------------------------
# Plot training and validation loss per epoch
#------------------------------------------------
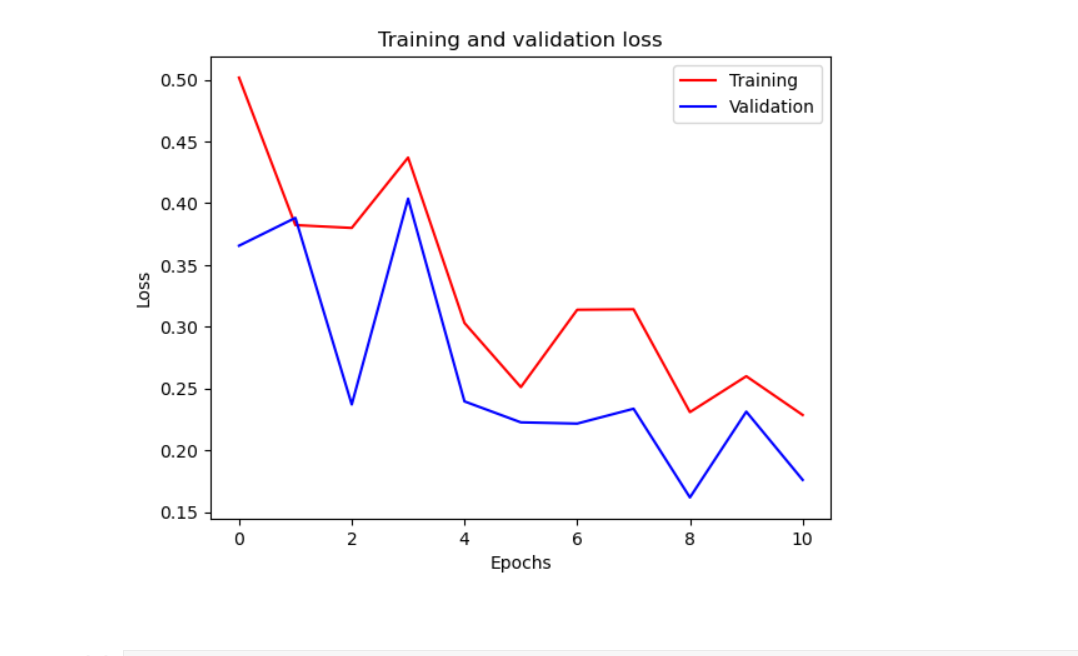
plt.plot(epochs, loss, 'r')
plt.plot(epochs, val_loss, 'b')
plt.title('Training and validation loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend(['Training', 'Validation'])
plt.show()

三. 总结
根据这次的了解和编写过程等我可以更好的理解使用机器学习方法对卫星图像进行分类,更好的了解
在学习编写等过程中遇到一些问题,代码会报错,写错等,但在各种资料查询可以慢慢解决问题
总代码:
import numpy as np
import tensorflow as tf
from tensorflow import keras
from keras import layers
from keras.preprocessing.image import ImageDataGenerator
from shutil import copyfile
import matplotlib.pyplot as plt
import shutil
import os
import random
root_dir = '/kaggle/working/data'
# Empty directory to prevent FileExistsError is the function is run several times
if os.path.exists(root_dir):
shutil.rmtree(root_dir)
def create_train_val_dirs(root_path):
os.mkdir(root_path)
training = os.path.join(root_path, 'training/')
validation = os.path.join(root_path, 'validation/')
train_cloudy = os.path.join(training, 'cloudy')
train_desert = os.path.join(training, 'desert')
train_green_area = os.path.join(training, 'green_area')
train_water = os.path.join(training, 'water')
valid_cloudy = os.path.join(validation, 'cloudy')
valid_desert = os.path.join(validation, 'desert')
valid_green_area = os.path.join(validation, 'green_area')
valid_water = os.path.join(validation, 'water')
os.mkdir(training)
os.mkdir(validation)
os.mkdir(train_cloudy)
os.mkdir(train_desert)
os.mkdir(train_green_area)
os.mkdir(train_water)
os.mkdir(valid_cloudy)
os.mkdir(valid_desert)
os.mkdir(valid_green_area)
os.mkdir(valid_water)
try:
create_train_val_dirs(root_path=root_dir)
except FileExistsError:
print(FileExistsError)
for rootdir, dirs, files in os.walk(root_dir):
for subdir in dirs:
print(os.path.join(rootdir, subdir))
def split_data(SOURCE_DIR, TRAINING_DIR, VALIDATION_DIR, SPLIT_SIZE):
source_files = os.listdir(SOURCE_DIR)
source_files_to_copy_train = random.sample(source_files, int(len(source_files) * SPLIT_SIZE))
for file in source_files_to_copy_train:
if os.path.getsize(os.path.join(SOURCE_DIR,file)) > 0:
shutil.copy(SOURCE_DIR+file, TRAINING_DIR+file)
else:
print(f'{file} is zero length, so ignoring.')
for file in source_files:
if file not in source_files_to_copy_train:
if os.path.getsize(os.path.join(SOURCE_DIR,file)) > 0:
shutil.copy(SOURCE_DIR+file, VALIDATION_DIR+file)
else:
print(f'{file} is zero length, so ignoring.')
training = "/kaggle/working/data/training/"
validation = "/kaggle/working/data/validation/"
CLOUDY_SOURCE_DIR = '/kaggle/input/satellite-image-classification/data/cloudy/'
DESERT_SOURCE_DIR = '/kaggle/input/satellite-image-classification/data/desert/'
GREEN_AREA_SOURCE_DIR = '/kaggle/input/satellite-image-classification/data/green_area/'
WATER_SOURCE_DIR = '/kaggle/input/satellite-image-classification/data/water/'
TRAINING_CLOUDY_DIR = os.path.join(training, "cloudy/")
VALIDATION_CLOUDY_DIR = os.path.join(validation, "cloudy/")
TRAINING_DESERT_DIR = os.path.join(training, 'desert/')
VALIDATION_DESERT_DIR = os.path.join(validation, 'desert/')
TRAINING_GREEN_AREA_DIR = os.path.join(training, 'green_area/')
VALIDATION_GREEN_AREA_DIR = os.path.join(validation, 'green_area/')
TRAINING_WATER_DIR = os.path.join(training, 'water/')
VALIDATION_WATER_DIR = os.path.join(validation, 'water/')
split_size = 0.9
split_data(CLOUDY_SOURCE_DIR, TRAINING_CLOUDY_DIR, VALIDATION_CLOUDY_DIR, split_size)
split_data(DESERT_SOURCE_DIR, TRAINING_DESERT_DIR, VALIDATION_DESERT_DIR, split_size)
split_data(GREEN_AREA_SOURCE_DIR, TRAINING_GREEN_AREA_DIR, VALIDATION_GREEN_AREA_DIR, split_size)
split_data(WATER_SOURCE_DIR, TRAINING_WATER_DIR, VALIDATION_WATER_DIR, split_size)
def train_val_generators(TRAINING_DIR, VALIDATION_DIR):
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=180,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range = 0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# Pass in the appropriate arguments to the flow_from_directory method
train_generator = train_datagen.flow_from_directory(directory=TRAINING_DIR,
class_mode='categorical',
target_size=(100, 100))
# Instantiate the ImageDataGenerator class (don't forget to set the rescale argument)
validation_datagen = ImageDataGenerator(rescale=1./255)
# Pass in the appropriate arguments to the flow_from_directory method
validation_generator = validation_datagen.flow_from_directory(directory=VALIDATION_DIR,
class_mode='categorical',
target_size=(100, 100))
return train_generator, validation_generator
train_generator, validation_generator = train_val_generators(training, validation)
x_train = []
y_train = []
c = 0
for feature, label in train_generator:
x_train.append(np.array(feature))
y_train.append(np.array(label))
c += 1
if c == 1:
break
x_train = np.array(x_train)
print(x_train.shape)
x_train = np.reshape(x_train, (32, 100, 100, 3))
print(x_train.shape)
fig, ax = plt.subplots(4, 4, figsize=(30, 30))
for i in range(0, 16):
ax[int(i / 4), (i % 4)].imshow(x_train[i])
def create_model():
model = keras.models.Sequential([
layers.Conv2D(32, (2,2), activation='relu', input_shape=(100, 100, 3)),
layers.MaxPooling2D(2,2),
layers.Conv2D(64, (2,2), activation='relu'),
layers.MaxPooling2D(2,2),
layers.Conv2D(64, (3,3), activation='relu'),
layers.MaxPooling2D(2,2),
# Flatten the results to feed into a DNN
layers.Flatten(),
# 512 neuron hidden layer
layers.Dropout(0.1),
layers.Dense(512, activation='relu'),
layers.Dropout(0.1),
layers.Dense(4, activation='softmax')
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
# Get the untrained model
model = create_model()
# Train the model
# Note that this may take some time.
history = model.fit(train_generator,
epochs=11,
verbose=1,
validation_data=validation_generator)
acc=history.history['accuracy']
val_acc=history.history['val_accuracy']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=range(len(acc)) # Get number of epochs
plt.plot(epochs, acc, 'r')
plt.plot(epochs, val_acc, 'b')
plt.title('Training and validation accuracy')
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.legend(['Training', 'Validation'])
plt.show()
print("")
plt.plot(epochs, loss, 'r')
plt.plot(epochs, val_loss, 'b')
plt.title('Training and validation loss')
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend(['Training', 'Validation'])
plt.show()