分布式事务
传统数据库事务
一,什么是事务
事务是指单个逻辑工作单元执行得一系列操作,要么都做,要么都不做,是不可分割的工作单位,是数据库环境中的的最小工作单元
二、为什么需要事务?
事务的四大特性
1.原子性:所谓的原子性就是说,在整个事务中的所有操作,要么全部完成,要么全部不做,没有中间状态。对于事务在执行中发生错误,所有的操作都会被回滚,整个事务就像从没被执行过一样。
2.一致性:事务的执行必须保证系统的一致性,就拿转账为例,A有500元,B有300元,如果在一个事务里A成功转给B50元,那么不管并发多少,不管发生什么,只要事务执行成功了,那么最后A账户一定是450元,B账户一定是350元。
3.隔离性:所谓的隔离性就是说,事务与事务之间不会互相影响,一个事务的中间状态不会被其他事务感知。
4.持久性:所谓的持久性,就是说一单事务完成了,那么事务对数据所做的变更就完全保存在了数据库中,即使发生停电,系统宕机也是如此
1)脏读
指一个事务读取到另一个事务未提交的数据。
2)不可重复读
指一个事务对同一行数据重复读取两次,但得到的结果不同。
3)虚读/幻读
指一个事务执行两次查询,但第二次查询的结果包含了第一次查询中未出现的数据。
4)丢失更新
指两个事务同时更新一行数据,后提交(或撤销)的事务将之前事务提交的数据覆盖了。
丢失更新可分为两类,分别是第一类丢失更新和第二类丢失更新。
-
第一类丢失更新是指两个事务同时操作同一个数据时,当第一个事务撤销时,把已经提交的第二个事务的更新数据覆盖了,第二个事务就造成了数据丢失。
-
第二类丢失更新是指当两个事务同时操作同一个数据时,第一个事务将修改结果成功提交后,对第二个事务已经提交的修改结果进行了覆盖,对第二个事务造成了数据丢失。
为了避免上述事务并发问题的出现,在标准的 SQL 规范中定义了四种事务隔离级别,不同的隔离级别对事务的处理有所不同。这四种事务的隔离级别如下。
隔离性四种隔离级别
1)Read Uncommitted(读未提交)
一个事务在执行过程中,既可以访问其他事务未提交的新插入的数据,又可以访问未提交的修改数据。如果一个事务已经开始写数据,则另外一个事务不允许同时进行写操作,但允许其他事务读此行数据。此隔离级别可防止丢失更新。会产生脏读、幻读、不可重复读的问题
2)Read Committed(读已提交)
一个事务在执行过程中,既可以访问其他事务成功提交的新插入的数据,又可以访问成功修改的数据。读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。此隔离级别可有效防止脏读。会产生幻读、不可重复读的问题
3)Repeatable Read(可重复读取)
一个事务在执行过程中,可以访问其他事务成功提交的新插入的数据,但不可以访问成功修改的数据。读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。此隔离级别可有效防止不可重复读和脏读。会产生幻读的问题
4)Serializable(可串行化)
提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,不能并发执行。此隔离级别可有效防止脏读、不可重复读和幻读。但这个级别可能导致大量的超时现象和锁竞争,在实际应用中很少使用。
一般来说,事务的隔离级别越高,越能保证数据库的完整性和一致性,但相对来说,隔离级别越高,对并发性能的影响也越大。因此,通常将数据库的隔离级别设置为 Read Committed,即读已提交数据,它既能防止脏读,又能有较好的并发性能。虽然这种隔离级别会导致不可重复读、幻读和第二类丢失更新这些并发问题,但可通过在应用程序中采用悲观锁和乐观锁加以控制。
控制事物
1.使用JDBC事务:通过使用JDBC的Connectio
2.使用spring
分布式事务
就是在分布式环境下,出现的事务问题,对比传统事务来说,分布式事务又分为,刚性事务,和柔性事务,刚性事务需要保证数据的强一致性,柔性事务呢需要保证数据的最终一致性。
分布式事务理论
CAP定理
分布式系统下的三个指标
1.一致性(Consistency):指的是强一致性即用户访问分布式系统中的任意节点,得到的数据必须一致。
2.可用性(Availability):用户访问集群中的任意健康节点,必须能得到响应,而不是超时或拒绝。
3.分区容错性:分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务
在分布式环境下,这三个指标不可能同时做到,且P是一定要保证的
因为网络是不可靠的。客户因素,没办法避免
CP:在一定时间内,等待集群节点进行数据同步后,对外提供访问
AP:在任何时间内,都对外访问,但是得到的数据可能不一样
base理论
对CAP的一种补充放弃强一致性,追求最终一致性
三个思想
基本可用(Basically Available):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
软状态(Soft State):在一定时间内,允许出现中间状态,比如临时的不一致状态。比如订单状态:待付款、已付款待发货、已发货、已签收、已结束
最终一致性(Eventually Consistent):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
AP保证最综一致性
CP保证强一致性
seata解决分布式事务
seata的三个架构
TC(Transaction Coordinator)事务协调者:维护全局和分支事务的状态,协调全局事务提交或回滚。监控和通知各个事务,包括分支事务和全局事务
TM (Transaction Manager) :事务管理器:定义全局事务的范围、开始全局事务、提交或回滚全局事务。用来执行事务
RM (Resource Manager):资源管理器:管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
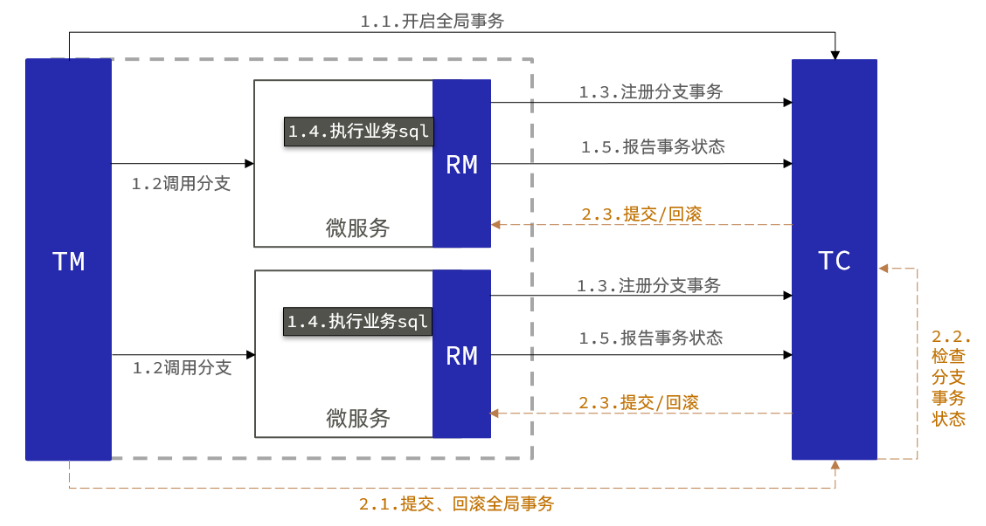
XA:强一致性,基于数据库隔离,无代码侵入,在一阶段不提交事务
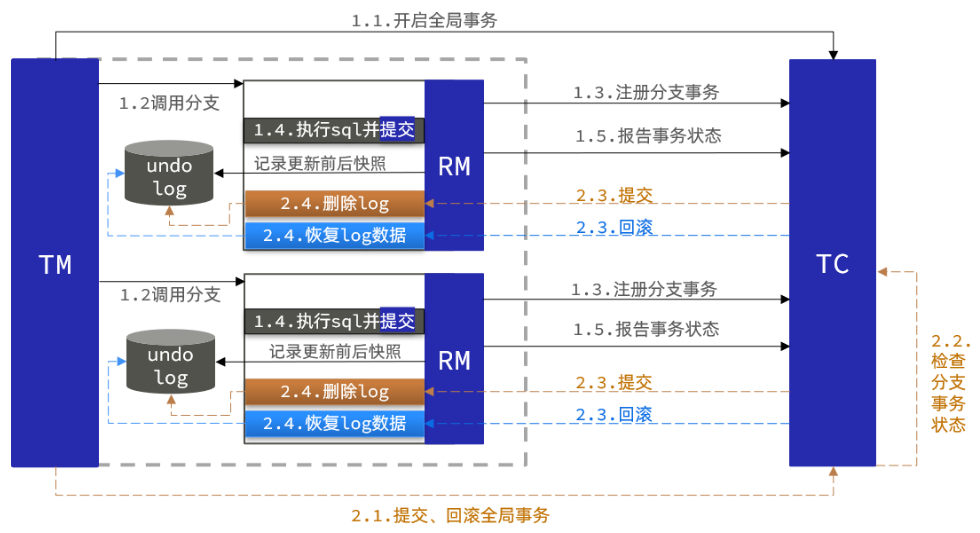
AT:默认模式,基于全局锁隔离,无代码侵入,一阶段提交事务,在提交事务前,会记录undolog日志,性能比XA模式好,二阶段TC通知回滚,则根据undolog回滚,通知提交,则删除undolog日志。
TCC:性能最好,不需要依赖关系型数据库,但代码入侵读高。Try:冻结可用数据,Confirm:确认提交数据,删除冻结数据 Canel:恢复数据,将冻结数据恢复
Seaga: 用于长事务,例如A项目调另外一个公司的项目接口。
XA模式工作原理图
AT模式工作图