Fully Attentional Network for Semantic Segmentation
* Authors: [[Qi Song]], [[Jie Li]], [[Chenghong Li]], [[Hao Guo]], [[Rui Huang]]
初读印象
comment:: (FLANet)常规的注意力在得到相容性矩阵的时候,把会有一个维度被压缩掉。为了解决这个问题,本文提出了一种新的方法,即全注意力网络,在保持高计算效率的同时,将空间注意力和通道注意力编码在一个单一的相似性图中。
动机
通道注意力\(Sim^{C\times C} = Q^{C\times HW}K^{HW\times C}\),在此过程中,每个通道可以与所有其他通道图连接,而空间信息将被整合,每个空间位置在矩阵乘法过程中无法感知来自其他位置的特征响应。同样的,空间注意力中通道维度之间的相互作用也缺失。注意力缺失问题会损害三维上下文信息( 3D context information,CHW )的完整性,因此两种注意力只能部分互补地获益。
在Cityscapes数据集上的分割结果显示,通道注意力在卡车、公共汽车和火车等大对象中效果更好,空间注意力在小/细类别上表现得更好。由于注意缺失问题的存在,两者在某些类别上都失去了精确性。且不能通过简单的堆叠来解决这种性能下降。
方法
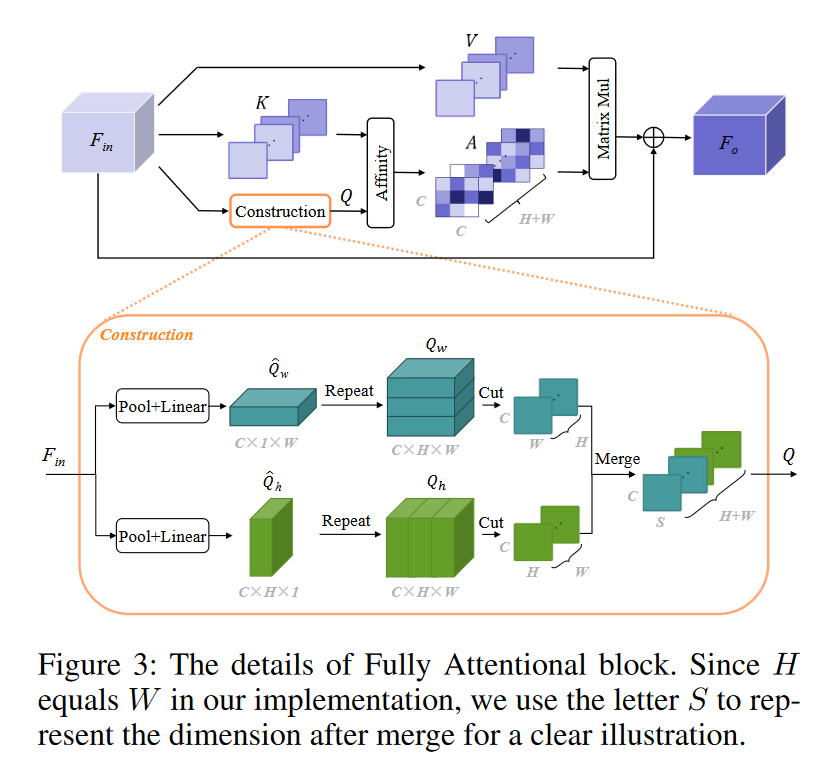 *分支1:
*分支1:
* 分别使用大小为H × 1和1 × W的池化窗口对\(F_{in}\)在水平和垂直两个方向做池化,得到两个方向的全局先验,用于实现相应维度上的空间相互作用。
* 对两个池化结果做重复使其恢复原尺度。
* 分别沿着水平方向和垂直方向做切片,得到H个\(C\times W\)的切片和W个\(C\times H\)的切片。因为之前池化过,所以H的切片上会有W的信息,W的切片上会有H的信息。
* 由于本例中H=W=S是相等的,拼接两者得到\((H+W)\times C\times S\)的先验Q。
- 分支2
- 直接对\(F_{in}\)分别沿着水平方向和垂直方向做切片,得到H个\(C\times W\)的切片和W个\(C\times H\)的切片,拼接两者得到\((H+W)\times S\times C\)的特征K。
- 分支3
- 直接对\(F_{in}\)分别沿着水平方向和垂直方向做切片,得到H个\(C\times W\)的切片和W个\(C\times H\)的切片,拼接两者得到\((H+W)\times C\times S\)的特征V。
Q和K的每一个切片做自注意力,虽然每个切片上压缩了空间信息,但是总共有\(H\times W\)个切片,总体的空间信息还是保留的。
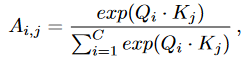
- 直接对\(F_{in}\)分别沿着水平方向和垂直方向做切片,得到H个\(C\times W\)的切片和W个\(C\times H\)的切片,拼接两者得到\((H+W)\times C\times S\)的特征V。
得到
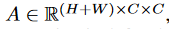 其中\(A_{i,j}\)表示第i和第j个通道在特定空间位置上的关联程度。\(A\)和\(V\)进行矩阵乘法,再将结果重塑为两个\(C\times H\times W\)的矩阵,将其相加,再将其乘以一个可学习的标量系数再与原输入进行相加。
其中\(A_{i,j}\)表示第i和第j个通道在特定空间位置上的关联程度。\(A\)和\(V\)进行矩阵乘法,再将结果重塑为两个\(C\times H\times W\)的矩阵,将其相加,再将其乘以一个可学习的标量系数再与原输入进行相加。
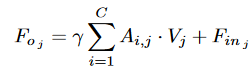
与传统的Channel NL方法仅通过乘以来自同一位置的空间信息来探索通道相关性不同,FLA实现了不同空间位置之间的空间连接,即在空间和通道两个维度上都使用了单一的注意力图。FLA具有更整体的语境观,对不同的场景更加鲁棒。此外,构建的先验表示带来了全局感受野,有助于提升特征区分能力。
效率
空间注意力的复杂度为:
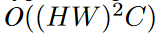 通道注意力的复杂度为:
通道注意力的复杂度为: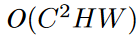
FLA的复杂度为:
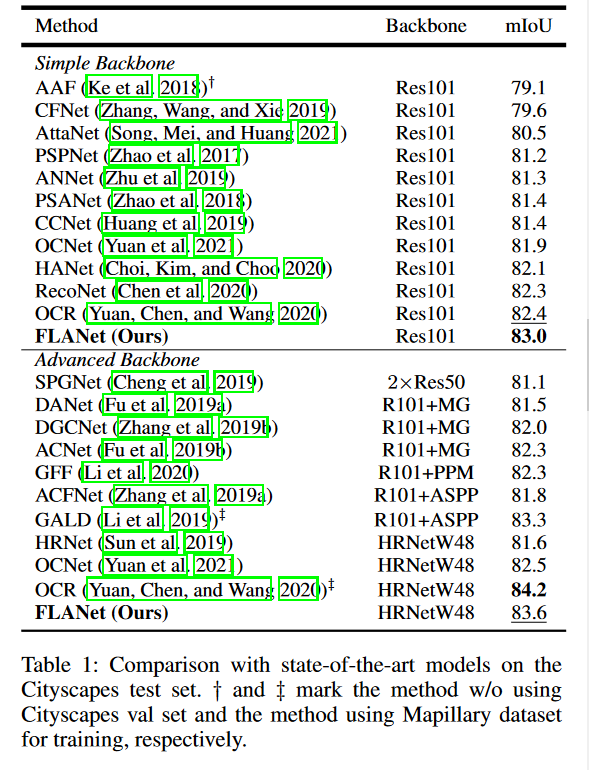
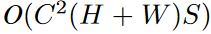 ###表现
###表现
启发
分别得到水平方向和垂直方向的切片,实际上是保留了该方向的空间信息,也就是分别建立了两个维度的空间信息。得到相容性矩阵的时候,被压缩掉的也只是\(S\)那个维度的信息,同样保留了通道信息。
- Segmentation Attentional Semantic Network FLANetsegmentation attentional semantic network convolutional segmentation networks semantic segmentation criss-cross attention semantic segmentation generative gaussian semantic segmentation transformers semantic segvit segmentation注意力attention network flanet attentional attentional attributed clustering embedding segmentation