1 过拟合和欠拟合
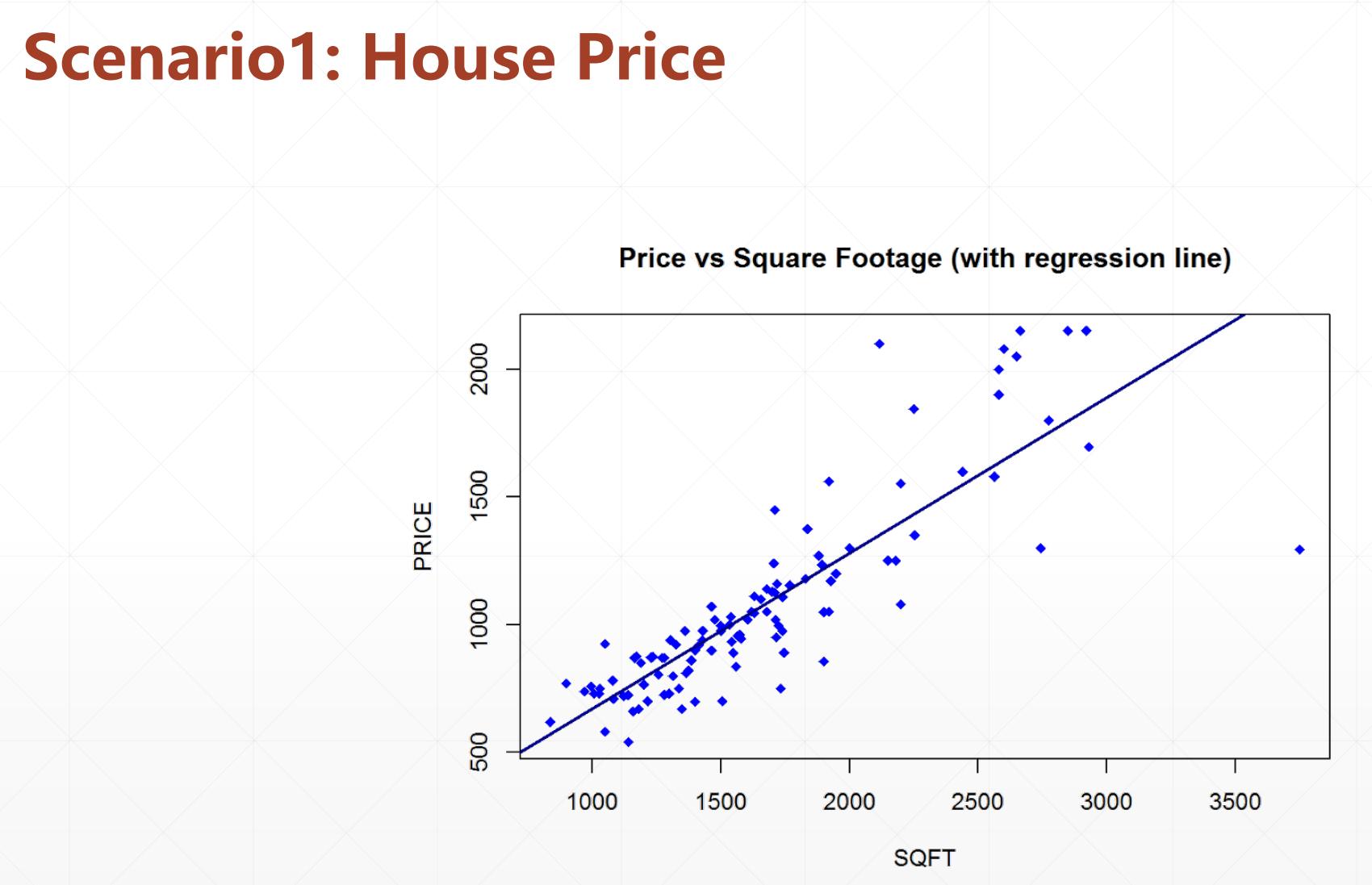
线性模型
非线性模型
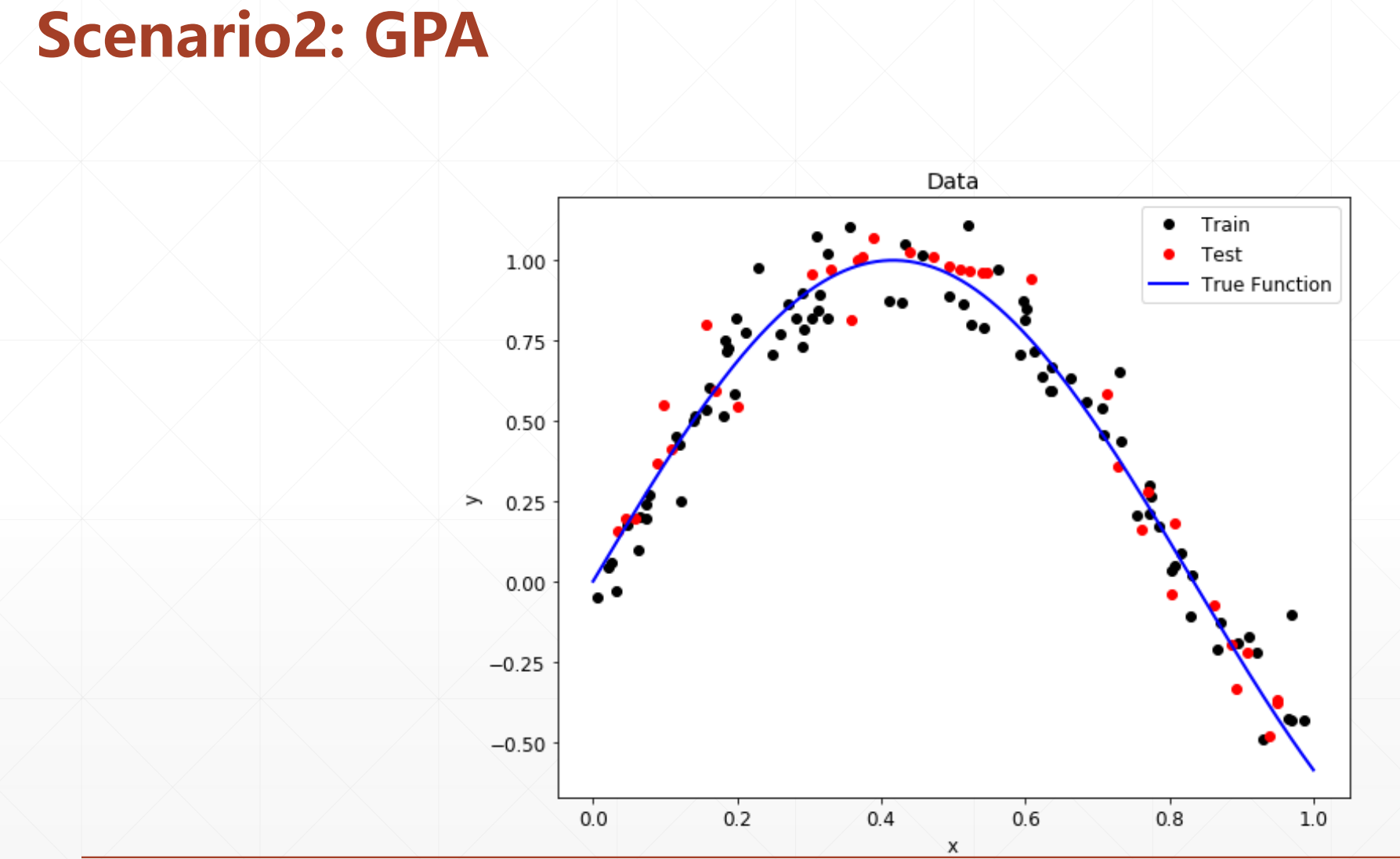
然而我们再做现实的预测的时候,我们并不知道它的结构。或者它属于那种分布,他的参数也不知道,类型也不知道,什么都不知道。
这里还会有一些其他的因素:

我们假设:
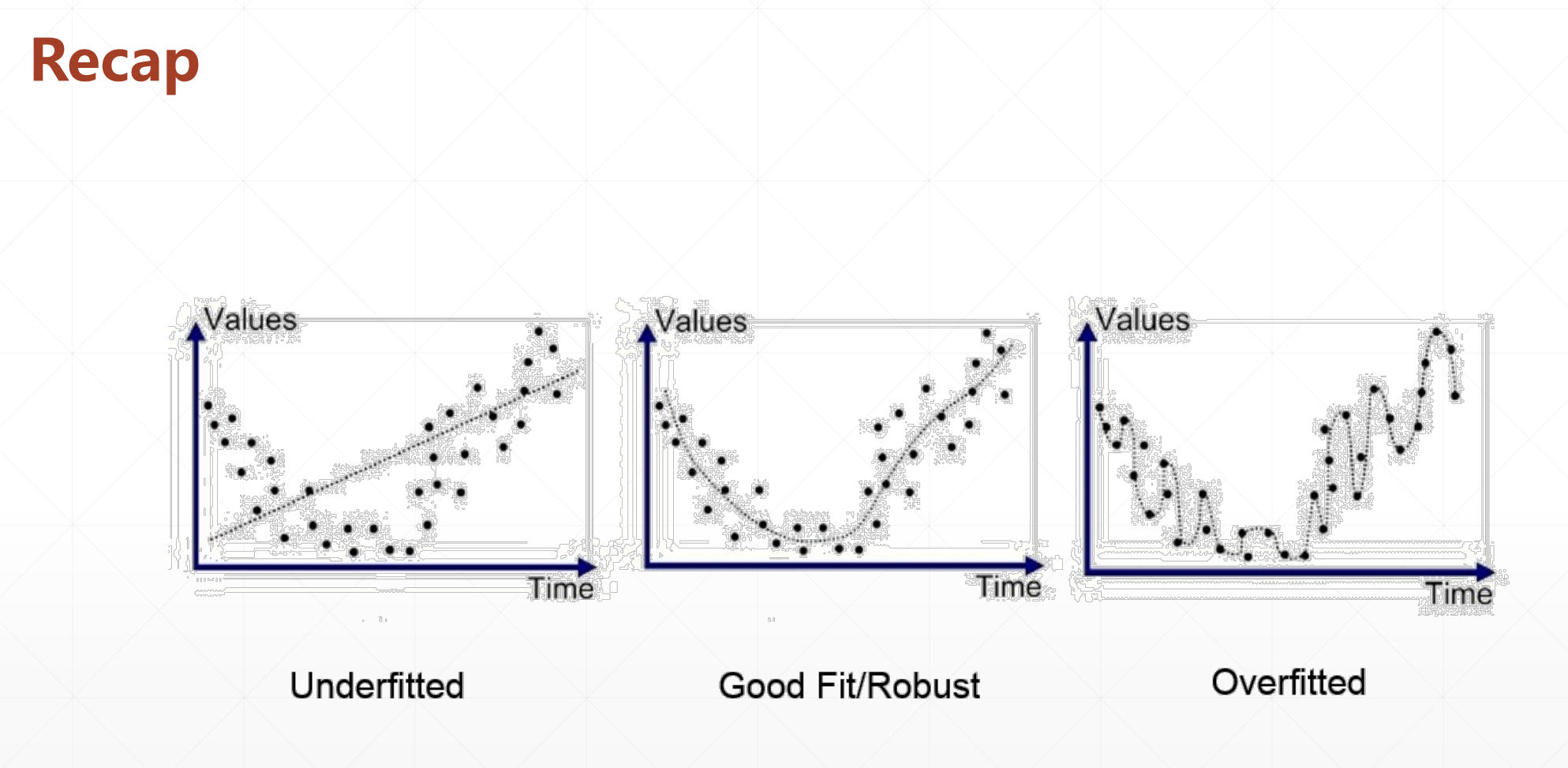
1.1 case1:(欠拟合)
这个时候我们的模型表达能力小于真实的数据的复杂度,导致模型的表达能力很弱。
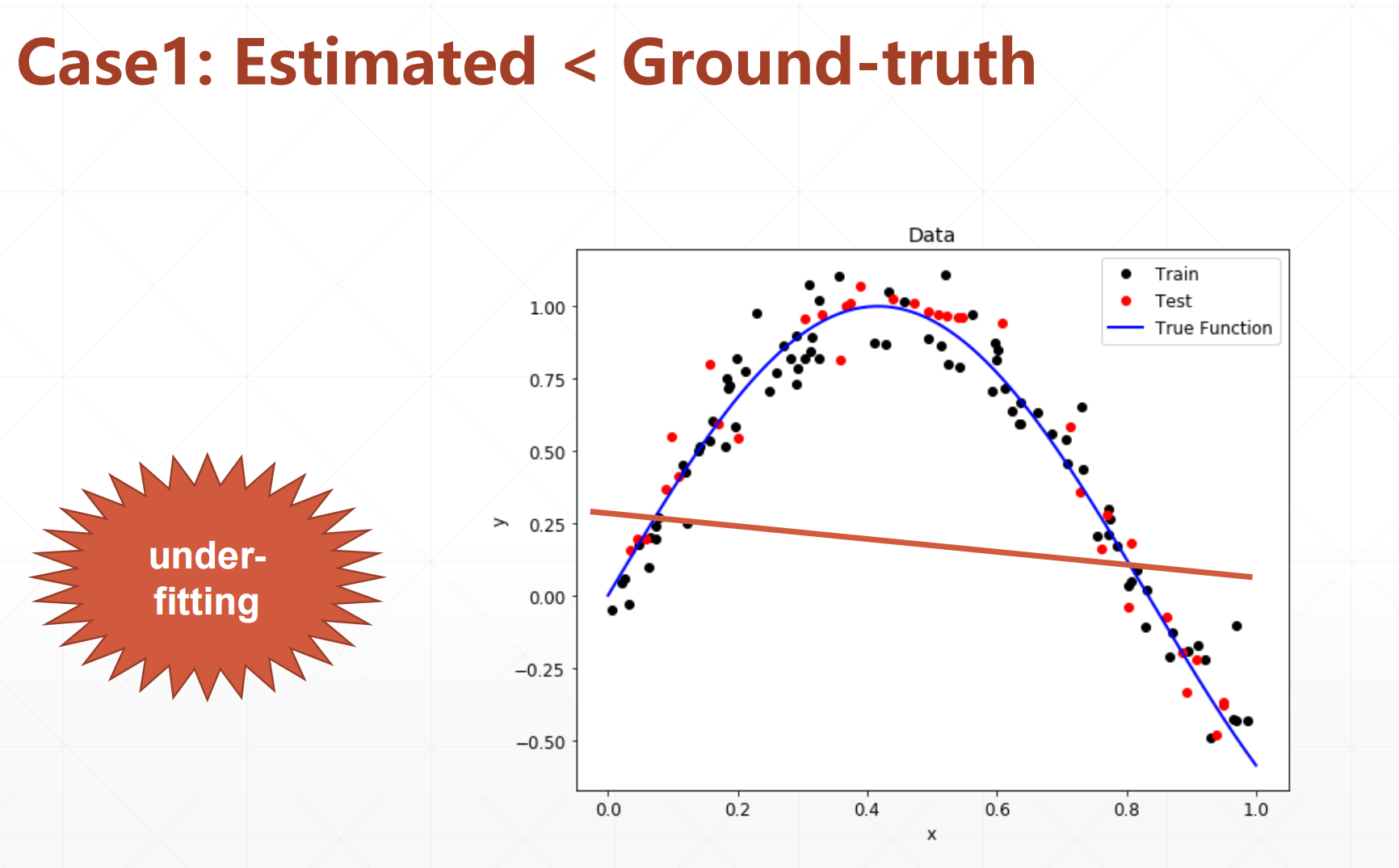
Underfitting:

这个时候我们可以增加模型的复杂度来试试。
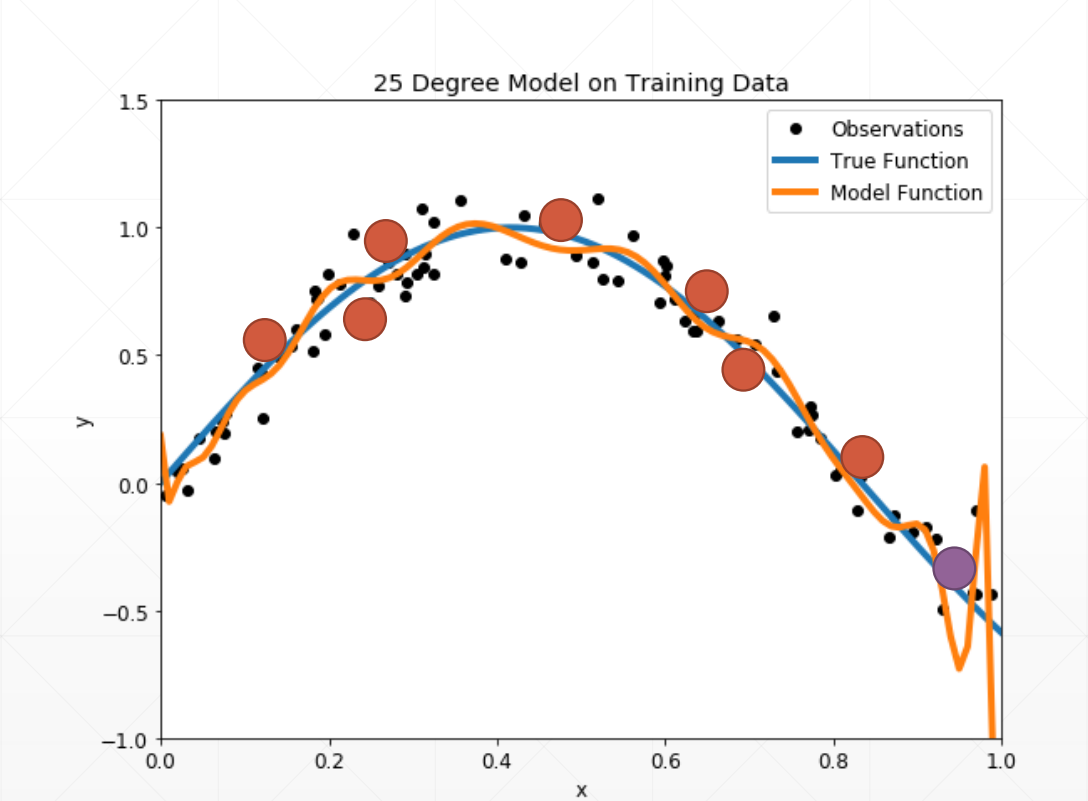
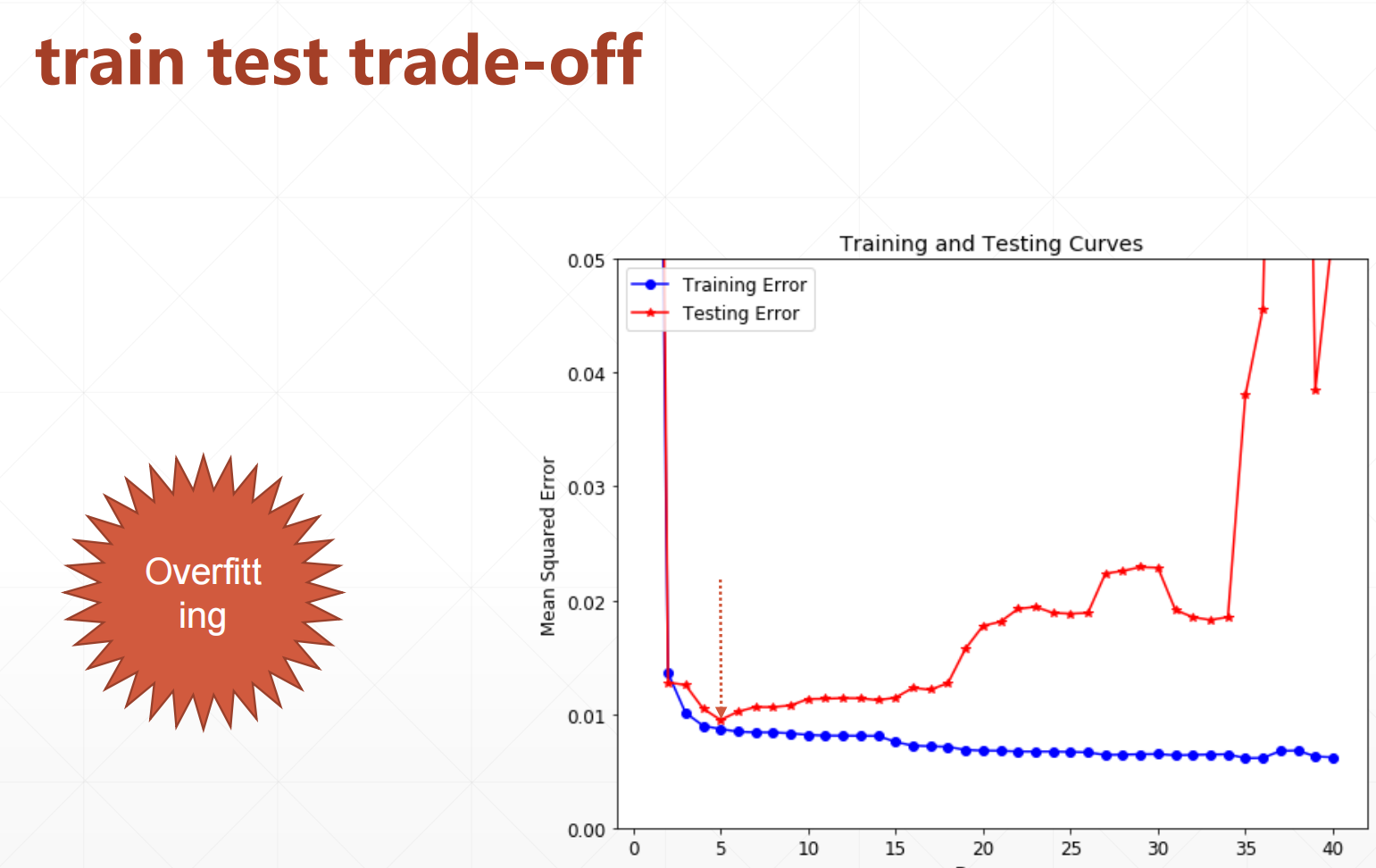
1.2 case2:(过拟合)
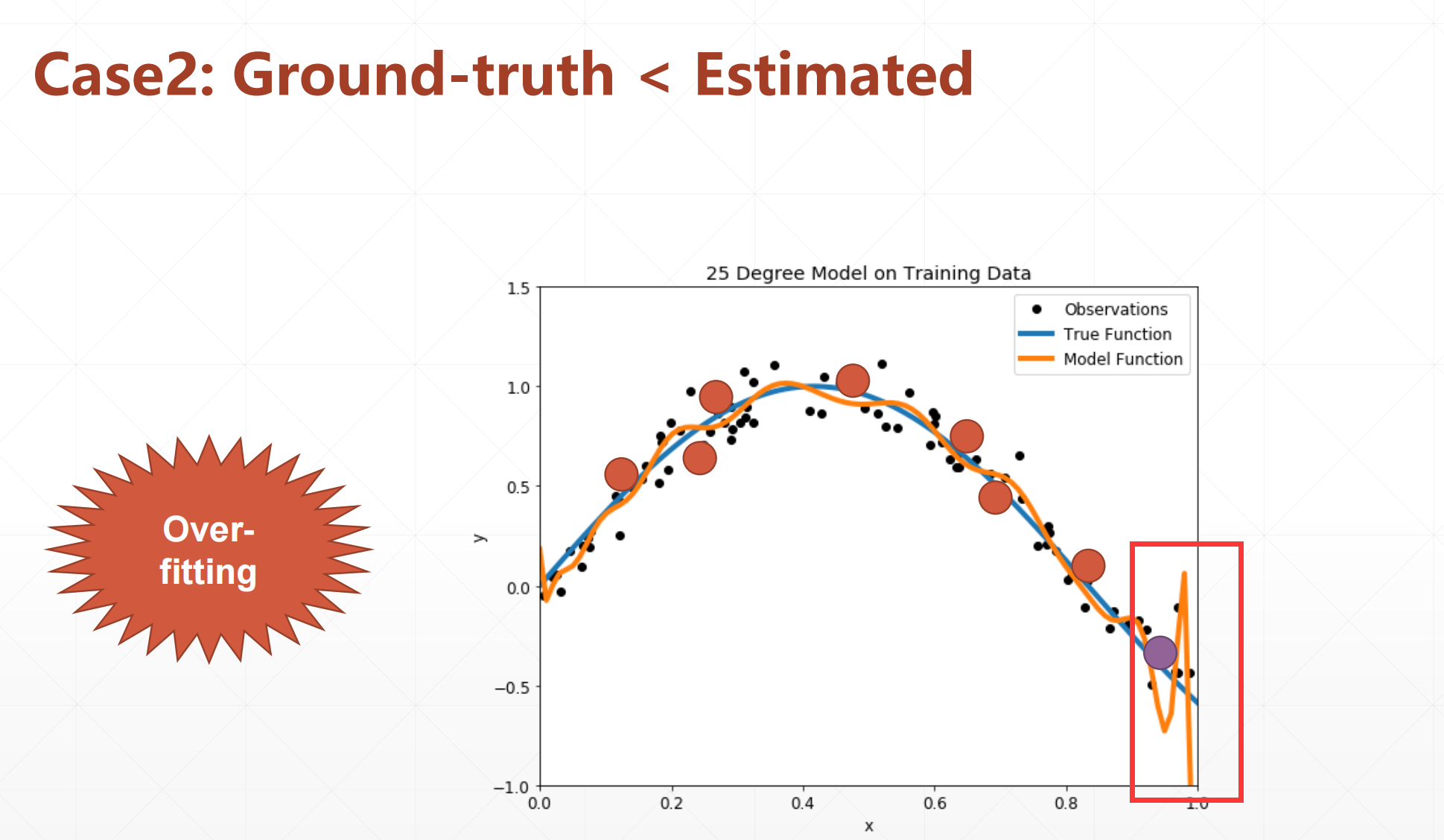
就是我们的模型过分的贴合我们的每一个点,在得再训练集上很好,在测试集里面很不好。

2 交叉验证
我们出现了上面的情况之后,我们最重要的还是:
▪ how to detect
▪ how to prevent
2.1 Train, val, test

然后上面我们的划分:(train,test)
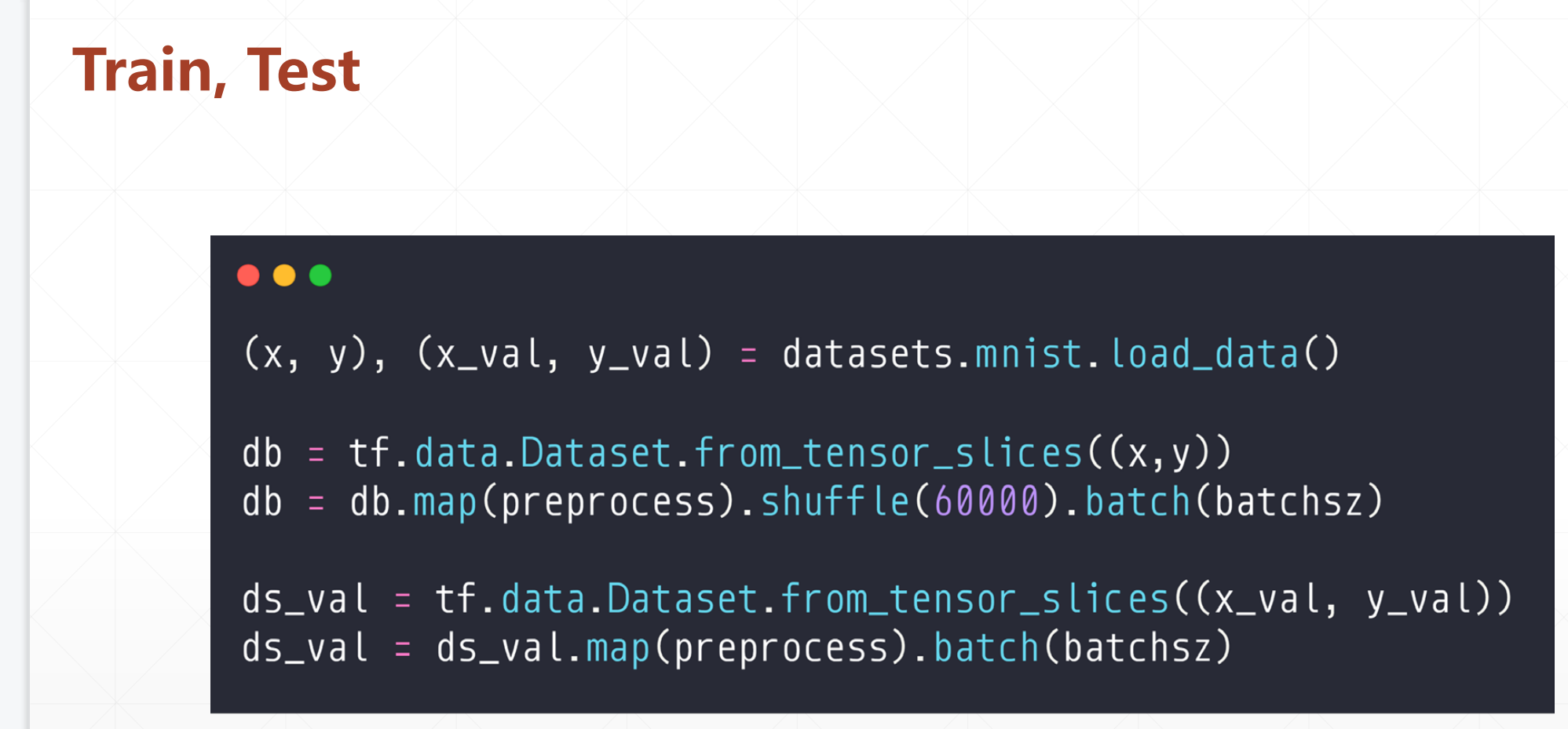
我们优化的时候可以把这个总的数据分割成三份:
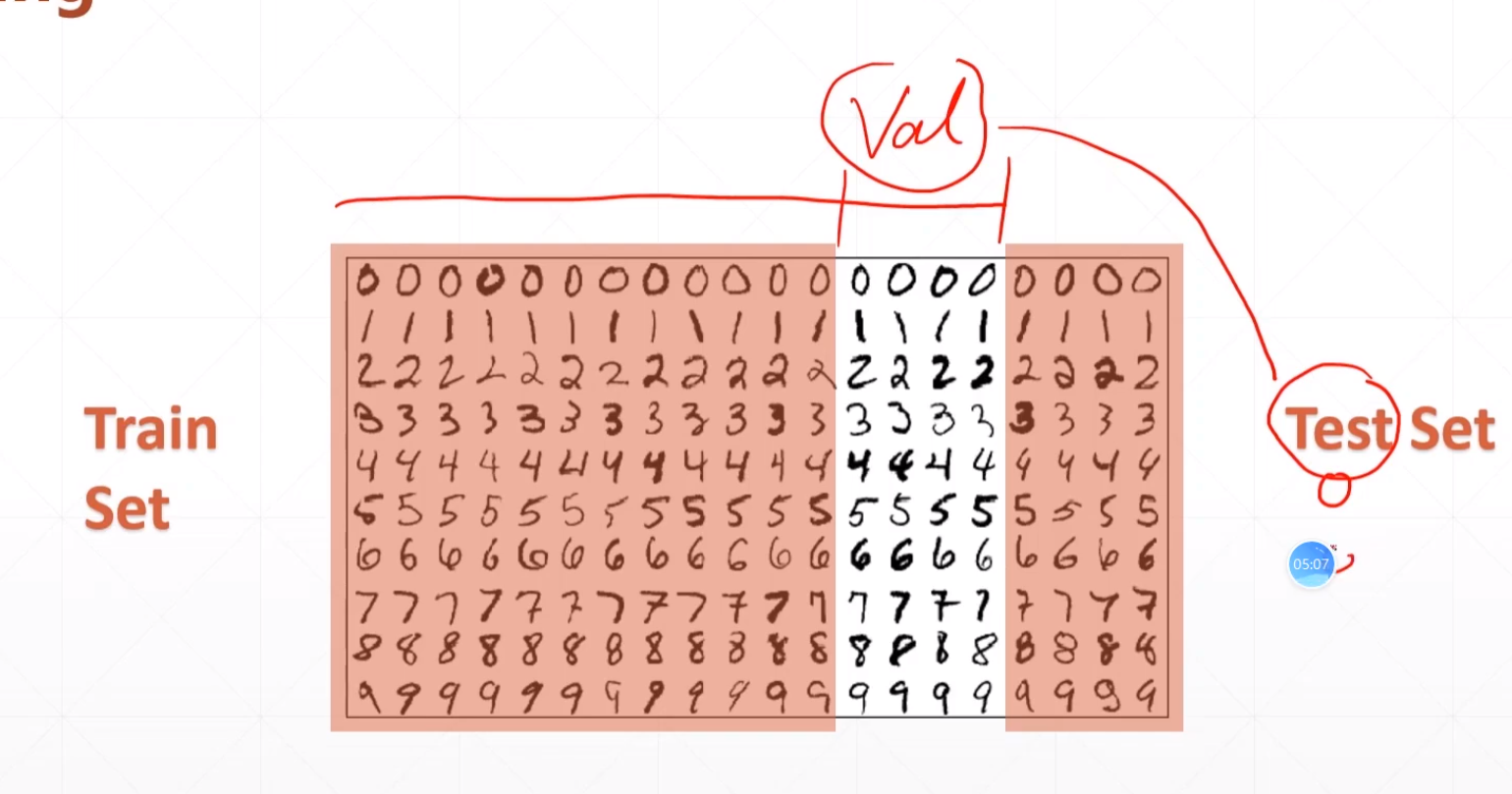
变成train,val,test:
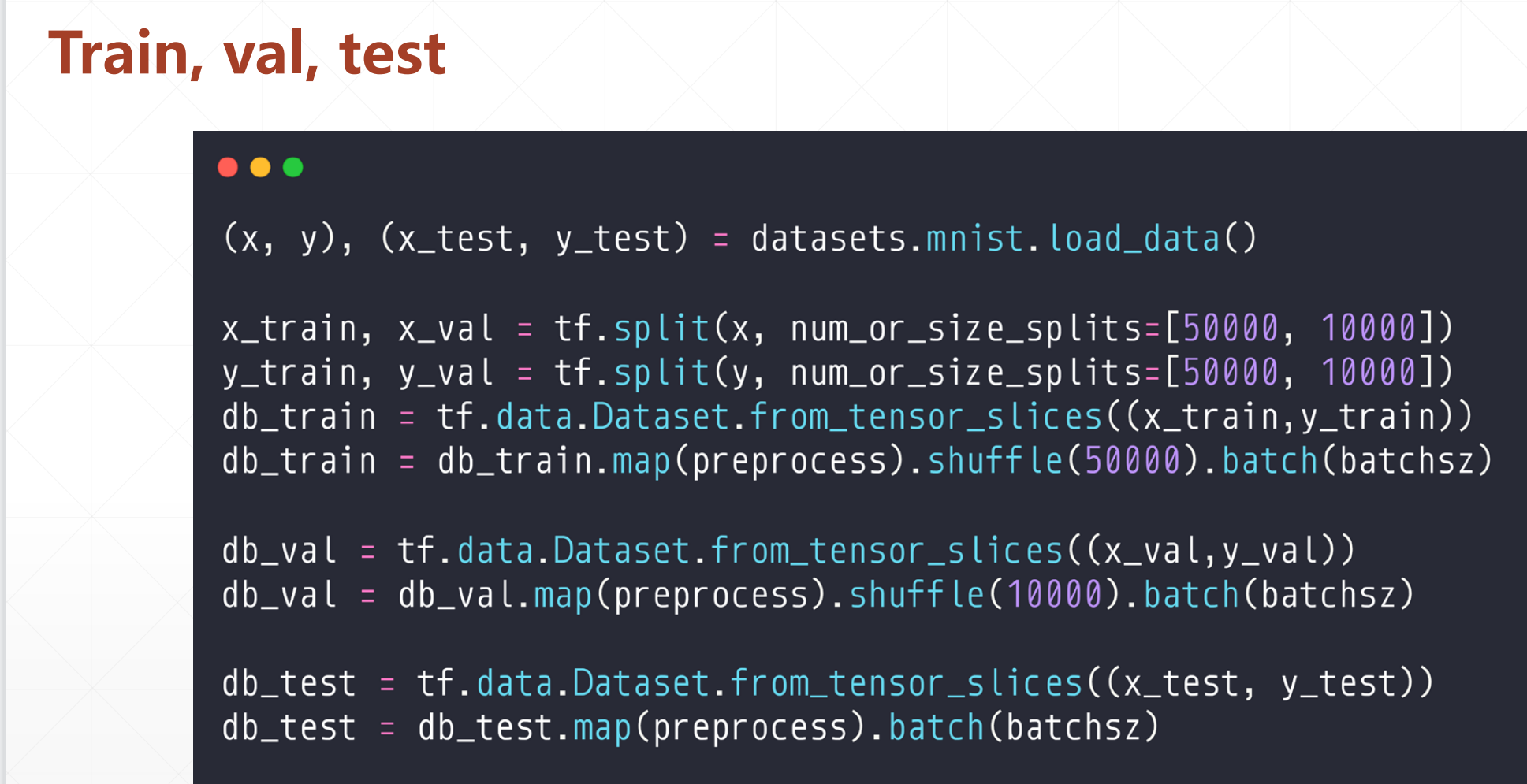
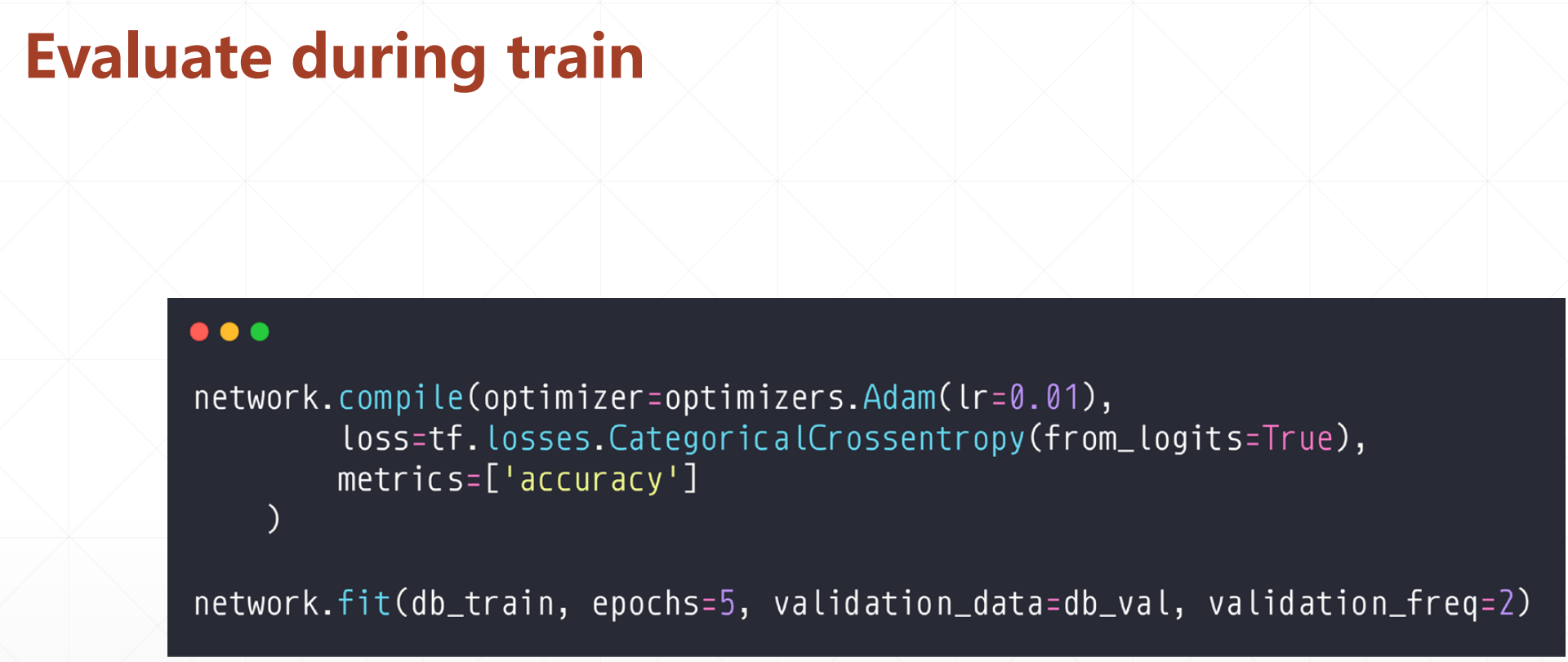
我们第一个在训练中间去预测的时候的数据是db_val,这里面validation_data是要评测的数据,然后validation_freq是评测的间隔。
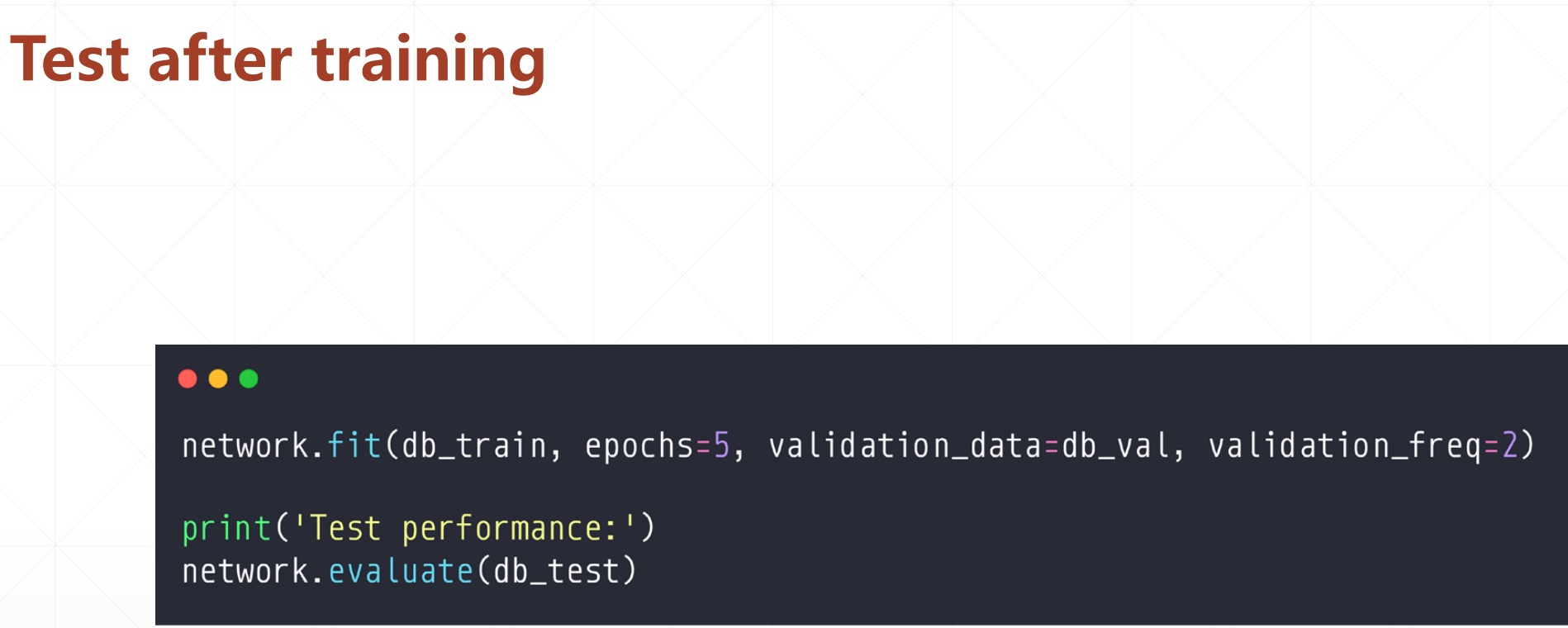
然后我们的最后的预测的时候用的数据就是db_test:
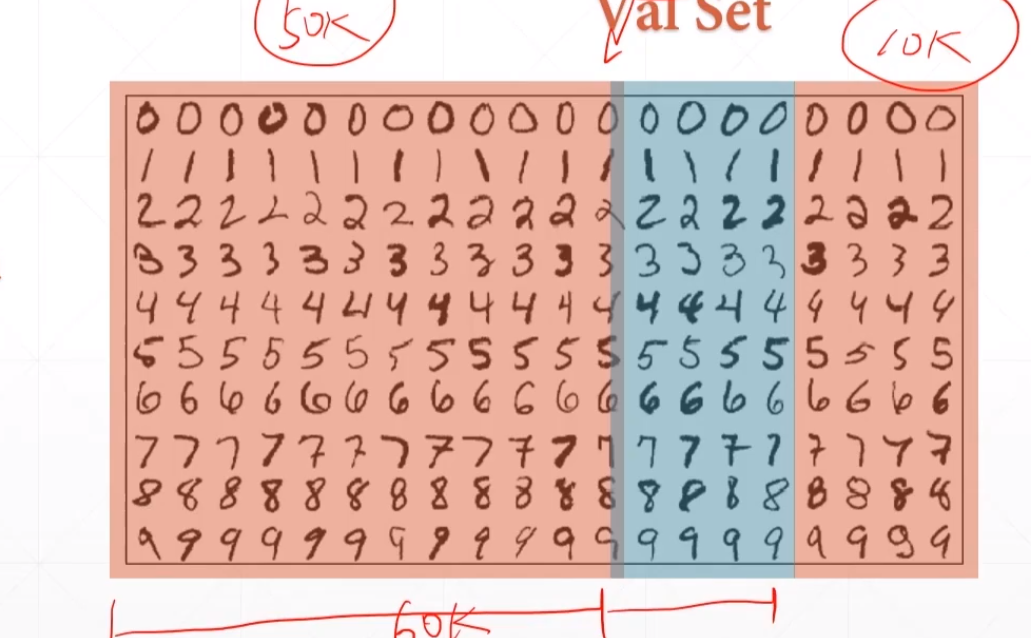
对于我们打比赛或者做项目的时候我们拿不到那些Test Set,我们通常实在train set和val set上面做测试跑参数,然后我们就期待在test set中有一个很好的表现。

所以我们就是需要在Train set中来挑选这个参数,然后我们在val set中进行来停止预测,使得其模型能停在那,有一个很好的参数。最后我们在test set中来测试我们的这些参数。
2.1 K-fold cross-validation
上面那个方法是人为的划分:
比如一个70k的数据集,train set划分50k,val set划分10k,test set划分成10k。
然后就是这个方法的核心:
每次在那60k数据里面,随机划分两部分,一部分是train,一部分val。
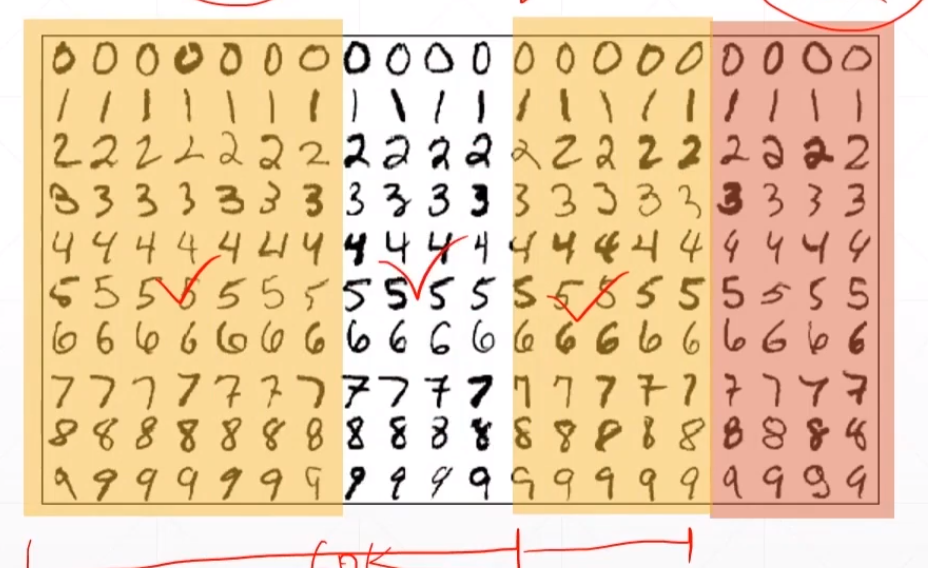
这样会保证每个train set和val set都有可能被train或者val set.
算法的核心就是把中的N分数据,随机的分出n-1分进行train set和那一份就行val set。

这个稍微也是有一点点的提升。
实现:
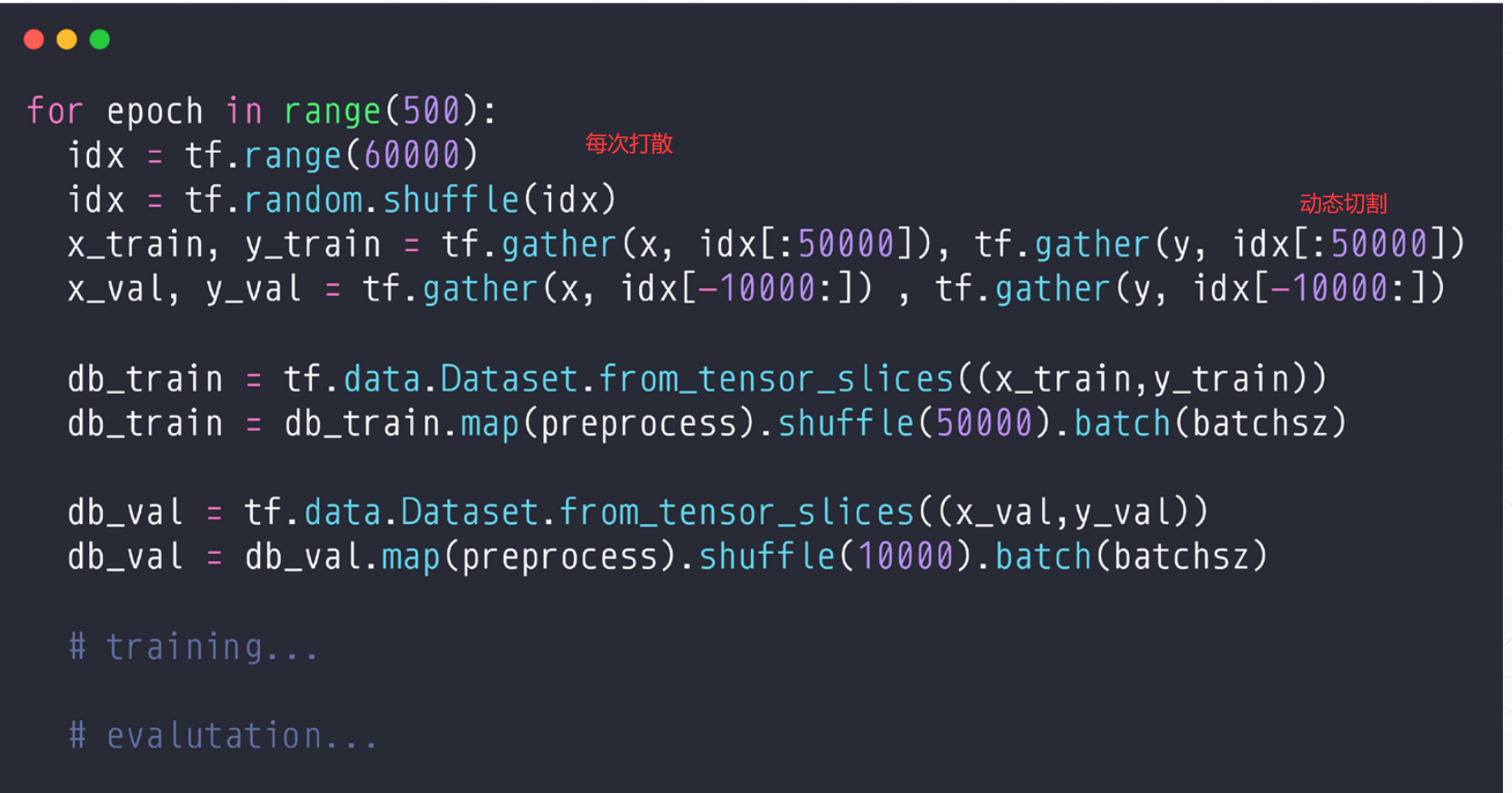
但是上面的比较麻烦。
所以我们有一个比较方便的:

这里validation_split=0.1,就是我们每次都会随机的分成0.9:0.1进行划分。
3 Reduce Overfitted(Weight Decay)
现在overfitted比较常见。
More data(更多的数据)
Constraint model complexity(迫使模型复杂度降低)
- shallow
- regularization(主要讲)
Dropout
Data argumentation
Early Stopping
3.1 regularization
原理
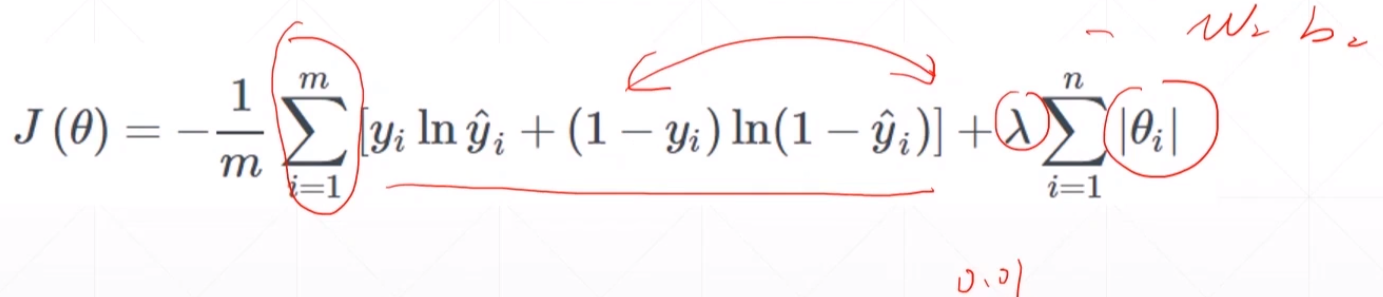
前面一部分使得pred和y的值更加接近。然后后面那一部分使得其参数\(\theta\)的范数接近于0。
比如说我们给了一个七次方的网络,f(x)=\(\Sigma\)\(ax^7\)的一个参数,我们通过着regularization之后会使得其高维度的比如\(x^4\)、\(x^5\)、\(x^6\)、\(x^7\)中的系数权值接近于0,然后使得f(x)=a+\(a_1x\)+\(a_2\)\(x^2\)+\(a_3\)\(x^3\)。达到一个降低模型复杂度的功能,是的模型退化成一个更少次方的网络,并且还保持其性能。
例如:
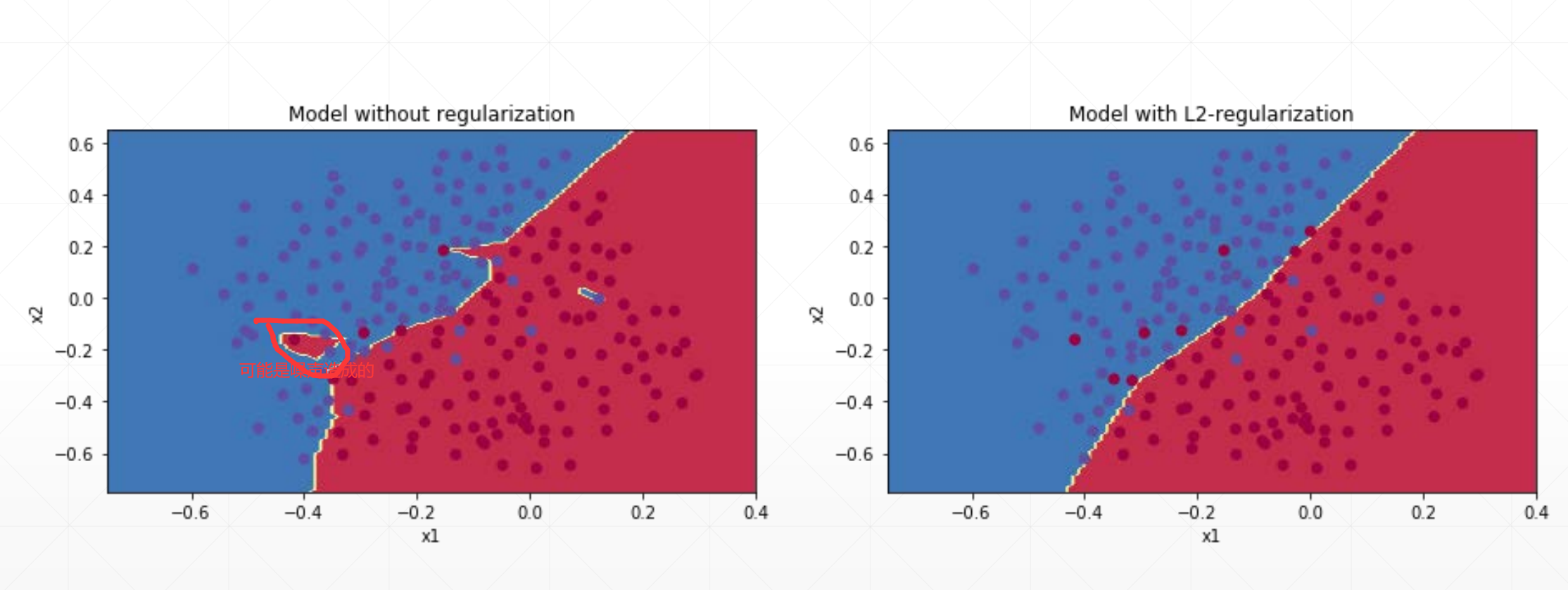
我们发现左边这个模型比较复杂,可能是因为一写噪声造成的。
实现
其中他有两种实现:

第一种实现

然后我们可以看到这个regularizers.l2(0.001)的意思就是loss'=loss+0.001*regularization。
第二种实现
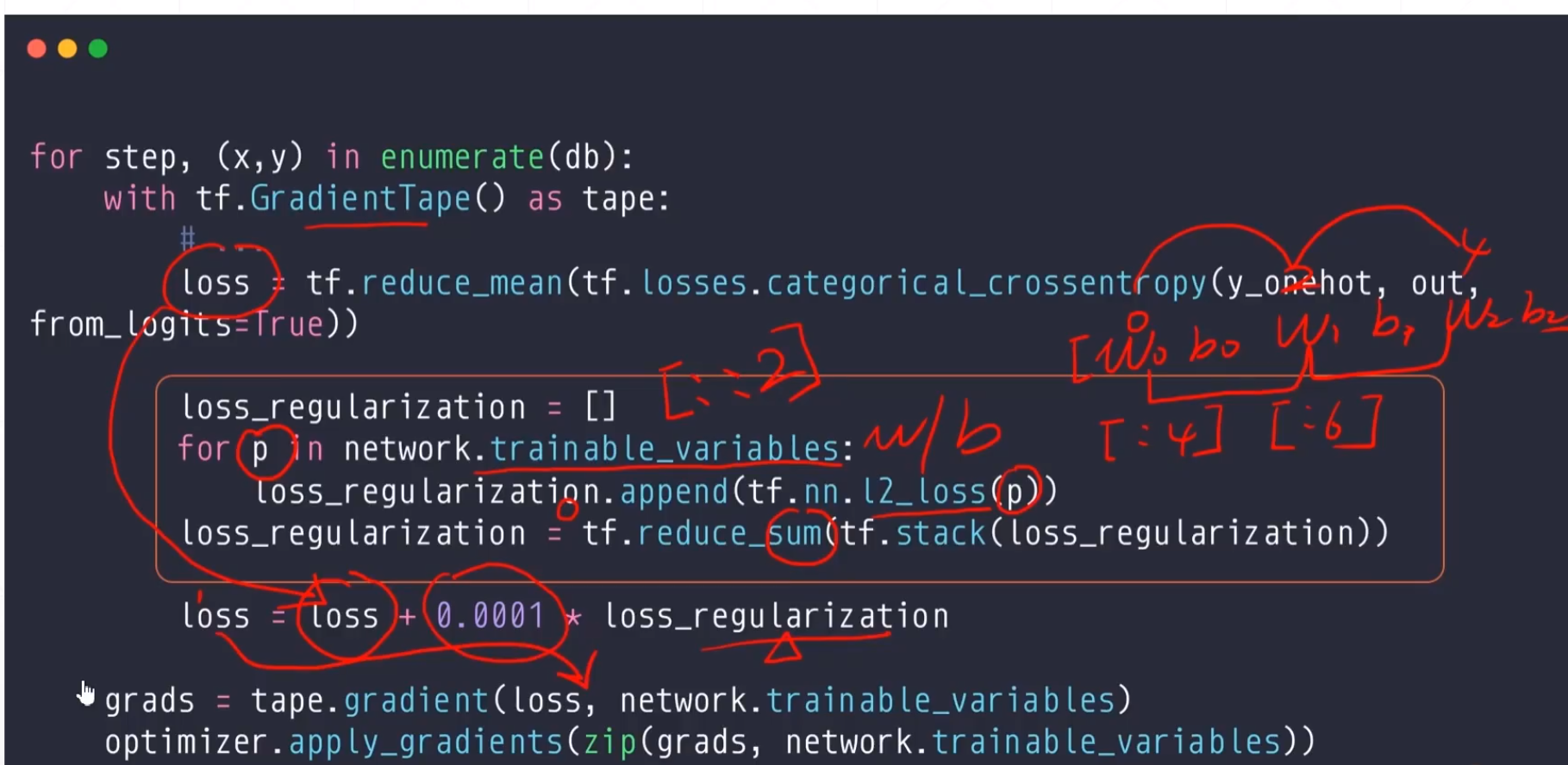
这个实现是比较灵活的,我们如果如果只需要前几层就[:4],我们只需要w的话,就[::2]。