零拷贝
传统拷贝
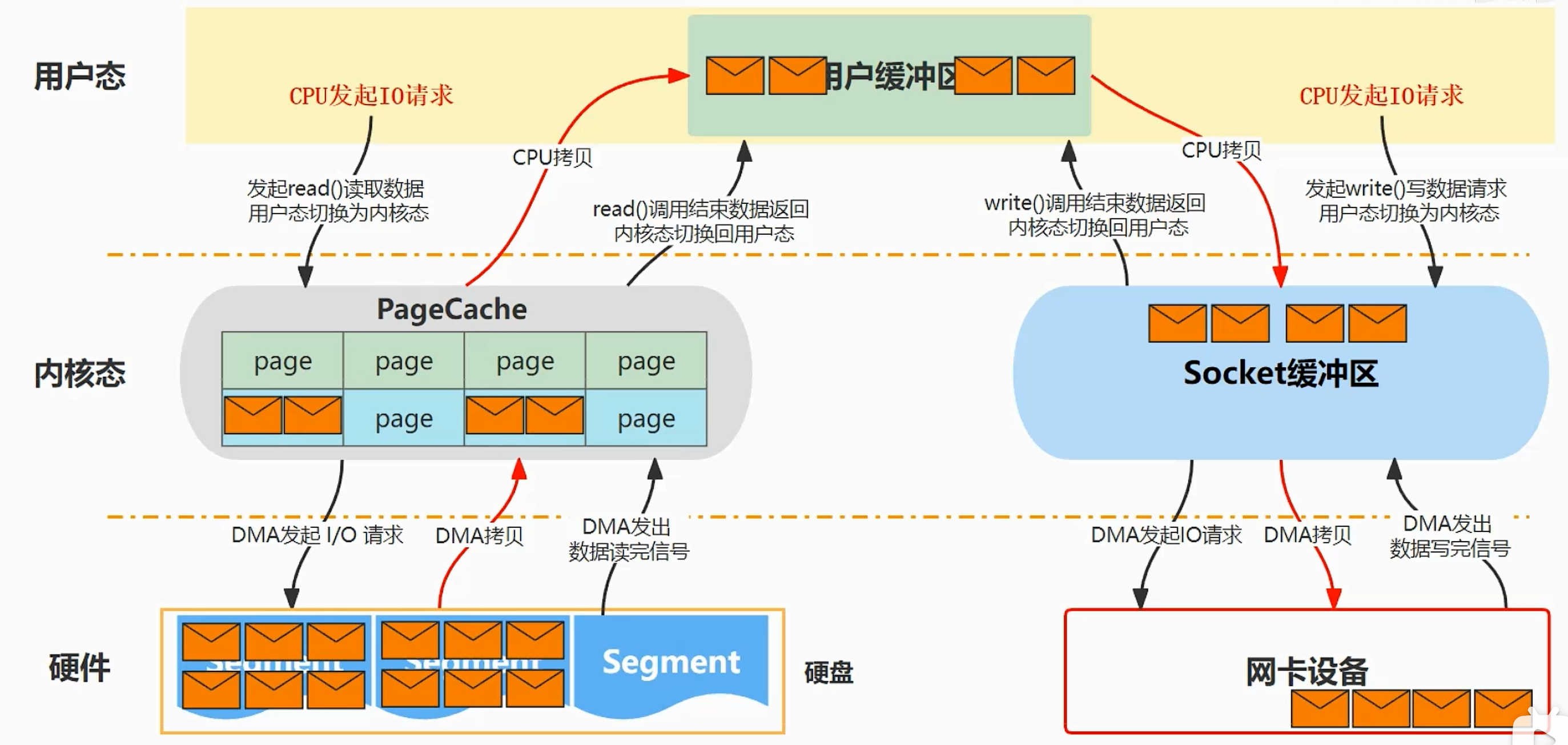
read:
- 当使用read调用来读取数据,此时会将用户态转化为内核态
- CPU对DMA控制器发起一个调用命令
- DMA将数据从硬盘拷贝到内核缓冲区中,拷贝完后通知CPU数据准备好了
- CPU将数据从内核缓冲区中拷贝到用户缓冲区中
- 在4过程中需要将内核态切换为用户态
- 拷贝完后,read调用结束,并唤醒已阻塞的进程
write:
- 当用户线程使用write调用来写入数据,此时会将用户态转化为内核态
- 将用户缓冲区中的数据拷贝到socket缓冲区
- CPU对DMA控制器发起一个调用命令
- DMA控制将数据从socket缓冲区拷贝到网卡设备上(拷贝到网卡,消费者才能消费到数据)
- 拷贝完成后,发送中断信号通知CPU数据已拷贝完成,CPU收到信号后,将内核态切换为用户态,系统调用返回,并唤醒阻塞写的进程
mmap(内存地址映射) + write
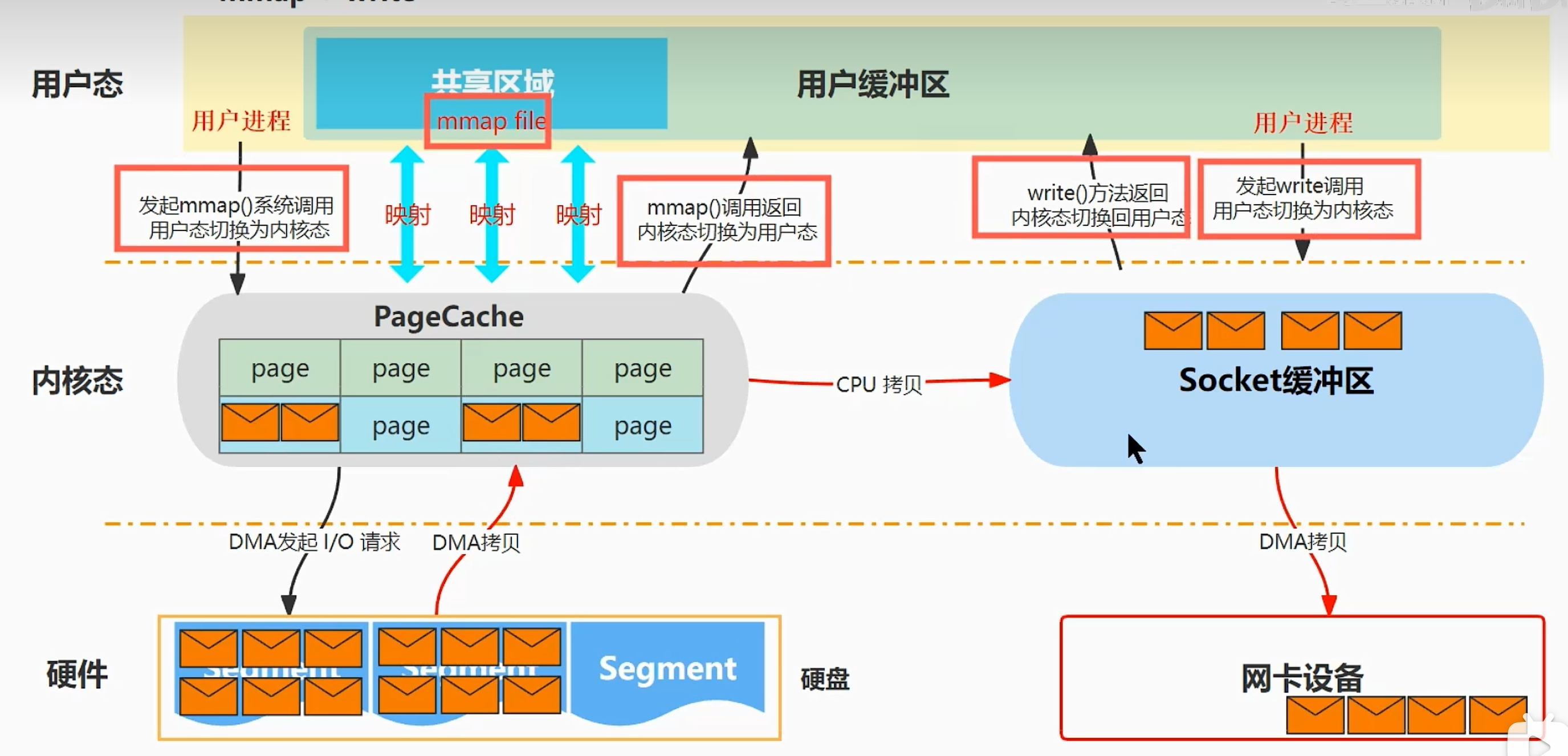
mmap:内存地址映射,将内核空间的PageCache映射到用户缓冲区
- 发现传统拷贝过程中,将数据拷贝到用户空间里并没有做任何修改,所以其实没必要拷贝到这里
- 因此这里采用内存映射的方式,将内核缓冲区映射到用户缓冲区(使用的是虚拟内存,不会占用物理内存),就可以减少一次CPU拷贝过程
- 用户进程发起mmp系统调用,此时用户态切换为内核态
- CPU对DMA控制器发起一个调用命令
- DMA将数据从硬盘拷贝到内核缓冲区中
- 拷贝完成后,mmap方法返回调用,此时内核态切换为用户态
- 用户线程使用write调用来写入数据,此时会将用户态转化为内核态
- CPU直接把数据从内核缓冲区拷贝到socket缓冲区
- DMA控制将数据从socket缓冲区拷贝到网卡设备上
- 拷贝完成后,发送中断信号通知CPU数据已拷贝完成,CPU收到信号后,将内核态切换为用户态,系统调用返回,并唤醒阻塞写的进程
-
总结:mmap读取数据快的原因就是,因为建立了pageCache到用户进程的虚拟地址映射,避免了把数据从pageCache拷贝到用户进程的过程,从而减少了一次CPU拷贝
-
注意,依然是两次系统调用,四次上下文切换,但只有三次数据拷贝,其中一次CPU拷贝,两次 DMA 拷贝
kafka生态系统组成
sendfile
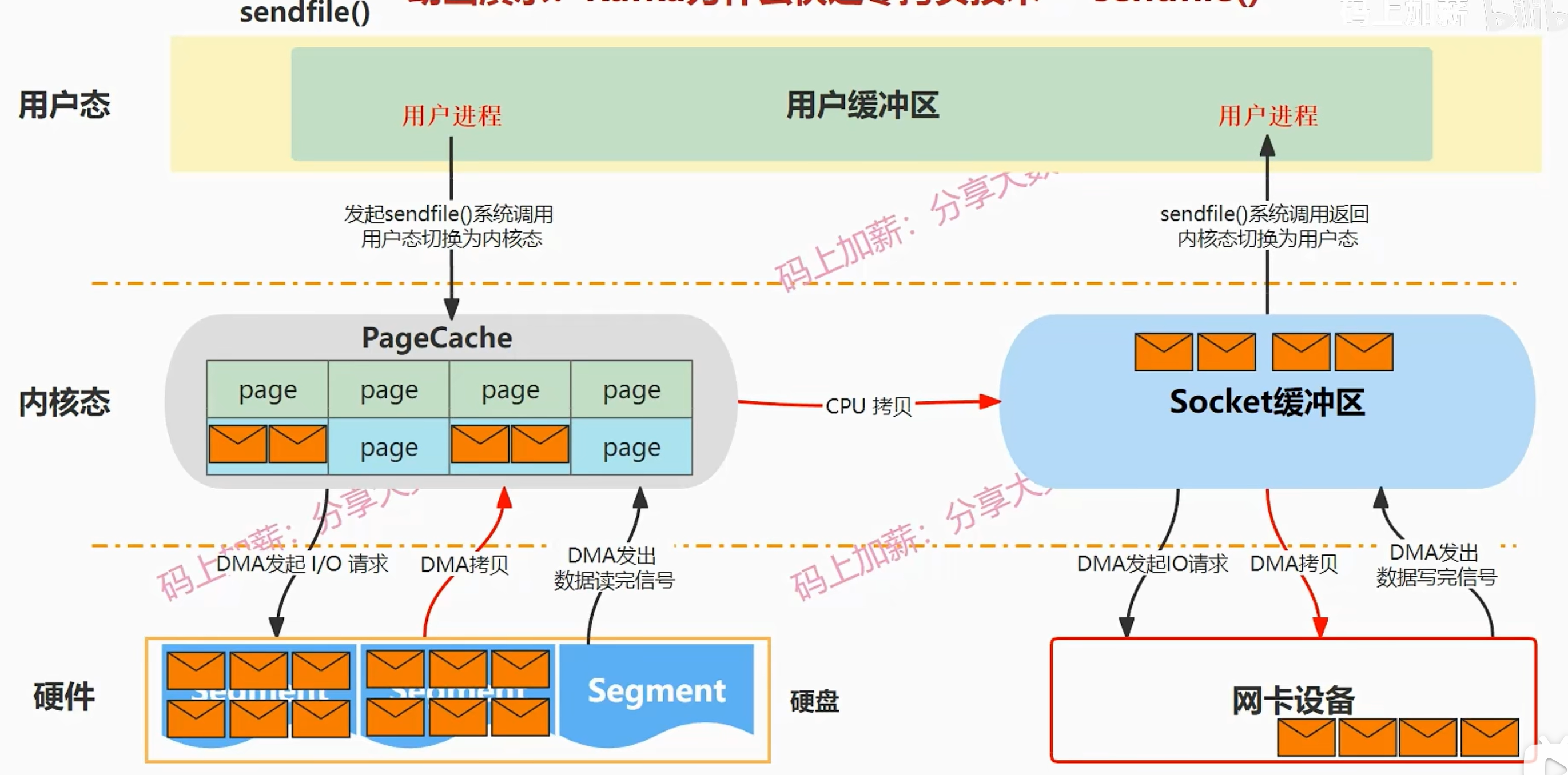
与mmap不同在于:
- 数据是完全不经过用户空间,它是直接把数据从内核缓冲区拷贝到socket缓冲区
- 减少了一次系统调用,sendfile系统调用它是包括了把数据从磁盘拷贝到内核态再拷贝到网卡设备这整个过程,而mmap系统调用不包括把数据从内核态拷贝到网卡设备,这一步需要使用write系统调用
总结:包括一次系统调用,三次数据拷贝,其中一次CPU拷贝、两次DMA拷贝
kafka底层代码调用的是:

这个方法使用了sendfile系统调用
sendfile + DMA gather copy
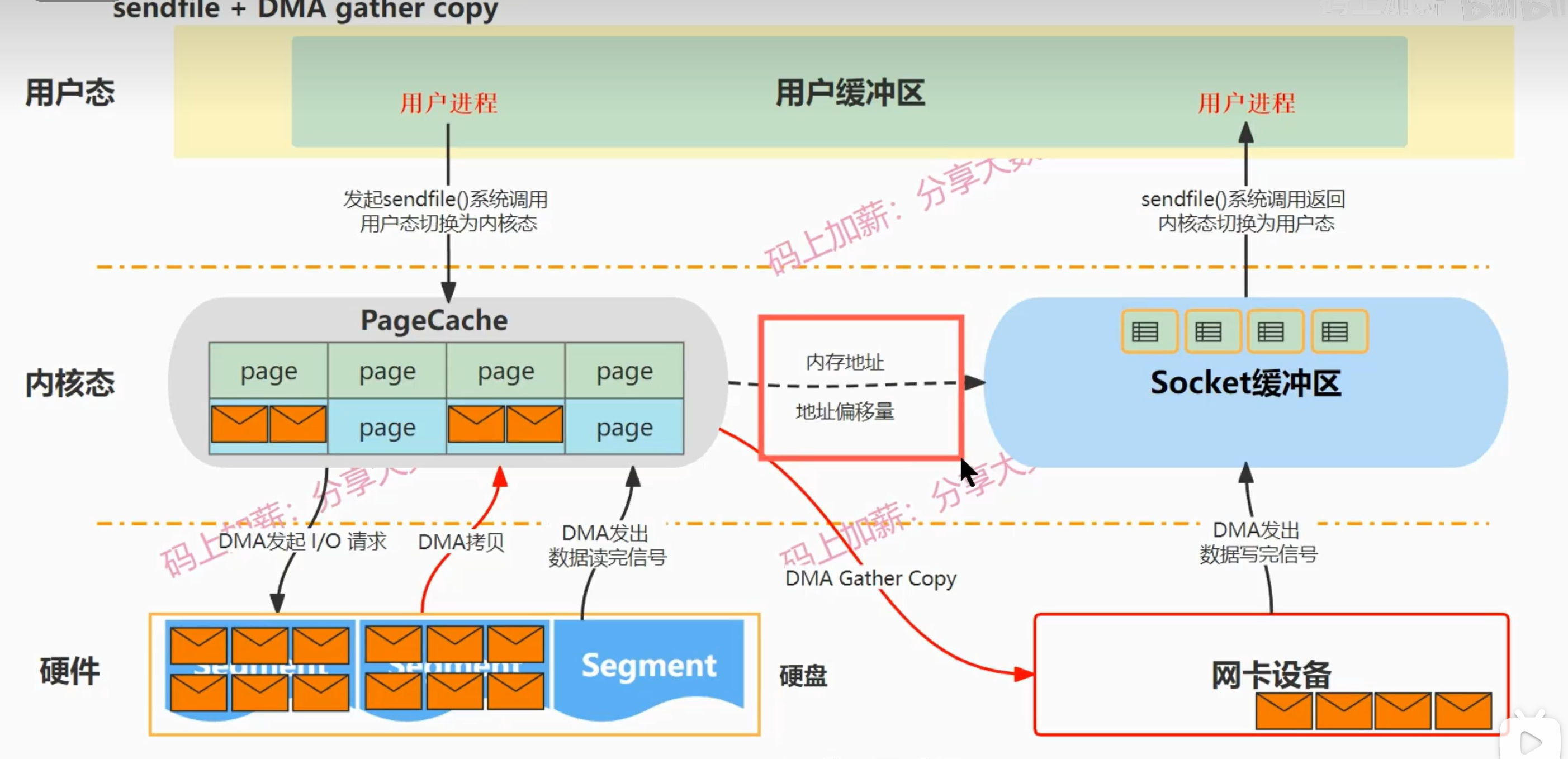
Linux2.4内核版本开始,对sendfile进行了改进
- 引入了gather操作
- 可以实现了无CPU拷贝
与sendfile区别:
- 它是把内核缓冲区中的数据的数据描述信息(包括:内存地址、地址偏移量等)读取到socket缓冲区中,然后就会发生一次DMA gather copy,DMA会根据数据的内存地址和偏移量等信息把数据批量的从内核缓冲区读取到网卡设备上,读取完毕后,发送信号,sendfile系统调用返回,上下文切换到用户态
- 省去了一次CPU拷贝过程
真正的零拷贝:指没有CPU拷贝的过程
splice + DMA copy
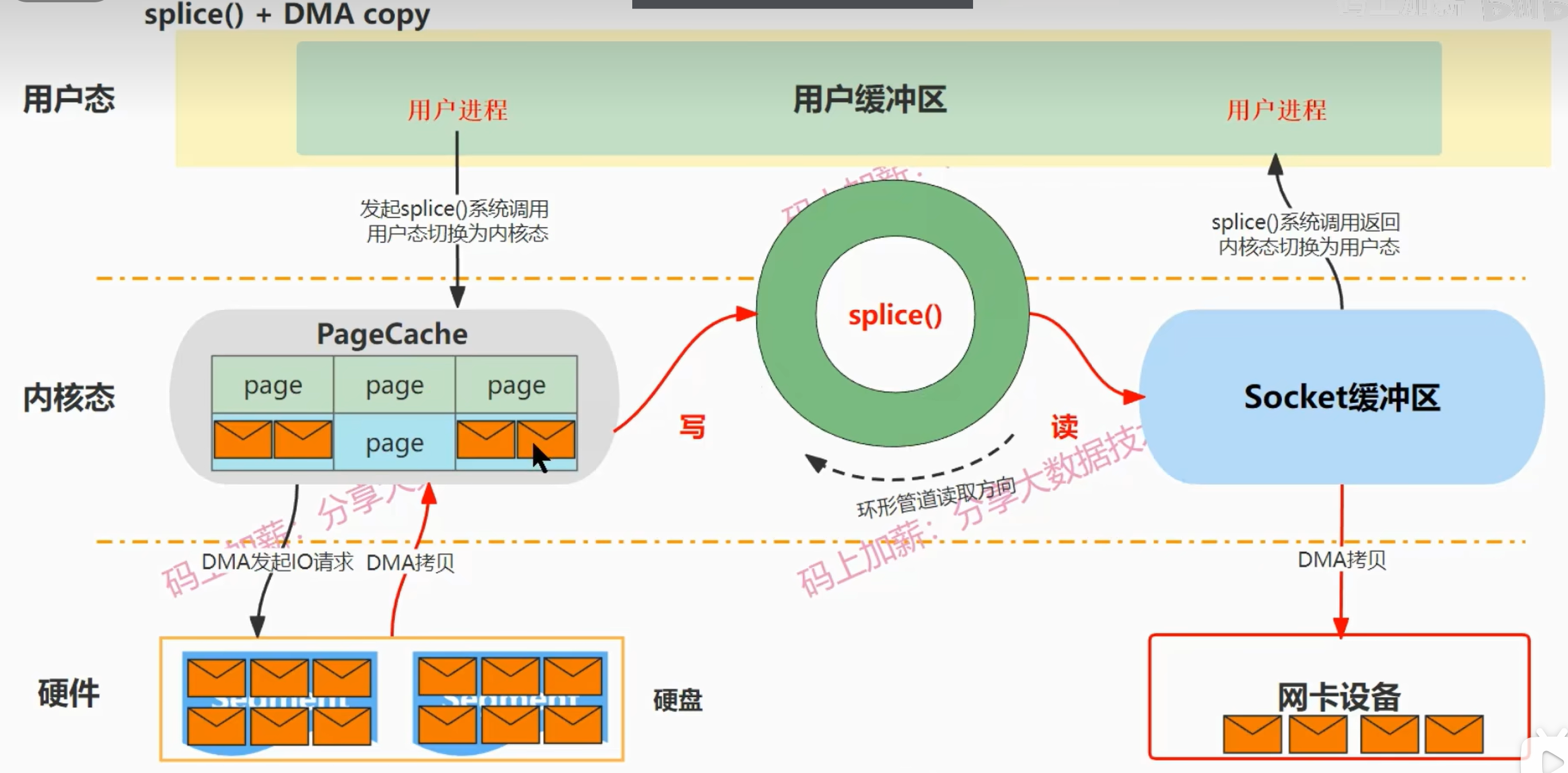
与sendfile的区别:
- 在内核缓冲区与socket缓冲区之间搭建了一个环形的管道,将内核缓冲区绑定到管道的写端,把socket缓冲区绑定到管道的读端,所以数据将通过这个管道被读取到socket缓冲区中,然后通过DMA将数据拷贝到网卡设备上,拷贝完成后,splice函数返回,上下文切换到用户态
- 省去了一次CPU拷贝过程