1 概要
用 Python 语言在只使用 Numpy 库的前提下,完成一个全连接网络的搭建和训练。
2 实现代码
2.1 环境设置
创建 Python 3.8.16 的虚拟环境,激活并执行python -m pip install numpy==1.18.5 tensorflow-gpu==2.3.0 Pillow matplotlib,完成环境配置。
然后执行代码,来导入需要的库。其中,在进行全连接网络的搭建和训练时,仅用到了 Numpy 库。
点击查看环境设置代码
import numpy as np
from tensorflow.keras.datasets import mnist # 在导入数据的时候借用 tensorflow.keras.datasets
import os # 在处理文件路径时借用 os
from PIL import Image # 在处理图像数据时借用 Pillow
import matplotlib.pyplot as plt # 在可视化时借用 matplotlib
import matplotlib
matplotlib.rc("font",family='SimSun') # 设置中文字体
2.2 定义激活函数
\(Sigmoid\) 函数为 \(\psi_{lg} = \frac{1}{1 + e^{-x}}\),其导数为 \(\psi_{lg}^{'} = \psi_{lg} (1 - \psi_{lg})\)。
点击查看进行激活函数定义的代码
# region >>> 激活函数 >>>
def sigmoid(np2d_arr):
"""
Sigmoid 函数
"""
return 1 / (1 + np.exp(-np2d_arr))
def d_sigmoid(np2d_arr):
"""
Sigmoid 函数的偏导数
"""
sgm = sigmoid(np2d_arr)
return sgm * (1 - sgm)
# endregion <<< 激活函数 <<<
2.3 定义优化器
Adam 算法使用状态变量 \(v_t \leftarrow \beta_1 v_{t-1} + (1 - \beta_1) g_t\) 和 \(s_t \leftarrow \beta_2 s_{t-1} + (1 - \beta_2) g_t^2\),其中,\(\beta_1\) 和 \(\beta_2\) 是非负加权参数,通常设置为 \(\beta_1=0.9\) 和 \(\beta_2=0.999\),\(g_t\) 表示梯度。
\(v_t\) 和 \(s_t\) 相应的标准化状态变量分别为 \(\hat v_t = \frac{v_t}{1-\beta_1^t}\) 和 \(\hat s_t = \frac{s_t}{1-\beta_2^t}\)。
然后就可以写出更新方程 \(x_t \leftarrow x_{t-1} - g_t^{'}\),其中,\(g_t^{'} = \frac{\eta \hat v_t}{\sqrt{\hat s_t} + \epsilon}\),\(\eta\) 表示学习率,通常 \(\epsilon = 10^{-6}\)。
点击查看进行优化器定义的代码
# region >>> 优化器 >>>
class Adam():
def __init__(self, learning_rate=0.001, b1=0.9, b2=0.999):
self.learning_rate = learning_rate
self.eps = 1e-6
self.v = None
self.s = None
# 衰减率
self.b1 = b1
self.b2 = b2
def update(self, w, grad_wrt_w):
if self.s is None:
self.v = np.zeros(np.shape(grad_wrt_w))
self.s = np.zeros(np.shape(grad_wrt_w))
self.v = self.b1 * self.v + (1 - self.b1) * grad_wrt_w
self.s = self.b2 * self.s + (1 - self.b2) * np.power(grad_wrt_w, 2)
v_hat = self.v / (1 - self.b1)
s_hat = self.s / (1 - self.b2)
self.w_updt = self.learning_rate * v_hat / (np.sqrt(s_hat) + self.eps)
return w - self.w_updt
# endregion <<< 优化器 <<<
2.4 定义全连接网络
全连接网络使用交叉熵作为损失函数,通过反向传播更新参数。
其中,对于交叉熵损失的计算,假设有单个样本,其真实分布为 \(y\),网络输出分布为 \(\hat y\),分类的总类别数为 \(n\),则其计算的方式为 \(Loss = - \Sigma_{i=1}^{n} y_i \log{\hat y_i}\)。
在反向传播的过程中,通过 Adam 算法计算参数的变化量 \(g_t^{'}\),来代替梯度 \(g_t\) 进行权重的更新。
另外,为损失函数添加了正则项 \(\lambda \| w \|\),\(\lambda=0.1\),缩小解空间,从而减少求出过拟合解的可能性。
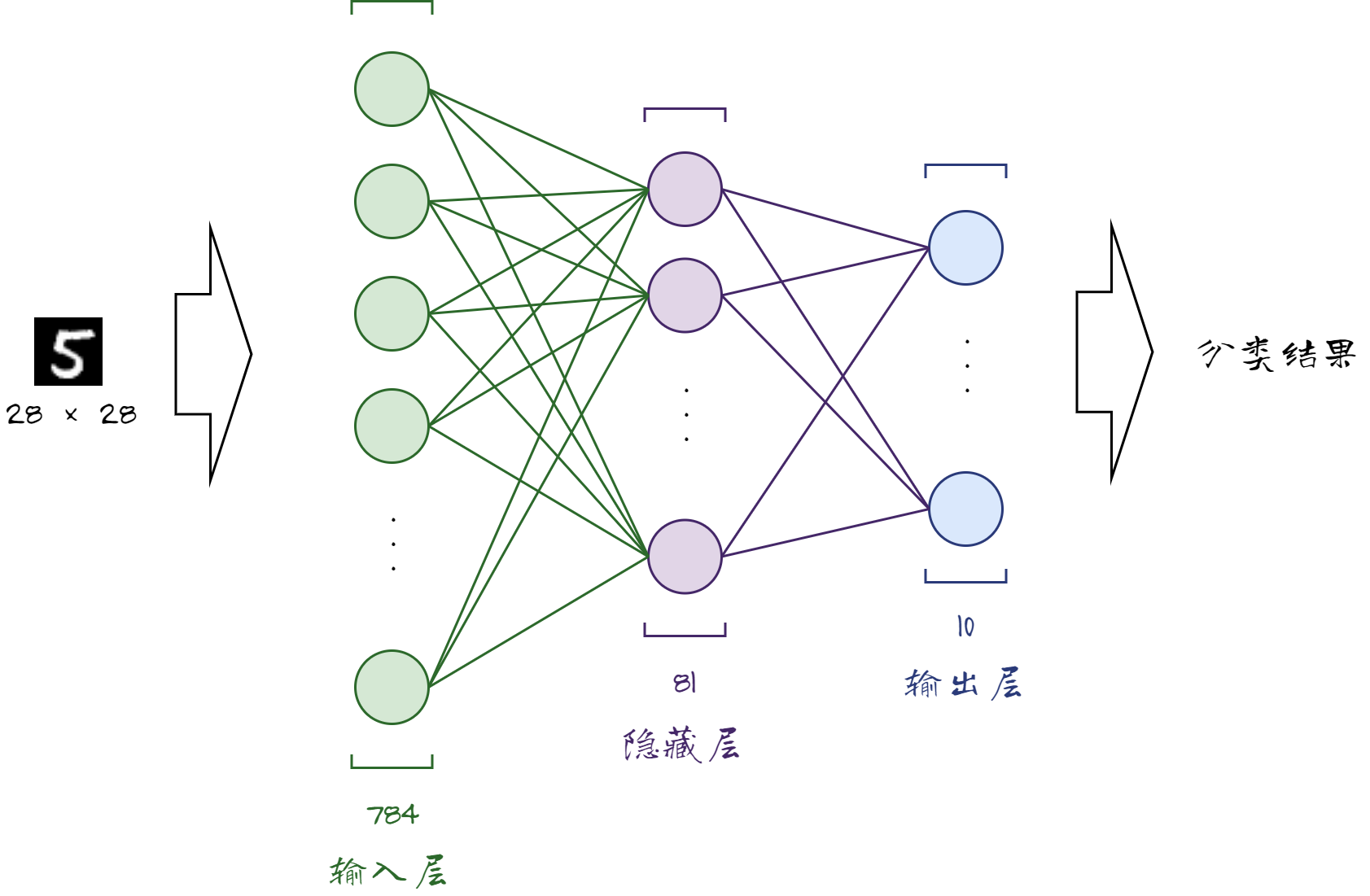
从MNIST数据集读取的每张图片都是 28 × 28 的像素矩阵,将其转换成长度为 784 的一维向量输入全连接网络。全连接网络的网络结构如下图所示(仅供参考),输入层 784 个神经元,隐藏层 81 个神经元,输出层 10 个神经元。
点击查看定义全连接网络的代码
# region >>> 全连接网络 >>>
class FullyConnectedNN(object):
"""
全连接神经网络
"""
@property
def num_layers(self):
# 神经网络的层数
return self.__num_lyr
def __init__(self, layer_dims, activ_funcs):
# 层数
self.__num_lyr = len(layer_dims)
# 隐藏层和输出层的输入矩阵
self.lyr_in = dict()
# 所有层的输出矩阵,初始化为一个空字典
self.lyr_out = {0: np.array([])}
# 隐藏层和输出层的权重矩阵
self.weight = dict()
# 隐藏层和输出层的偏置列向量
self.bias = dict()
# 隐藏层和输出层的激活函数
self.__ac_func = dict()
# 对隐藏层和输出层的参数进行初始化
for i in range(1, self.__num_lyr, 1):
self.lyr_in[i] = np.array([])
self.lyr_out[i] = np.array([])
self.weight[i] = np.random.uniform(
# 随机初始化权重矩阵
low=-1, high=1, size=(layer_dims[i], layer_dims[i - 1])
)
self.bias[i] = np.random.uniform(-1, 1, (layer_dims[i], 1)) # 随机初始化偏置列向量
self.__ac_func[i] = activ_funcs[i - 1] # 设置激活函数
# 反向传播过程中的误差矩阵
self.bp_err = np.array([])
# 更新前为反向传播过程存储的权重矩阵
self.bp_wgt = np.array([])
def grad_loss_out(self):
# 损失函数对输出矩阵元素的偏导数
return self.bp_err @ self.bp_wgt # 误差矩阵与权重矩阵的乘积
def grad_loss_weight(self, layer_id):
# 损失函数关于权重矩阵元素的偏导数
return self.bp_err.T @ self.lyr_out[layer_id - 1] # 误差矩阵的转置与上一层的输出矩阵的乘积
def grad_loss_bias(self):
# 损失函数关于偏置列向量元素的偏导数
err0_sum = self.bp_err.sum(0)
return err0_sum.reshape((err0_sum.shape[0], 1)) # 误差矩阵的每一列求和,然后转换为列向量
def forward(self, features):
# 前向传播
self.lyr_out[0] = features # 输入层的输出矩阵就是输入特征矩阵
for i in range(1, self.__num_lyr, 1):
self.lyr_in[i] = ( # 隐藏层和输出层的输入矩阵
self.weight[i] @ self.lyr_out[i - 1].T + self.bias[i]
).T
self.lyr_out[i] = self.__ac_func[i](self.lyr_in[i]) # 输出等于激活函数作用于输入
class BackpropagationNN(FullyConnectedNN):
"""
全连接网络中的反向传播
"""
def set_learning_rate(self, rate):
# 初始化学习率
self.__lr = rate if 0 < rate < 1 else 0.01
def cal_out_err(self):
# 计算输出层的误差矩阵
pass
def __init__(self, layer_dims, activ_funcs, hid_grad_activ_funcs):
super().__init__(layer_dims, activ_funcs)
# 标签矩阵
self.label = None
# 学习率
self.__lr = 0.01
# 所有隐藏层激活函数的导数
self.__hid_grd_acf = dict()
# 输出层 id, 输出层的一个键
self.max_lid = self.num_layers - 1
for i in range(1, self.max_lid, 1):
self.__hid_grd_acf[i] = hid_grad_activ_funcs[i - 1]
def __adjust_weight(self, layer_id):
# 使用Adam优化器更新权重矩阵
self.weight[layer_id] = Adam(learning_rate=self.__lr) \
.update(self.weight[layer_id], self.grad_loss_weight(layer_id))
def __adjust_bias(self, layer_id):
# 调整偏置列向量
self.bias[layer_id] -= self.__lr * self.grad_loss_bias()
def __call_hid_err(self, layer_id):
# 计算隐藏层的误差矩阵
self.bp_err = self.__hid_grd_acf[layer_id](
self.lyr_in[layer_id]) * self.grad_loss_out() # 隐藏层的误差矩阵等于隐藏层的激活函数的导数与输出层的误差矩阵的乘积
self.bp_wgt = self.weight[layer_id] # 更新前的权重矩阵
def __backward(self):
self.bp_err = self.cal_out_err() # 计算输出层的误差矩阵
self.bp_wgt = self.weight[self.max_lid] # 用输出层的权重矩阵更新反向传播过程中的权重矩阵
self.__adjust_weight(self.max_lid) # 调整权重矩阵
self.__adjust_bias(self.max_lid) # 调整偏置列向量
for i in range(self.max_lid - 1, 0, -1):
self.__call_hid_err(i) # 计算隐藏层的误差矩阵
self.__adjust_weight(i) # 调整隐藏层的权重矩阵
self.__adjust_bias(i) # 调整隐藏层的偏置列向量
# 训练一个批次(向前传播遍历了神经网络的所有层,然后向后传播更新了权重矩阵和偏置列向量)
def train_one_batch(self, features, labels):
self.forward(features)
self.label = labels
self.__backward()
# 训练一个周期,一个周期包含 batch_size 个批次
def train_one_epoch(self, features, labels, batch_size):
num_sp = labels.shape[0] # 样本数量
iteration = (num_sp + batch_size - 1) // batch_size # 迭代次数
index = np.arange(0, num_sp, 1) # 样本索引
# 打乱样本顺序
np.random.shuffle(index)
ite_idx = 0
for i in range(iteration):
# 在打乱的样本中取出一个批次大小的样本,进行小批量梯度下降
sub_idx = index[ite_idx:ite_idx + batch_size:1]
sub_features = features[sub_idx]
sub_labels = labels[sub_idx]
self.train_one_batch(sub_features, sub_labels)
ite_idx += batch_size
class SoftmaxClassifier(BackpropagationNN):
"""
基于交叉熵和Softmax 的分类器
"""
@staticmethod
def softmax(np2d_arr):
# Softmax 函数
row_max = np.amax(np2d_arr, axis=1) # 每一行的最大值
exp_matrix = np.exp(np2d_arr - row_max.reshape((row_max.shape[0], 1))) # 每一行减去该行的最大值,然后取指数
row_sum = np.sum(exp_matrix, axis=1) # 指数运算后的矩阵的每一行的和
return exp_matrix / row_sum.reshape((row_sum.shape[0], 1))
def ce_loss(self, outputs, labels):
# 交叉熵损失函数
cross_entropy_loss = -np.sum(labels * np.log(np.where(outputs == 0, 0.001, outputs))) / labels.shape[0]
# 添加 L1 正则化项
l1_reg = self.__lambda * np.sum(np.abs(outputs))
loss = cross_entropy_loss + l1_reg
return loss
def cal_out_err(self):
# 输出层的误差矩阵 等于输出层的输出矩阵减去标签矩阵,然后除以样本数量
return (self.lyr_out[self.max_lid] - self.label) / self.label.shape[0]
def __init__(self, layer_dims, hid_activ_funcs, hid_grad_activ_funcs):
activ_funcs = [func for func in hid_activ_funcs]
activ_funcs.append(self.softmax)
super().__init__(layer_dims, activ_funcs, hid_grad_activ_funcs)
self.loss = []
self.accuracy = []
# 正则化项参数
self.__lambda = 1e-1
def train_mul_epoch(self, features, labels, batch_size, epoch_size,
test_features=None, test_labels=None):
# 训练多个周期
test_x = features if test_features is None else test_features
test_y = labels if test_labels is None else test_labels
for i in range(epoch_size):
self.train_one_epoch(features, labels, batch_size)
# 在测试集上测试损失和准确率
_features = test_x
_labels = test_y
self.forward(_features)
loss = self.ce_loss(self.lyr_out[self.max_lid], _labels)
outputs = np.argmax(self.lyr_out[self.max_lid], axis=1)
_labels = np.argmax(_labels, axis=1)
accu = np.sum(outputs == _labels) / _labels.shape[0]
print('周期: {: <6}'.format(i), end='')
print('损失: {: <15.6f}'.format(loss), end='')
print('准确率: {:.6f}'.format(accu))
self.loss.append(loss)
self.accuracy.append(accu)
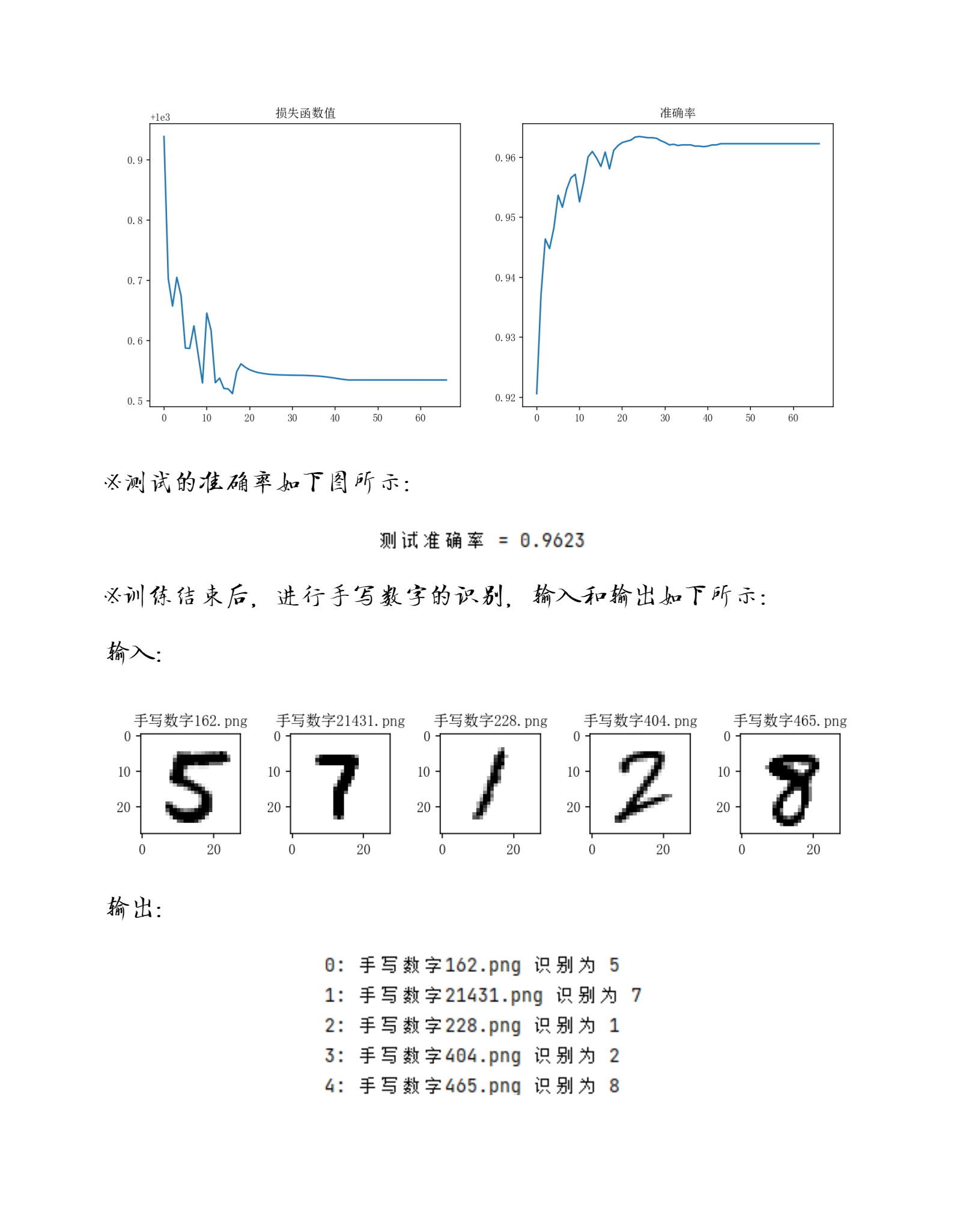
# 可视化训练过程
def visual_training(self):
fig = plt.figure(figsize=(12, 5))
# 损失函数
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(self.loss)
ax1.set_title('损失函数值')
# 准确率
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(self.accuracy)
ax2.set_title('准确率')
plt.show()
# 测试准确率
def test_accuracy(self, features, labels):
self.forward(features)
outputs = np.argmax(self.lyr_out[self.max_lid], axis=1)
labels = np.argmax(labels, axis=1)
return np.sum(outputs == labels) / features.shape[0]
# endregion <<< 全连接网络 <<<
2.5 脚本入口
在 Python 脚本的入口函数中,执行 加载数据 \(\rightarrow\) 创建模型 \(\rightarrow\) 训练 \(\rightarrow\) 测试 \(\rightarrow\) 预测 等任务。
点击查看脚本入口代码
# region >>> 脚本入口 >>>
if __name__ == '__main__':
# 使用 One-Hot 编码表示一个数字
def get_one_hot(one_dim_digit):
one_hot = np.zeros(shape=(10,)) # 分类手写数字 0~9 共10个数字
one_hot[one_dim_digit[0]] = 1 # 用一个长度为10的向量表示一个数字,其中只有一个元素为1,其余为0
return one_hot
# >>> 加载数据 >>>
(train_features, train_labels), (test_features, test_labels) = mnist.load_data() # 从keras.datasets中导入mnist数据集
# 28*28=784,每张图片都是28*28的像素矩阵,将其转换为一维向量输入神经网络
feature_dim = train_features.shape[1] * train_features.shape[2]
# 训练数据
train_num = train_features.shape[0] # 第0个维度的大小是训练集数量
# 将训练集的每张图片转换为一维向量,并且将像素的值归一化到0~1之间
train_features = train_features.reshape((train_num, feature_dim)) / 255
train_labels = np.apply_along_axis(
get_one_hot, axis=1, arr=train_labels.reshape((train_num, 1)) # 将训练集的每个标签转换为One-Hot向量
)
# 测试数据
test_num = test_features.shape[0] # 第0个维度的大小是测试集数量
# 将测试集的每张图片转换为一维向量,并且将像素的值归一化到0~1之间
test_features = test_features.reshape((test_num, feature_dim)) / 255
test_labels = np.apply_along_axis(
get_one_hot, axis=1, arr=test_labels.reshape((test_num, 1)) # 将测试集的每个标签转换为One-Hot向量
)
# <<< 加载数据 <<<
# >>> 创建模型 >>>
classifier = SoftmaxClassifier((feature_dim, 81, 10), # 输入层784个神经元,隐藏层81个神经元,输出层10个神经元
(sigmoid,), # 隐藏层使用sigmoid激活函数
(d_sigmoid,)) # 隐藏层使用sigmoid激活函数的导数
# <<< 创建模型 <<<
# >>> 训练 >>>
num_trains = 3 # 训练次数
learning_rates = [0.1, 0.0001, 1e-7] # 学习率
batch_sizes = [27, 31, 35] # 批次大小
epoch_sizes = [19, 25, 23] # 周期数
for i in range(0, num_trains):
print(
f"-*- 训练阶段{i + 1}: lr={learning_rates[i]}, batch_size={batch_sizes[i]}, epoch_size={epoch_sizes[i]} -*-")
classifier.set_learning_rate(learning_rates[i]) # 设置学习率
# 每次训练 batch_sizes[i] 个样本,训练 epoch_sizes[i] 次
classifier.train_mul_epoch(train_features, train_labels, batch_sizes[i], epoch_sizes[i],
test_features, test_labels)
# 可视化训练过程
classifier.visual_training()
# <<< 训练 <<<
# >>> 测试 >>>
print('\n测试准确率 = ', end='')
print(classifier.test_accuracy(test_features, test_labels)) # 在测试集上测试神经网络的准确率
# <<< 测试 <<<
# >>> 预测 >>>
def predict_written_number(folder_path):
fig, axs = plt.subplots(1, len(os.listdir(folder_path)), figsize=(9, 5))
plt.subplots_adjust(wspace=0.5, hspace=0.5) # 调整子图之间的间距
for i, filename in enumerate(os.listdir(folder_path)):
if filename.endswith(".jpg") or filename.endswith(".png"):
img_path = os.path.join(folder_path, filename)
img = Image.open(img_path).convert("L") # 转换为灰度图像
img = img.resize((28, 28)) # 调整大小为28x28
img_data = np.array(img) # 转换为Numpy数组
img_data = img_data / 255.0 # 归一化(将像素值缩放到0~1)
# 在子图中显示图像
axs[i].set_title(f'手写数字{os.path.basename(img_path)}', fontsize=11)
axs[i].imshow(img_data, cmap='binary')
img_data = img_data.reshape(1, 784) # 将28x28的矩阵转换为784的向量
classifier.forward(img_data)
print(f'{i}: 手写数字{os.path.basename(img_path)} '
f'识别为 {np.argmax(classifier.lyr_out[classifier.max_lid])}')
plt.show()
input_image_path = "inputs/"
predict_written_number(input_image_path)
# <<< 预测 <<<
# endregion <<< 脚本入口 <<<
3 评估和可视化
代码执行报告如下所示: