UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery
* Authors: [[Libo Wang]], [[Rui Li]], [[Ce Zhang]], [[Shenghui Fang]], [[Chenxi Duan]], [[Xiaoliang Meng]], [[Peter M. Atkinson]]
初读印象
comment:: (UNetFormer)采用了由基于CNN的编码器和专门设计的基于Transformer的解码器组成的混合架构。
动机
具有固定接受视图的卷积操作旨在提取局部模式,在本质上缺乏对全局上下文信息或长程依赖关系建模的能力.在语义分割方面,如果仅对局部信息建模,逐像素分类往往是模糊的,而在全局上下文信息的帮助下,每个像素的语义内容变得更加准确。
虽然自注意力机制缓解了上述问题,但它们通常需要大量的计算时间和内存来捕获全局上下文,从而降低了它们的效率,限制了它们在实时城市应用中的潜力。
提出的UnetFormer采用了由基于CNN的编码器和专门设计的基于Transformer的解码器组成的混合架构。在保证网络效率的同时,实现城市场景的精确分割。
方法
总体结构
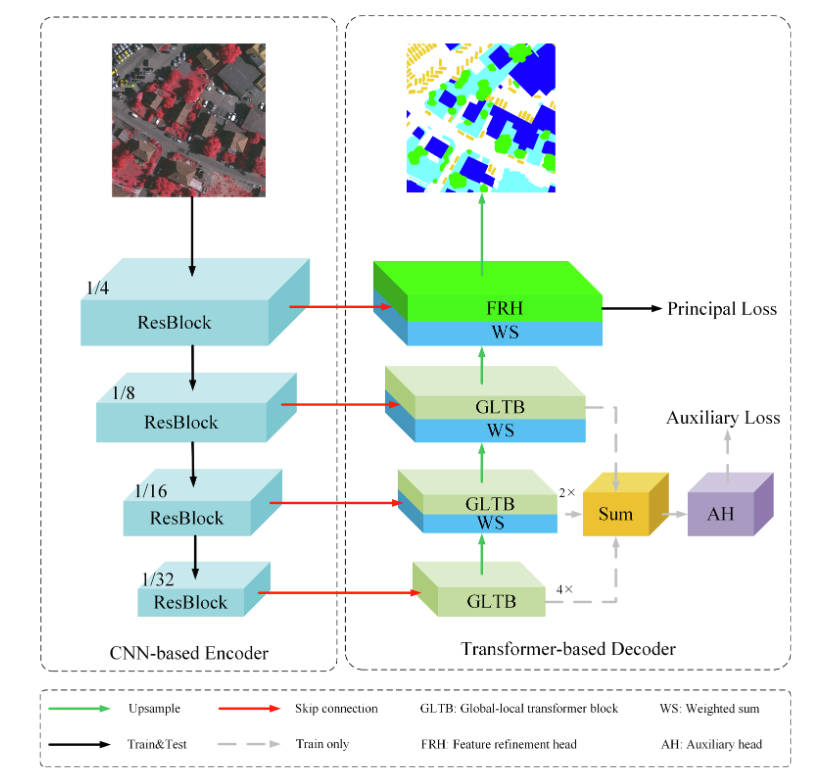 Backbone为Resnet18同一层解码器和编码器的输出特征的融合:
Backbone为Resnet18同一层解码器和编码器的输出特征的融合:

Transformer-based decoder
Global-local Transformer Block(GLTB)
全局-局部Transformer模块由全局-局部注意力、多层感知器、两个批归一化层和两个附加操作组成
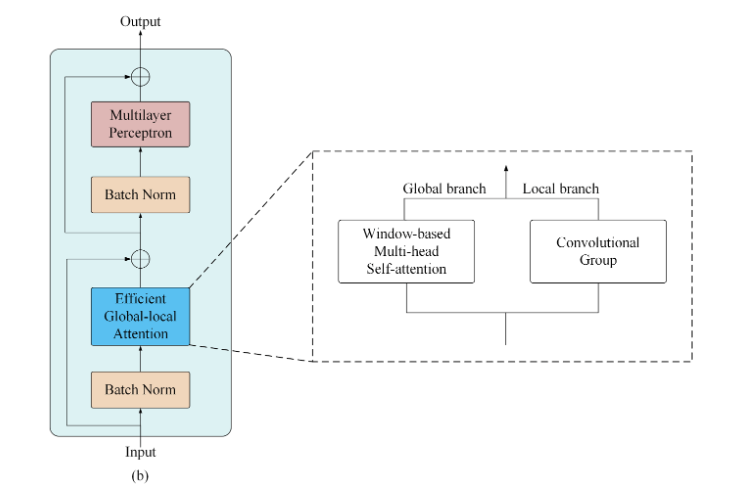 ######Global-local attention
######Global-local attention
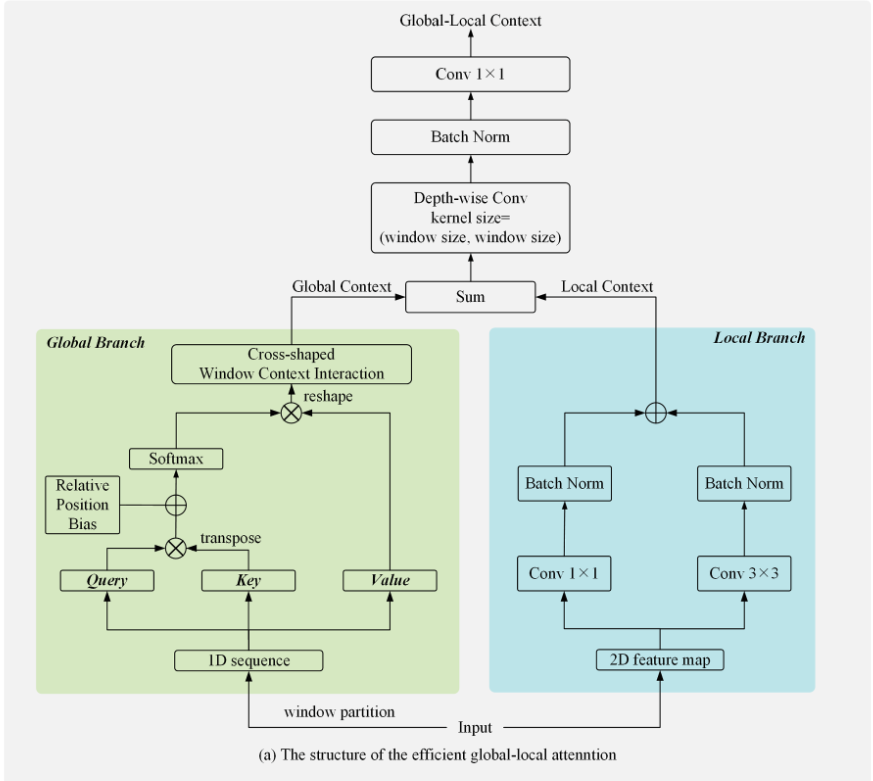
- 局部分支:使用两个并行的卷积层,核大小分别为3和1来提取局部上下文。然后在最后的求和操作之前附加两个批归一化操作。
- 全局分支
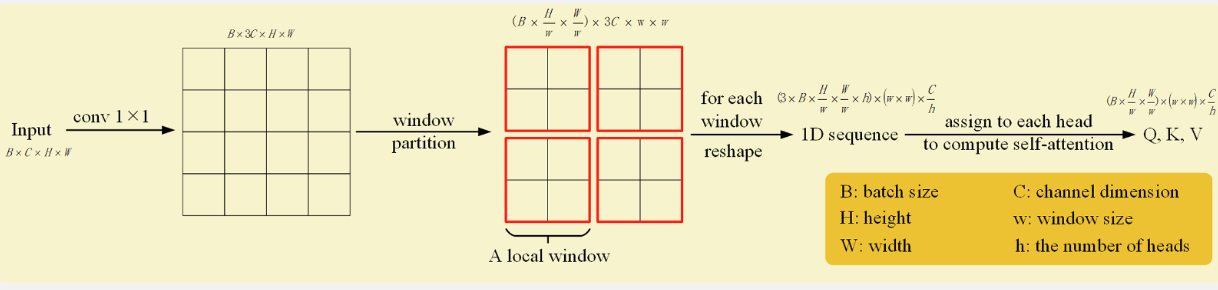 *基于窗口的多头注意力
*基于窗口的多头注意力
* 1×1卷积扩充3倍通道
* 划分窗口、使用多头注意力-
十字窗口上下文交互模块:捕获跨窗口关系
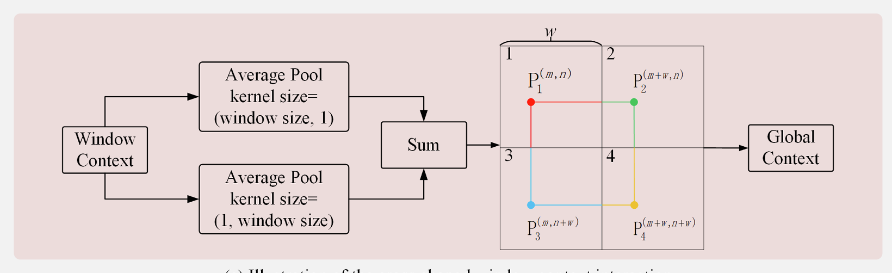
- 分别计算水平平均池化和垂直平均池化
-
Feature refinement head (FRH)
解决的问题:第一个Resblock产生的浅层特征保留了城市场景丰富的空间细节,但缺乏语义内容,而深层全局-局部特征提供了精确的语义信息,但空间分辨率较粗。
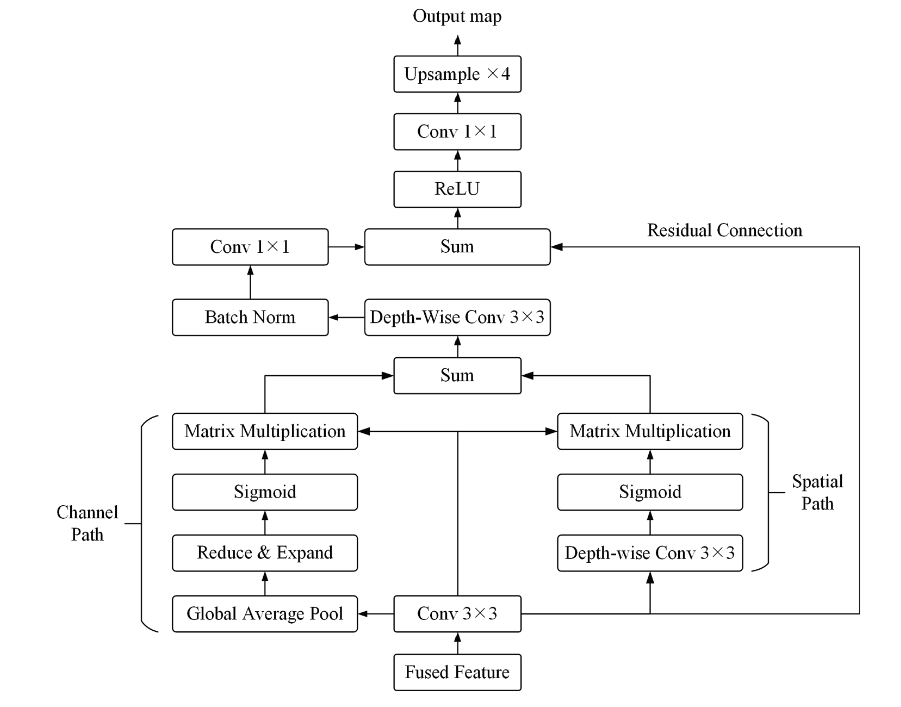
一个通道路径和一个空间路径
输入输出
遥感图像的语义分割
启发
在注意力中嵌入了相对位置偏移。
在局部块中使用注意力,同时,用十字窗口上下文交互模块来增强局部块之间的联系,防止建模能力被局限在局部块中,这是近来如swimtransformer都在做的事情,可以用于有局部块的场景。
- segmentation transformer UNetFormer UNet-like efficientsegmentation transformer unetformer unet-like cvpr_efficient domain-based transformers high-quality segmentation transformers camouflaged one-stage transformer-based combinations segmentation squeeze-enhanced segmentation transformer seaformer segmentation transformers semantic segvit weakly-supervised segmentation transformers unet-like unetformer efficient