I/O 数据库是一系列文件操作函数,既方便用户使用,又提高了整体效率。
看起来比较优质的 I/O 库函数汇总,链接如下:https://blog.csdn.net/xiaxiaoyule/article/details/44050507?utm_source=app&app_version=4.15.0&code=app_1562916241&uLinkId=usr1mkqgl919blen
几乎每个支持C语言编程的操作系统都可以提供文件I/O库函数。
二、I/O 库函数的算法
(一)程序必须给每个文件声明一个指针变量,这个变量的类型为FILE*,当它处于活动状态时为流所用。
(二)流通过fopen函数打开,打开的时候必须指定需要访问的文件或者设备以及访问方式。例如: FILE* fopen(const char* filename,const char*mode)
(三)根据需要对文件进行读取和写入。
(四)fread算法:
fread算法如下:
(1)在第一次调用 fread()时,FILE结构体的缓冲区是空的,fread()使用保存的文件描述符fd发出一个
n=read(fd,fbuffer,BLKSIZE);
系统调用,用数据块填充内部的 fbuf [] 的指针、计数器和状态变量,以表明内部缓冲区有一个数据块。
尝试满足来自内部缓冲区的fread()调用。
若,内部缓冲区没有足够的数据,则会再发出一个 read()系统调用来填充内部缓冲区,将数据从内部缓冲区传输到程序缓冲区,直到满足程序所需的字节数。将数据复制到程序缓冲区后,他会更新内部缓冲区的指针、计数器等,为下一个fread()做好准备。然后返回实际读取的数据对象;
(2)在之后的每次fread()调用中,它都尝试满足来自FILE结构体内部缓冲区的调用。当缓冲区变成空时,它就会发出 read()系统调用来重新填充内部缓冲区。
因此,fread()一方面接受来自用户程序的调用;另一方面向操作系统内核发出read()系统调用。除了系统调用之外,所有fread()处理都在用户模式映像中执行。它只在需要的时候才会进入操作系统内核,并且以一种最高效匹配文件的方式进入。会提供自动缓冲机制。
(五)fwrite()算法
fwrite()在每次被调用的时候,它将数据写入内部缓冲区,并调整缓冲区的指针、计数器和状态变量,以跟踪缓冲区的字节数。如果缓冲区已满,则发出write()系统调用,将整个缓冲区写入操作系统内核。
()fclose函数可以关闭文件流的局部缓冲区,然后,它会发出一个close(fd)系统调用来关闭 FILE 结构体中的文件描述。最后释放 FILE 结构体,并将 FILE 指针重置为NULL。
例如: fclose(FILE* steam) ###### I/O函数列表:
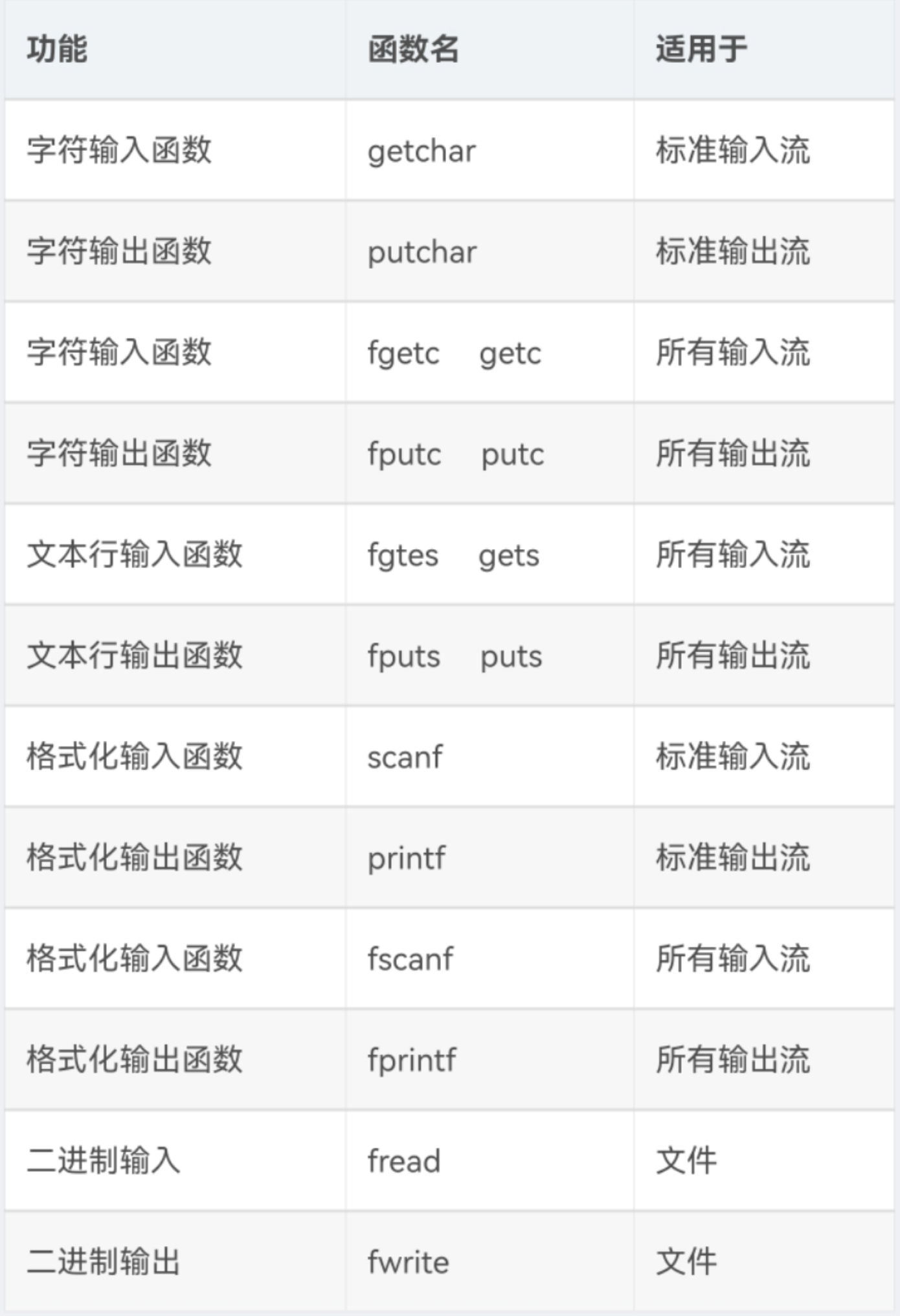
三、使用I/O库函数或系统调用
·fread() 和 fwrite() 将数据从内核复制到内部缓冲区,然后从内部缓冲区将数据复制到程序缓冲区。
·read()将数据直接复制到程序的缓冲区。
所以,它传输了两次数据;
而 read() 将数据从内核直接复制到程序的缓冲区,只复制了一次。因此对于BLKSIZE为单位的读/写数据来说,read()比 fread()更高效,同样,write()比 fwrite()更高效。
当然,以上的高效是相对于BLKSIZE为单位的读/写数据来说的。
四、I/O库模式
r+:表示读/写,不会阶段文件;
w+:表示读/写,但是会先截断文件;若文件不存在,创建文件;
a+:表示通过追加进行读/写,文件不存在创建文件。
五、文件流缓冲
-
无缓冲
-
行缓冲
-
全缓冲 通过fopen()创建文件流之后,在对其执行任何操作之前,用户均可发出一个
setvbuf(FILE *stream, char *buf, int node, int size)调用来设置缓冲区(buf)、缓冲区大小(size)和缓冲方案(mode),它们必须是以下一个宏: -
IONBUF:无缓冲
-
IOLBUF:行缓冲
-
IOFBUF:全缓冲 此外,还有其他的setbuf()函数,是setvbuf()的变体。对于行缓冲流或全缓冲流,可用fflush(stream)立即清除流的缓冲区。
Chatgpt测试如下图所示:


