定义
自旋锁与互斥锁有点类似,只是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,”自旋”一词就是因此而得名。由于自旋锁使用者一般保持锁时间非常短,因此选择自旋而不是睡眠是非常必要的,自旋锁的效率远高于互斥锁。
信号量和读写信号量适合于保持时间较长的情况,它们会导致调用者睡眠,因此只能在进程上下文使用(_trylock的变种能够在中断上下文使用),而自旋锁适合于保持时间非常短的情况,它可以在任何上下文使用。如果被保护的共享资源只在进程上下文访问,使用信号量保护该共享资源非常合适,如果对共享资源的访问时间非常短,自旋锁也可以。但是如果被保护的共享资源需要在中断上下文访问(包括底半部即中断处理句柄和顶半部即软中断),就必须使用自旋锁。
实现
传统的自旋锁本质上用一个整数来表示,值为1代表锁未被占用, 为0或者为负数表示被占用,传统自旋锁已不再使用。
Linux 内核 2.6.25 版本中引入了排队自旋锁:谁先等待锁,谁先获得锁。所以 linux 的自旋锁就是排队自旋锁(ticket spinlock),有关结构体定义如下:
typedef struct { union { u32 slock; struct __raw_tickets { #ifdef __ARMEB__ u16 next; u16 owner; #else u16 owner; u16 next; #endif } tickets; }; } arch_spinlock_t;
自旋锁,为什么要禁止抢占?
以linux为例,如果允许抢占,线程1正在持有该锁,此时发生了schedule后线程2又去试图拿该锁,线程2就会自旋在那里,浪费CPU资源。
假如只有单核,把自旋锁的preempt_disable注释掉,即允许抢占,使用自旋锁会产生死锁么?
不会。线程1在执行临界区,被schedule出去,线程2试图获取该锁,线程2会自旋在那里(浪费CPU,不主动让出CPU),等到再次被调度到线程1并释放了该锁后,线程2才可以继续往下跑。
自旋锁临界区为什么不允许sleep(使用会schedule类函数)?
线程1在执行临界区,此时该CPU禁止抢占,如果调用sleep主动schedule出去后,该CPU就永远回不来了,此时如果线程2试图获取该锁,就会发生死锁。(实际应该是发生kernel panic)
自旋锁只有在内核可抢占或SMP的情况下才真正需要,在单CPU且不可抢占的内核下,自旋锁的所有操作都是空操作,在单CPU且可抢占的内核下,自旋锁实际上只进行开启和关闭内核抢占的操作,如下:
include\linux\spinlock_api_up.h
#define _raw_spin_lock(lock) __LOCK(lock)
#define __LOCK(lock) \
do { preempt_disable(); ___LOCK(lock); } while (0)
#define ___LOCK(lock) \
do { __acquire(lock); (void)(lock); } while (0)
# define __acquire(x) (void)0
SMP情况下,除了关抢占,还需要用到独占的汇编指令操作变量,如下:
kernel\locking\spinlock.c
include\linux\spinlock_api_smp.h
void __lockfunc _raw_spin_lock(raw_spinlock_t *lock)
{
__raw_spin_lock(lock);
}
static inline void __raw_spin_lock(raw_spinlock_t *lock)
{
preempt_disable();
spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
}
static inline void arch_spin_lock(arch_spinlock_t *lock)
{
unsigned long tmp;
u32 newval;
arch_spinlock_t lockval;
prefetchw(&lock->slock);
__asm__ __volatile__(
"1: ldrex %0, [%3]\n"
" add %1, %0, %4\n"
" strex %2, %1, [%3]\n"
" teq %2, #0\n"
" bne 1b"
: "=&r" (lockval), "=&r" (newval), "=&r" (tmp)
: "r" (&lock->slock), "I" (1 << TICKET_SHIFT)
: "cc");
while (lockval.tickets.next != lockval.tickets.owner) {
wfe();
lockval.tickets.owner = READ_ONCE(lock->tickets.owner);
}
smp_mb();
}
如何使用自旋锁函数
获得自旋锁和释放自旋锁有好几个版本,因此让读者知道在什么样的情况下使用什么版本的获得和释放锁的宏是非常必要的。
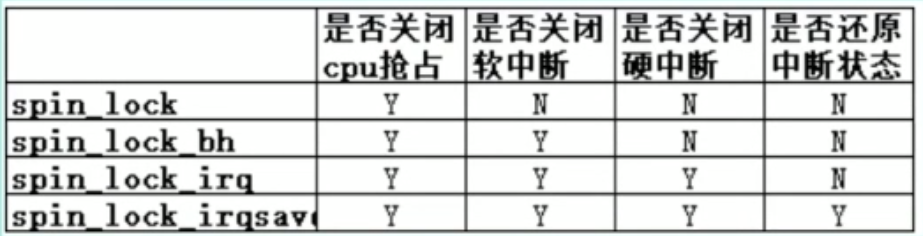
被保护的共享资源只在进程上下文访问和软中断上下文访问
当在进程上下文访问共享资源时,可能被软中断打断,从而可能进入软中断上下文来对被保护的共享资源访问,因此对于这种情况,对共享资源的访问必须使用spin_lock_bh和spin_unlock_bh来保护(关闭软中断)。当然使用spin_lock_irq和spin_unlock_irq以及spin_lock_irqsave和spin_unlock_irqrestore也可以,它们失效了本地硬中断(本地指当前CPU中断),失效硬中断隐式地也失效了软中断。但是使用spin_lock_bh和spin_unlock_bh是最恰当的,它比其他两个快。
被保护的共享资源只在进程上下文和tasklet或timer上下文访问
应该使用与上面情况相同的获得和释放锁的宏,因为tasklet和timer是用软中断实现的。
spinlock用在进程上下文和中断
进程A中调用了spin_lock(&lock)然后进入临界区,此时来了一个中断(interrupt),该中断也运行在和进程A相同的CPU上,并且在该中断处理程序中恰巧也会spin_lock(&lock)试图获取同一个锁。由于是在同一个CPU上被中断,进程A会被设置为TASK_INTERRUPT状态,
中断处理程序无法获得锁,会不停的忙等,由于进程A被设置为中断状态,schedule()进程调度就无法再调度进程A运行,这样就导致了死锁!但是如果该中断处理程序运行在不同的CPU上就不会触发死锁。因为在不同的CPU上出现中断不会导致进程A的状态被设为TASK_INTERRUPT,只是换出。当中断处理程序忙等被换出后,进程A还是有机会获得CPU,执行并退出临界区,所以在使用spin_lock时要明确知道该锁不会在中断处理程序中使用。如果有,那就需要使用spinlock_irq_save,该函数即会关抢占,也会关本地中断(本CPU中断)。
被保护的共享资源只在一个tasklet或timer上下文访问
不需要任何自旋锁保护,因为同一个tasklet或timer只能在一个CPU上运行,即使是在SMP环境下也是如此。实际上tasklet在调用tasklet_schedule标记其需要被调度时已经把该tasklet绑定到当前CPU,因此同一个tasklet决不可能同时在其他CPU上运行。timer也是在其被使用add_timer添加到timer队列中时已经被帮定到当前CPU,所以同一个timer绝不可能运行在其他CPU上。当然同一个tasklet有两个实例同时运行在同一个CPU就更不可能了。
被保护的共享资源只在两个或多个tasklet或timer上下文访问
对共享资源的访问仅需要用spin_lock和spin_unlock来保护,不必使用_bh版本,因为当tasklet或timer运行时,不可能有其他tasklet或timer在当前CPU上运行。