SSTables
LSM(log-structured merge-tree)树使用排序字符串表(SSTable:Sorted Strings Table)格式持久化到磁盘。顾名思义,SSTable是一种用于存储键值对的格式,其中的键是按排序排列的。SSTable由多个被称为段的有序文件组成。这些段一旦写入磁盘就不可更改。一个简单的例子如下:
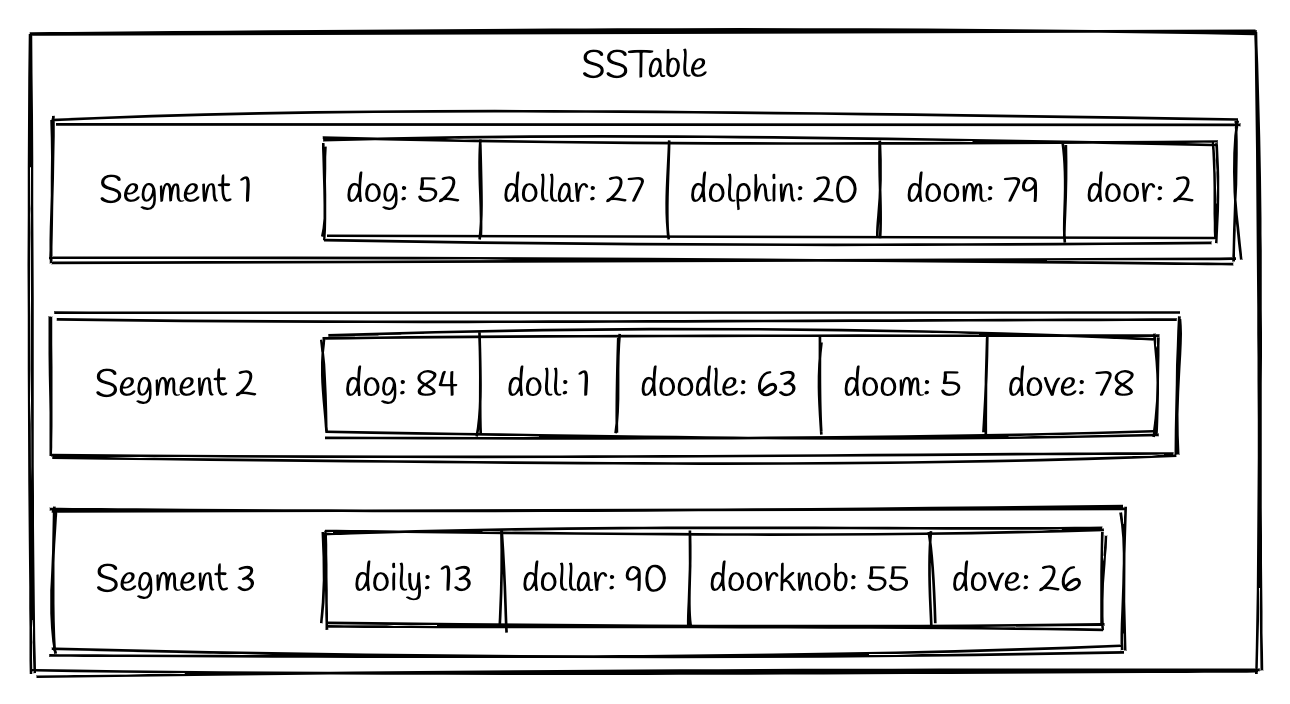
可以看到,每个段中的键值对都是按键排序的。将在下一节讨论什么是段以及如何生成段。
写入数据
LSM树只能执行顺序写入。你可能想知道,当数据值可以以任何顺序写入时,我们如何以排序格式顺序写入数据。这可以通过使用内存树结构来解决。这种结构通常被称为内存表(memtable),但其底层数据结构通常是某种形式的排序树,如红黑树。当写入数据时,数据会被添加到这棵红黑树上。
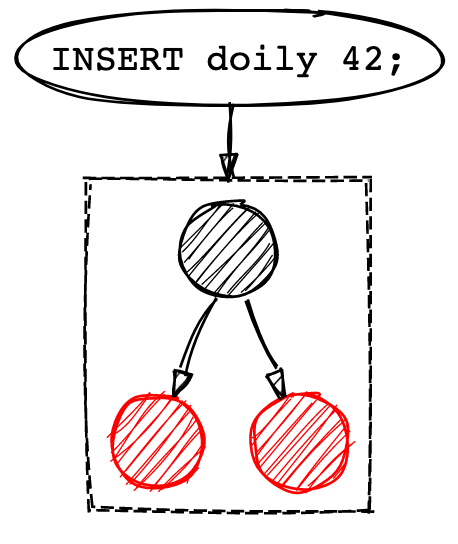
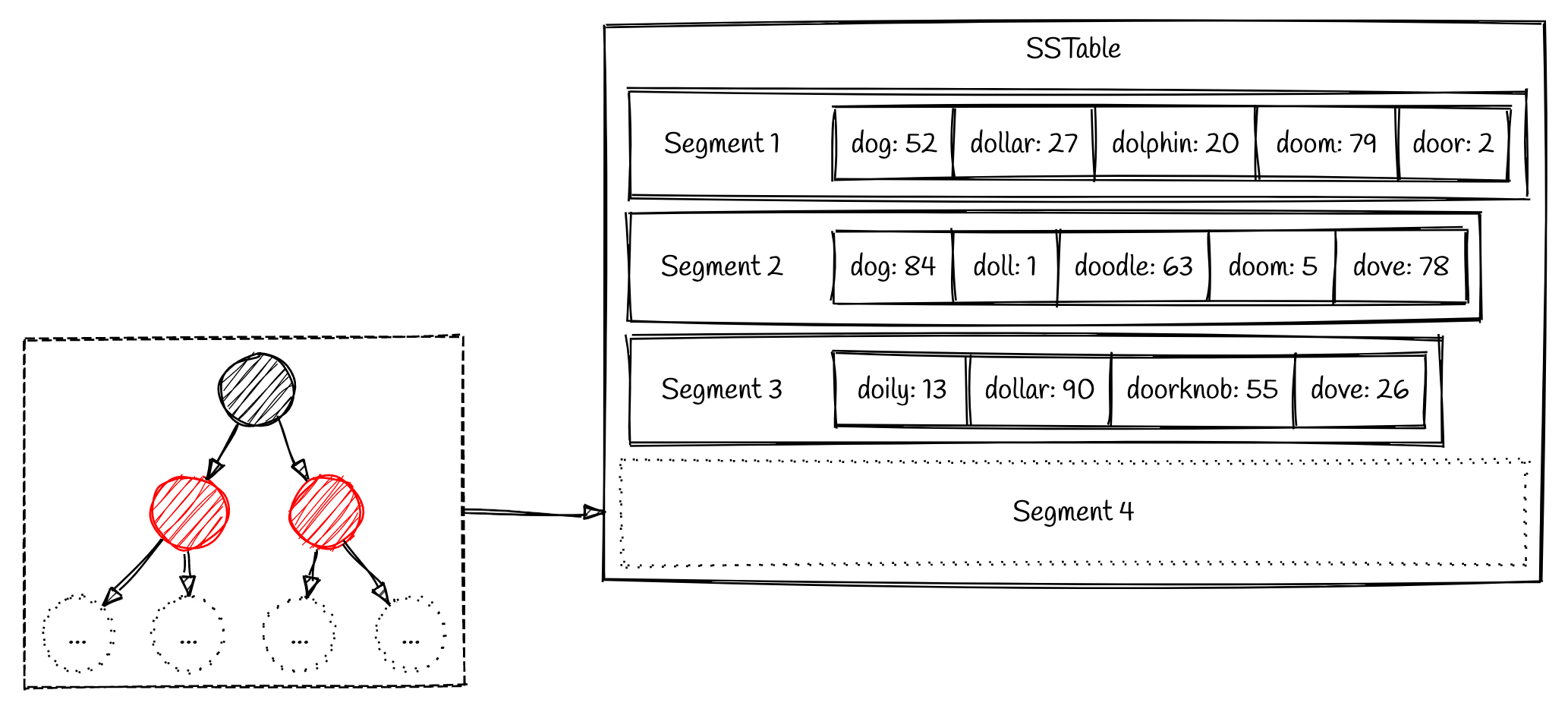
我们写入的内容会存储在这棵红黑树上,直到这棵树达到预定义的大小。一旦红黑树有了足够的条目,它就会按排序顺序作为磁盘段刷新到磁盘上。这样,即使插入可能以任何顺序进行,我们也能以单次顺序写入的方式写入段文件。
读数据
那么,我们如何在SSTable中找到一个值呢?最简单的方法是扫描段,查找所需的键。我们将从最新的数据段开始,一直到最老的数据段,直到找到我们要找的键。这意味着我们能更快地检索到最近写入的键。一个简单的优化方法是保留一个内存稀疏索引。
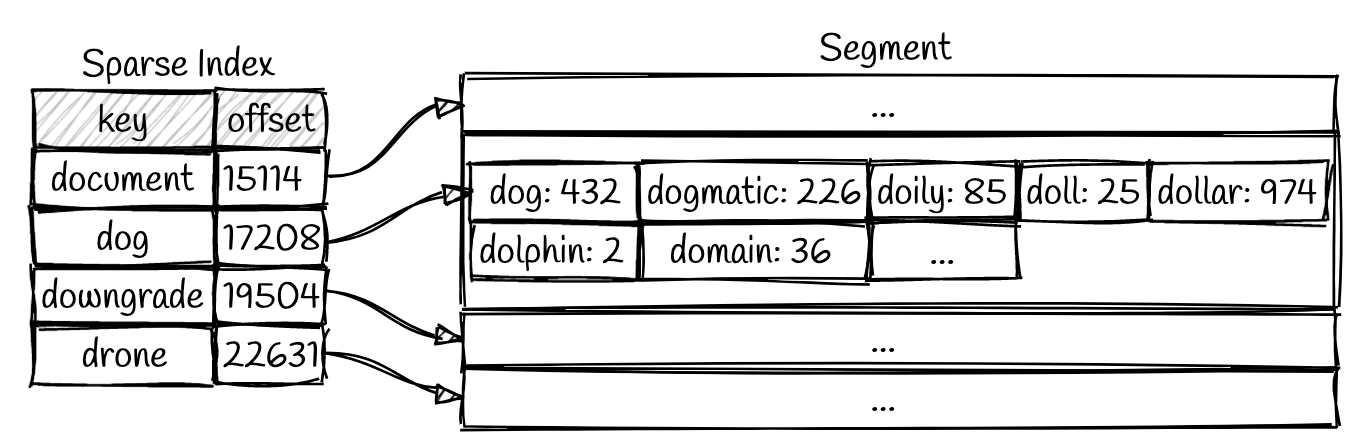
我们可以使用该索引快速找到我们想要的键前后的值的偏移量。现在,我们只需根据这些边界扫描每个段文件的一小部分即可。例如,假设这样一种情况,我们想查找上面段中的键:doller。我们可以在稀疏索引上执行二叉搜索,找到dollar位于dog和downgrade之间。现在,我们只需从偏移量17208到19504之间进行扫描,即可找到该值(或确定该值不存在)。
这是一个很好的改进,但如果查找不存在的记录呢?我们最终还是会在所有数据段文件中循环,却无法在每个数据段中找到键。这就需要一个Bloom过滤器来帮助我们解决这个问题。bloom过滤器是一种节省空间的数据结构,可以告诉我们数据中是否不存在某个值。我们可以在写入条目时将其添加到bloom过滤器中,并在读取开始时对其进行检查,以便有效地响应对不存在的数据请求。
压缩
随着时间的推移,系统在持续运行时会积累更多的段文件。这些段文件需要清理和维护,以防止段文件数量失控。这是"压缩"的进程的职责。压缩是一个后台进程,它不断地将旧的段合并成新的段。
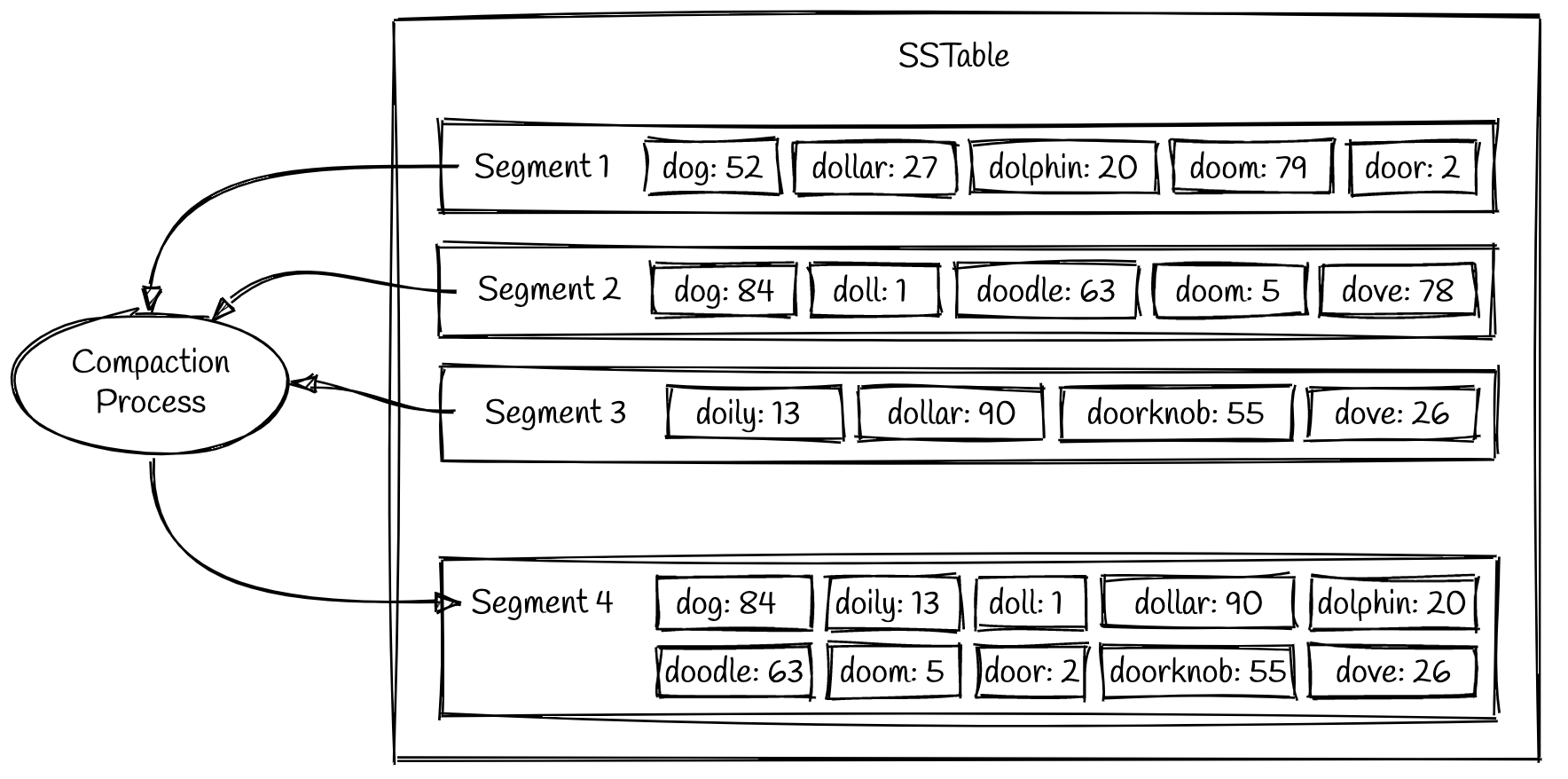
从上面的示例中可以看出,第1和第2段都有一个键"dog"。较新的数据段包含最新写入的值,因此数据段2中的值会被转入数据段4中。一旦压缩过程写入了新的段,旧的段文件就会被删除。
删除数据
如果段文件被认为是不可变的,那么如何从SSTable中删除数据呢?实际上,删除与写入数据的路径完全相同。只要收到删除请求,就会为该键写入一个称为"tombstone"的唯一标记。
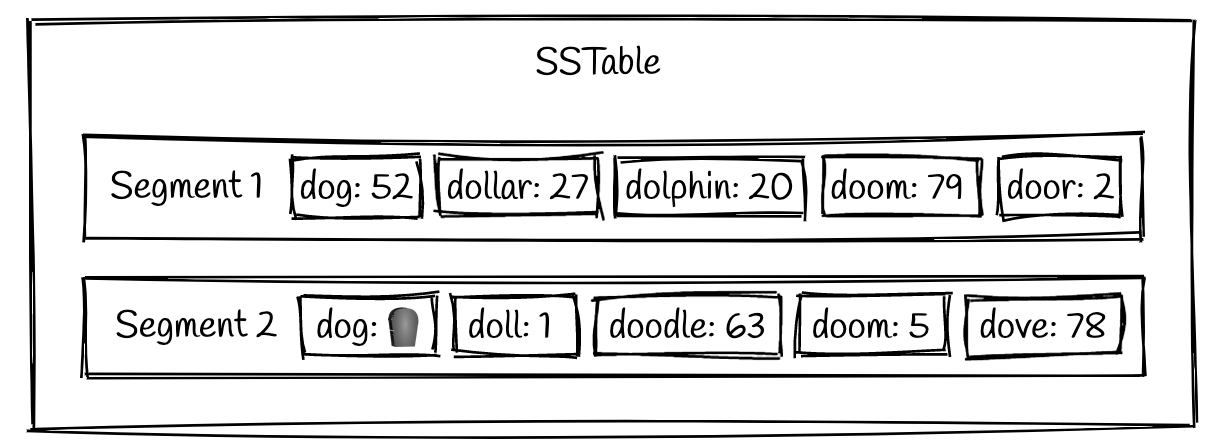
上面的示例显示,键dog在过去的某个时刻的值是52,但现在它有了一个"tombstone"标记。这表明,如果我们收到对key dog的请求,我们应该返回一个表示该键不存在的响应。这意味着删除请求最初实际上会占用磁盘空间,许多开发人员可能会对此感到惊讶。最终,"tombstone"会被压缩掉,使值不再存在于磁盘上。
结论
我们现在了解了基本的LSM树存储引擎是如何工作的:
1.写存储在内存树(也称为 memtable)中。如有必要,还会更新任何支持的数据结构(bloom 过滤器和稀疏索引)。
2.当这棵树变得过大时,就会将键按排序顺序刷新到磁盘上。
3.当读取数据时,会检查Bloom过滤器。如果Bloom过滤器显示该值不存在,就会告诉客户端找不到该键。如果Bloom过滤器显示该值存在,就开始从最新到最旧迭代段文件。
4.对于每个分段文件,都会检查稀疏索引,并扫描预计能找到键的偏移量,直到找到键为止。一旦在段文件中找到该值,将立即返回。