本文分享自华为云社区 《华为云HBase 冷热分离最佳实践》,作者:pippo。
HBase介绍
HBase是Hadoop Database的简称,是建立在Hadoop文件系统之上的分布式面向列的数据库,它具有高可靠、高性能、面向列和可伸缩的特性,提供快速随机访问海量数据能力。
HBase采用Master/Slave架构,由HMaster节点、RegionServer节点、ZooKeeper集群组成,底层数据存储在HDFS上。
整体架构如图所示:

HMaster主要负责:
- 在HA模式下,包含主用Master和备用Master。
- 主用Master:负责HBase中RegionServer的管理,包括表的增删改查;RegionServer的负载均衡,Region分布调整;Region分裂以及分裂后的Region分配;RegionServer失效后的Region迁移等。
- 备用Master:当主用Master故障时,备用Master将取代主用Master对外提供服务。故障恢复后,原主用Master降为备用。
RegionServer主要负责:
- 存放和管理本地HRegion。
- RegionServer负责提供表数据读写等服务,是HBase的数据处理和计算单元,直接与Client交互。
- RegionServer一般与HDFS集群的DataNode部署在一起,实现数据的存储功能。读写HDFS,管理Table中的数据。
ZooKeeper集群主要负责:
- 存放整个 HBase集群的元数据以及集群的状态信息。
- 实现HMaster主从节点的Failover。
HDFS集群主要负责:
- HDFS为HBase提供高可靠的文件存储服务,HBase的数据全部存储在HDFS中。
结构说明:
Store
- 一个Region由一个或多个Store组成,每个Store对应图中的一个Column Family。
MemStore
- 一个Store包含一个MemStore,MemStore缓存客户端向Region插入的数据,当RegionServer中的MemStore大小达到配置的容量上限时,RegionServer会将MemStore中的数据“flush”到HDFS中。
StoreFile
- MemStore的数据flush到HDFS后成为StoreFile,随着数据的插入,一个Store会产生多个StoreFile,当StoreFile的个数达到配置的阈值时,RegionServer会将多个StoreFile合并为一个大的StoreFile。
HFile
- HFile定义了StoreFile在文件系统中的存储格式,它是当前HBase系统中StoreFile的具体实现。
HLog(WAL)
- HLog日志保证了当RegionServer故障的情况下用户写入的数据不丢失,RegionServer的多个Region共享一个相同的HLog。
HBase提供两种API来写入数据。
- Put:数据直接发送给RegionServer。
- BulkLoad:直接将HFile加载到表存储路径。
HBase 冷热分离诉求
HBase是Hadoop Database的简称,是建立在Hadoop文件系统之上的分布式面向列的数据库,它具有高可靠、高性能、面向列和可伸缩的特性,提供快速随机访问海量数据能力。
在海量大数据场景下,表中的部分业务数据随着时间的推移仅作为归档数据或者访问频率很低,同时这部分历史数据体量非常大,比如订单数据或者监控数据,如果降低这部分数据的存储成本将会极大的节省企业的成本。
冷热分离功能支持将冷热数据存储在不同的介质上,冷数据的存储类型为普通IO存储,热数据的存储类型为超高IO存储。普通IO存储的价格仅为超高IO存储的30%,大大降低了存储成本。
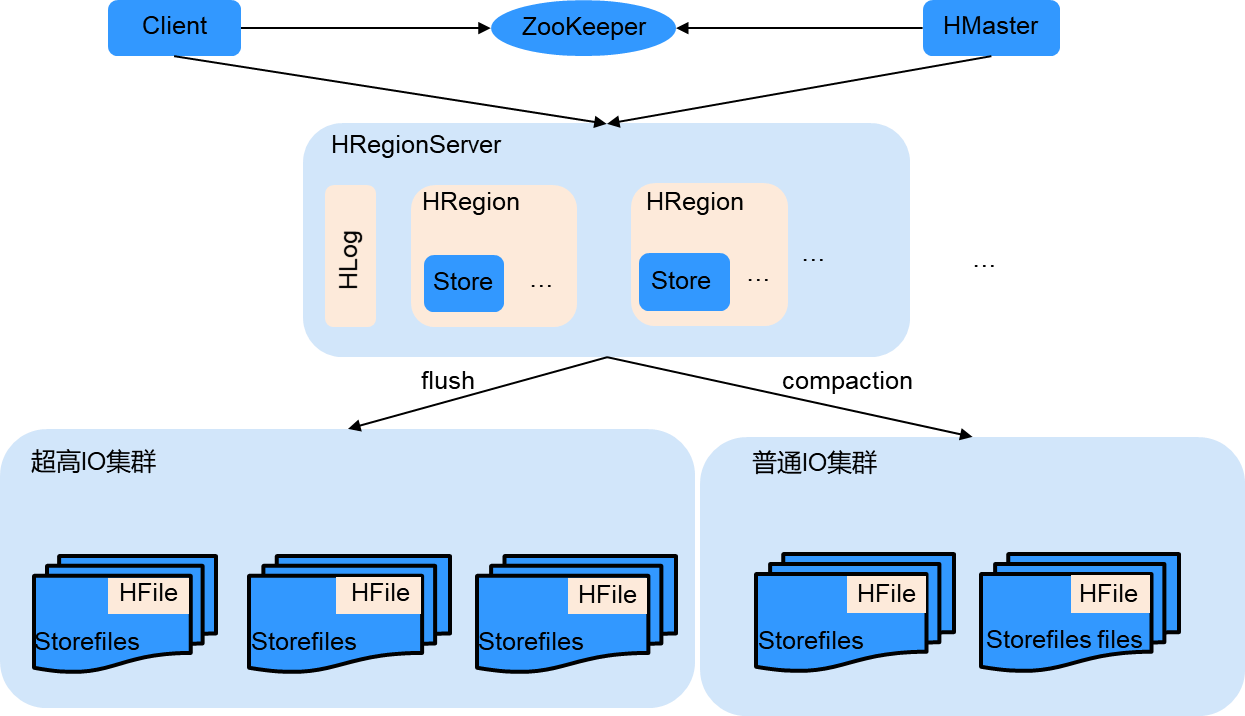
HBase 冷热分离介绍
HBase支持对同一张表的数据进行冷热分离存储。用户在表上配置数据冷热时间分界点后,HBase会依赖用户写入数据的时间戳(毫秒)和时间分界点来判断数据的冷热。数据开始存储在热存储上,随着时间的推移慢慢往冷存储上迁移。同时用户可以任意变更数据的冷热分界点,数据可以从热存储到冷存储,也可以从冷存储到热存储。
整体架构如图所示:
命令介绍
设置表的冷热分界线
创建冷热分离表:
hbase(main):002:0> create 'hot_cold_table', {NAME=>'f', COLD_BOUNDARY=>'86400'}
参数说明:
NAME:需要冷热分离的列族。
COLD_BOUNDARY:冷热分离时间点,单位为秒(s)。例如COLD_BOUNDARY为86400,代表86400秒(一天)前写入的数据会被自动归档到冷存储。
取消冷热分离。hbase(main):004:0> alter 'hot_cold_table', {NAME=>'f', COLD_BOUNDARY=>""}
为已经存在的表设置冷热分离,或者修改冷热分离分界线,单位为秒。
hbase(main):005:0> alter 'hot_cold_table', {NAME=>'f', COLD_BOUNDARY=>'86400'}
查询冷热分离是否设置或者修改成功hbase(main):005:0> desc 'hot_cold_table'
数据写入冷热分离的表与普通表的数据写入方式完全一致,数据会先存储在热存储(超高IO)中。随着时间的推移,如果一行数据满足当前时间-时间列值>COLD_BOUNDARY设置的值条件,则会在执行Compaction时被归档到冷存储(普通IO)中。
插入记录执行“put”命令往指定表插入一条记录,需要指定表的名称,主键,自定义列,以及插入的具体值。
hbase(main):004:0> put 'hot_cold_table','row1','cf:a','value1'
参数说明:
hot_cold_table:表的名称。
row1:主键。
cf:a:自定义的列。
value1:插入的值。
数据查询由于冷热数据都在同一张表中,因此用户所有的查询操作都只需在一张表内进行。在查询时,建议通过配置TimeRange来指定查询的时间范围,系统将会根据指定的时间范围决定查询模式,即仅查询热存储、仅查询冷存储或同时查询冷存储和热存储。如果查询时未限定时间范围,则会导致查询冷数据。在这种情况下,查询吞吐量会受到冷存储的限制。
随机查询
不指定HOT_ONLY参数来查询数据。在这种情况下,将会查询冷存储中的数据。
hbase(main):001:0> get 'hot_cold_table', 'row1'
通过指定HOT_ONLY参数来查询数据。在这种情况下,只会查询热存储中的数据。
hbase(main):002:0> get 'hot_cold_table', 'row1', {HOT_ONLY=>true}
通过指定TimeRange参数来查询数据。在这种情况下,CloudTable将会比较TimeRange和冷热边界值,以确定是只查询热存储还是冷存储中的数据,还是同时查询热冷存储中的数据
hbase(main):003:0> get 'hot_cold_table', 'row1', {TIMERANGE => [0, 1568203111265]}
范围查询
不指定HOT_ONLY参数来查询数据。在这种情况下,将会查询冷存储中的数据。
hbase(main):001:0> scan 'hot_cold_table', {STARTROW =>'row1', STOPROW=>'row9'}
通过指定HOT_ONLY参数来查询数据。在这种情况下,只会查询热存储中的数据。hbase(main):002:0> scan 'hot_cold_table', {STARTROW =>'row1', STOPROW=>'row9', HOT_ONLY=>true}
通过指定TimeRange参数来查询数据。在这种情况下,CloudTable将会比较TimeRange和冷热边界值,以确定是只查询热存储还是冷存储中的数据,还是同时查询热冷存储中的数据。
hbase(main):003:0> scan 'hot_cold_table', {STARTROW =>'row1', STOPROW=>'row9', TIMERANGE => [0, 1568203111265]}
数据合并
- 合并表所有分区的热数据区。
hbase(main):002:0> major_compact 'hot_cold_table', nil, 'NORMAL', 'HOT'
- 合并表所有分区的冷数据区。
hbase(main):002:0> major_compact 'hot_cold_table', nil, 'NORMAL', 'COLD'
- 合并表所有分区的热冷数据区。
hbase(main):002:0> major_compact 'hot_cold_table', nil, 'NORMAL', 'ALL'
HBase 冷热分离效果
