celery定时任务与周期任务
创建celery定时任务的方法与方式
创建celery的定时任务有很多,我们这里只提到笔者使用过的
首先你需要创建两个文件。
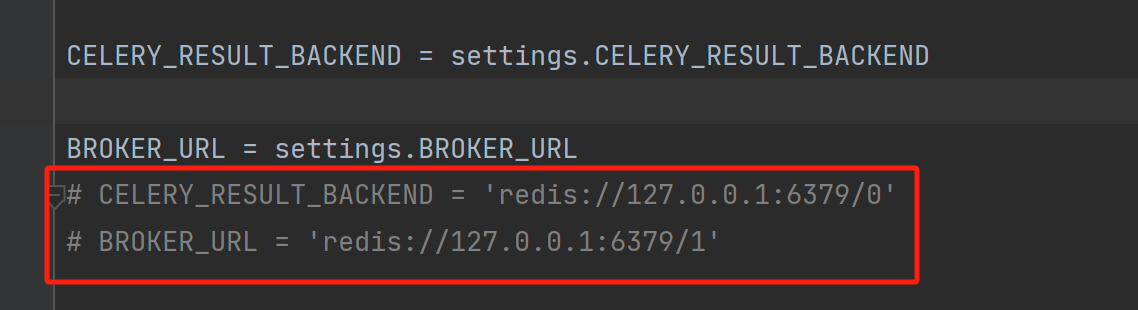
第一个文件为celery配置一些东西。
import os,django os.environ.setdefault("DJANGO_SETTINGS_MODULE", "settings") django.setup() from django.conf import settings CELERY_RESULT_BACKEND = settings.CELERY_RESULT_BACKEND BROKER_URL = settings.BROKER_URL # CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/0' # BROKER_URL = 'redis://127.0.0.1:6379/1' # clelery 启动的工作数量设置 CELERY_WOEKER_CONCURRENCY = 20 # 任务预取 CELERY_PREFETCH_MULTIPLIER = 20 # 防止死锁 CELERY_FORCE_EXECV = True # celery 的worker 在执行100后,重新启动 CELERY_WORKER_MAX_TASKS_PER_CHILD = 100 # 禁用所有速度限制,一切以本定时任务为主 CELERY_DISABLE_RATE_LIMITS = True # 不用格林尼治时间 CELERY_ENABLE_UTC = False # 关闭celery时间感知 DJANGO_CELERY_BEAT_TZ_AWARE = False # 将schedule数据入库 CELERY_BEAT_SCHEDULER = "django_celery_beat.schedulers:DatabaseScheduler"
上面的代码,是你创建celery的一些配置,这个文件的名字你可以任意取名,但是不能是celery.py这个名字,给出的建议是:celeryconfig.py
你需要创建一个文件名为:celery.py的文件,注意,名字必须是这个。
from celery import Celery app = Celery("fault") app.config_from_object("fault_analyse.prospect.celery_config.celeryconfig") app.autodiscover_tasks([ "fault_analyse.prospect.tasks", ])
解释最后一句代码:
fault_analyse.prospect.tasks
这个值,是你tasks文件所在路径,如果你还不知道这是什么,你可以继续向下看,下面会介绍。
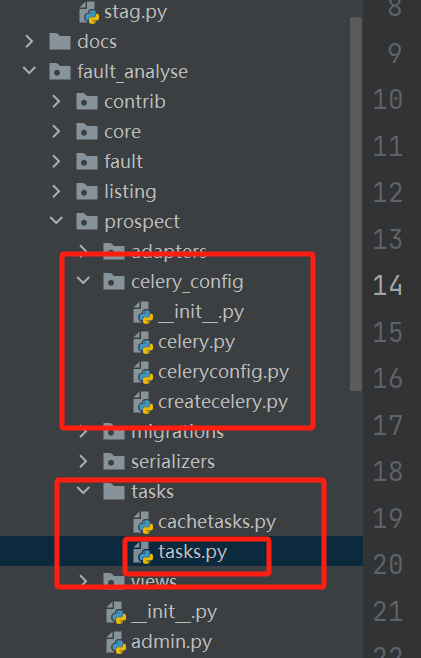
tasks文件
所谓tasks文件,就是你要把你需要运行的函数写在的地方,这个文件的名字,它必须是tasks.py
例如我的文件路径就是:
而,tasks文件里面的写法就很简单了:
from celery import shared_task @shared_task def periodic_tasks(): # _get_bk_token() logger.info("periodic_tasks函数开始绘制") main_cache()
你只需要把celery提供的shared_task函数导入进来,然后在你需要跑的函数上面使用语法糖装饰即可。
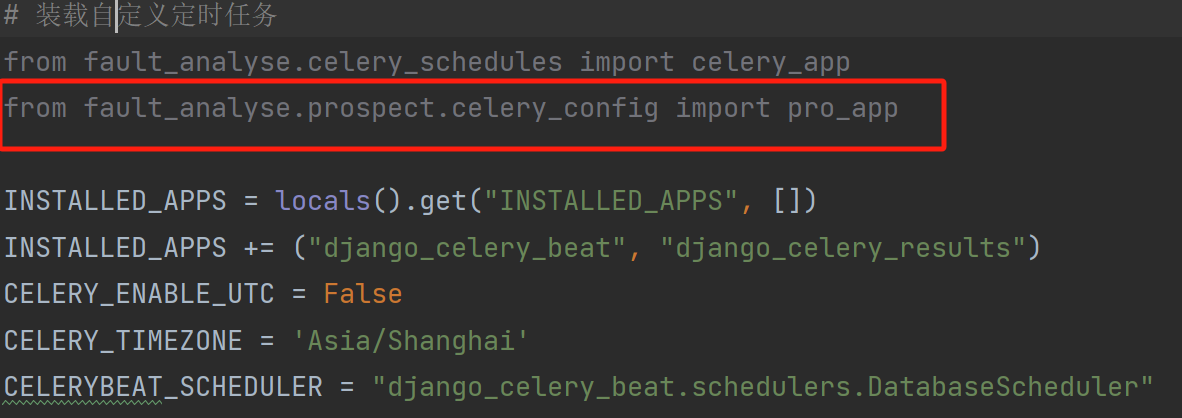
以上的准备工作结束后,你还需要在任意位置创建一个celery_schedules.py的文件
里面的代码也很简单:
from fault_analyse.prospect.celery_config import pro_app from celery.schedules import crontab pro_app.conf.beat_schedule = { "every-10-minute": { "task": "fault_analyse.prospect.tasks.tasks.periodic_tasks", # 每十分钟一次 'schedule': crontab(minute="*/10"), } }
首先,将你的celery文件里面的app导入进来,上面导入的之所以不叫app,我相信你已经知道了为什么——我在init里面进行了重命名! 所以你无需关注它的名字。
写法:
task:你的函数位置,一层一层的点进去,直到你需要运行的函数。
schedule : 你的任务怎样运行,crontab函数到底是怎么用的,你可以去百度自己搜一下。
它的基本用法是:minute=”*” 每分钟 minute=”*/10”每十分钟
hour=”0,1”每天凌晨零点与一点。
crontab的用法实在太丰富,我无法为你全部列出,你可以去celery的官网亦或是百度自查
我们这里,以每十分钟为例子。
然后,你要去配置文件里面装载你的app
经过以上的配置,你将会配置好你的全部相关celery的问题
验证定时任务
你需要去终端,执行以下命令即可:
python manage.py celery worker -l info
或
python manage.py celery worker -l info -P eventlet
如果以上代码提示eventlet未安装,你需要pip install eventlet 即可
然后再启动一个终端,执行beat
celery -A app.celery_config beat -l info
app.celery_config 这个是你celery的文件所在目录
动态创建周期任务
我为你写好了他们的创建,你可以直接看
import json from django_celery_beat.models import PeriodicTask, CrontabSchedule, ClockedSchedule from datetime import datetime from django.conf import settings class CreatCelerySchedule: __doc__ = \ """ 这是一个定时、周期任务的相关类 如果你对定时任务并不熟悉,那么这个类已经实现了大部分的方法,你可以直接调用。 其中delete 与 enabled 看上去是多余的方法,当你会使用了celery的定时任务,那么你可以直接调celery的方法即可。 返参中加入注解类型,方便客户端调用 """ # @staticmethod def __clockedschedule(self, dtime: datetime) -> (ClockedSchedule, bool): """ 创建仅仅执行一次的定时任务模型对象 :param dtime: datetime 对象 或者是时间戳 :return: schedule: django_celery_beat.models.ClockedSchedule 即 ClockedSchedule 对象 created:创建成功:true,更新成功:false,失败:引发异常 """ schedule, created = ClockedSchedule.objects.get_or_create(clocked_time=dtime) return schedule, created @staticmethod def crontabschedule(minute: str = "*", hour: str = "*", day_of_week: str = "*", day_of_month: str = "*") -> ( CrontabSchedule, bool): """ 创建周期任务模型对象 :param minute: 定时任务的分钟数 (0,30) or */30 第零分钟与第三十分钟进行一次 或者是 每三十分钟进行一次 :param hour: 定时任务的小时数 (8,20) or */12 第八时与第二十时进行一次 或者是 每十二个小时进行一次 :param day_of_week: 定时任务的天关于周 (0,5) 每周的周日 或者是 周五进行一次 :param day_of_month: 定时任务的天关于月 (10,15) 每月的十号与十五号进行一次 :return: 创建后的任务对象,是否‘创建’成功:如果创建成功会返回true,否则返回false 值得注意的是:get到数据后,create会返回false """ schedule, created = CrontabSchedule.objects.get_or_create(minute=minute, hour=hour, day_of_week=day_of_week, day_of_month=day_of_month, timezone=settings.TIME_ZONE, ) return schedule, created @staticmethod def periodicschedule(schedule, name: str, task: str, args: list = [], one_off: bool = False) -> PeriodicTask: """ 将你创建好的对应对象,注册到celery-beat队列里面,并向数据库存入 :param schedule: 你必须传一个模型实例进来,否则我无法得知你要创建什么实例 :param name: 为你的任务起一个名字,这个名字不可以重复,如果他是重复的,那么将会更新以前的 :param task: 你需要执行的函数。他的书写格式必须为:‘app.dir.tasks.function’ :param args: 为你的函数传入参数,目前版本仅支持位置入参 :param one_off: 是否仅执行一次,默认不是 :return: """ # todo:这里理论上应该支持关键字入参,后续更新 if not isinstance(args, list): raise TypeError("你必须传入一个list对象,这是定时任务的要求的入参,你必须按照规定传参。") args = json.dumps(args) if not isinstance(schedule, CrontabSchedule): raise TypeError("你必须传入一个定时任务对象") PeriodicTask.objects.update_or_create(name=name, defaults={ "crontab": schedule, "task": task, "one_off": one_off, "args": args, }) # else: # _ = PeriodicTask.objects.update_or_create(name=name, defaults={ # "clocked": schedule, # "name": name, # "task": task, # "one_off": True, # "args": args or [], # # }) @staticmethod def selectperiodic(name): """ 使用id查值没有意义,请使用name进行查找 :param name: 你需要查找的名字 :return: Queryset 对象 """ return PeriodicTask.objects.filter(name=name) @staticmethod def delete(ptmodel: PeriodicTask): """ :param ptmodel: 将 PeriodicTask 的 model 传入 ,切记不是 queryset 对象 :return: """ ptmodel.delete() @staticmethod def enabled(ptmodel: PeriodicTask, ny: bool): """ :param ptmodel: 将 PeriodicTask 的 model 传入 ,切记不是 queryset 对象 :param ny: 开启还是关闭,需要一个 bool 值 :return: """ ptmodel.enabled = ny ptmodel.save()
函数的用法以及可能的用法已经写进去了,你可以直接看。
你需要执行的函数上面使用:@app.task
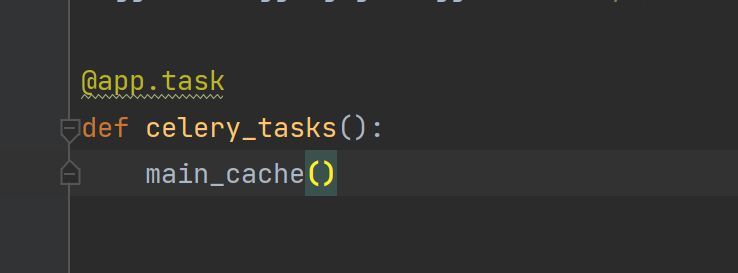
app 你应该是记得的,是吗。
启动方式

期间你可能遇到的问题:
can`t pickle module objects
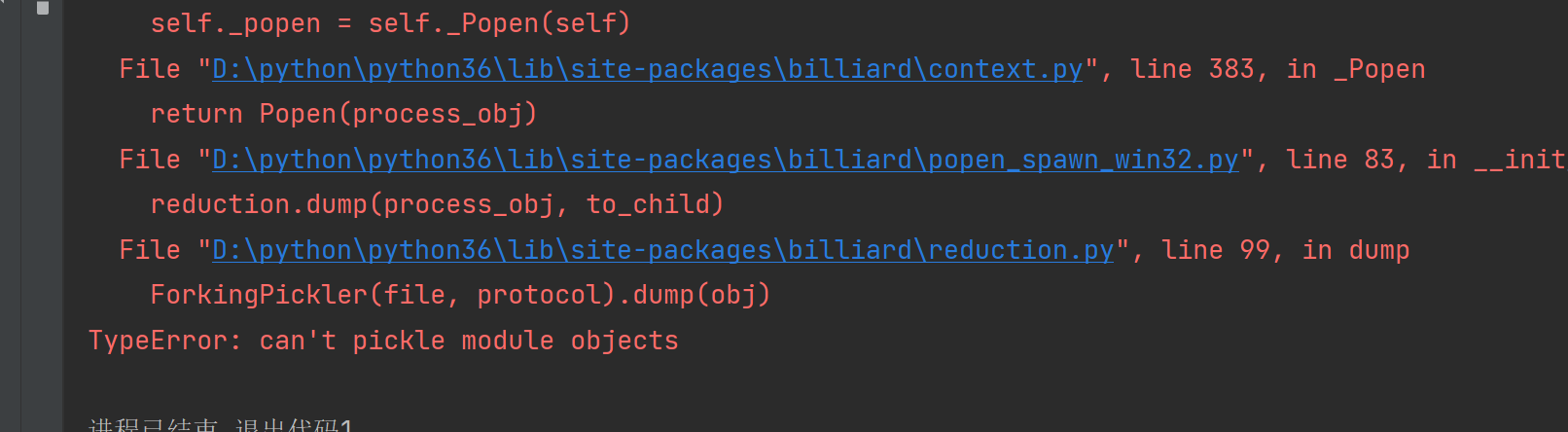
它出现的问题是:
celery3.2.0以上的版本,是不支持直接pickle的,因为他们认为这是不安全的。
而造成这个问题的原因,很可能就是你打开文件时,用的是导入的方式,例如:
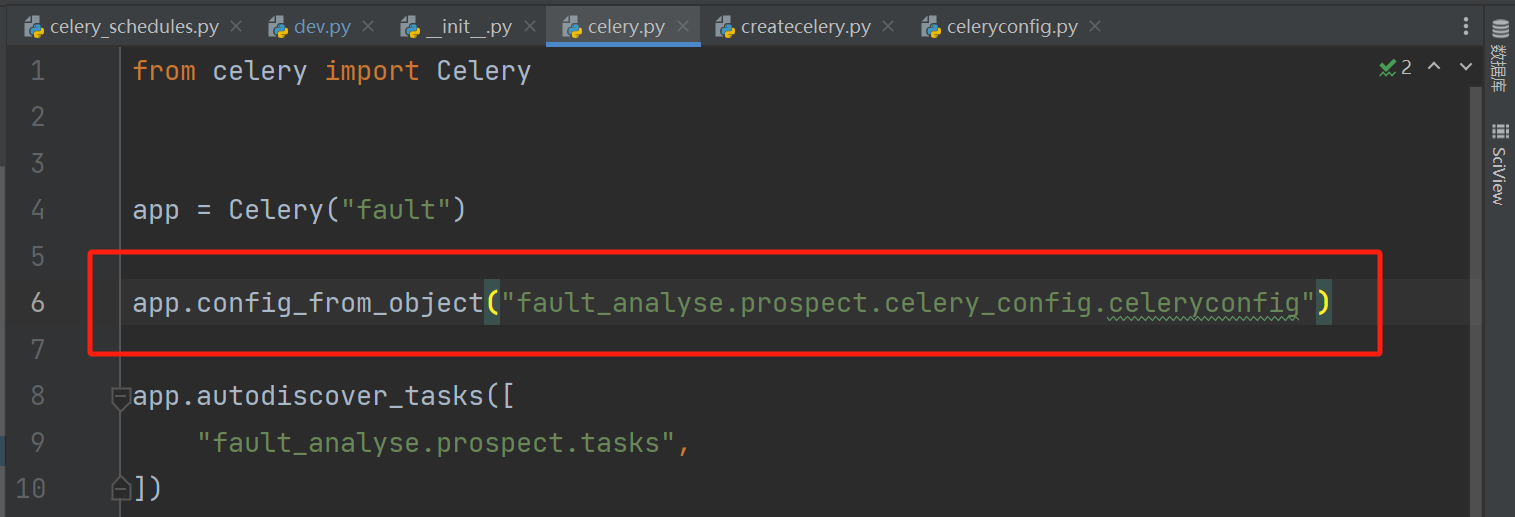
这里的写法不是按照相对位置写的,而是按照:
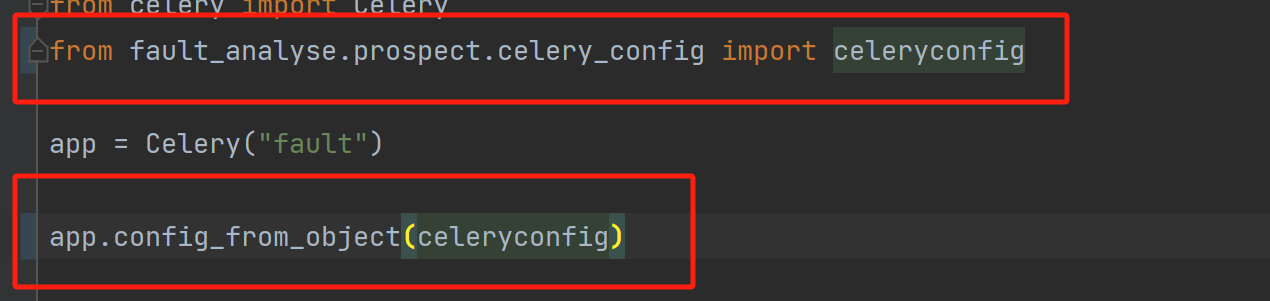
如果你是按照下面的写法写的,那么它就可能造成这个问题。
maximum recursion depth exceeded
递归超过了最大深度
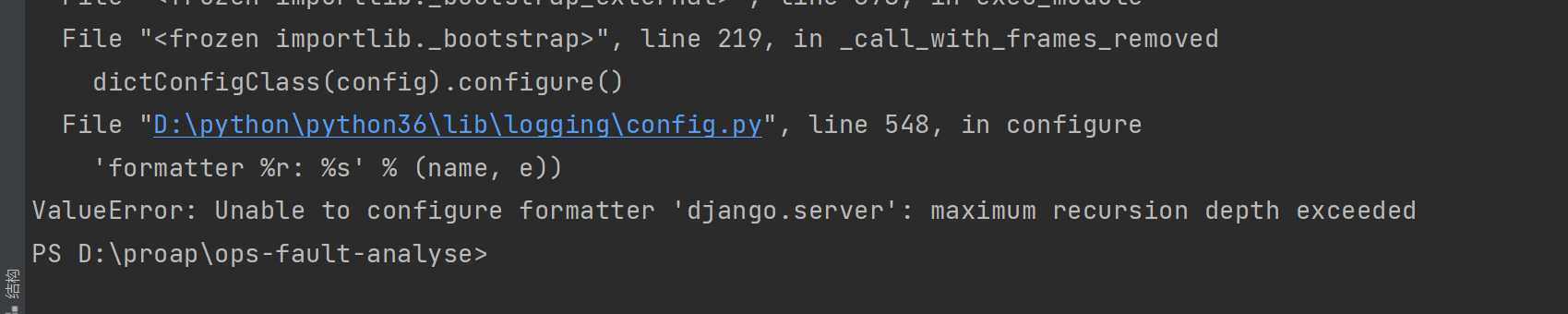
如果是上面的问题,那么在开发阶段,我们用本地自己的redis配置就可以了。
或者在你的dev文件里面,加入他们两个亦可。记得解开注释。