1. 花数据集
数据集来自kaggle官网下载。分为五类花,每类花有1000张图片。下载方式可以参考我的https://www.cnblogs.com/wancy/p/17446715.html
2. 图片大小分布图
训练模型之前,我们会需要先分析数据集,由于此类数据集每类花的图片数量一样,是均衡的。训练模型之前,我们需要传入合适图片大小输入,选择合适的图片大小也会对模型最终性能有一定影响。所以训练模型之前先观察图片大小分布。
import os import cv2 import numpy as np import matplotlib.pyplot as plt # 读取图片文件夹中所有图片的大小信息 def get_image_sizes(image_folder): sizes = [] for folder_name in os.listdir(image_folder): # print("文件夹名"+folder_name) folder_path = os.path.join(image_folder, folder_name) # print(folder_path) if os.path.isdir(folder_path): for img_name in os.listdir(folder_path): image = cv2.imread(folder_path+"/"+img_name) sizes.append((image.shape[0], image.shape[1])) # (height, width) return sizes # 绘制散点图 def plot_size_scatter(sizes): x = [size[1] for size in sizes] # width y = [size[0] for size in sizes] # height plt.scatter(x, y, s=5, alpha=0.5, c='steelblue') plt.title('Image Size Scatter') plt.xlabel('Width (pixel)') plt.ylabel('Height (pixel)') plt.show() # 代码 if __name__ == '__main__': sizes = get_image_sizes('./5-flower-types-classification-dataset/flower_images') print(f'Total images: {len(sizes)}') plot_size_scatter(sizes)

可以发现,图片大部分大小范围在(200x200,1000,1000)以内,在此之内选择比较合适。
3. tensorflow训练模型
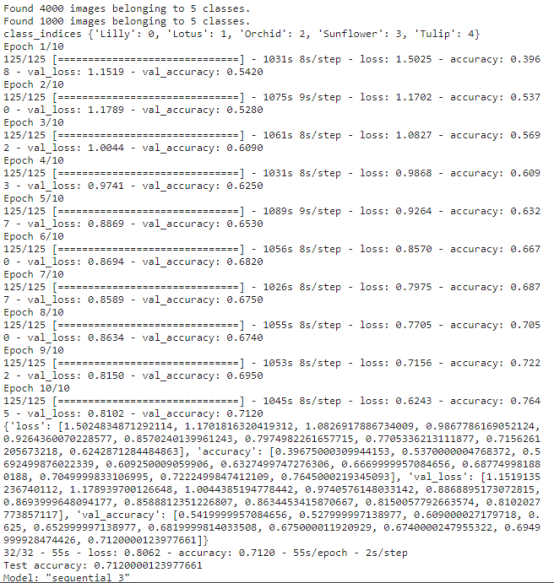
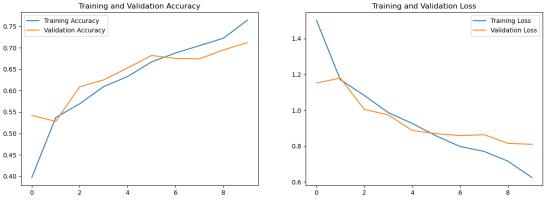
import tensorflow as tf import os from matplotlib import pyplot as plt #from tensorflow.keras.preprocessing import image from tensorflow.keras.callbacks import TensorBoard # 创建TensorBoard回调函数 # tensorboard = TensorBoard(log_dir='./log', historytogram_freq=1) data_dir = './5-flower-types-classification-dataset/flower_images' # 数据路径 # 设置图像尺寸和批次大小 img_size = (224, 224) batch_size = 32 # 将数据文件夹名称存储在列表中 data_folders = os.listdir(data_dir) # 使用 ImageDataGenerator 类读取和增强数据 train_datagen = image.ImageDataGenerator(rescale=1. / 255,rotation_range=20,zoom_range=0.2,horizontal_flip=True,validation_split=0.2) # 读取并划分训练集和测试集数据 train_generator = train_datagen.flow_from_directory(data_dir,target_size=img_size,batch_size=batch_size,class_mode='categorical',subset='training') valid_generator = train_datagen.flow_from_directory(data_dir,target_size=img_size,batch_size=batch_size,class_mode='categorical',subset='validation') #类别标签字典 class_indices = train_generator.class_indices print("class_indices",class_indices)####{'Lilly': 0, 'Lotus': 1, 'Orchid': 2, 'Sunflower': 3, 'Tulip': 4} # 构建模型 # model = tf.keras.Sequential([ # tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(img_size[0], img_size[1], 3)), # tf.keras.layers.MaxPooling2D((2, 2)), # tf.keras.layers.Conv2D(64, (3, 3), activation='relu'), # tf.keras.layers.MaxPooling2D((2, 2)), # tf.keras.layers.Conv2D(128, (3, 3), activation='relu'), # tf.keras.layers.MaxPooling2D((2, 2)), # tf.keras.layers.Flatten(), # tf.keras.layers.Dense(512, activation='relu'), # tf.keras.layers.Dropout(0.5), # tf.keras.layers.Dense(len(data_folders), activation='softmax') # ]) #定义模型 model=tf.keras.Sequential() #conv_layer = layers.Conv2D(64, (3, 3), bias_initializer="zeros", kernel_initializer=GlorotUniform(seed=42)) model.add(tf.keras.layers.Conv2D(32,(3,3),input_shape=(img_size[0], img_size[1], 3),activation="relu",padding="same")) model.add(tf.keras.layers.Conv2D(32,(3,3),activation="relu",padding="same")) #tf.keras.layers.Dropout(0.5) model.add(tf.keras.layers.MaxPool2D())#默认2*2,步长也为2 model.add(tf.keras.layers.Conv2D(64,(4,4),activation='relu',padding="same")) model.add(tf.keras.layers.Conv2D(128,(3,3),activation='relu',padding="same")) model.add(tf.keras.layers.MaxPool2D())#默认2*2,步长也为2 #4维转2维 model.add(tf.keras.layers.Flatten()) model.add(tf.keras.layers.Dense(512,activation='relu')) model.add(tf.keras.layers.Dense(256,activation='relu')) model.add(tf.keras.layers.Dense(5,activation='softmax')) #dense_layer = layers.Dense(64, kernel_initializer=GlorotUniform(seed=42)) # 编译和训练模型 # optimizer = tf.keras.optimizers.Adam(learning_rate=0.001) # model.compile(optimizer=optimizer, ...) """ 在tensorflow.keras中, 如果没有手动指定优化器的学习率,那么model.compile默认使用的Adam优化器的学习率为0.001 """ #sparse_categorical_crossentropy要求target为非onehot编码,函数内部进行onehot编码实现。categorical_crossentropy要求target为onehot编码。 model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) # history = model.fit(train_generator,steps_per_epoch=len(train_generator),epochs=3,validation_data=valid_generator,validation_steps=len(valid_generator),callbacks=[tensorboard]) history = model.fit(train_generator,steps_per_epoch=len(train_generator),epochs=10,shuffle=True,validation_data=valid_generator,validation_steps=len(valid_generator)) #shuffle=True #每个epoch后,将使用validation_steps个batch的数据进行评估 print(history.history) # 评估模型并输出结果 test_loss, test_acc = model.evaluate(valid_generator, verbose=2) print('Test accuracy:', test_acc) model.save('./model/my_model.h5') ##################################################################### print(model.summary()) """ model.summary()是TensorFlow中用于打印模型结构信息的函数。它会输出模型的各层名称、类型、输入和输出张量的形状等信息,以帮助我们了解模型的结构和参数数量。 """ #画图 性能评估 acc = history.history['accuracy'] val_acc = history.history['val_accuracy'] loss =history.history['loss'] val_loss = history.history['val_loss'] plt.figure(figsize=(15, 5)) plt.subplot(1, 2, 1) plt.plot(acc, label='Training Accuracy') plt.plot(val_acc, label='Validation Accuracy') plt.title('Training and Validation Accuracy') plt.legend() #plt.grid() plt.subplot(1, 2, 2) plt.plot(loss, label='Training Loss') plt.plot(val_loss, label='Validation Loss') plt.title('Training and Validation Loss') plt.legend() #plt.grid() plt.show()
运行结果:
4. 测试效果
网上找了几张图片测试。不是很准。
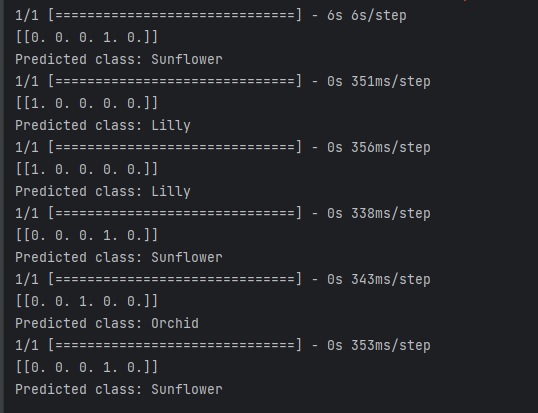
小结:模型训练用得是kaggle平台,训练了10个epoch。准确率达到了70%左右。增加epoch应该能提高准确率。另外,当我将模型从kaggle下载出来拷贝到本地测试分类时,报错了,后来发现,训练的版本为tf2.12.0,本地为2.6.0,相差较大,后改为2.11.0就不报错了。
参考资料:
https://cloud.tencent.com/developer/article/2094683?areaSource=102001.3&traceId=LonVetBuRWMw4aKCESBvu
若存在不足或错误之处,欢迎评论与指正!