简介
StreamingFileSink 提供了将数据分桶写入文件系统的功能。
如何分桶是可以配置,默认使用基于时间的分桶策略,每个小时创建一个新的桶,也可以自定义分桶策略。
文件滚动策略支持两种方式,基于时间和文件大小的DefaultRollingPolicy策略和基于Flink检查点的OnCheckpointRollingPolicy策略。
文件结构及写入方式
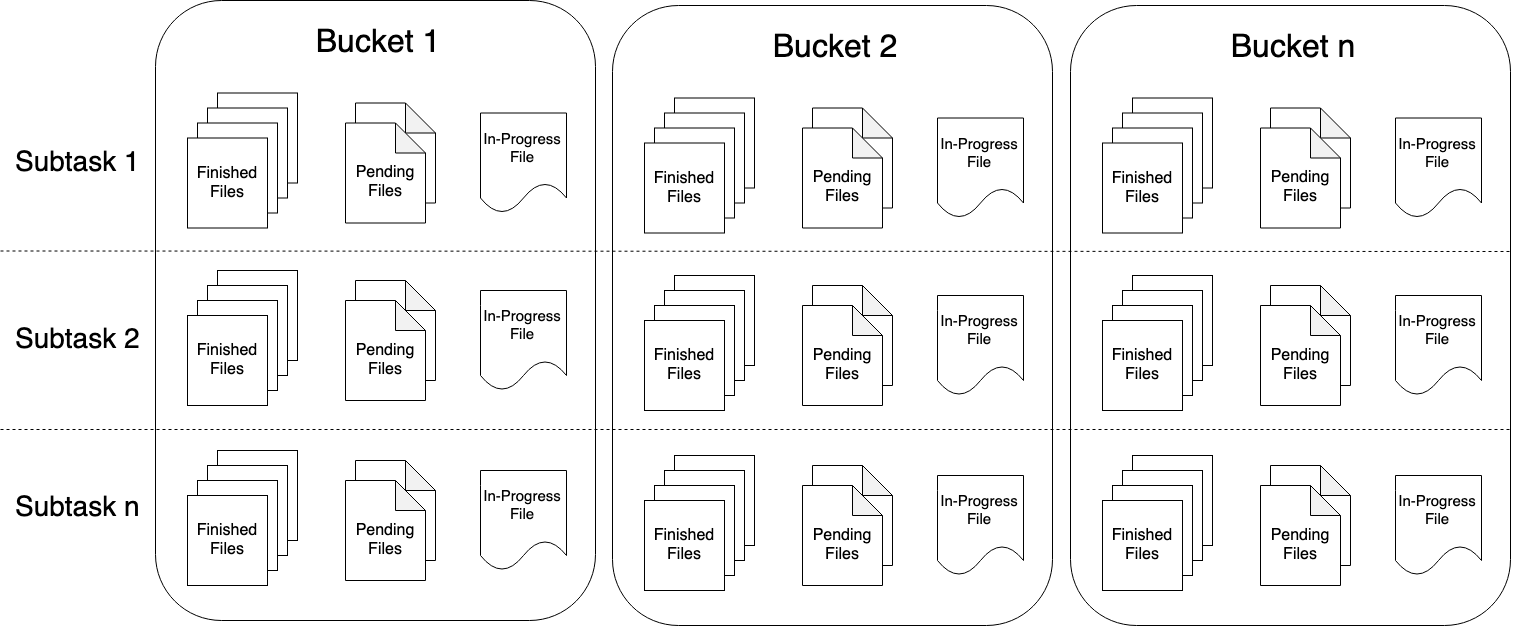
part file三种状态:
- in-progress:表示当前part file正在被写入
- pending:写入完成后等待提交的状态(flink写hdfs的二段提交的体现)
- finished:写入完成状态,只有finished状态下的文件才会保证不会再有修改,下游可安全读取
part file默认命名规则如下:
-
In-progress / Pending: part--.inprogress.uid
-
Finished: part--
flink允许用户给part file自定义前缀和后缀,通过OutputFileConfig即可配置,比如使用"prefix"和"ext"分别作为前、后缀,得到的文件如下:
└── 2019-08-25–12
├── prefix-0-0.ext
├── prefix-0-1.ext.inprogress.bd053eb0-5ecf-4c85-8433-9eff486ac334
├── prefix-1-0.ext
└── prefix-1-1.ext.inprogress.bc279efe-b16f-47d8-b828-00ef6e2fbd11
StreamingFileSink提供了基于行、列两种文件写入格式
Row-encoded sink: StreamingFileSink.forRowFormat(basePath, rowEncoder)
Bulk-encoded sink: StreamingFileSink.forBulkFormat(basePath, bulkWriterFactory)
//行 StreamingFileSink.forRowFormat(new Path(path), new SimpleStringEncoder<T>()) .withBucketAssigner(new PaulAssigner<>()) //分桶策略 .withRollingPolicy(new PaulRollingPolicy<>()) //滚动策略 .withBucketCheckInterval(CHECK_INTERVAL) //检查分桶的时间间隔 .build(); //列 parquet StreamingFileSink.forBulkFormat(new Path(path), ParquetAvroWriters.forReflectRecord(clazz)) .withBucketAssigner(new PaulBucketAssigner<>()) .withBucketCheckInterval(CHECK_INTERVAL) .build();
RowFormatBuilder 允许用户指定:
-
Custom RollingPolicy :自定义滚动策略以覆盖默认的 DefaultRollingPolicy
-
bucketCheckInterval (默认为1分钟):毫秒间隔,用于基于时间的滚动策略。
bulkWriterFactory可以自定义实现,自己想要的格式。
滚动策略
滚动策略 RollingPolicy 定义了指定的文件在何时关闭(closed)并将其变为 Pending 状态,随后变为 Finished 状态。
处于 Pending 状态的文件会在下一次 Checkpoint 时变为 Finished 状态,通过设置 Checkpoint 间隔时间,可以控制部分文件(part file)对下游读取者可用的速度、大小和数量。
Flink 有两个内置的滚动策略:
行/列这两种写入格式除了文件格式的不同,另外一个很重要的区别就是文件滚动策略的不同,forRowFormat行写可基于文件大小、滚动时间、不活跃时间进行滚动,
但是对于forBulkFormat列写方式只能基于checkpoint机制进行文件滚动,即在执行snapshotState方法时滚动文件,如果基于大小或者时间滚动文件,
那么在任务失败恢复时就必须对处于in-processing状态的文件按照指定的offset进行truncate,由于列式存储是无法针对文件offset进行truncate的,
因此就必须在每次checkpoint使文件滚动,其使用的滚动策略实现是OnCheckpointRollingPolicy。
重要: 使用 StreamingFileSink 时需要启用 Checkpoint ,每次做 Checkpoint 时文件写入完成转为Finished状态。如果 Checkpoint 被禁用,部分文件(part file)将永远处于 'in-progress' 或 'pending' 状态,下游系统无法安全地读取。
重要: 批量编码模式仅支持 OnCheckpointRollingPolicy 策略, 在每次 checkpoint 的时候切割文件。
小文件处理
不管是Flink还是SparkStreaming写hdfs不可避免需要关注的一个点就是如何处理小文件,众多的小文件会带来两个影响:
- Hdfs NameNode维护元数据成本增加
- 下游hive/spark任务执行的数据读取成本增加
小文件产生原因:
这与文件滚动周期、checkpoint时间间隔设置相关,如果滚动周期较短、checkpoint时间也比较短或者数据流量有低峰期达到文件不活跃的时间间隔,很容易产生小文件。
几种处理小文件的方式:
- 减少并行度
回顾一下文件生成格式:part + subtaskIndex + connter,其中subtaskIndex代表着任务并行度的序号,也就是代表着当前的一个写task,越大的并行度代表着越多的subtaskIndex,数据就越分散,
如果我们减小并行度,数据写入由更少的task来执行,写入就相对集中,这个在一定程度上减少的文件的个数,但是在减少并行的同时意味着任务的并发能力下降;
- 增大checkpoint周期或者文件滚动周期
以parquet写分析为例,parquet写文件由processing状态变为pending状态发生在checkpoint的snapshotState阶段中,如果checkpoint周期时间较短,就会更快发生文件滚动,增大checkpoint周期,
那么文件就能积累更多数据之后发生滚动,但是这种增加时间的方式带来的是数据的一定延时;
- 下游任务合并处理
待Flink将数据写入hdfs后,下游开启一个hive或者spark定时任务,通过改变分区的方式,将文件写入新的目录中,后续任务处理读取这个新的目录数据即可,同时还需要定时清理产生的小文件,
这种方式虽然增加了后续的任务处理成本,但是其即合并了小文件提升了后续任务分析速度,也将小文件清理了减小了对NameNode的压力,相对于上面两种方式更加稳定,因此也比较推荐这种方式。
通用注意事项
- 重要提示 1
使用 Hadoop < 2.7 时,请使用 OnCheckpointRollingPolicy 滚动策略,该策略会在每次检查点时进行文件切割。 这样做的原因是如果部分文件的生命周期跨多个检查点,
当 StreamingFileSink 从之前的检查点进行恢复时会调用文件系统的 truncate() 方法清理 in-progress 文件中未提交的数据。 Hadoop 2.7 之前的版本不支持这个方法,因此 Flink 会报异常。
- 重要提示 2
鉴于 Flink 的 sink 以及 UDF 通常不会区分作业的正常结束(比如有限流)和异常终止,因此正常结束作业的最后一批 in-progress 文件不会被转换到 “完成” 状态。
- 重要提示 3
Flink 以及 StreamingFileSink 不会覆盖已经提交的数据。因此如果尝试从一个包含 in-progress 文件的旧 checkpoint/savepoint 恢复, 且这些 in-progress 文件会被接下来的成功 checkpoint 提交,
Flink 会因为无法找到 in-progress 文件而抛异常,从而恢复失败。
- 重要提示 4
目前 StreamingFileSink 只支持三种文件系统: HDFS、S3和Local。如果配置了不支持的文件系统,在执行的时候 Flink 会抛出异常。
Demo
列模式写入
行模式写入
参考:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/zh/dev/connectors/streamfile_sink.html