一、海量数据处理的方法总结
参考CSDN技术贴:海量数据处理方法
C++面试必备-海量数据处理
二、快速Json文件解析的库
三、无锁队列
四、C++打包静态库
静态库和动态库
Linux-(C/C++)生成并使用静态库/动态库
c/c++依赖静态库、动态库符号问题
在远程linux服务器上运行C++的可执行文件时,常可能因为缺少对应版本的库而运行错误,因此需要打包静态库后上传运行。打包静态库的方法参照以下几个语句:
-
打包库需要的.o文件:
g++ -c example/upload.cpp -o upload.o -I ./include -
根据.o文件打包静态库:
ar rcs libteam17.a upload.o -
链接静态库生成可执行文件:
g++ example/upload.cpp -o run_upload -static -Wl,--whole-archive -lpthread -Wl,--no-whole-archive -I ./include -L ./libteam17.a -
运行可执行文件:
./run_upload "/data/data" 1694003473274 1694305049996
五、关于C++代码中使用了多线程std::thread,使用-static -lpthread静态编译后,运行段错误的问题。
加强理解所以再整理一下:
在Linux下使用gcc静态编译程序,编译时没有任何告警或错误。但是编译完成运行可执行文件时,会报段错误(Segmentation fault)。
调用gdb调试之后把为题定位在std::thread,调用std::thread::join()或者std::thread::detach(),就会报段错误。
需要注意的是,常规动态编译之后运行,是不会报错的,只有编译静态库会出现这个问题;且这个问题只出现在linux下,Windows下使用MinGW不会报错;可以使用boost::thread代替std::thread,来暂时解决,但是治标不治本。
报错原因:目前这个问题只在ubuntu上存在,在Redhat系平台上不需要这样操作。因为pthread_join是weak symbol,默认静态链接找到第一个符号就不找了,而whole archive会把每个object file包含进来,那么当把strong symbol的pthread_join加进来之后,weak symbol的pthread_join会被strong symbol的“覆盖”掉,就可以避免段错误。但是在Redhat上,首先找到的就不是weak symbol,所以就不需要额外的处理。
ubuntu:

redhat:
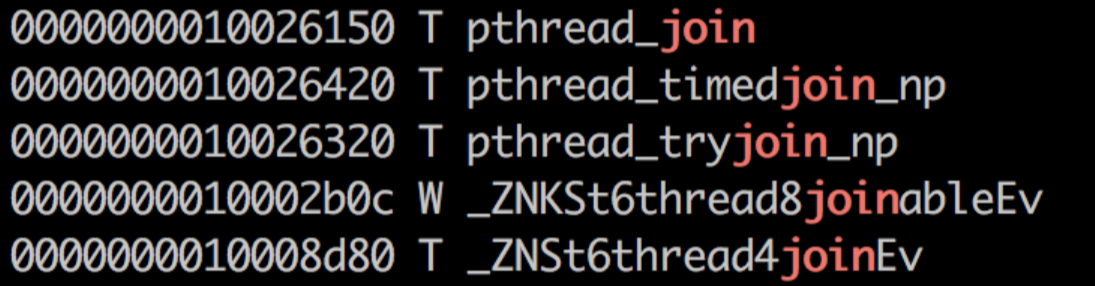
解决办法:把pthread_join的weak symbol 变成strong symbol。
- 在
-lpthread字段后加上-Wl,--whole-archive -lpthread -Wl,--no-whole-archive。 - 显示引用 pthread_join 来源
#include <thread>
void foo()
{
printf("hello\n");
}
int main()
{
auto* f = pthread_join; // **!!!**
std::thread t(foo);
t.join();
}
六、其他程序问题可能导致的段错误总结
七、如何调用gdb调试
关于gdb需要知道的技巧
gdb调试设置断点的方法
C/C++编程:gdb找出程序段错误位置
C/C++编程:linux下的段错误(Segmentation fault)产生的原因及调试方法(经典)
八、多线程,生产者-消费者模型
C++11多线程 创建多个线程、数据共享问题
生产者-消费者模型
C++多线程 链式、循环队列实现生产者消费者
两种实现形式