Golang常见控制结构
条件语句
-
if语句
* 不支持三目运算符* 可省略条件表达式括号* 代码块左括号 必须在条件表达式尾部* else 或 else if 必须和 上一代码块右括号 同一行


if 条件表达式1 { ... } else if 条件表达式2 { ... } else { ... }
-
switch语句
switch var1 { case val1: ... case val2: ... default: ... } //能用来判断某个 interface 变量中实际存储的变量类型 var x interface{} switch x.(type){ case nil: ... case type1: ... case type2: ... default: /* 可选 */ ... }
需要注意的是:Go里面switch默认相当于每个 case 最后带有 break,匹配成功后不会自动向下执行其他 case,而是跳出整个 switch, 但是可以使用 fallthrough 强制执行后面的case代码。
-
select语句
select中的default子句总是可运行的。
如果有多个case都可以运行,select会随机公平地选出一个执行,其他不会执行。
如果没有可运行的case语句,且有default语句,那么就会执行default的动作。
如果没有可运行的case语句,且没有default语句,select将阻塞,直到某个case通信可以运行
经典用法
//比如在下面的场景中,使用全局resChan来接受response,如果时间超过3S,resChan中还没有数据返回,则第二条case将执行 var resChan = make(chan int) // do request func test() { select { case data := <-resChan: doData(data) case <-time.After(time.Second * 3): //time.After() 返回一个channel fmt.Println("request time out") } }
func main() { ch := make(chan int, 1) go func() { for i := 1; i <= 5; i++ { ch <- i time.Sleep(1 * time.Second) } close(ch) }() for { select { case val, ok := <-ch: if ok { fmt.Println(val) } else { //通道关闭 ch = nil } default: fmt.Println("No value ready") time.Sleep(500 * time.Millisecond) } if ch == nil { break } } }
数据结构
源码文件:src/runtime/select.go line:19 type scase struct { c *hchan // 存储 case 使用的 channel elem unsafe.Pointer // 指向 case 中数据的指针 //例如 case ch1 <- data,elem 指向 data }
实现原理

编译器在中间代码生成期间会根据 select 中 case 的不同对控制语句进行优化,这一过程都发生在 src/cmd/compile/internal/walk/select.go 的 walkSelectCases() 函数中,函数对四种不同 case 情况,会调用不同的函数:
1.select 不存在任何的 case;
walkSelectCases() 会直接调用 runtime.block() 函数,而 runtime.block() 会调用 gopark() 函数,以 waitReasonSelectNoCases 的原因挂起当前协程,并且永远无法被唤醒,Go程序检测到这种情况,直接panic。
源码文件:src/cmd/compile/internal/walk/select.go line:33 func walkSelectCases(cases []*ir.CommClause) []ir.Node { ncas := len(cases) sellineno := base.Pos // select没有case时 if ncas == 0 { return []ir.Node{mkcallstmt("block")} } ...
2.select 只存在一个 case;
只有一个时,对 case 的处理就是对普通 channel 的读写操作
(紧接上述代码) // select 只有一个 case 时 if ncas == 1 { cas := cases[0] ir.SetPos(cas) l := cas.Init() if cas.Comm != nil { //不是default n := cas.Comm //获取 case 的条件语句 l = append(l, ir.TakeInit(n)...) switch n.Op() { //检查 case 对 channel 的操作:读或写 default: //case 不读不写,直接报错 base.Fatalf("select %v", n.Op()) case ir.OSEND: // 写操作,不用转换形式,直接是 chan <- data case ir.OSELRECV2: //读操作,有不同形式 r := n.(*ir.AssignListStmt) if ir.IsBlank(r.Lhs[0]) && ir.IsBlank(r.Lhs[1]) { //<- chan 形式 n = r.Rhs[0] break } r.SetOp(ir.OAS2RECV) //data,ok := <- chan 形式 } l = append(l, n) //case 条件语句加入待执行语句列表 } l = append(l, cas.Body...) //case 条件后的语句加入待执行语句列表 l = append(l, ir.NewBranchStmt(base.Pos, ir.OBREAK, nil)) //默认加入break return l } ...
之后的3和4的源码有点复杂,之后再详细了解,这里只是简单描述其实现逻辑。
3.select 存在两个 case,其中一个 case 是 default;
- 判断 case 的条件语句是写操作还是读操作
- 写操作调用 selectnbsend() 函数,读操作调用 selectnbrecv() 函数
- 编译器将 select 改写为 if 语句,case 的条件语句作为 if 的条件语句( selectnbsend() 或 selectnbrecv() ),default 放入 else 分支
4.select 存在多个 case;
- 生成scase对象数组,定义selv和order数组,selv存放scase数组内存地址,order用来做scase排序使用,对scase数组排序是为了以某种机制选出待执行的case;
- 编译器生成调用 runtime.selectgo() 的逻辑,selv和order数组作为入参传入selectgo() 函数,同时定义该函数的返回值,chosen 和 recvOK,chosen 表示被选中的case的索引,recvOK表示对于接收操作,是否成功接收;
- 根据 selectgo 返回值 chosen 来生成 if 语句来执行相应索引的 case。
循环控制
-
for语句
s := "abc" for i, n := 0, len(s); i < n; i++ { // 常见的 for 循环,支持初始化语句。 println(s[i]) } n := len(s) for n > 0 { // 替代 while (n > 0) {} println(s[n]) // 替代 for (; n > 0;) {} n-- } for { // 替代 while (true) {} println(s) // 替代 for (;;) {} }
-
range语句
//遍历切片 func RangeSlice(slice []int) { for index, value := range slice { //当数据量大 或 value类型为string时,对value的赋值可能是多余的,可以用 slice[index] 引用 value值 _, _ = index, value } } //遍历map func RangeMap(myMap map[int]string) { for key, _ := range myMap { _, _ = key, myMap[key] //在map中,通过 key值 查找 value值 的性能消耗可能高于赋值消耗,取决于 value 的数据结构特征 } }
//range 会复制对象
func main() {
a := [3]int{0, 1, 2}
for i, v := range a { //index、value 都是从复制品中取出。
if i == 0 { //在修改前,我们先修改原数组。
a[1], a[2] = 999, 999
fmt.Println(a) //确认修改有效,输出 [0, 999, 999]。
}
a[i] = v + 100 //使用复制品中取出的 value 修改原数组。
}
fmt.Println(a) //输出 [100, 101, 102]。
}
-
Goto、Break、Continue
三个语句都可以配合标签(label)
使用标签名区分大小写,定以后若不使用会造成编译错误
continue、break配合标签(label)可用于多层循环跳出
func Demo() { Tag: for i := 0; i < 10; i++ { for j := 0; j < 10; j++ { if j == 2 { //break Tag //退出 Tag 对应的代码块 //continue Tag //结束当前循环,开始 Tag 对应代码块的下一次循环迭代过程 goto GotoTag //前往GotoTag } fmt.Printf("%v-%v\n", i, j) } } GotoTag: fmt.Println("结束for循环") }
访问控制
-
mutex
互斥锁是并发程序中对共享资源进行访问控制的主要手段,对此Go语言提供了非常简单易用的Mutex,Mutex为一结构体类型,对外暴露两个方法Lock()和Unlock()分别用于加锁和解锁。
mutex数据结构
源码文件:src/sync/mutex.go line:34 type Mutex struct { state int32 sema uint32 }
- Mutex.state表示互斥锁的状态,内部实现时把该变量分成四份,用于记录Mutex的四种状态。
- Mutex.sema表示信号量,协程阻塞等待该信号量,解锁的协程释放信号量从而唤醒等待信号量的协程。
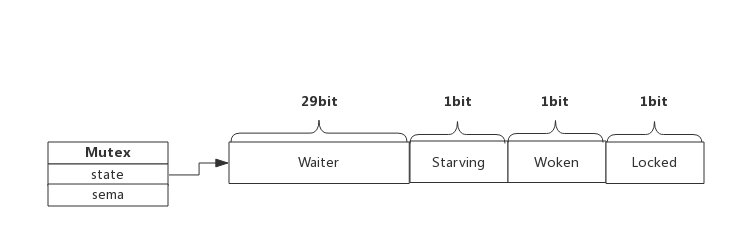
- Locked: 表示该Mutex是否已被锁定,0:没有锁定 1:已被锁定。
- Woken: 表示是否有协程已被唤醒,0:没有协程唤醒 1:已有协程唤醒,正在加锁过程中。
- Starving:表示该Mutex是否处于饥饿状态,0:没有饥饿 1:饥饿状态,说明有协程阻塞了超过1ms。
- Waiter: 表示阻塞等待锁的协程个数,协程解锁时根据此值来判断是否需要释放信号量。
加锁 Lock()
1.首先如果当前锁处于未加锁状态就直接用 CAS 方法尝试获取锁,这是 Fast Path
2.如果失败就进入 Slow Path
源码文件:src/sync/mutex.go line:81 func (m *Mutex) Lock() { // Fast path: 当Mutex处于Unlocked状态,没有goroutine在排队,更没有饥饿,即Mutex.state = 0 时,可以直接获得锁 if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) { ... //精简了race检测相关的代码 return } // 当没有直接获得锁时,进入 Slow path m.lockSlow() }
3.Slow path 会首先判断当前能不能进入自旋状态,如果可以就进入自旋,最多自旋 4 次
- mutexLocked | mutexStarving 等于 ( 0000 0001B | 0000 0100B = 0000 0101B) 含义代表处于饥饿模式并且已加锁
- old & (mutexLocked | mutexStarving) == mutexLocked 等于 (old & 0000 0101B) = 0000 0001B) 含义代表 old 必须不是饥饿模式,并且已加锁。
- old & mutexWoken == 0 等于(old & 0000 0010B = 0 ) 含义代表 old 的 Woken 位上必须为0,说明代表原来状态不是唤醒的
- old >> mutexWaiterShift != 0 代表丢掉后面三位获取 m.state 前面的位数,也就是 waiter 等待者的数量,含义就是等待者数量不为0
- old | mutexWoken 代表将 old 设置为唤醒,因为(任何数 | 0000 0010B)状态都是唤醒的
源码文件:src/sync/mutex.go line:45、117
const(
mutexLocked = 1 << iota //0000 0001B
mutexWoken //0000 0010B
mutexStarving //0000 0100B
mutexWaiterShift = iota // = 3
starvationThresholdNs = 1e6
)
...
func (m *Mutex) lockSlow() { var waitStartTime int64 // 当前goroutine等待时间 starving := false // 当前goroutine是否处于饥饿状态 awoke := false // 当前goroutine是否处于唤醒状态 iter := 0 // 当前goroutine自旋迭代次数 old := m.state //复制当前锁状态 for { if old&(mutexLocked|mutexStarving) == mutexLocked && runtime_canSpin(iter) { //判断 old 不处于饥饿状态,且已加锁,当前goroutine自旋次数小于4次 if !awoke && old&mutexWoken == 0 && old>>mutexWaiterShift != 0 && //当前goroutine不处于唤醒状态,且锁的 waiter != 0时 atomic.CompareAndSwapInt32(&m.state, old, old|mutexWoken) { //将 m.state 设置为唤醒,通知Unlock不要唤醒其他goroutines awoke = true } runtime_doSpin() //自旋等待锁的释放 iter++ old = m.state //新状态覆盖老状态 continue } ...
4.自旋完成之后,就会去计算当前的锁的状态:
- 锁还没有被释放,锁处于正常状态;
- 锁还没有被释放,锁处于饥饿状态;
- 锁已经被释放,锁处于正常状态;
- 锁已经被释放,锁处于饥饿状态;
(紧接上述代码) //new 用来设置新的状态 new := old //如果来到这里就停止自旋了,如果第一次来到这里,说明只执行了自旋,并且有进行其他操作,也没为饥饿 //如果 old 不是饥饿状态,尝试获得锁 if old&mutexStarving == 0 { //old&mutexStarving == 0 相当于(old & 0000 0100B) == 0,说明原来不是饥饿模式 new |= mutexLocked //意思是将m.state的最后一位置为1 ,new 现在是上锁了 }
//如果 old 处于加锁或饥饿状态,goroutine 进入等待队列 if old&(mutexLocked|mutexStarving) != 0 { //mutexLocked|mutexStarving == 0000 0001B|0000 0100B = 0000 0101B //(old & 0000 0101B)!=0说明,原来是加锁的或者原来是饥饿的 new += 1 << mutexWaiterShift //此时将waiter数量+1 }
//如果当前 goroutine 处于饥饿状态,且 old 处于加锁状态,将 new 设为饥饿状态 if starving && old&mutexLocked != 0 { new |= mutexStarving }
//如果当前 goroutine 是被唤醒状态,重置 锁(new)的唤醒标志
//因为接下来 goroutine 要么是拿到锁了,要么是进入了等待队列 if awoke { if new&mutexWoken == 0 { throw("sync: inconsistent mutex state") } // &^ 是将new 的唤醒位清空 // mutexWoken=&0000 0010B,当任何数与这个进行&^操作时,都会被置为0,如果new Woken为1,那么就会被清空为0,如果new Woken为0,那么与左侧保持一致,为0。 new &^= mutexWoken }
5.然后尝试通过 CAS 获取锁
- CAS 方法在这里指的是
atomic.CompareAndSwapInt32(addr, old, new) bool方法,这个方法会先比较传入的地址的值是否是 old,如果是的话就尝试赋新值,如果不是的话就直接返回 false,返回 true 时表示赋值成功 - 如果没有获取到就调用
runtime_SemacquireMutex方法休眠当前 goroutine 并且尝试获取信号量,直到被唤醒 - goroutine 被唤醒之后会先判断当前 goroutine 是否处在饥饿状态,(如果当前 goroutine 超过 1ms 都没有获取到锁就会进饥饿模式)
- 之后判断 锁 是否处于饥饿状态
- 如果锁处在饥饿状态,当前 goroutine 就会获得互斥锁,如果等待队列中只存在当前 goroutine 或者当前 goroutine 不处于饥饿状态,锁就会从饥饿模式中退出
- 如果锁不在饥饿状态,当前 goroutine 就会设置唤醒标记、重置迭代次数并重新执行获取锁的循环
(紧接上述代码) //尝试将 m.state 设置为 new if atomic.CompareAndSwapInt32(&m.state, old, new) { // 进入这个代码块代表锁状态被改变了,不一定是上锁成功 if old&(mutexLocked|mutexStarving) == 0 { // 成功上锁 break // locked the mutex with CAS } queueLifo := waitStartTime != 0 // 如果 waitStartTime = 0,则queueLifo = false,说明之前已经等待过了,放到等待队列头,否则排队列尾 if waitStartTime == 0 { waitStartTime = runtime_nanotime() // 如果没有等待过,就初始化设置现在的等待时间 } runtime_SemacquireMutex(&m.sema, queueLifo, 1) // 使用 sleep 原语来阻塞当前 goroutine,直到被唤醒 // 被唤醒后,从此处开始执行 starving = starving || runtime_nanotime()-waitStartTime > starvationThresholdNs // 如果当前 goroutine 等待时间超过 starvationThresholdNs,mutex 进入饥饿模式 old = m.state // 再次获取锁当前状态 if old&mutexStarving != 0 { //old 处于饥饿状态,且当前 goroutine 被唤醒,意味锁被直接交给了当前 goroutine if old&(mutexLocked|mutexWoken) != 0 || old>>mutexWaiterShift == 0 { //old 处于非法状态时 throw("sync: inconsistent mutex state") } delta := int32(mutexLocked - 1<<mutexWaiterShift) // 当前的goroutine获得了锁,那么就把等待队列-1 if !starving || old>>mutexWaiterShift == 1 { // 如果当前 goroutine 不是饥饿模式或只剩一个等待者时 delta -= mutexStarving // 锁退出饥饿模式 } atomic.AddInt32(&m.state, delta) // 设置新state, 因为已经获得了锁,退出、返回 break } // 如果锁不是饥饿模式,就把当前的goroutine设为被唤醒,并且重置iter(重置spin) awoke = true iter = 0 } else { // 如果CAS不成功,重新获取锁的state, 从for循环开始处重新开始 old = m.state }
解锁 Unlock()
源码文件:src/sync/mutex.go line:212 func (m *Mutex) Unlock() { ... //精简了race检测相关的代码 // Fast path: 原子操作释放锁 new := atomic.AddInt32(&m.state, -mutexLocked) if new != 0 { // 根据 state 的新值 new 来判断是否需要执行 Slow path m.unlockSlow(new) } }
unlockSlow
源码文件:src/sync/mutex.go line:227 func (m *Mutex) unlockSlow(new int32) { if (new+mutexLocked)&mutexLocked == 0 { //new+mutexLocked代表将锁置为1,如果两个状态& 不为0,则说明重复解锁,panic fatal("sync: unlock of unlocked mutex") } if new&mutexStarving == 0 { //锁不处于饥饿状态 old := new for { //当等待队列为 0 或锁处于 加锁、唤醒或饥饿状态时 if old>>mutexWaiterShift == 0 || old&(mutexLocked|mutexWoken|mutexStarving) != 0 { return //直接返回,因为在唤醒状态时,goroutine 会自己抢锁,饥饿状态会直接把锁给队头 } //等待队列-1,并让锁进入唤醒状态 new = (old - 1<<mutexWaiterShift) | mutexWoken if atomic.CompareAndSwapInt32(&m.state, old, new) { //更新锁状态,尝试获取唤醒一个 goroutine 的权力 runtime_Semrelease(&m.sema, false, 1) //更新成功,唤醒一个 goroutine return } old = m.state //更新失败,获取当前锁状态,循环尝试 } } else { //锁处于饥饿模式,把锁直接交给等待队列头 runtime_Semrelease(&m.sema, true, 1) } }
-
rwmutex
读写锁相对于互斥锁来说粒度更细,可以说是Mutex的一个改进版,非常适合读多写少的场景。使用读写锁可以并发读,但是不能并发读写,或者并发写写
rwmutex数据结构
源码文件:src/sync/rwmutex.go line:35 type RWMutex struct { w Mutex // 复用互斥锁 writerSem uint32 // 信号量,用于写等待读 readerSem uint32 // 信号量,用于读等待写 readerCount int32 // 当前执行读的 goroutine 数量 readerWait int32 // 写操作被阻塞的准备读的 goroutine 的数量 }
因为复用了mutex的代码,rwmutex的源码很简单,就不在叙述了,这里就简略描述加锁、解锁的逻辑:
写锁
加锁:先获取互斥锁(阻塞其他写操作),将 readerCount 赋值给 readerWait,再将 readerCount 减去 2^30(阻塞后来的读操作),然后阻塞等待当前所有读操作结束
解锁:将 readerCount 加上 2^30,唤醒所有因写操作被阻塞的准备读的 goroutine,然后解除互斥锁
读锁
加锁:增加当前执行读的 goroutine 数量,然后阻塞等待当前写操作结束(当 readerCount < 0 时,说明当前有写操作执行)
解锁:减少当前执行读的 goroutine 数量,然后唤醒等待写操作的 goroutine(当 readerWait = 0 时,说明有写操作准备执行,且后面的读操作被阻塞,之前的读操作已全部结束)