20230407:tensorflow transformer
-
tf.name_scope:
这个函数会规定对象和操作属于那个范围,但是不会对“对象”的“作用域”产生任何影响,也就是不是全局变和局部变量的概念.
这个东西有很多种用法:with tf.name_scope("loss"): #这个名字是随意指定,看你想干什么 xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,logits= logits) with tf.name_scope()"cgx_name_scope"): a = tf.constant(1,name='my_a') #定义常量 b = tf.Variable(2,name='my_b') #定义变量 c = tf.add(a,b,name='my_add') #二者相加(操作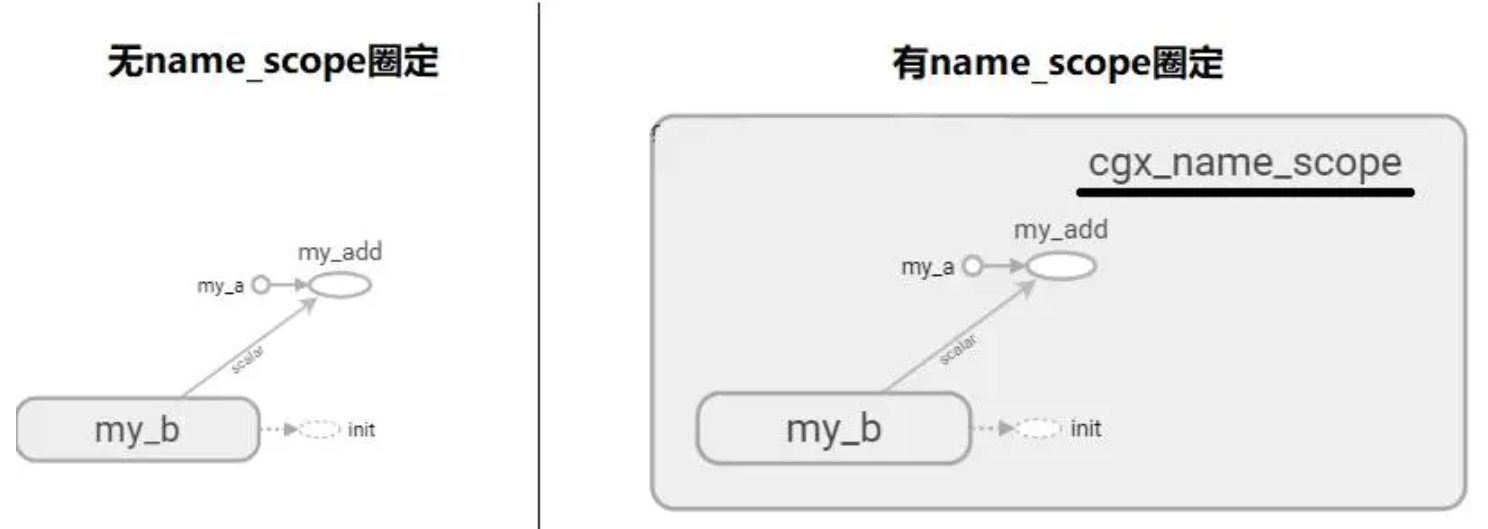
在上图可以看到,有固定的话会在tensorboard中圈出来.
-
Transformers的来源(转载地址)
- Huggingface
Huggingface(抱抱脸)总部位于纽约,是一家专注于自然语言处理、人工智能和分布式系统的创业公司。他们所提供的聊天机器人技术一直颇受欢迎,但更出名的是他们在NLP开源社区上的贡献。Huggingface一直致力于自然语言处理NLP技术的平民化(democratize),希望每个人都能用上最先进(SOTA, state-of-the-art)的NLP技术,而非困窘于训练资源的匮乏。
除了官网,他们在http://medium.com上也时常有高质量的分享,这里是他们的medium主页。https://medium.com/huggingface/aboutmedium.com/huggingface/about
- Transformer结构和BERTology家族
2020年,NLP最前沿的研究领域基本上已经被大型语言模型+迁移学习这一范式所垄断了。
2017年6月,研究人员提出了Transformer编码解码结构, 这一结构也成为了后续一系列工作的基石。2018年10月,基于Transformer,Google的研究人员发布了“全面超越人类”的BERT,一种融合了双向上下文信息预训练语言模型,该模型当时一举打破了11项纪录。从此之后,BERT的继任者们百花齐放,不断刷新各leaderboard最高成绩。现在,这些研究被称为BERTology,不完全的名单包括:Transformer-XL, XLNet, Albert, RoBERTa, DistilBERT, CTRL, ...
BERTs模型虽然很香,但是用起来还是有一些障碍,比如:
- 预训练需要大量的资源,一般研究者无法承担。以RoBERTa为例,它在160GB文本上利用1024块32GB显存的V100卡训练得到,如果换算成AWS上的云计算资源的话,但这一模型就需要10万美元的开销。
- 很多大机构的预训练模型被分享出来,但没有得到很好的组织和管理。
- BERTology的各种模型虽然师出同源,但在模型细节和调用接口上还是有不少变种,用起来容易踩坑
- Transformers名字的历史沿革
为了让这些预训练语言模型使用起来更加方便,Huggingface在github上开源了Transformers。这个项目开源之后备受推崇,截止2020年5月,已经累积了26k的star和超过6.4k的fork。
Transformers最早的名字叫做pytorch-pretrained-bert,推出于google BERT之后。顾名思义,它是基于pytorch对BERT的一种实现。pytorch框架上手简单,BERT模型性能卓越,集合了两者优点的pytorch-pretrained-bert自然吸引了大批的追随者和贡献者。
其后,在社区的努力下,GPT、GPT-2、Transformer-XL、XLNET、XLM等一批模型也被相继引入,整个家族愈发壮大,这个库适时地更名为pytorch-transformers。
深度学习框架上一直存在着pytorch和tensorflow两大阵营,为了充分利用两个框架的优点,研究人员不得不经常在两者之间切换。Transformers的开发者们也敏锐地抓住了这一个痛点,加入了pytorch和TF2.0+的互操作性,模型之间可以方便地互相转换,算法的实现也是各自最native的味道。此举显然笼络了更多的自然语言研究人员和从业者投入麾下。而项目的名字,也顺理成章地改成了现在的Transformers。时至今日,Transformers已经在100+种人类语言上提供了32+种预训练语言模型。作为NLP的从业者,真的很难抵制住去一探究竟的诱惑。
- Transformers的设计理念
了解一下Transformers库的设计理念有助于更好地使用它。
-
分享及关爱。我们把各种模型和代码汇集到一处,从而使得更多人可以共享昂贵的训练资源。我们提供了简单一致的API,遵循经典的NLP Pipeline设计。
-
性能优异且易于访问。一方面我们会尽可能让模型复现论文中的最优结果,一方面我们也尽力降低使用的门槛。我们的三大组件configuration, tokenizer和model都可以通过一致的from_pertrained()方法来实例化。
-
注重可解释性和多样性。我们让使用者能够轻松访问到hidden states, attention weights和head importance这样的内部状态,从而更好地理解不同的模型是如何运作的。我们提供了类似GLUE, SuperGLuE, SQuAD这样的基准测试集的接入,方便对不同模型效果进行比较。
-
推进传播最佳实践。在贴近原模型作者意图的基础上,我们的代码实现会尽可能地规范化,遵循业界的最佳实践,比如对于PyTorch和TensorFlow 2.0的完全兼容。
-
从学界到业界。在工业级支持上,Transformers的模型支持TorchScript,一种PyTorch中创建可序列化可优化模型的方式,也能够和Tensorflow Extended框架相兼容。
- Transformers的组件和模型架构
Transformers提供了三个主要的组件。
- Configuration配置类。存储模型和分词器的参数,诸如词表大小,隐层维数,dropout rate等。配置类对深度学习框架是透明的。
- Tokenizer分词器类。每个模型都有对应的分词器,存储token到index的映射,负责每个模型特定的序列编码解码流程,比如BPE(Byte Pair Encoding),SentencePiece等等。也可以方便地添加特殊token或者调整词表大小,如CLS、SEP等等。
- Model模型类。提供一个基类,实现模型的计算图和编码过程,实现前向传播过程,通过一系列self-attention层直到最后一个隐藏状态层。在最后一层基础上,根据不同的应用会再做些封装,比如XXXForSequenceClassification,XXXForMaskedLM这些派生类。
Transformers的作者们还为以上组件提供了一系列Auto Classes,能够从一个短的别名(如bert-base-cased)里自动推测出来应该实例化哪种配置类、分词器类和模型类。
Transformers提供两大类的模型架构,一类用于语言生成NLG任务,比如GPT、GPT-2、Transformer-XL、XLNet和XLM,另一类主要用于语言理解任务,如Bert、DistilBert、RoBERTa、XLM.
-
对于BERT来说,如果单从网络结构上来说的话,个人感觉并没有太大的创新,这也正如作者所说”BERT整体上就是由多层的Transformer Encoder堆叠所形成“,并且所谓的”Bidirectional“其实指的也就是Transformer中的self-attention机制。真正让BERT表现出色的应该是基于MLM和NSP这两种任务的预训练过程,使得训练得到的模型具有强大的表征能力。在下一篇文章中,掌柜将会详细介绍如何动手来实现BERT模型,以及如何载入现有的模型参数并运用在下游任务中。