常见的几种数据同步方案
微微一笑 码易有道 2024-01-07 16:25 发表于北京
关键词:数据同步、数据异构、数据迁移
引言
当今时代,数据是企业运营的核心。随着业务的扩张和用户规模的增加,确保不同部分之间的数据一致性、实时性和可靠性变得尤为关键。本文将探讨几种常见的数据同步方案,涵盖了数据库主从同步、数据迁移同步和数据实时同步。通过深入了解各种方案的特点、优势和局限性,我们可以更好地选择和定制适合特定业务场景的数据同步策略,为构建高效、稳定、可扩展的系统奠定基础。
主要内容如下:
方案一、数据库主从复制
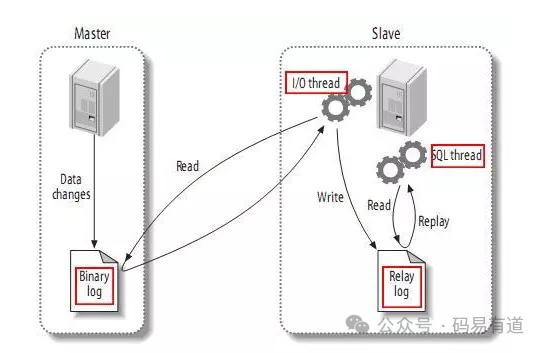
数据库主从复制是一种常见的数据同步方案,其中主数据库将其变更操作传播到一个或多个从数据库。
MySQL数据库主从复制的配置步骤:
- 确保主从数据库版本一致:确保主数据库和从数据库使用相同的MySQL版本,以避免兼容性问题。
- 配置主数据库:在主数据库上进行配置,打开MySQL配置文件(通常是my.cnf或my.ini),参数设置:
#设置主服务器的唯一标识
server-id = 1
#启用二进制日志,记录主数据库上的所有更改
log_bin = /var/log/mysql/mysql-bin.log
#指定要复制的数据库
binlog_do_db = your_database_name
- 创建复制用户: 在主数据库上创建一个用于复制的用户,确保该用户具有适当的权限:
#replication_user和replication_password替换成自己的用户名和密码
#创建用于复制的用户
create user 'replication_user'@'%' identified by 'replication_password';
#复制授权
grant replication slave on *.* to 'replication_user'@'%';
#刷新权更改应用
flush privileges;
- 获取主数据库的二进制日志位置: 在主数据库上执行以下命令,记录输出的File和Position,配置从数据库时用到:
SHOW MASTER STATUS;
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 6470 | your_name | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
- 配置从数据库:在从数据库上进行配置,打开MySQL配置文件,参数设置:
server-id = 2
保存配置并重启从数据库。
- 连接从数据库到主数据库: 在从数据库上执行以下命令,替换master_host、master_user、master_password、master_log_file和master_log_pos为主数据库的信息:
#配置从数据库连接到主数据库
change master to
master_host = 'master_host',
master_user = 'replication_user',
master_password = 'replication_password',
#从SHOW MASTER STATUS;中获取的File值。
master_log_file = 'master_log_file',
#从SHOW MASTER STATUS;中获取的Position值
master_log_pos = master_log_pos;
- 启动从数据库的复制进程:
START SLAVE;
- 验证复制状态: 在主数据库上进行一些数据更改,并在从数据库上执行以下命令:
SHOW SLAVE STATUS\G
总之,数据库主从复制方案,适用于读多写少的场景,读请求可以分担到从数据库,减轻主数据库负载。优势: 提高读取性能,分担主数据库负载,提供容灾和备份机制。局限性: 存在复制延迟,可能导致从数据库数据不一致;主库单点故障可能影响整个系统;不适用于写入密集型应用。
方案二、ETL工具数据迁移
ETL(Extract, Transform, Load)工具广泛用于不同数据存储系统之间的数据迁移、整合和同步,特别是在大规模数据迁移、数据仓库建设、数据清洗和转换等方面。常见的ETL工具有:
名称 | 主要特点 | 适用场景 |
|---|---|---|
Apache NiFi | 提供直观的可视化界面,支持实时数据流,强调易用性和可管理性 | 适用于构建实时数据流程,易用界面,强大的管理功能 |
Talend Open Studio | 强大的图形化界面和丰富的连接器,支持多种数据源和目标,复杂的转换和清洗功能 | 适用于复杂数据转换,多源多目标数据同步,大规模数据迁移 |
Apache Camel | 基于企业集成模式,支持多种协议和数据格式 | 适用于构建灵活的数据集成解决方案,企业级数据集成和消息路由 |
Kettle (Pentaho) | 提供图形界面,支持强大的数据操作和转换功能,整合Pentaho平台的其他组件 | 适用于全面数据整合,业务智能和数据分析 |
选择建议:
- 如果注重实时数据流程和易用性,Apache NiFi 是一个好的选择。
- 对于复杂数据转换和大规模迁移,Talend Open Studio 提供了丰富的功能和广泛的连接器。
- 如果已经使用 Apache Camel 的其他组件,或需要高度灵活性和可定制性,可以考虑使用 Apache Camel。
- 对于全面数据整合和业务智能,Pentaho Data Integration 可能是一个全面的解决方案。
具体使用依赖于企业的具体需求、技术栈和团队的技能水平。
这里我们以Apache NiFi为例简单探究其使用,说明数据迁移的过程即可。
官网地址:https://nifi.apache.org/
下载地址:https://archive.apache.org/dist/nifi/
安装和部署读者自行查阅。这里根据ETL功能说明下主要执行流程。
单机架构:
Web Server Web服务器的作用是托管NiFi的基于HTTP的命令和控制API。
Flow Controller 流程控制器是整个操作的核心。它为扩展提供线程运行,并管理扩展何时接收到执行资源的调度。
Extensions 有各种类型的NiFi扩展,这些在其他文档中有描述。这里的关键点是扩展在JVM中运行和执行。
FlowFile Repository FlowFile存储库是NiFi用于跟踪当前在流中活动的给定FlowFile状态的地方。存储库的实现是可插拔的。
Content Repository 内容存储库是给定FlowFile的实际内容字节所在的地方。
Provenance Repository Provenance存储库是存储所有Provenance事件数据的地方。
工具定位及使用流程:
这边就以从mysql查询数据在写入到mysql为例做一个简单流程进行演示:
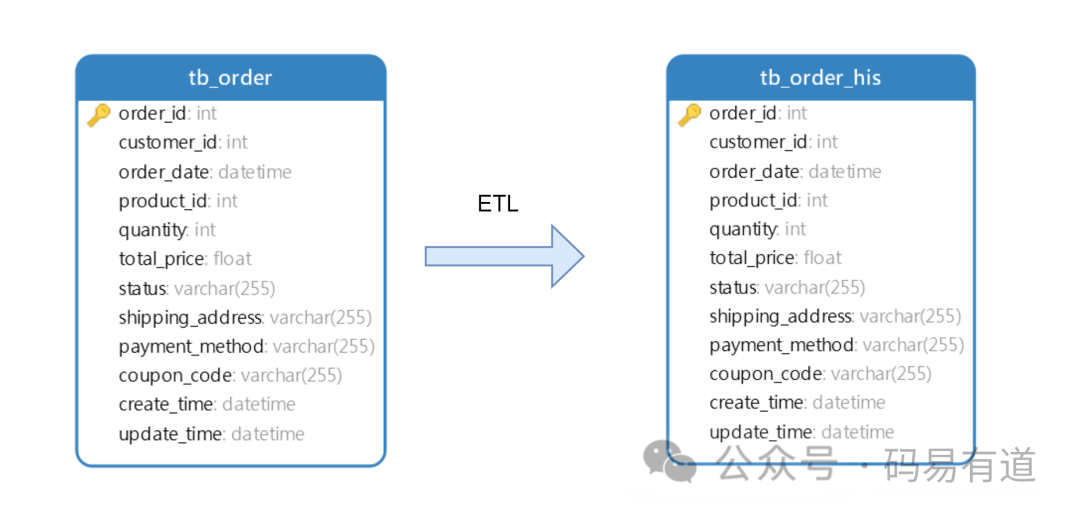
详细步骤可参考(文章出处):https://blog.csdn.net/be_racle/article/details/134223354
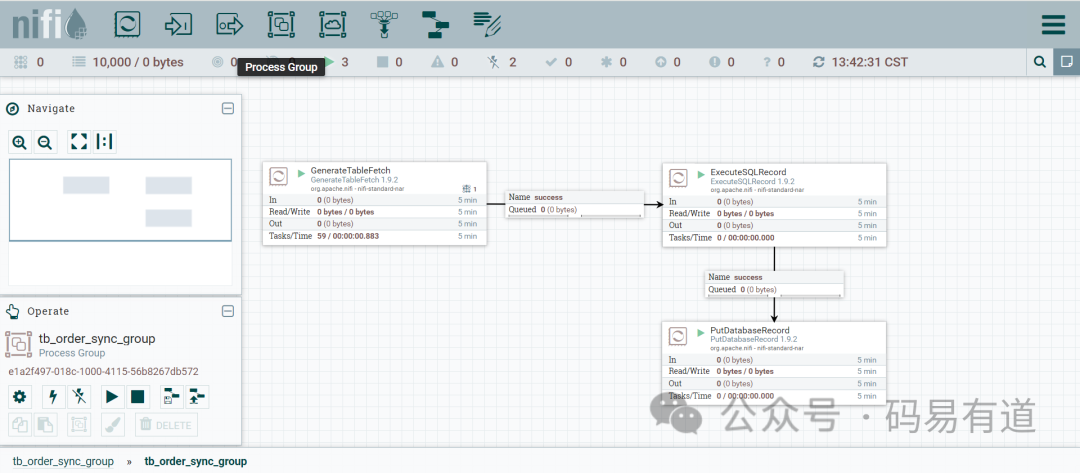
感兴趣的可以深究,这里只想说明:对大数据量处理,包括数据提取,数据加载,增量数据同步,可以借助这些工具,ETL工具提供了一些可视化的组件+配置具体的链接类型。可以省去很多人工的成本,也间接的保证了数据一致性的问题。是很好的数据处理工具。但是因为引入新的组件,在多数据源的情况下,不可避免的带来系统的复杂性。
方案三、触发器增量数据同步
如上,比如:例子中的触发器是在tb_order表中插入新数据时触发的,将新数据同步到tb_order_his表中(读者可以根据需要调整触发器的触发时机和逻辑)
现状:tb_order 共有3条记录

tb_order_his 0条记录

触发器逻辑脚本:
# 创建触发器
DELIMITER //
CREATE TRIGGER sync_order_to_history
AFTER INSERT ON tb_order
FOR EACH ROW
BEGIN
INSERT INTO tb_order_his (
order_id, customer_id, order_date, product_id, quantity,
total_price, status, shipping_address, payment_method,
coupon_code, create_time, update_time
)
VALUES (
NEW.order_id, NEW.customer_id, NEW.order_date, NEW.product_id, NEW.quantity,
NEW.total_price, NEW.status, NEW.shipping_address, NEW.payment_method,
NEW.coupon_code, NEW.create_time, NEW.update_time
);
END;
//
DELIMITER ;
这个触发器是在tb_order表发生插入操作之后触发的,会将新插入的数据复制到tb_order_his表中。请注意,我假设 tb_order_his 表的结构和 tb_order 表相同。
测试触发器的工作:
# 向tb_order插入数据
INSERT INTO tb_order VALUES (4, 4, '2024-01-15 12:00:00', 104, 4, 150.25, '待支付', '567 Elm St, County', 'Credit Card', 'DISCOUNT_15', '2024-01-15 12:00:00', '2024-01-15 12:00:00');
# 查询tb_order_his,确保数据同步成功
SELECT * FROM tb_order_his;
查看结果:同步成功:
tb_order

tb_order_his

触发器同步的优点:
实时性: 触发器可以实现实时数据同步,当触发事件发生时,同步操作会立即执行,确保目标表中的数据与源表保持同步。
简化操作: 触发器能够在数据库层面自动执行同步操作,无需在应用程序中编写额外的同步逻辑,简化了开发和维护工作。确保源表和目标表之间的数据一致性。
触发器同步的缺点:
性能影响: 触发器的执行会引入额外的性能开销,特别是在大规模数据操作时。频繁触发的触发器可能导致数据库性能下降。
复杂性: 当触发器逻辑复杂或有多个触发器时,可能难以追踪和调试触发器的行为,特别是在维护时。
并发控制: 在高并发环境中,触发器可能引发并发控制的问题,需要谨慎处理以确保数据一致性。
方案四、手工脚本同步(朴实无华)
这种就是常见的SQL脚本,常用于数据割接,错误数据修改,包括配置数据,业务字段,运维手工调整异常数据等。比较简单,只是为了文章结构完整说明一下。举个简单的例子吧:
# insert into tb_target select * from tb_source
INSERT INTO tb_order_his (
order_id, customer_id, order_date, product_id, quantity,
total_price, status, shipping_address, payment_method,
coupon_code, create_time, update_time
)
SELECT
order_id, customer_id, order_date, product_id, quantity,
total_price, status, shipping_address, payment_method,
coupon_code, create_time, update_time
FROM tb_order;
比较简单,没什么好总结的。
方案五、实时数据同步方案(使用消息队列)
这种方案主要是:将 MySQL 数据变更事件捕获并通过消息队列传递给下游数据源。比如:从Mysql同步数据到ClickHouse,一种常见的方法是使用Debezium作为MySQL CDC(Change Data Capture)工具,结合Kafka作为消息队列。大致的步骤:
- 配置 MySQL 数据库连接信息:
# MySQL 连接配置
database.hostname=mysql-host
database.port=3306
database.user=mysql-user
database.password=mysql-password
# Debezium 配置
connector.class=io.debezium.connector.mysql.MySqlConnector
tasks.max=1
database.server.id=1
database.server.name=my-app-connector
database.whitelist=mydatabase
- 启动 Debezium 连接器:
通过命令行或配置文件启动 Debezium 连接器,例如:
debezium-connector-mysql my-connector.properties
- 创建 Kafka-topic:
Debezium将变更事件发送到 Kafka 主题,确保 Kafka 主题已经创建:
kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic my-topic
- Java 伪代码示例 - 消费 Kafka 主题并将数据写入 ClickHouse:
import org.apache.kafka.clients.consumer.Consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class ClickHouseDataConsumer {
private static final String KAFKA_BOOTSTRAP_SERVERS = "localhost:9092";
private static final String KAFKA_TOPIC = "my-topic";
private static final String CLICKHOUSE_URL = "clickhouse-url";
private static final String CLICKHOUSE_USER = "clickhouse-user";
private static final String CLICKHOUSE_PASSWORD = "clickhouse-password";
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KAFKA_BOOTSTRAP_SERVERS);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "clickhouse-consumer-group");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
try (Consumer<String, String> consumer = new KafkaConsumer<>(properties)) {
consumer.subscribe(Collections.singletonList(KAFKA_TOPIC));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
records.forEach(record -> processKafkaMessage(record.value()));
}
} catch (Exception e) {
e.printStackTrace();
}
}
private static void processKafkaMessage(String message) {
// 解析 Kafka 消息,获取变更数据
// 将数据写入 ClickHouse
writeToClickHouse(message);
}
private static void writeToClickHouse(String message) {
// 实现将数据写入 ClickHouse 的逻辑
}
}
使用 Kafka 实时同步 MySQL 具有一些优势和缺点:
优势:
实时性高: Kafka 是一个高吞吐、低延迟的消息队列系统,能够提供近实时的数据同步,使得应用能够快速获取最新的数据变更。
消息持久化: Kafka 具有消息持久化的特性,能够保证即使消费者离线一段时间,仍然可以获取之前未处理的消息,确保数据不丢失。
缺点:
一致性保证: Kafka 保证了分区内的消息顺序性,但在整个集群范围内的消息顺序性较难保证。在某些场景下,可能需要额外的手段来保证全局的一致性。
对于小规模的应用,引入 Kafka 可能显得过于笨重,使用轻量级的解决方案可能更为合适。
总结
同步方案 | 描述 | 优势 | 局限性 |
|---|---|---|---|
数据库主从复制 | 利用数据库自身的主从复制特性,将主数据库的变更同步到一个或多个从数据库。 | 实现简单,可以提供相对实时的数据同步,适用于读多写少的场景。 | 主从之间需要稳定的网络连接,伴随主从延迟问题。适用于MySQL、PostgreSQL等数据库。 |
ETL工具数据迁移 | 使用专业的ETL工具,如Apache NiFi、Talend等,定期抽取源数据库中的数据,进行数据转换,然后加载到目标数据库中。 | 可以进行复杂的数据转换和清洗,适用于异构数据库之间的同步。 | 需要配置合适的调度策略,处理好增量同步和全量同步的问题。 |
基于数据库触发器的同步 | 在源数据库中设置触发器,当数据发生变更时触发相应的动作,例如将变更信息记录到一个同步表,目标数据库定期轮询同步表并处理变更。 | 可以实现较为实时的同步,适用于小规模数据。 | 需要小心设计触发器,避免对源数据库性能造成过大影响。 |
手工数据脚本 | 手动编写数据脚本,将数据从一个数据库插入到另一个数据库中。 | 简单直接,适用于小规模数据的同步。上线配置,数据割接等 | 异常情况处理,认为干扰因素。 |
实时数据同步方案(使用消息队列) | 将源数据库的变更操作发布到消息队列,消费者订阅消息并将变更操作同步到目标数据库。 | 实现实时同步,异步处理对系统性能影响较小。 | 需要考虑消息队列的可靠性和消费者的幂等性。 |
结尾
感谢阅读到最后。本文主要是一些实践中的总结和思考,还有很多值得选择的方案。不足之处,愿意和大家一起探讨并改进。希望本篇文章对你有帮助,也欢迎你加入我们,一起做长期且正确的事情!!!
阅读 1396

码易有道
关注
分享收藏1
3
关注后可发消息
复制搜一搜分享收藏划线
人划线