链接:https://zhuanlan.zhihu.com/p/87858287
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
联邦学习(Federated Learning, a.k.a. Federated Machine Learning)可以分为三类:横向联邦学习(Horizontal Federated Learning),纵向联邦学习(Vertical Federated Learning),联邦迁移学习(Federated Transfer Learning)[1, 2]。
有不少读者说,横向联邦学习和纵向联邦学习容易混淆,不太清楚为什么这么分类。我在这里再解释一下横向联邦学习和纵向联邦学习。
横向联邦学习
数据矩阵(也可以是表格,例如,Excel表格)的横向的一行表示一条训练样本,纵向的一列表示一个数据特征(或者标签)。通常用表格查看数据(例如,病例数据),用一行表示一条训练样本比较好,因为可能有很多条数据。
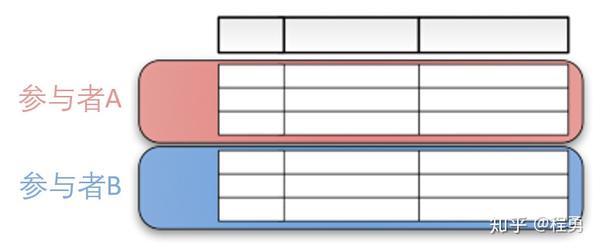
横向联邦学习,适用于参与者的数据特征重叠较多,而样本ID重叠较少的情况,例如,两家不同地区的银行的客户数据 [1, 2]。“横向”二字来源于数据的“横向划分(horizontal partitioning, a.k.a. sharding)”。如图1所示例,联合多个参与者的具有相同特征的多行样本进行联邦学习,即各个参与者的训练数据是横向划分的,称为横向联邦学习。图2给出了一个横向划分表格的示例。横向联邦使训练样本的总数量增加。
横向联邦学习也称为特征对齐的联邦学习(Feature-Aligned Federated Learning),即横向联邦学习的参与者的数据特征是对齐的,如图3所示例。“特征对齐的联邦学习”这个名字有点长,还是用“横向联邦学习”比较好。


纵向联邦学习
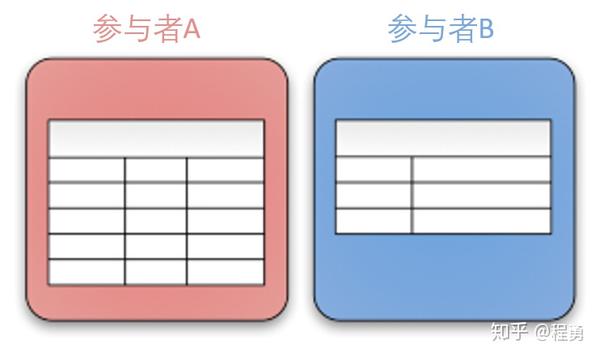
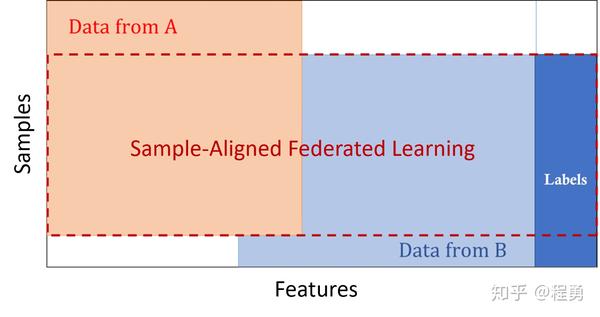
纵向联邦学习,适用于参与者训练样本ID重叠较多,而数据特征重叠较少的情况,例如,同一地区的银行和电商的共同的客户数据 [1, 2]。“纵向”二字来源于数据的“纵向划分(vertical partitioning)”。如图4所示例,联合多个参与者的共同样本的不同数据特征进行联邦学习,即各个参与者的训练数据是纵向划分的,称为纵向联邦学习。图5给出了一个纵向划分表格的示例。纵向联邦学习需要先做样本对齐,即找出参与者拥有的共同的样本,也就叫“数据库撞库(entity resolution, a.k.a. entity alignment)”。只有联合多个参与者的共同样本的不同特征进行纵向联邦学习,才有意义。纵向联邦使训练样本的特征维度增多。
纵向联邦学习也称为样本对齐的联邦学习(Sample-Aligned Federated Learning),即纵向联邦学习的参与者的训练样本是对齐的,如图6所示例。“样本对齐的联邦学习”这个名字有点长,还是用“纵向联邦学习”比较好。

小节
横向联邦学习的名称来源于训练数据的“横向划分”,也就是数据矩阵或者表格的按行(横向)划分。不同行的数据有相同的数据特征,即数据特征是对齐的。
纵向联邦学习的名称来源于训练数据的“纵向划分”,也就是数据矩阵或者表格的按列(纵向)划分。不同列的数据有相同的样本ID,即训练样本是对齐的。
参考:
https://www.zhihu.com/search?type=content&q=%E7%BA%B5%E5%90%91%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0%20%E6%A8%AA%E5%90%91%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0