PPI ETM
PPI
概念
PPI(Programmable Peripheral Interconnect),是将不同外设“连接”在一起,而不经过CPU的一种技术,可以有效降低CPU负载和芯片运行功耗
具体举例:
比如想要定时采样,那么你需要一个定时器外设以及一个ADC外设,正常的做法是设置中断,当定时器计数到某一个时刻,进入中断事件,然后在中断事件中使用ADC外设采样。而PPI通过配置通道,当定时器计数到某一时刻触发事件,而接收端的TEP端点会自动执行ADC采样,不需要CPU的调度,可以有效降低负载以及功耗,并且由于不进入中断,启动ADC的操作就不存在被其他高优先级中断打断的可能,系统实时性更好
具体原理与DMA类似,不过DMA是将外设数据存储到内存,而PPI是通过外设的事件变化而执行相关的任务,直接通过硬件实现,都不需要通过CPU
具体原理
PPI实现是通过PPI通道连接事件与任务实现的
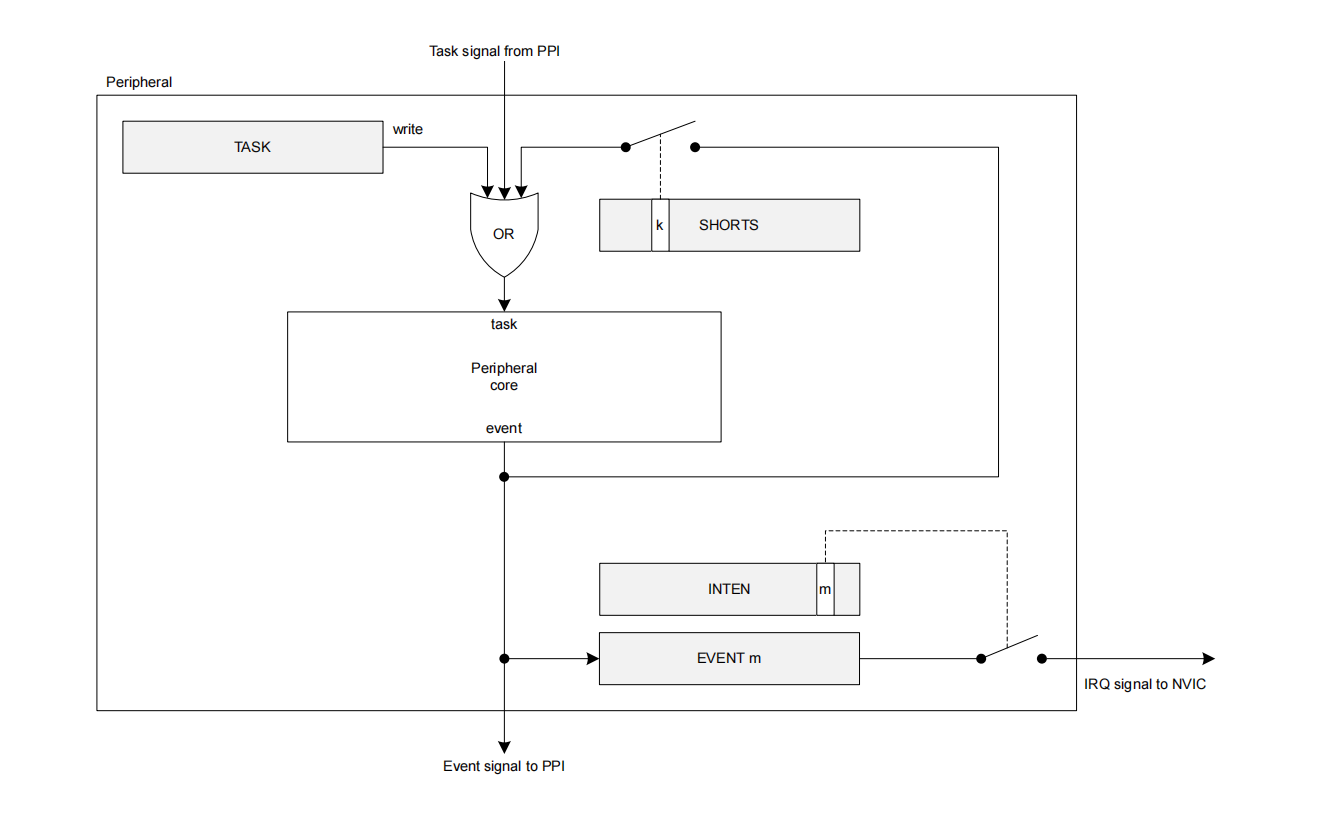
原理如下图所示:
每一个PPI通道包括三个端点,分别是一个事件端点(EEP),一个任务端点(TEP),以及一个fork任务端点,这样它可以通过某一个PPI通道把外设1的event跟外设2的task相连,这样一旦外设1的event置起(相关寄存器为1),将会自动触发外设2的task(将相关寄存器自动置1)
PPI通道情况
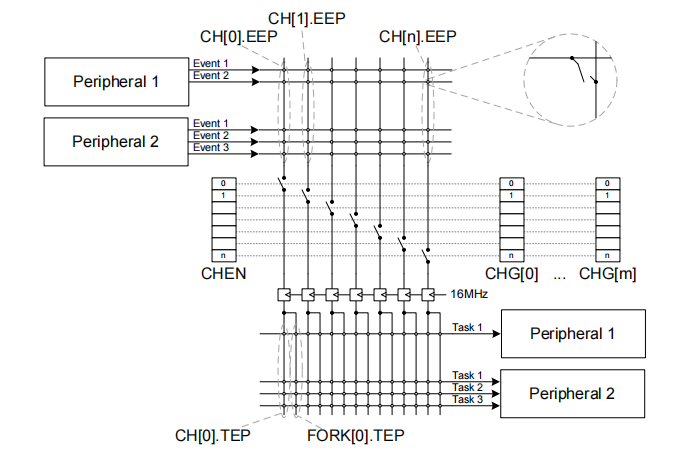
一共有32个通道,如下图

20个可编程通道,12个固定通道(固定通道的fork任务端点也可以编程),并且这些固定通道可以单独启用、禁用或添加到 PPI 通道组
固定PPI通道功能如下:
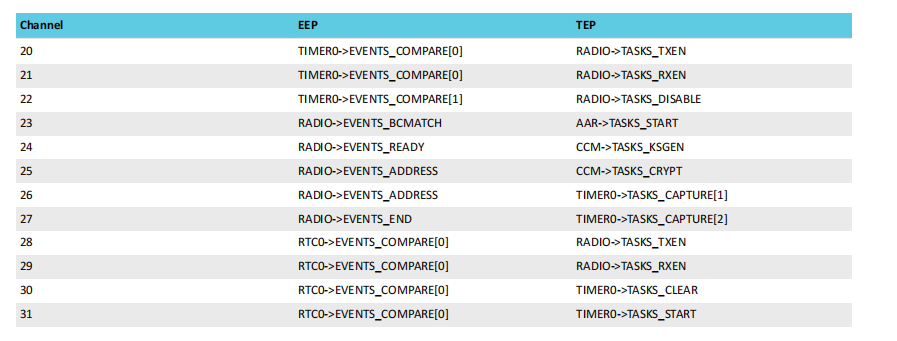
这些通道通过端点事件来触发固定的任务,简单来说,外设事件使用与事件关联的事件寄存器的地址连接到 EEP,外设任务使用与任务关联的任务寄存器的地址连接到 TEP,这样当外设事件发生时,另一个外设就可以自动执行相关任务。
在每个 PPI 通道上,信号与 16 MHz 时钟同步,这样可以避免时序违例
由于通道都是通过寄存器来进行配置,下面介绍寄存器的概念以及使用
寄存器使用
由于PPI通道有32个,所以PPI的控制寄存器有32bit,每一个bit控制对应的通道开启或者关闭,EEP 和 TEP为32bit,可以方便写入外设的时间和任务地址,PPI寄存器的基地址为0x4001F000,其它在此基础上偏移
寄存器的概况:
寄存器种类分为以下几种:
- 6个组寄存器,包括任务组寄存器和事件组寄存器
- CHEN
- CHENSET
- CHENCLR
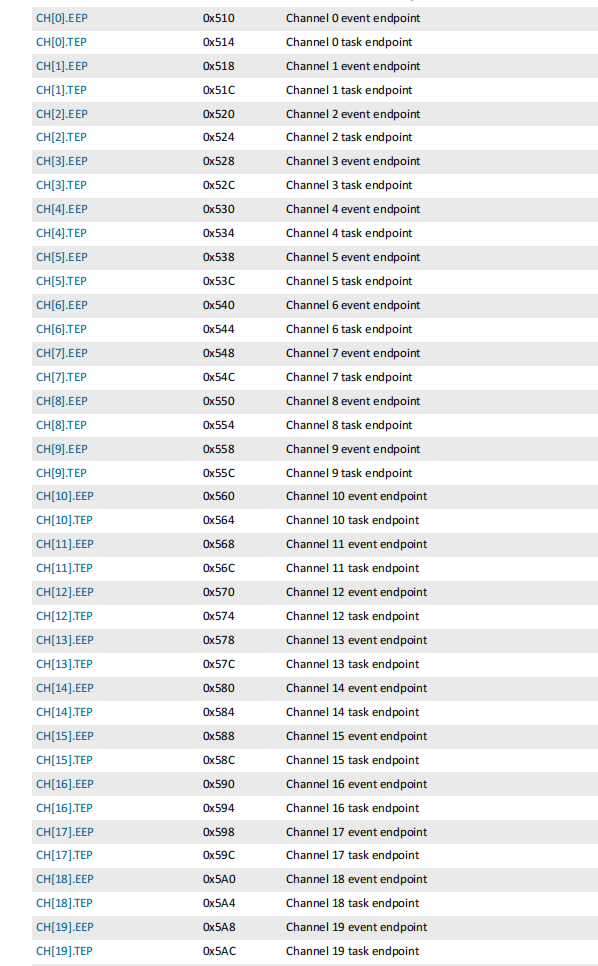
- 20个通道的EEP 和 TEP 32bit,可以写入相关的事件或者任务地址
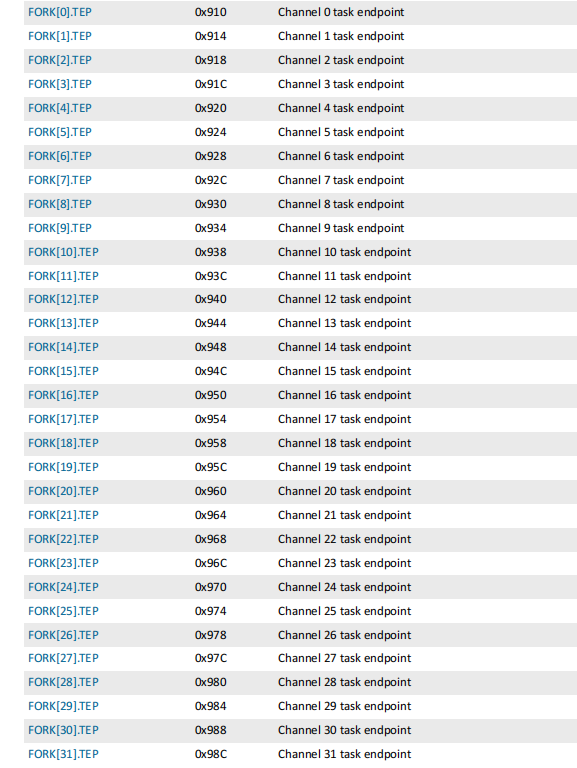
- 32个fork任务寄存器
六个组寄存器:
先绑定地址,也就是哪一个通道在通道组里,然后设置该通道开启还是关闭
CHG寄存器负责绑定相关通道的地址(对应bit置1即可加入该通道)


寄存器设置某一个组的PPI通道开启关闭
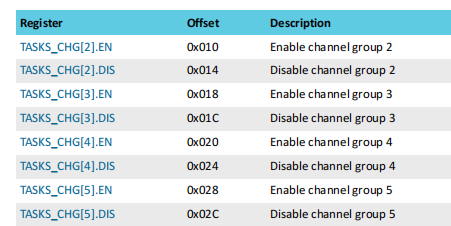
当通道组相交的时候,单个通道的EN使能比DIS禁用有更高的优先级
CHEN、CHENSET、CHENCLR寄存器
设置单个通道的开启或关闭

20个通道的EEP 和 TEP
事件与任务节点寄存器,记录事件和任务的端点地址
32个fork任务寄存器
fork任务寄存器绑定要执行任务的地址,可以扩展相关功能,就是相当于可以同时多触发32个事件
寄存器具体形式
以CHEN寄存器进行说明:

共有32bit,代表32个通道,对应的通道为1则开启这个通道,每一个寄存器的偏移都是4个字节,因为是32bit。
使用方法:
禁用或者开启PPI通道有两种方法:
- 使用 CHEN、CHENSET 和 CHENCLR 寄存器单独启用或禁用 PPI 通道。
- 通过组的启用和禁用任务启用或禁用 PPI 通道组中的 PPI 通道。
/*
CHEN寄存器(Channel Enable Register):
CHEN寄存器用于控制单个PPI通道的使能状态,当CHEN位为1时,表示对应的PPI通道处于使能状态
CHENSET寄存器(Channel Enable Set Register):
CHENSET寄存器用于设置(使能)多个PPI通道。该寄存器的每个位对应一个PPI通道,并且通过设置相应的位,可以将对应的PPI通道置为使能状态。这个通道不能写0
在写1的时候两者作用相同,但是CHENSET可以读,读取他的值来获取某一个通道是否被使能了
CHENCLR(Channel Enable Clear):
用于清除(禁用)多个PPI通道的使能状态,通过设置CHENCLR寄存器中的某个位,可以将对应的PPI通道禁用
通过GPIOTE和PPI共同使用来处理事件与任务
通过寄存器来实现:
单个通道的方法
步骤如下:
- 分配好GPIOTE 对应的输入事件和输出任务
- 分配好PPI通道,在PPI通道两端 EEP TEP赋值输入事件和输出任务的地址。
- 使能PPI通道。
static void gpiote_init(void)
{
nrf_gpio_cfg_input(BSP_BUTTON_0,NRF_GPIO_PIN_PULLUP);//设置管脚位上拉输入
NRF_GPIOTE->CONFIG[0] = (GPIOTE_CONFIG_POLARITY_HiToLo << GPIOTE_CONFIG_POLARITY_Pos)//绑定GPIOTE通道0
| (BSP_BUTTON_0<< GPIOTE_CONFIG_PSEL_Pos) // 配置输入事件状态
| (GPIOTE_CONFIG_MODE_Event << GPIOTE_CONFIG_MODE_Pos);//事件模式
NRF_GPIOTE->CONFIG[1] = (GPIOTE_CONFIG_POLARITY_Toggle << GPIOTE_CONFIG_POLARITY_Pos)//绑定GPIOTE通道1
| (BSP_LED_0 << GPIOTE_CONFIG_PSEL_Pos) // 配置任务输出状态
| (GPIOTE_CONFIG_MODE_Task << GPIOTE_CONFIG_MODE_Pos);//任务模式
}
void ppi_init(void)
{
// 配置PPI的端口,通道0一端接按键任务,另外一端接输出事件
NRF_PPI->CH[0].EEP = (uint32_t)(&NRF_GPIOTE->EVENTS_IN[0]);//事件
NRF_PPI->CH[0].TEP = (uint32_t)(&NRF_GPIOTE->TASKS_OUT[1]);//任务
// 使能PPI的通道0
NRF_PPI->CHEN = (PPI_CHEN_CH0_Enabled << PPI_CHEN_CH0_Pos);//使能第0通道
}
int main(void)
{
gpiote_init();
ppi_init();
while(1){
}
}
组通道的方法
...//gpiote_init
void ppi_init(void)
{
// 配置PPI通道0,一端接GPIOTE事件0,一端接GPIOTE任务1
NRF_PPI->CH[0].EEP = (uint32_t)(&NRF_GPIOTE->EVENTS_IN[0]);
NRF_PPI->CH[0].TEP = (uint32_t)(&NRF_GPIOTE->TASKS_OUT[1]);
// 配置PPI通道1,一端接GPIOTE事件2,一端接GPIOTE任务3
NRF_PPI->CH[1].EEP = (uint32_t)(&NRF_GPIOTE->EVENTS_IN[2]);
NRF_PPI->CH[1].TEP = (uint32_t)(&NRF_GPIOTE->TASKS_OUT[3]);
//把通道0和通道1 绑定到PPI group0之上
NRF_PPI->CHG[0]=0x03;
}
/*通过按钮来管理组的开启与关闭*/
int main(void)
{
gpiote_init();
ppi_init();
KEY_Init();
LED_Init();
LED3_Close();
LED4_Close();
while (true)
{
if( KEY3_Down()== 0){
LED4_Close();
NRF_PPI->TASKS_CHG[0].EN = 1;//使能PPI group0
LED3_Toggle();
}
if( KEY4_Down()== 0){
LED3_Close();
NRF_PPI->TASKS_CHG[0].DIS = 1;//关闭PPI group0
LED4_Toggle();
}
}
}
fork 寄存器的使用方法
...//gpiote_init
void ppi_init(void)
{
// 配置PPI一端接输入事件0,一端接输出任务1
NRF_PPI->CH[0].EEP = (uint32_t)(&NRF_GPIOTE->EVENTS_IN[0]);
NRF_PPI->CH[0].TEP = (uint32_t)(&NRF_GPIOTE->TASKS_OUT[1]);
//输出端接通道0的fork分支端,在CH[0] TASKS_OUT[1]的基础上加上TASKS_OUT[2]
NRF_PPI->FORK[0].TEP= (uint32_t)(&NRF_GPIOTE->TASKS_OUT[2]);
// 使能通道0
NRF_PPI->CHEN = (PPI_CHEN_CH0_Enabled << PPI_CHEN_CH0_Pos);
}
...
while (true){
}
总结:
使用步骤就是先将地址绑定在对应寄存器内,然后通过开启单个通道使能或者组通道使能来实现PPI功能
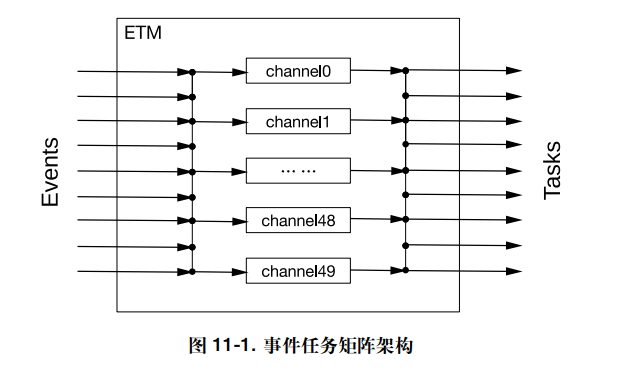
ETM
概念
事件任务矩阵 (ETM) 外设包含 50 个可配置通道。每个通道可以将任意指定外设的事件映射到任意指定外设的 任务,从而触发外设执行指定任务,无需 CPU 干预。
功能
每一个外设都有固定的事件,官方定义完了。
 U
U
每一个事件都通过特定的宏定义出来了,任意事件可以一个通道与任意一个任务相对应。
每一个通道的具体原理如下:
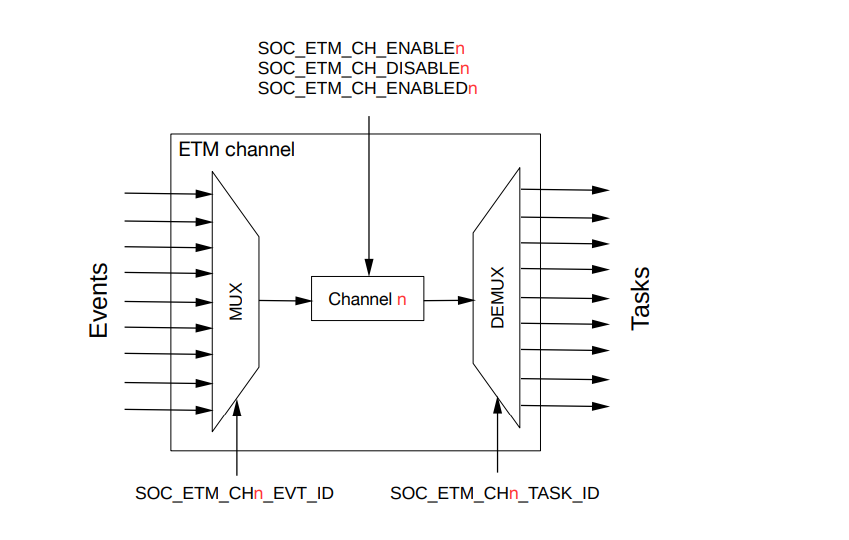
一个事件通过一个多路选择器连接到通道,通道由三个寄存器分别控制开启和关闭,最后通过多路复用器实现任务的运行。
PPI和ETM对比
相同点:
-
设计思路都是外设事件直接触发外设任务,不需要经过CPU
-
都是通过通道的方式连接事件与任务,每个通道都通过三个寄存器分别表示状态,控制开启,控制关闭,其中每一位代表一个通道
-
都可以多对一或者一对多
不同点:
- PPI是通过寄存器开关来控制事件和通道的连接,ETM是通过多路选择器控制
- PPI是通过绑定事件的地址来实现事件的触发,ETM是通过宏定义实现事件的触发,所以使用上PPI需要自己注册相关事件,ETM有官方写好的宏定义,调用更为方便
- ETM的通道较多为50个,功能更为强大,但是为了控制其余的18个通道,需要额外多出三个通道控制的寄存器
- PPI可以实现事件组控制,便于管理,而ETM不可以
- PPI连接了一个16M的时钟来保持时序同步,而ETM没有,所以ETM对两个连续事件之间的时间间隔有要求
问题:
-
FORK TEP是用来做什么的?
这个通道相当于TEP的扩展通道,相当于一个事件可以同时触发两个任务,其中一个是正常的TEP,而第二个任务就是fork TEP,这个任务也可以自己定义相关的逻辑,相当于让功能增强一倍 -
通道组 是否只是用来同时EN或DIS组内的通道?
我觉得是这样的,他有两个寄存器来管理组通道,其中一个就是设置通道组里是哪一个通道,第二个就是开启或者关闭通道组
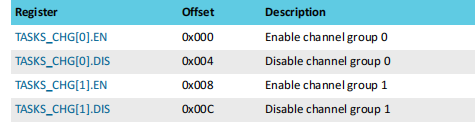
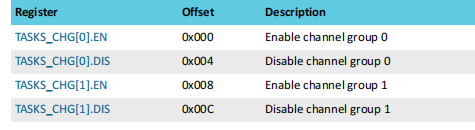
每一个通道组的控制有两组寄存器来实现,第一组寄存器用来绑定相关通道,如下图:

第二组寄存器用来实现组的开关
我觉得主要目的是方便了灵活配置,或者说如果组内的两个通道指甲需要数据传输,可以把它们放在一个通道组里面,这样就更加便于管理
思考:
-
CHEN寄存器可以直接读写 为何还需要CHENSET和CHENCLR 这两个寄存器 ?
- CHENSET和CHENCLR 可以读出CHEN寄存器的状态
- CHENSET和CHENCLR 可以在设置多位开关的时候更为方便,比如在开启一些通道的基础上,还想开启10和15通道,用CHENSET就可以直接实现,而不需要再重新设置一下CHEN。
-
PPI的event和task为什么都是独立的32位寄存器 ?
因为这个芯片每个外设都分配了一个固定的 0x1000 字节地址空间块,相当于 1024 x 32 位寄存器。
32位寄存器刚好可以写入外设事件和外设任务的地址,这样当事件或者任务出现的时候,可以直接执行相关任务,方便后面的PPI外设地址写入