上世纪30年代,受Fisher关于显著性和假设检验的影响,统计数据分析流程一般如下图所示。
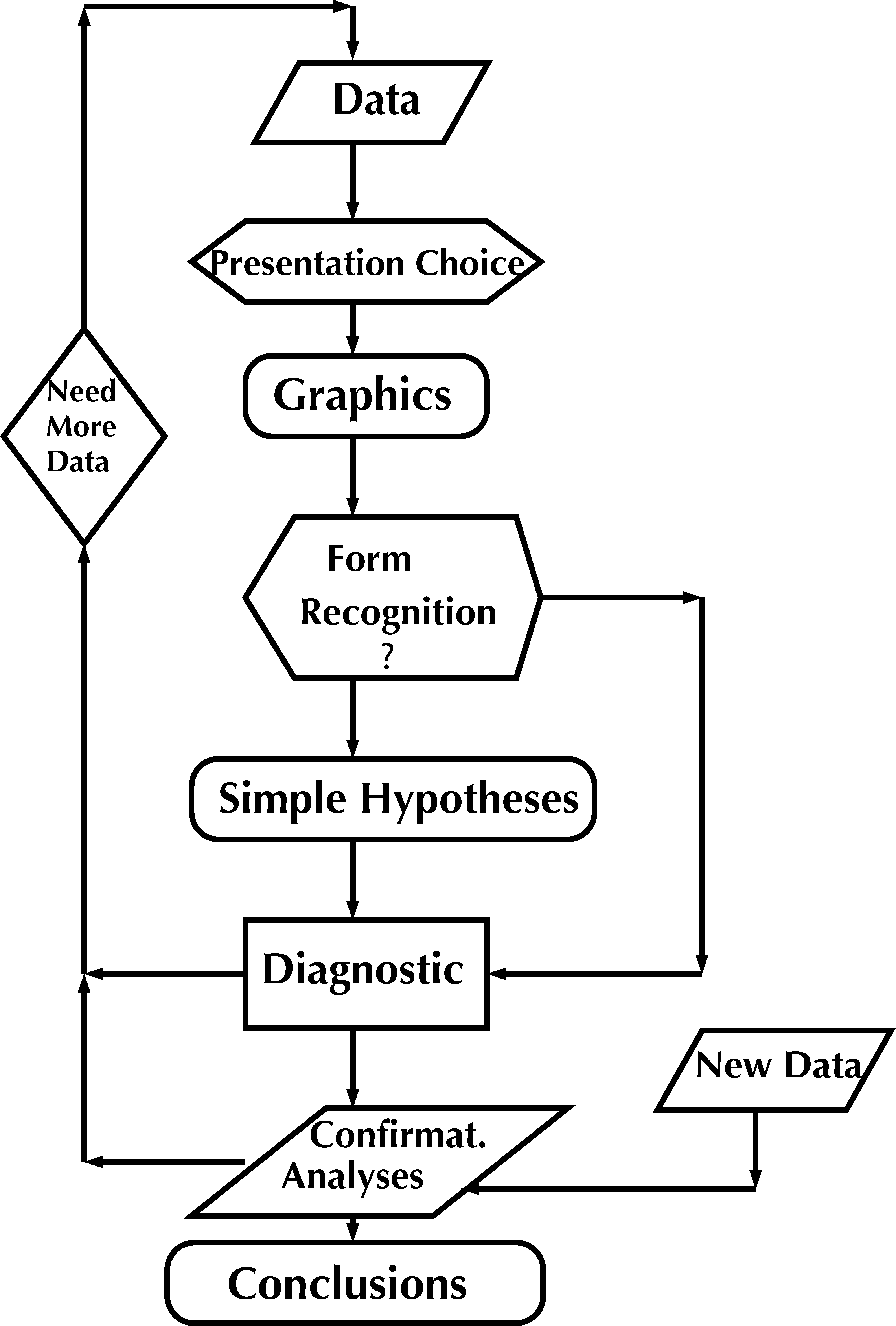
70年代,Tukey推荐使用探索性数据分析(EDA)进行统计分析。EDA 建立在数据可视化的基础上,然后辅以验证性数据分析 (CDA):假设驱动的推理方法,理想情况下应该是稳健的,而不是依赖于复杂的假设。
90 年代后期的生物学提出了大p小n问题:如考虑n=200个患者组织样本的基因表达数据集位于p=20000个基因上。如果我们想构建一个回归或分类模型,从20000个基因或特征中“预测”临床变量,例如疾病类型或结果,可能会遇到问题,因为模型参数的潜在数量可能比测量数量大几个数量级。这些问题源于参数的不可识别性或过度拟合。至少,普通模型(例如普通的多元线性模型)就是这种情况。统计学家意识到,他们可以通过使用正则化要求稀疏性来补救这种情况,即要求许多潜在参数要么为零,要么至少接近于零。稀疏性原理的推广是通过引用高维统计学中的思想(经验贝叶斯)来实现的,即不试图从头开始学习所有参数,而是利用它们相似甚至相同的事实。
2010 年代,计算机科学家发现并设计深度神经网络的方法,有时可以提供惊人的预测质量,而无需过多担心参数的可识别性或唯一性。
在剑桥大学出版的《Modern Statistics for Modern Biology》一书中,试图涵盖这些发展及其在当前生物学研究中的应用。包括现代生物学家必须处理的许多不同类型的数据,如RNA-Seq、流式细胞术、分类群丰度、成像数据和单细胞测序等。

该书共13章,每一章都包含某一具体目标,并包含完整的 R 代码示例,总结了要点和练习。第1章使用概率论和通过生成数据建立模型;第2章是自下而上的方法是一种统计思维;第3章中学习如何可视化数据;第4章为异质生物数据建立现实的模型;第5章介绍聚类;第6章概述基本假设检验工作流程;第7章介绍简单矩阵最基本的无监督分析方法——主成分分析;第8章讲线性模型和方差分析;第9章讨论结合多种数据类型的更多异质数据;第10章探讨网络和进化树;第11章探索从图像和空间统计中提取特征;第12章研究监督学习;第13章总结实验设计和数据分析的良好做法。
可以看到,经典统计学已经慢慢与计算机科学和现代生物学等融合,发展为各种交叉学科,如统计基因组学、生物信息学等。本书的好处在于直接提供代码,一行行运行理解,比光看书效率高很多。
source("https://www.huber.embl.de/msmb/install_packages.R")

数据下载:https://www.huber.embl.de/msmb/data.tar.gz