工程概论作业2——查重算法
GitHub仓库:点击跳转
目录
作业信息
| 这个作业属于哪个课程 | 工程概论 |
|---|---|
| 这个作业要求在哪里 | 个人项目(查重算法) |
| 这个作业的目标 | 1.设计查重算法 2.学习工程开发流程 3.自我综合能力检验 |
作业需求
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
- 原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
- 抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
- 从命令行参数给出:论文原文的文件的绝对路径。
- 从命令行参数给出:抄袭版论文的文件的绝对路径。
- 从命令行参数给出:输出的答案文件的绝对路径。
注意:答案文件中输出的答案为浮点型,精确到小数点后两位
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 25 | 33 |
| · Estimate | · 估计这个任务需要多少时间 | 305 | 362 |
| Development | 开发 | 20 | 25 |
| · Analysis | · 需求分析 (包括学习新技术) | 15 | 12 |
| · Design Spec | · 生成设计文档 | 15 | 20 |
| · Design Review | · 设计复审 | 15 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 20 | 30 |
| · Coding | · 具体编码 | 60 | 80 |
| · Code Review | · 代码复审 | 15 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 40 |
| Reporting | 报告 | 40 | 30 |
| · Test Repor | · 测试报告 | 20 | 15 |
| · Size Measurement | · 计算工作量 | 10 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 50 |
| · 合计 | 325 | 395 |
开发环境
语言: Java 16
IDE : IDEA 2022
系统: Windows 11 家庭中文版 22H2
算法设计
算法思路
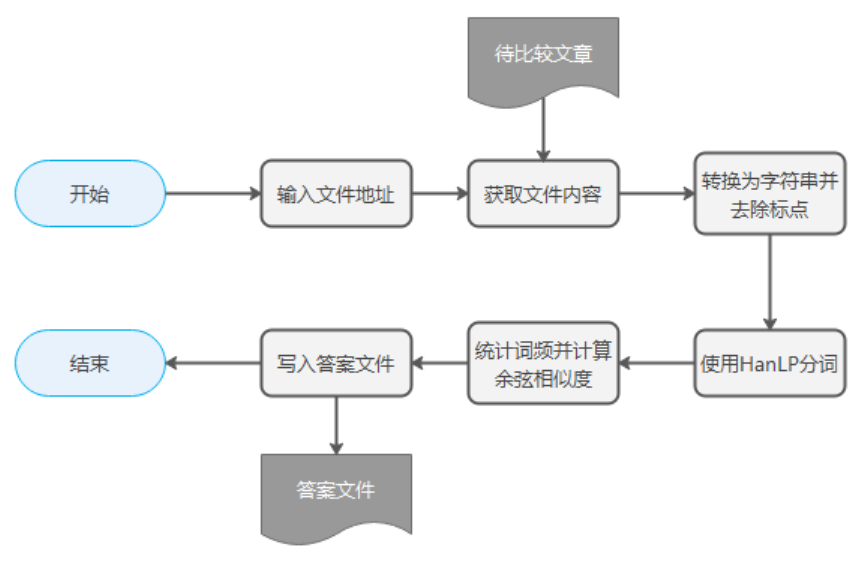
- 读入两篇文章并转化为字符串
- 使用正则表达式匹配并去除文章标点符号
- 使用中文分词库HanLP进行文本分词
- 使用余弦相似度算法统计词频并计算出相似度
- 将结果写入目标文件
函数列表
| 函数 | 作用 |
|---|---|
| readFile | 读取文件内容并去除标点后返回字符串 |
| calculateSimilarity | 计算余弦相似度 |
| getWordFrequency | 统计词频 |
| calculateDotProduct | 计算向量的内积 |
| calculateMagnitude | 计算向量的模 |
| writeResult | 将相似度结果写入文件 |
程序流程
性能分析
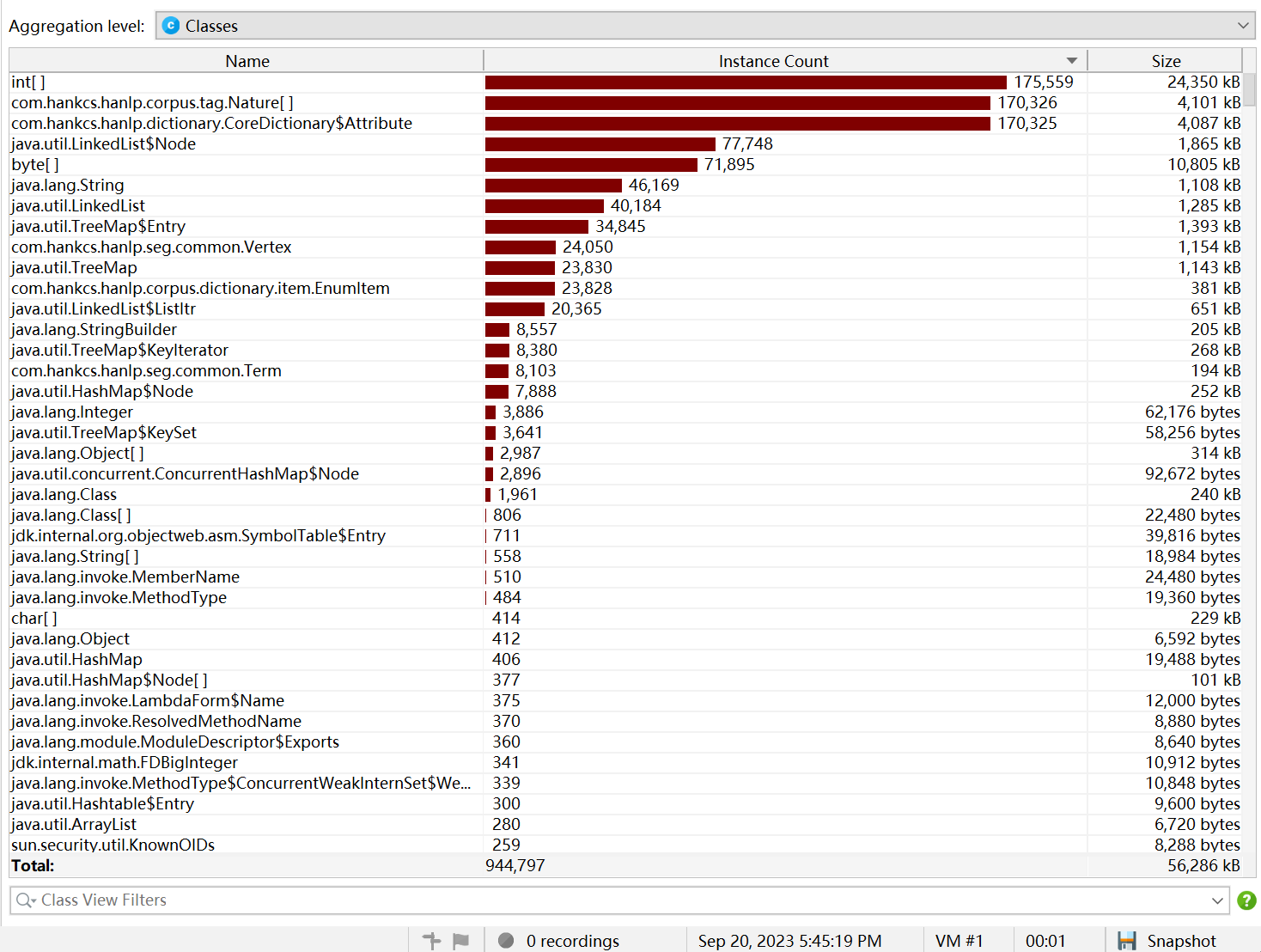
可以看到,程序的大部分资源用于分词以及向量计算时创建和调用数组上,以及使用HanLP进行中文文章分词。由于是对两篇文章进行分词和向量计算,故可以利用多线程运算提高效率。
单元测试
测试样例
- 原文:今天是星期天,天气晴,今天晚上我要去看电影。
- 抄袭版:今天是周天,天气晴朗,我晚上要去看电影。
执行样例
java -jar main.jar C:\\Users\\23989\\Desktop\\TEST\\test01_a.txt C:\\Users\\23989\\Desktop\\TEST\\test01_b.txt C:\\Users\\23989\\Desktop\\TEST\\answer.txt
分词与统计词频
Map<String, Integer> wordFrequency = new HashMap<>();
// 使用HanLP进行中文分词
List<Term> termList = HanLP.segment(article);
// 统计词频
for (Term term : termList) {
String word = term.word;
int frequency = wordFrequency.getOrDefault(word, 0);
wordFrequency.put(word, frequency + 1);
}
// 调试代码
System.out.println(termList);
System.out.println(wordFrequency);
执行结果
[今天/t, 是/v, 星期天/t, 天气/n, 晴/v, 今天/t, 晚上/t, 我/r, 要/v, 去/v, 看/v, 电影/n]
{天气=1, 我=1, 要=1, 电影=1, 晴=1, 星期天=1, 今天=2, 去=1, 看=1, 晚上=1, 是=1}
计算向量内积
// 计算向量的内积
double dotProduct = calculateDotProduct(wordFrequency1, wordFrequency2);
System.out.println("向量内积: "+dotProduct);
执行结果
向量内积: 10.0
计算向量的模
// 计算向量的模
double magnitude1 = calculateMagnitude(wordFrequency1);
double magnitude2 = calculateMagnitude(wordFrequency2);
System.out.println("向量模: "+"m1= "+magnitude1+"\tm2= "+magnitude2);
执行结果
向量模: m1= 3.7416573867739413 m2= 3.3166247903554
计算相似度并写入文件
// 计算余弦相似度
double similarity = dotProduct / (magnitude1 * magnitude2);
return similarity * 100; // 转换为百分比形式
// 将结果写入文件
writeResult(answerPath, similarity);
System.out.printf("Similarity: %.2f%%\n", similarity);
System.out.println("结果已写入路径: "+answerPath);
执行结果
Similarity: 80.58%
结果已写入路径: C:\Users\23989\Desktop\TEST\answer.txt
终端总执行结果
PS D:\JAVA\IDEA\WorkPlace\DuplicateChecking\out\artifacts\main_jar> java -jar main.jar C:\\Users\\23989\\Desktop\\TEST\\test01_a.txt C:\\Users\\23989\\Desktop\\TEST\\test01_b.txt C:\\Users\\23989\\Desktop\\TEST\\answer.txt
向量内积: 13.0
向量模: m1= 5.0990195135927845 m2= 5.0
Similarity: 50.99%
结果已写入路径: C:\\Users\\23989\\Desktop\\TEST\\answer.txt
程序总用时: 203.4899ms
异常处理
输入地址格式有误
使用特殊判断检验参数数目
if(args.length!=3){
System.out.println("请输入正确地址格式: [原文文件] [抄袭版论文的文件] [答案文件]");
System.out.println("请确保地址为绝对地址且不含空格");
}else{
···
}
执行结果
PS D:\JAVA\IDEA\WorkPlace\DuplicateChecking\out\artifacts\main_jar> java -jar main.jar
请输入正确地址格式: [原文文件] [抄袭版论文的文件] [答案文件]
请确保地址为绝对地址且不含空格
程序总用时: 0.2484ms
文件访问异常
try {
···
} catch (IOException e) {
System.out.println("文件读取或写入失败!(请检查路径后重试)");
e.printStackTrace();
}
执行结果
PS D:\JAVA\IDEA\WorkPlace\DuplicateChecking\out\artifacts\main_jar> java -jar main.jar 1 1 1
文件读取或写入失败!(请检查路径后重试)
程序总用时: 0.6939ms
参考文献
java去除字符串标点
使用余弦相似度算法计算文本相似度
HanLP: Han Language Processing
IDEA集成JProfiler11可视化工具(安装、集成、测试、简单教程)
Java多线程超详解
【教程】IDEA java项目如何导出为Jar包(含依赖)