
脱离网页化python 没有可视化
#%matplotlib inline
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0~1之间
# trans = transforms.ToTensor()
# mnist_train = torchvision.datasets.FashionMNIST(
# root="./data", train=True, transform=trans, download=True)
# mnist_test = torchvision.datasets.FashionMNIST(
# root="./data", train=False, transform=trans, download=True)
# print(len(mnist_train), len(mnist_test))
# def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save
# """绘制图像列表"""
# figsize = (num_cols * scale, num_rows * scale)
# _, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
# axes = axes.flatten()
# for i, (ax, img) in enumerate(zip(axes, imgs)):
# if torch.is_tensor(img):
# # 图片张量
# ax.imshow(img.numpy())
# else:
# # PIL图片
# ax.imshow(img)
# ax.axes.get_xaxis().set_visible(False)
# ax.axes.get_yaxis().set_visible(False)
# if titles:
# ax.set_title(titles[i])
# return axes
# X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
# show_images(X.reshape(18, 28, 28), 2, 9, titles=(y))
import sys
#获取线程输目
def get_dataloader_workers(): #@save
"""在非Windows的平台上,使用4个进程来读取数据"""
return 0 if sys.platform.startswith('win') else 4
#下载数据
def load_data_fashion_mnist(batch_size, resize=None): #@save
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="./data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="./data", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
# train_iter, test_iter = load_data_fashion_mnist(32, resize=64)
# for X, y in train_iter:
# print(X.shape, X.dtype, y.shape, y.dtype)
# break
# 精度评估0 保存每个训练样本的结果
class Accumulator: #@save
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
# 精度评估1 具体计算函数
def accuracy(y_hat, y): #@save
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
# 精度评估2 总评估
def evaluate_accuracy(net, data_iter): #@save
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
# 单次训练函数
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
i=0
for X, y in train_iter:
if i%30==0:print("当前训练样本",i)
i=i+1
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
#总训练
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
#animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
#legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
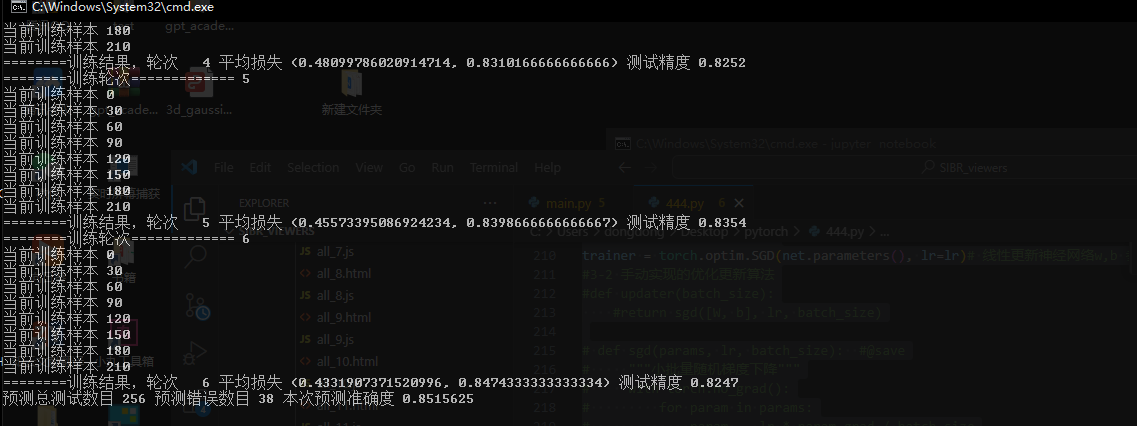
print("========训练轮次=============",epoch+1)
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
print("========训练结果,轮次 ",epoch+1,"平均损失",train_metrics,"测试精度",test_acc)
#animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
#在表达式条件为 false 的时候触发异常。
# assert train_loss < 0.5, train_loss
# assert train_acc <= 1 and train_acc > 0.7, train_acc
# assert test_acc <= 1 and test_acc > 0.7, test_acc
#####################################
import torch
from torch import nn
from d2l import torch as d2l
# 1 系统API模型
# 1-1 线性求解器 Linear y=w*x+b
# 1-2 网络层数 2层 784*256 256*10
# 1-3 层与层之间的激活函数 ReLU()
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
'''
手动初始化参数
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
'''
# 手动实现的单层模型
# def net(X):
# return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
# 手动实现的多层模型
# def net(X):
# X = X.reshape((-1, num_inputs))
# H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
# return (H@W2 + b2)
# 手动ReLU激活函数
# def relu(X):
# a = torch.zeros_like(X)
# return torch.max(X, a)
# 0 初始化网络参数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01) # 均值0 方差1
# 0 初始化网络参数
net.apply(init_weights);
# 2 损失函数
batch_size, lr, num_epochs = 256, 0.1, 6 # 每次参与训练的总样本数目 更新步长 训练总批次
#2-1系统api损失函数
loss = nn.CrossEntropyLoss(reduction='none')# 损失函数 softmax和交叉熵损失 计算
#2-2手动定义的损失函数--交叉熵
# def cross_entropy(y_hat, y):
# return - torch.log(y_hat[range(len(y_hat)), y])
#2-2手动定义的损失函数--均方损失
# def squared_loss(y_hat, y): #@save
# """均方损失"""
# return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
#3跟新函数
#3-1 系统自带的优化更新算法
trainer = torch.optim.SGD(net.parameters(), lr=lr)# 线性更新神经网络w,b 参数 w= w - lr*w.grad b = b - lr*b.grad(梯度)
#3-2 手动实现的优化更新算法
#def updater(batch_size):
#return sgd([W, b], lr, batch_size)
# def sgd(params, lr, batch_size): #@save
# """小批量随机梯度下降"""
# with torch.no_grad():
# for param in params:
# param -= lr * param.grad / batch_size
# param.grad.zero_()
# 4训练
# 4-1 加载数据
train_iter, test_iter = load_data_fashion_mnist(batch_size)
# 4-2 训练过程
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
# 5预测结果
def predict_ch3(net, test_iter, n=6): #@save
"""预测标签(定义见第3章)"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
error_num=0
allTest_num=len(trues)
for i in range(0,len(trues)):
if trues[i]!=preds[i]:
print("真实标签",trues[i],"预测标签",preds[i])
error_num=error_num+1
result_=1-error_num/allTest_num
print("预测总测试数目",allTest_num,"预测错误数目",error_num,"本次预测准确度",result_)
# 训练1次 256个样本/次 0.77
# 训练3次 256个样本/次 0.82
# 训练6次 256个样本/次 0.85
#titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
#d2l.show_images(
#X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter)