MEMORY REPLAY WITH DATA COMPRESSION FOR CONTINUAL LEARNING--阅读笔记
摘要:
在这项工作中,我们提出了使用数据压缩(MRDC)的内存重放,以降低旧的训练样本的存储成本,从而增加它们可以存储在内存缓冲区中的数量。观察到压缩数据的质量和数量之间的权衡对于内存重放的有效性是非常重要的,我们提出了一种基于确定性点过程(DPPs)的新方法,以有效地为当前到达的训练样本确定合适的压缩质量。通过这种方式,使用具有适当选择质量的朴素数据压缩算法,可以通过在有限的存储空间中保存更多的压缩数据,从而在很大程度上提高最近的强基线。
1 INTRODUCTION
我们展示了我们的建议在现实应用中的优势,如自动驾驶的目标检测的持续学习,其中的增量数据是非常大规模的。
我们的贡献包括:
(1)我们提出了带数据压缩的内存重放,这既是持续学习的重要基线,也是持续学习的重要方向;
(2)我们通过经验验证了压缩数据的质量和数量之间的权衡是非常重要的,并提供了一种新的方法来有效地确定它;
(3)大量的实验表明,使用适当选择质量的朴素数据压缩算法可以通过在有限的存储空间中保存更多的压缩数据,在很大程度上提高内存重放。
2 RELATED WORK
持续学习:略
数据压缩:
旨在提高文件的存储效率,包括无损压缩和有损压缩。无损压缩需要从压缩数据中完美地重建原始数据,这限制了其压缩率。相比之下,有损压缩可以通过降低原始数据来实现更高的压缩率,因此在实际应用中得到了广泛的应用。具有代表性的手工制作方法包括JPEG(或JPG),这是最常用的有损压缩算法、WebP和JPEG2000。另一方面,神经压缩方法通常依赖于通过rnn2015;2017)、自动编码器和GANs来优化香农的速率失真权衡。
3 CONTINUAL LEARNING PRELIMINARIES
4 METHOD
4.1 MEMORY REPLAY WITH DATA COMPRESSION
本文为内存重放提出了一个重要的基线,即使用数据压缩来增加可以存储在内存缓冲区中的旧训练样本的数量以便于更有效地恢复旧数据的分布。数据压缩通常被定义为一个函数 \(F_c^q(\cdot)\) ,该函数用于把原始数据 \(x_{t,i}\) 压缩成 \(x_{t,i,q}=F_c^q(x_{t,i})\) , \(q\) 用于控制压缩质量。由于每个\(x_{t,i,q}\) 比\(x_{t,i}\) 拥有更小的存储成本,因此内存缓冲区可以维护更多的旧训练样本以供回放。\(N^{mb}_{q,t} \geq N^{mb}_t\) 。
与监督学习的学习理论类似,本文认为持续学习也将受益于重放更多的压缩数据,假设它们近似地遵循原始数据的分布。但是,如果压缩率过高,则很可能违反该假设。直观地说,这就导致了质量和数量之间的权衡:如果存储空间有限,降低数据压缩的质量\(q\)将增加可以存储在内存缓冲区中的压缩数据的数量\(N_q^{mb}\),反之亦然。
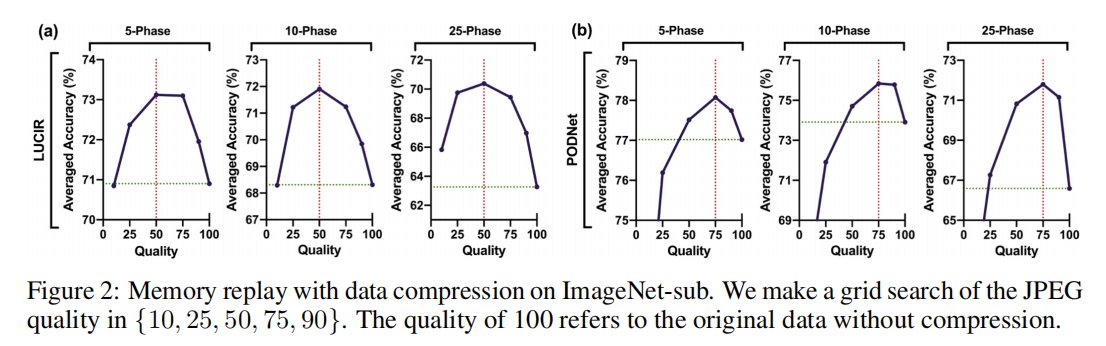
在这里,我们通过使用JPEG压缩图像来评估所提出的想法,这是一种简单但常用的有损压缩算法。JPEG可以保存质量在[1,100]范围内的图像,其中降低质量会导致更小的文件大小。使用相当于每个类20张原始图像的内存缓冲区,我们使用具有代表性的内存重放方法对JPEG质量进行网格搜索,如LUCIR和PODNet。如图2所示,具有适当质量的压缩数据的内存重放性能大大优于原始数据。但是,无论质量是太大还是太小,都会影响性能。特别是,实现最佳性能的质量随着内存重放方法的不同而变化,但对于增量阶段的不同分割数量是一致的.
4.2 QUALITY-QUANTITY TRADE-OFF
由于质量\(q\)和数量\(N_q^{mb}\)之间的权衡对于内存重放来说是非常重要的,因此需要仔细确定它。在从训练数据集D中学习每个任务后,让我们考虑几个压缩子集\(D_q^{mb}=\{(x_{q,i},y_i)\}_{i=1}^{N_q^{m b}}\) ,其中\(q\)来自一组候选数据中\(Q=\{q_1,q_2,q_3,...\}\) 。每个\(D_q^{mb}\)都是通过从\(D\)中选择一个子集\(D_q^{mb∗}= \{(x_{q,i},y_i)\}_{i=1}^{N_q^{m b}}\)来构建的, 选择时遵循特征平均值或其他原则。大小\(N_q^{mb}\)被确定为最大的数量,这样\(D_q^{mb∗}\)的压缩版本到一个质量的\(q\)可以存储在内存缓冲区中。因此,较小的\(q\)可以节省较大的\(N_q^{mb}\),反之亦然。
目标是选择一个可以最好地表示\(D\)的压缩子集,即为内存重放确定一个合适的\(q\)。
为了理解数据压缩的影响,数据压缩依赖于压缩函数\(F_q^c(·)\)和连续学习的嵌入函数\(F_θ^e(·)\),我们重点分析了压缩数据\(f_{q,i}=F_\theta^e(F_q^c(x_i))\)的特征。我们首先计算每个压缩子集\(D_q^{mb}\)特征矩阵\(M_{q}^{c}=[\bar{f}_{q,1},\bar{f}_{q,2},...,\bar{f}_{q,N_{q}^{m b}}]\) ,其中每一列的\(\bar{f}_{q,i}\) 通过\({f}_{q,i}\) 在L2范数下\({||f_{q,i}||_2=1}\)标准化得到的。类似的,我们得到每个原始子集\(D_q^{mb*}\)的特征矩阵\(M_q^*=[\bar{f_1},\bar{f_2},...,\bar{f}_{N_q^{mb}}]\) ,然后,我们可以从两个方面来分析质量-数量的权衡:
在经验方面:我们使用t-SNE来可视化原始子集(光点)的特征,其中包括不同数量的原始数据,以及它的压缩子集(黑点),这是通过压缩原始子集以适应内存缓冲区而获得的。

随着数量的增加和质量的降低,压缩子集的面积最初与原始子集相似,并同步扩展。然而,由于大量低质量的压缩数据出现分布外,压缩子集的面积比原来的子集大得多,性能也严重下降
在理论方面:对于给定的数据集,我们的目标是通过选择一个合适的压缩质量\(q\)找到压缩数据集,这个压缩数据集可以可以最好的表示数据集\(D\).
为了这个目标,本文引进了\(\mathcal{P}_q(D_q^{mb}|{D})\) 去描绘在给定输入\(D\)下选择\(D_q^{mb}\) 的条件似然。学习的目标是根据训练任务选择合适的\(q\),以便对看不见的输入做出准确的预测。虽然有各种各样的目标函数可以用来学习,但这里我们关注的是广泛使用的极大似然估计(MLE),其中的目标是选择\(q\)来最大化观测数据的条件似然:
这里,我们应用Determinantal Point Processes (DPPs)来表示条件似然,由于DPPs不仅是优雅的概率抽样模型,它可以通过行列式来表征每个可能的子集的概率,而且还可以通过子集中所有元素所跨越的体积来提供概率的几何解释。特别地,条件\(DPP\)是一个条件概率模型,它为每个可能的子集\(D_q^{mb}\)分配一个概率\(\mathcal{P}_q(D_q^{mb}|D)\) . 由于网络参数\(θ\)在压缩过程中是固定的,而特征矩阵\(M_q^c=F_\theta^e({D}_q^{mb})\),我们将\(\mathcal{P}_q(D_q^{m b}|D)\)等价地改写为\(\mathcal{P}_q(M_q^c|D)\) 。在形式上,这样的DPP将概率\(\mathcal{P}_q(D_q^{mb}|D)\)表示为:
在本工作中,我们采用了最广泛使用的点积核函数,其中\(L_{M_q^c}=M_q^{c\top}M_q^c\) 和\(L_{M}=M^{\top}M\)
然而,由于在等式(2)中计算分母的复杂性非常高,很难对\(\mathcal{P}_q(M_q^c|D)\)进行优化。同样的,引进了\(\mathcal{P}_q(D_q^{mb*}|{D})\) 去描绘在给定输入\(D\)下选择\(D_q^{mb*}\) 的条件似然。我们提出了一个宽松的等式优化方案,(1)我们最大化\(\mathcal{P}_q(D_q^{mb*}|{D})\) 因为\(\mathcal{P}_q(M_q^c|D)\leq\mathcal{P}_q(M_q^*|D)\) 在有损压缩下总是满足的。(2)限制约束使得\(\mathcal{P}_q(M_q^c|D)\) 和\(\mathcal{P}_q(M_q^*|D)\) 一致。
这个宽松安排的求解如下:
首先计算\(\mathcal{P}_q(M_q^*|D)\)
其中,条件\(DPP\)核矩阵\(L(D;θ)\)只依赖于\(D\)和\(θ\)。在我们的任务中,\(\mathcal{P}_{q}(M_{q}^{*}|D)\)随\(N_q^{mb}\)单调增加,因此,优化\(L_1\)被同等地转换为\(\text{max}_q N_q^{m b}\),显著降低了复杂性.
第二,为了约束\(\mathcal{P}_q(M_q^c|D)\) 和\(\mathcal{P}_q(M_q^*|D)\) 一致 ,我们提出最小化
为了避免计算\(Z_q\),我们可以将优化的\(L_2\)转换为最小化\(|R_q−1|\),因为它们都意味着最大化\(q\)
将\(L_1\)和\(L_2\)放在一起,我们的方法最终被重新表述为
\(g(\cdot):\mathbb{R}\to\mathbb{N}\) 表示输出最大数(即\(N_q^{mb}\))的函数,这样质量\(q\)的压缩版本\(D_q^{mb∗}\)的可以存储在内存缓冲区中。
因为等式中的函数\(g(·)\)是高度不光滑的,基于梯度的方法不适用。实际上,我们通过在有限大小的集合Q中选择最佳候选值来解决它。一般来说,Q中的候选值可以从Q的范围中被等距离地选择,例如JPEG的[1,100]。更多的候选值可以更准确地确定一个合适的q,但复杂性会呈线性增长。在我们的实验中,我们发现选择5个候选值是一个很好的选择。
4.3 VALIDATE OUR METHOD WITH GRID SEARCH RESULTS
本质上,在4.1中描述的网格搜索。4.1可以看作是确定压缩质量的一种简单的方法,这类似于选择其他超参数进行持续学习。该策略是使用不同的质量学习一个任务序列或子序列,并选择最好的一个,这将导致大量的额外计算,如果旧的数据不能重新访问,或者未来的数据不能立即访问,就不那么适用了。相比之下,我们的方法在4.2只需要计算每个压缩子集\(D_q^{mb}\)和原始子集\(D_q^{mb∗}\)的特征体积,不进行重复训练。

现在我们用网格搜索结果验证我们的方法确定的质量,其中LUCIR和PODNet在ImageNet-sub上的JPEG质量为50和75时取得了最好的性能。
我们在图5中显示了每个增量相的Rq和图5中5-phase以及10-phase和25-phase的所有增量相的平均\(R_q\)。基于等式中的原理(5)
$\epsilon=0.5 \(可以清楚地看到,50和75分别是LUCIR和PODNet所选择的质量,因为它们是满足\)|R_q-1|<\epsilon\(的最小质量因此,我们的方法所确定的质量与网格搜索结果一致,但计算成本节省了100多倍。有趣的是,对于每个质量q,\)|R_q-1|<\epsilon$.在每个增量阶段和所有增量阶段的平均值中是否普遍一致。

6 CONCLUSION
在这项工作中,我们提出,使用适当选择压缩质量的数据压缩,可以通过在有限的存储空间中保存更多的压缩数据,从而大大提高内存重放的效率。为了有效地确定压缩质量,我们提供了一种基于确定点过程(DPPs)的新方法来避免重复训练,并在类增量学习和半监督连续学习中验证了我们的方法。我们的工作不仅提供了一个重要的但尚未被充分探索的基线,而且还为持续学习开辟了一个有前途的新途径。进一步的工作可以为增量数据开发自适应压缩算法来提高压缩率,或者提出新的正则化方法来约束数据压缩引起的分布变化。同时,基于DPPs的理论分析可以作为在内存重放中集成可优化变量的通用框架,比如选择原型的策略。此外,我们的工作还建议如何在有限的存储空间中保存一批训练数据,以最好地描述其分布,这将推动其在数据压缩和数据选择领域的更广泛的应用。