一、背景与挖掘目标
二、分析方法与过程
网站智能推荐的主要步骤如下:
- 从系统中获取用户访问网站的原始记录。
- 分析用户访问内容,用户流失及用户分类等。
- 对数据进行预处理,包含数据去重,数据变换,数据分类等过程。
- 以用户访问html后缀的网页为关键条件,对数据进行处理。
- 对比多种推荐算法的效果,选择效果较好的模型。
- 通过模型预测,获得推荐结果。
采用上述的分析方法与思路,结合原始数据及分析目标,整理的网站智能推荐流程如下图所示:
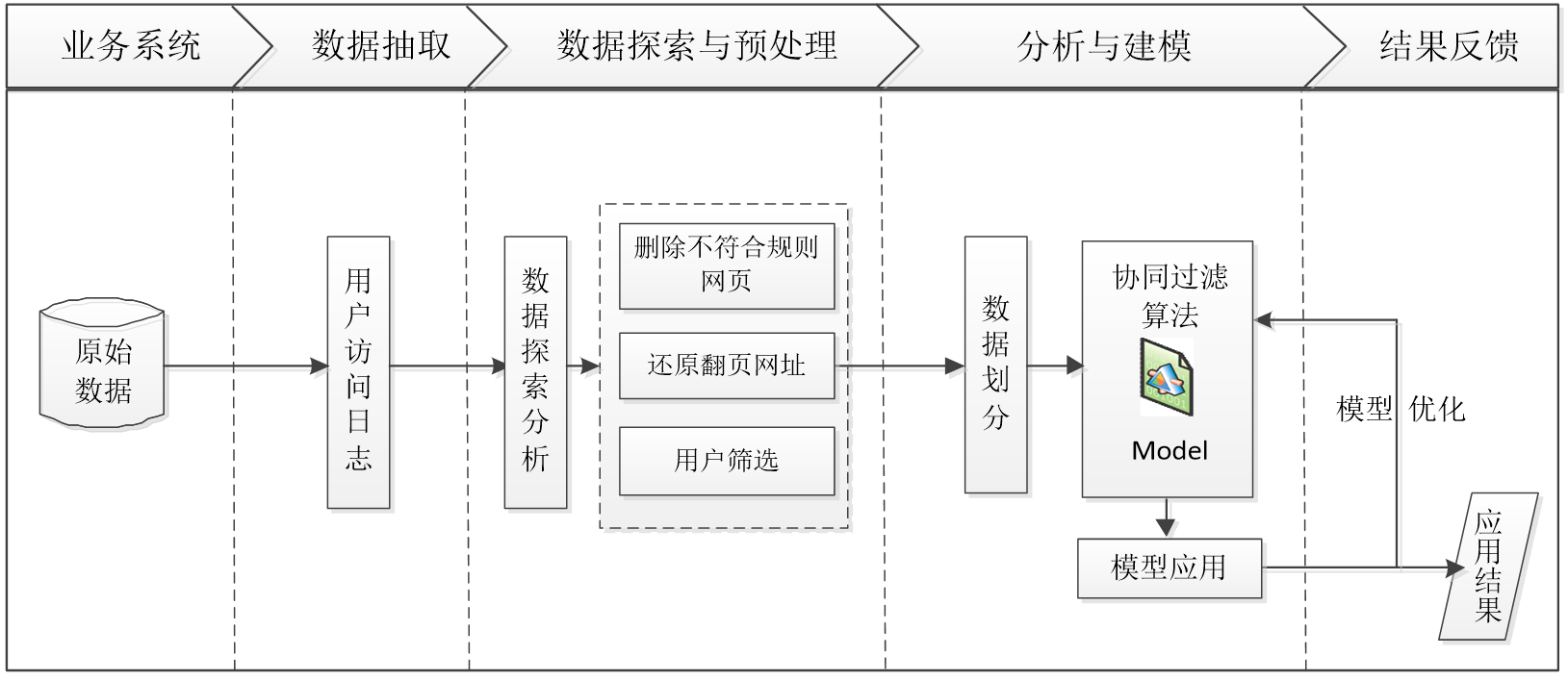
三、上机实验
3.1 数据抽取
以用户的访问时间为条件,选取三个月内(2015-02-01~2015-04-29)用户的访问数据作为原始数据集。由于每个地区的用户访问习惯以及兴趣爱好存在差异性,因此,抽取广州地区的用户访问数据进行分析,其数据量总共有837450条记录,其中包括用户号、访问时间、来源网站、访问页面、页面标题、来源网页、标签、网页类别、关键词等。
在数据抽取过程中,由于数据量较大且存储在数据库中,为了提高数据处理的效率,采取使用Python读取数据库的操作方式。本案例用到的数据库为开源数据库MySQL-community-5.6.39.0)。安装数据库后导入本案例的数据原始文件7law.sql,然后可以利用Python对数据库进行相关的操作,其中Python连接MySQL数据库及对数据库进行操作。
1、安装pymysql
2、导入7law.sql
3、连接数据库
import os import pandas as pd # 修改工作路径到指定文件夹 os.chdir("D:/JupyterLab-Portable-3.1.0-3.9/notebooks/大三下/RecommendingSystem") # 第一种连接方式 from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:12345@192.168.31.140:3306/7law?charset=utf8') connection = engine.connect() sql = pd.read_sql('all_gzdata', connection, chunksize = 10000) # # 第二种连接方式 # import pymysql as pm # con = pm.connect('localhost','root','12345','test',charset='utf8') # data = pd.read_sql('select * from all_gzdata',con=con) # con.close() #关闭连接 # 保存读取的数据 data.to_csv('../RecommendingSystem/all_gzdata.csv', index=False, encoding='utf-8')
all_gzdata.csv:
3.2 数据探索分析
原始数据集中包括用户号、访问时间、来源网站、访问页面、页面标题、来源网页、标签、网页类别和关键词等信息,需要对原始数据进行网页类型、点击次数、网页排名等各个维度的分布分析,了解用户浏览网页行为及关注内容,获得数据内在的规律。
第一步:分析网页类型
import pandas as pd from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:12345@192.168.31.140:3306/7law?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) # 分析网页类型 counts = [i['fullURLId'].value_counts() for i in sql] #逐块统计 counts = counts.copy() counts = pd.concat(counts).groupby(level=0).sum() # 合并统计结果,把相同的统计项合并(即按index分组并求和) counts = counts.reset_index() # 重新设置index,将原来的index作为counts的一列。 counts.columns = ['index', 'num'] # 重新设置列名,主要是第二列,默认为0 counts['type'] = counts['index'].str.extract('(\d{3})') # 提取前三个数字作为类别id counts_ = counts[['type', 'num']].groupby('type').sum() # 按类别合并 counts_.sort_values(by='num', ascending=False, inplace=True) # 降序排列 counts_['ratio'] = counts_.iloc[:,0] / counts_.iloc[:,0].sum() print(counts_)
对原始数据中用户点击的网页类型进行统计分析,结果如下图:

通过上表可以发现,点击与咨询相关(网页类型为101,http://www.****.com/ask/)的记录占了49.16%,其他的类型(网页类型为199)占比24%左右,知识相关(网页类型为107,http://www.****.com/info/)占比22%左右。
# 知识类型内部统计 # 因为只有107001一类,但是可以继续细分成三类:知识内容页、知识列表页、知识首页 def count107(i): #自定义统计函数 j = i[['fullURL']][i['fullURLId'].str.contains('107')].copy() # 找出类别包含107的网址 j['type'] = None # 添加空列 j['type'][j['fullURL'].str.contains('info/.+?/')]= '知识首页' j['type'][j['fullURL'].str.contains('info/.+?/.+?')]= '知识列表页' j['type'][j['fullURL'].str.contains('/\d+?_*\d+?\.html')]= '知识内容页' return j['type'].value_counts() # 注意:获取一次sql对象就需要重新访问一下数据库(!!!) #engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) counts2 = [count107(i) for i in sql] # 逐块统计 counts2 = pd.concat(counts2).groupby(level=0).sum() # 合并统计结果 print(counts2) #计算各个部分的占比 res107 = pd.DataFrame(counts2) # res107.reset_index(inplace=True) res107.index.name= '107类型' res107.rename(columns={'type':'num'}, inplace=True) res107['比例'] = res107['num'] / res107['num'].sum() res107.reset_index(inplace = True) print(res107)
 (数据没有导入全)
(数据没有导入全)
根据统计结果对用户点击的页面类型进行排名,依次为咨询相关、知识相关、其他方面的网页、法规(类型为301)、律师相关(类型为102)。进一步对咨询类别内部进行统计分析,其结果如下表所示:

浏览咨询内容页(101003)记录是最多,其次是咨询列表页(101002)和咨询首页(101001)。初步分析可以得知用户都喜欢通过浏览问题的方式找到自己需要的信息,而不是以提问的方式或者查看长篇知识的方式。
分析其他(199)页面的情况,其中网址中带有“?”的占了32%左右,其他咨询相关与法规专题占比达到41%左右,地区和律师占比20%左右。
# 统计带“?”的数据 def countquestion(i): # 自定义统计函数 j = i[['fullURLId']][i['fullURL'].str.contains('\?')].copy() # 找出类别包含107的网址 return j #engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000) counts3 = [countquestion(i)['fullURLId'].value_counts() for i in sql] counts3 = pd.concat(counts3).groupby(level=0).sum() print(counts3) # 求各个类型的占比并保存数据 df1 = pd.DataFrame(counts3) df1['perc'] = df1['fullURLId']/df1['fullURLId'].sum()*100 df1.sort_values(by='fullURLId',ascending=False,inplace=True) print(df1.round(4))
网址中带有“?”的一共有65492条记录,且不仅仅出现在其他类别中,同时也会出现在咨询内容页和知识内容页中,但在其他类型(1999001)中占比最高,达到98.82%。因此需要进一步分析其类型内部的规律。见表:



# 统计199类型中的具体类型占比 def page199(i): #自定义统计函数 j = i[['fullURL','pageTitle']][(i['fullURLId'].str.contains('199')) & (i['fullURL'].str.contains('\?'))] j['pageTitle'].fillna('空',inplace=True) j['type'] = '其他' # 添加空列 j['type'][j['pageTitle'].str.contains('法律快车-律师助手')]= '法律快车-律师助手' j['type'][j['pageTitle'].str.contains('咨询发布成功')]= '咨询发布成功' j['type'][j['pageTitle'].str.contains('免费发布法律咨询' )] = '免费发布法律咨询' j['type'][j['pageTitle'].str.contains('法律快搜')] = '快搜' j['type'][j['pageTitle'].str.contains('法律快车法律经验')] = '法律快车法律经验' j['type'][j['pageTitle'].str.contains('法律快车法律咨询')] = '法律快车法律咨询' j['type'][(j['pageTitle'].str.contains('_法律快车')) | (j['pageTitle'].str.contains('-法律快车'))] = '法律快车' j['type'][j['pageTitle'].str.contains('空')] = '空' return j # 注意:获取一次sql对象就需要重新访问一下数据库 #engine = create_engine('mysql+pymysql://root:12345@192.168.31.140:3306/7law?charset=utf8') sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)# 分块读取数据库信息 #sql = pd.read_sql_query('select * from all_gzdata limit 10000', con=engine) counts4 = [page199(i) for i in sql] # 逐块统计 counts4 = pd.concat(counts4) d1 = counts4['type'].value_counts() print(d1) d2 = counts4[counts4['type']=='其他'] print(d2) # 求各个部分的占比并保存数据 df1_ = pd.DataFrame(d1) df1_['perc'] = df1_['type']/df1_['type'].sum()*100 df1_.sort_values(by='type',ascending=False,inplace=True) print(df1_)
网址中带有lawfirm关键字的对应律师事务所,带有ask/exp、ask/online关键字的对应咨询经验和在线咨询页。大多数用户浏览网页额的情况为咨询内容页、知识内容页、法规专题页、在线咨询页,其中咨询内容页和知识内容页占比最高。
第二步:分析网页点击次数
统计原始数据用户浏览网页次数的情况,结果如表所示。其中,浏览1次的用户最多,占所有用户58%左右:
