一、HDFS元数据管理
HDFS是一个分布式文件存储系统,文件分布式存储在多个DataNode节点上。一个文件存储在哪些DataNode节点的哪些位置的元数据信息(metadata)由NameNode节点来处理。随着存储文件的增多,NameNode上存储的信息也会越来越多。在HDFS中主要是通过两个组件FSImage(快照文件,存放在主Namenode上)和EditsLog来实现metadata的更新。在某次启动HDFS时,会从FSImage文件中读取当前HDFS文件的metadata,之后对HDFS的操作步骤都会记录到edit log文件中。创建目录执行样例如图所示:
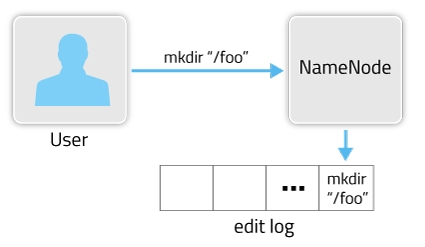
完整的metadata信息由FSImage文件和edit log文件组成。fsimage中存储的信息就相当于整个hdfs在某一时刻的一个快照。 FSImage文件和EditsLog文件可以通过ID来互相关联。在参数dfs.namenode.name.dir设置的路径下,会保存FSImage文件和EditsLog文件,如果是QJM方式HA的话,EditsLog文件保存在参数dfs.journalnode.edits.dir设置的路径下。 文件样例如图所示:
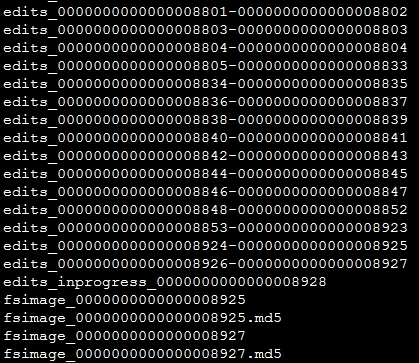
在上图中可以看到,edit log文件以edits_开头,后面跟一个txid范围段,并且多个edit log之间首尾相连,正在使用的edit log名字为edits_inprogress_txid(图中倒数第5行,最后一个edits文件)。该路径下还会保存两个fsimage文件,文件格式为fsimage_txid。上图中可以看出fsimage文件已经加载到了最新的一个edit log文件(加载了末尾数字8927这个edits文件),仅仅只有inprogress状态的edit log未被加载。在启动HDFS时,只需要读入fsimage_0000000000000008927以及edits_inprogress_0000000000000008928就可以还原出当前hdfs的最新状况。如果edit log文件越来越多、越来越大时,当重新启动hdfs时,由于需要加载fsimage后再把所有的edit log也加载进来,随着存储文件的增多,NameNode上存储的信息也会越来越多。HDFS提供Checkpoint机制来实现editslog和fsimage快照文件的合并。
fsimage和edit log合并的过程如下图所示:
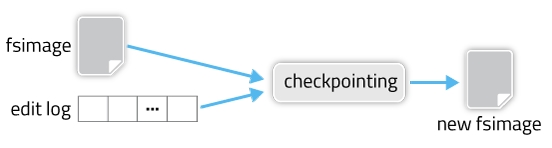
其实这个合并过程是一个很耗I/O与CPU的操作,并且在进行合并的过程中肯定也会有其他应用继续访问和修改hdfs文件。所以,这个过程一般不是在单一的NameNode节点上进行从。如果HDFS没有做HA的话,checkpoint由SecondNameNode进程(一般SecondNameNode单独起在另一台机器上)来进行,这种方式基本不用。在HA模式下,checkpoint则由StandBy状态的NameNode来进行。 什么时候进行checkpoint由两个参数dfs.namenode.checkpoint.preiod(默认值是3600,即1小时)和dfs.namenode.checkpoint.txns(默认值是1000000)来决定。period参数表示,经过1小时就进行一次checkpoint,txns参数表示,hdfs经过100万次操作后就要进行checkpoint了。这两个参数任意一个得到满足,都会触发checkpoint过程。进行checkpoint的节点每隔dfs.namenode.checkpoint.check.period(默认值是60)秒就会去统计一次hdfs的操作次数。在HA模式下checkpoint过程由StandBy NameNode来进行,以下简称为NM备节点,Active NameNode简称为NM主节点。HA模式下的edit log文件会同时写入多个JournalNodes节点的dfs.journalnode.edits.dir路径下,JournalNodes的个数为大于1的奇数(MRS大多为3个节点),类似于Zookeeper的节点数,当有不超过一半的JournalNodes出现故障时,仍然能保证集群的稳定运行。 NM备节点会读取FSImage文件中的内容,并且每隔一段时间就会把NM主节点写入edit log中的记录读取出来,这样NM备节点的NameNode进程中一直保持着hdfs文件系统的最新状况namespace。当达到checkpoint条件的某一个时,就会直接将该信息写入一个新的FSImage文件中,然后通过HTTP传输给NM主节点,传送过程如图所示:
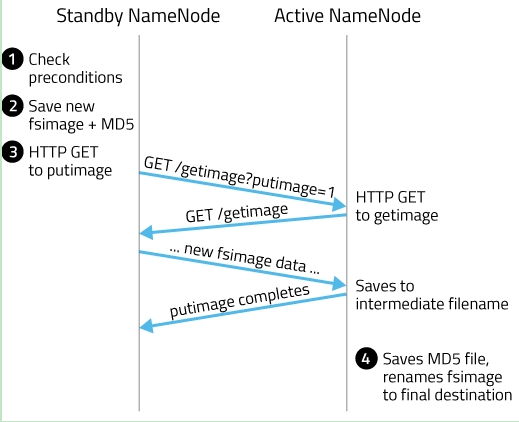
1. NM备节点检查是否达到checkpoint条件:离上一次checkpoint操作是否已经有一个小时,或者HDFS已经进行了100万次操作。
2. NM备节点检查达到checkpoint条件后,将该namespace以fsimage.ckpt_txid格式保存到NM备节点的磁盘上,并且随之生成一个MD5文件。然后将该fsimage.ckpt_txid文件重命名为fsimage_txid。
3. 然后NM备节点通过HTTP联系NM主节点。
4. NM主节点通过HTTP从NM备节点获取最新的fsimage_txid文件并保存为fsimage.ckpt_txid,然后也生成一个MD5,将这个MD5与NM备节点的MD5文件进行比较,确认NM主节点已经正确获取到了NM备节点最新的fsimage文件。然后将fsimage.ckpt_txid文件重命名为fsimage_txit。
通过上面一系列的操作,NM备节点上最新的FSImage文件就成功同步到了NM主节点上。
HDFS元数据相关参考材料:
https://www.cnblogs.com/nucdy/p/5892144.html
https://blog.csdn.net/dabokele/article/details/51686257
二、HDFS度写过程说明
2.1HDFS写入流程
写详细步骤:
 流程图后续优化。
流程图后续优化。
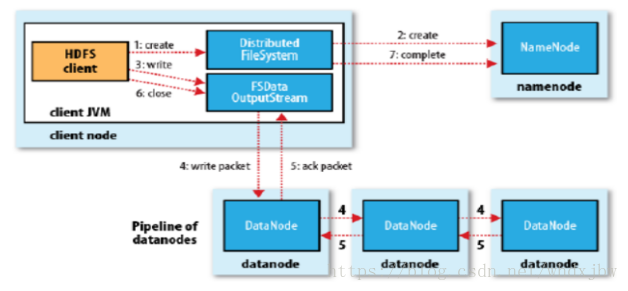
1、客户端向NameNode发出写文件请求。
2、检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。(注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录,我们不用担心后续client读不到相应的数据块,因为在第5步中DataNode收到块后会有一返回确认信息,若没写成功,发送端没收到确认信息,会一直重试,直到成功)
3、client端按128MB(根据实际配置block块大小)的块切分文件。
4、client将NameNode返回的分配的可写的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和NameNode分配的多个DataNode构成pipeline管道,client端向输出流对象中写数据。client每向第一个DataNode写入一个packet,这个packet便会直接在pipeline里传给第二个、第三个…DataNode。(注:并不是写好一个块或一整个文件后才向后分发)
5、每个DataNode写完一个块后,会返回确认信息。(注:并不是每写完一个packet后就返回确认信息,个人觉得因为packet中的每个chunk都携带校验信息,没必要每写一个就汇报一下,这样效率太慢。正确的做法是写完一个block块后,对校验信息进行汇总分析,就能得出是否有块写错的情况发生)
6、写完数据,关闭输输出流。
7、发送完成信号给NameNode。
2.2HDFS读取流程
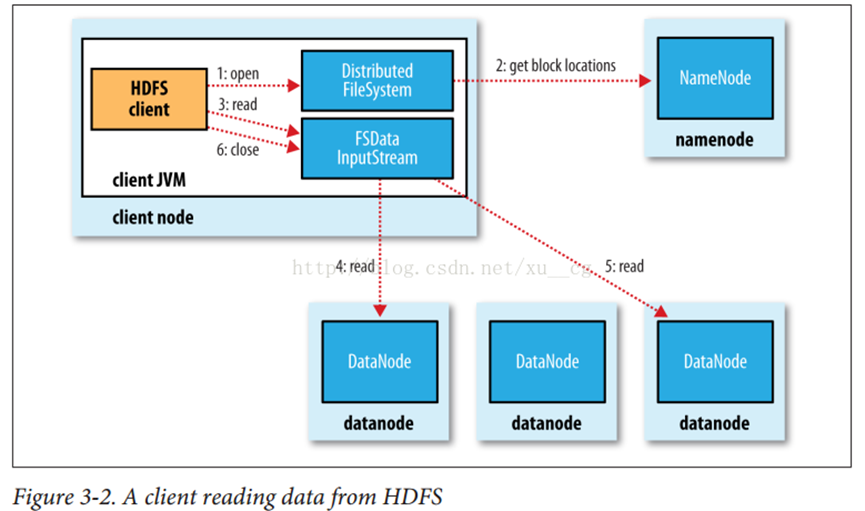
1、Client向NameNode发起RPC请求,来确定请求文件block所在的位置;
2、 NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode 都会返回含有该 block 副本的 DataNode 地址;这些返回的 DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
3、 Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是DataNode,那么将从本地直接获取数据(短路读取特性);
4、底层上本质是建立Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
5、当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
6、读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
7、 read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据;
8、最终读取来所有的 block 会合并成一个完整的最终文件。
2.3 通过校验和方式保证HDFS读写过程保证数据完整性
HDFS 的client端即实现了对 HDFS 文件内容的校验和 (checksum) 检查。当客户端创建一个新的HDFS文件时候,分块后会计算这个文件每个数据块的校验和,此校验和会以一个隐藏文件形式保存在同一个 HDFS 命名空间下。当client端从HDFS中读取文件内容后,它会检查分块时候计算出的校验和(隐藏文件里)和读取到的文件块中校验和是否匹配,如果不匹配,客户端可以选择从其他 Datanode 获取该数据块的副本。
HDFS中文件块目录结构具体格式如下:
${dfs.datanode.data.dir}/
├── current
│ ├── BP-526805057-127.0.0.1-1411980876842
│ │ └── current
│ │ ├── VERSION
│ │ ├── finalized
│ │ │ ├── blk_1073741825
│ │ │ ├── blk_1073741825_1001.meta
│ │ │ ├── blk_1073741826
│ │ │ └── blk_1073741826_1002.meta
│ │ └── rbw
│ └── VERSION
└── in_use.lock
in_use.lock表示DataNode正在对文件夹进行操作
rbw是“replica being written”的意思,该目录用于存储用户当前正在写入的数据。
Block元数据文件(*.meta)由一个包含版本、类型信息的头文件和一系列校验值组成。校验和也正是存在其中。
参考材料:https://blog.csdn.net/whdxjbw/article/details/81072207
三、HDFS API调用
在 java 中操作 HDFS,主要涉及以下 Class:
Configuration:该类的对象封转了客户端或者服务器的配置; FileSystem:该类的对象是一个文件系统对象,可以用该对象的一些方法来对文件进行操作,通过 FileSystem 的静态方法 get 获得该对象。
FileSystem fs = FileSystem.get(conf)
get 方法从 conf 中的一个参数 fs.defaultFS 的配置值判断具体是什么类型的文件系统。如果我们的代码中没有指定 fs.defaultFS,并且工程 classpath下也没有给定相应的配置,conf中的默认值就来自于hadoop的jar包中的core-default.xml ,默认值为: file:/// ,则获取的将不是一个DistributedFileSystem 的实例,而是一个本地文件系统的客户端对象
3.1 使用url的方式访问数据
@Test
public void demo1()throws Exception{
//第一步:注册hdfs 的url,让java代码能够识别hdfs的url形式
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
InputStream inputStream = null;
FileOutputStream outputStream =null;
//定义文件访问的url地址
String url = "hdfs://1.1.1.1:8020/test/input/install.log";
//打开文件输入流
try {
inputStream = new URL(url).openStream();
outputStream = new FileOutputStream(new File("c:\\hello.txt"));
IOUtils.copy(inputStream, outputStream);
} catch (IOException e) {
e.printStackTrace();
}finally {
IOUtils.closeQuietly(inputStream);
IOUtils.closeQuietly(outputStream);
}
}
3.2 获取文件系统(FileSystem)的几种方式
方式1:
@Test
public void getFileSystem() throws URISyntaxException, IOException {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.get(new URI("hdfs://1.1.1.1:8020"), configuration);
System.out.println(fileSystem.toString());
}
方式2:
@Test
public void getFileSystem2() throws URISyntaxException, IOException {
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://1.1.1.1:8020");
FileSystem fileSystem = FileSystem.get(new URI("/"), configuration);
System.out.println(fileSystem.toString());
}
方式3:
@Test
public void getFileSystem3() throws URISyntaxException, IOException {
Configuration configuration = new Configuration();
FileSystem fileSystem = FileSystem.newInstance(new URI("hdfs://1.1.1.1:8020"), configuration);
System.out.println(fileSystem.toString());
}
方式4:
@Test
public void getFileSystem4() throws Exception{
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS","hdfs://1.1.1.1:8020");
FileSystem fileSystem = FileSystem.newInstance(configuration);
System.out.println(fileSystem.toString());
}
3.3 通过官方API遍历hdfs文件系统
/**
* 递归遍历官方提供的API版本
* @throws Exception
*/
@Test
public void listMyFiles()throws Exception{
//获取fileSystem类
FileSystem fileSystem = FileSystem.get(new URI("hdfs://1.1.1.1:8020"), new Configuration());
//获取RemoteIterator 得到所有的文件或者文件夹,第一个参数指定遍历的路径,第二个参数表示是否要递归遍历
RemoteIterator<LocatedFileStatus> locatedFileStatusRemoteIterator = fileSystem.listFiles(new Path("/"), true);
while (locatedFileStatusRemoteIterator.hasNext()){
LocatedFileStatus next = locatedFileStatusRemoteIterator.next();
System.out.println(next.getPath().toString());
}
fileSystem.close();
}
3.4 拷贝文件到本地
@Test
public void getFileToLocal()throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://1.1.1.1:8020"), new Configuration());
FSDataInputStream open = fileSystem.open(new Path("/test/input/install.log"));
FileOutputStream fileOutputStream = new FileOutputStream(new File("c:\\install.log"));
IOUtils.copy(open,fileOutputStream );
IOUtils.closeQuietly(open);
IOUtils.closeQuietly(fileOutputStream);
fileSystem.close();
}
3.5 hdfs上创建文件夹
@Test
public void mkdirs() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://1.1.1.1:8020"), new Configuration());
boolean mkdirs = fileSystem.mkdirs(new Path("/hello/mydir/test"));
fileSystem.close();
}
3.6 hdfs文件上传
@Test
public void putData() throws Exception{
FileSystem fileSystem = FileSystem.get(new URI("hdfs://1.1.1.1:8020"), new Configuration());
fileSystem.copyFromLocalFile(new Path("file:///c:\\install.log"),new Path("/hello/mydir/test"));
fileSystem.close();
}
更详细开发内容参考华为云官网HDFS开发指南
https://support.huaweicloud.com/devg3-mrs/mrs_07_090002.html
https://support.huaweicloud.com/devg3-mrs/mrs_07_300002.html