一、简介
Scrapy提供了一个Extension机制,可以让我们添加和扩展一些自定义的功能。利用Extension我们可以注册一些处理方法并监听Scrapy运行过程中的各个信号,做到发生某个事件时执行我们自定义的方法。
Scrapy已经内置了一些Extension,如LogStats这个Extension用于记录一些基本的爬取信息,比如爬取的页面数量、提取的Item数量等,CoreStats这个Extension用于统计爬取过程中的核心统计信息,如开始爬取时间、爬取结束时间等。
和Downloader Middleware、Spider Middleware以及Item Pipeline一样,Extension也是通过settings.py中的配置来控制是否被启用的,是通过EXTESION这个配置项来实现的,例如:
EXTENSIONS={
scrapy.extensions.corestats.Corestats': 500',
scrapy.extensions.telnet.TelnetConsole': 501,
}通过如上配置我们就开启了CoreStats和TelnetConsole这两个Extension。
另外我们也可以实现自定义的Extension,实现过程其实很简单,主要分为两步:
- 实现一个Python类,然后实现对应的处理方法,如实现一个spider_opened方法用于处理Spider开始爬取时执行的操作,可以接收一个spider参数并对其进行操作。
- 定义from_crawler类方法,其第一个参数是cls类对象,第二个参数是crawler。利用crawler的signals对象将Scrapy的各个信号和已经定义的处理方法关联起来。
接下来我们用一个实例来演示一下Extension的实现过程。
二、实例演示
我们来尝试利用Extension实现爬取事件的消息通知。在爬取开始时、爬取到数据时、爬取结束时通知指定的服务器,将这些事件和对应的数据通过HTTP请求发送给服务器。
本节通过上节Item Pipeline的代码进行演示,主要内容如下:
import scrapy
from testItemPipeline.items import TestitempipelineItem
class MovieSpiderSpider(scrapy.Spider):
name = 'movie_spider'
allowed_domains = ['ssr1.scrape.center']
start_url = 'http://ssr1.scrape.center'
def start_requests(self):
for i in range(1,11):
url=self.start_url+f'/page/{i}'
yield scrapy.Request(url=url,callback=self.parse_index)
def parse_index(self,response):
data_list = response.xpath('//div[@class="el-col el-col-18 el-col-offset-3"]//div[@class="el-card item m-t is-hover-shadow"]')
for item in data_list:
href = item.xpath('./div/div/div[1]/a/@href').extract_first()
url = response.urljoin(href)
yield scrapy.Request(url=url,callback=self.parse_detail)
def parse_detail(self, response):
item = TestitempipelineItem()
item["name"] = response.xpath('//div[@class="el-card__body"]/div[@class="item el-row"]/div[@class="p-h el-col el-col-24 el-col-xs-16 el-col-sm-12"]/a/h2/text()').extract_first()
item["categories"] = ','.join(response.xpath('//div[@class="el-card__body"]/div[@class="item el-row"]/div[@class="p-h el-col el-col-24 el-col-xs-16 el-col-sm-12"]/div[@class="categories"]/button/span/text()').extract())
item["score"] = ''.join(response.xpath('//div[@class="el-card__body"]/div[@class="item el-row"]/div[@class="el-col el-col-24 el-col-xs-8 el-col-sm-4"]/p/text()').extract_first()).replace("\n","").replace(" ","")
item["drama"] = ''.join(response.xpath('//div[@class="el-card__body"]/div[@class="item el-row"]/div[@class="p-h el-col el-col-24 el-col-xs-16 el-col-sm-12"]/div[@class="drama"]/p/text()').extract_first()).replace("\n","")
item["directors"] = []
dd = response.xpath('//div[@class="el-col el-col-18 el-col-offset-3"]//div[@class="directors el-row"]')
for data in dd:
directors_name = data.xpath('./div[@class="director el-col el-col-4"]/div[@class="el-card is-hover-shadow"]/div[@class="el-card__body"]/p/text()').extract_first()
directors_image = data.xpath('./div[@class="director el-col el-col-4"]/div[@class="el-card is-hover-shadow"]/div[@class="el-card__body"]/img/@src').extract_first()
item["directors"].append({
'name': directors_name,
'image': directors_image
})
item["actors"] = []
ss = response.xpath('//div[@class="actors el-row"]//div[@class="actor el-col el-col-4"]')
for data in ss:
actors_image = ''.join(data.xpath('./div/div/img/@src').extract_first())
actors_name = ''.join(data.xpath('./div/div/p/text()').extract_first())
item["actors"].append({
"name": actors_name,
"image": actors_image
})
yield item另外本节我们需要用到Flask来搭建一个简易的测试服务器,也需要利用requests来实现HTTP请求的发送,因此需要安装好Flask、requests和loguru这3个库,使用pip安装即可:
- pip install flask requests loguru
1、部署本地flask服务器
为了方便验证,我们用Flask定义一个轻量级的服务器,用于接收POST请求并输出接收到的事件和数据,server.py的代码如下:

2、extensions.py
在testItemPipeline文件夹下新建一个extensions.py文件。
- 注意:在新建的文件夹一定要和其他组件是同一级别目录,如Spider、Item等。
接下来我们先实现几个对应的事件处理方法:
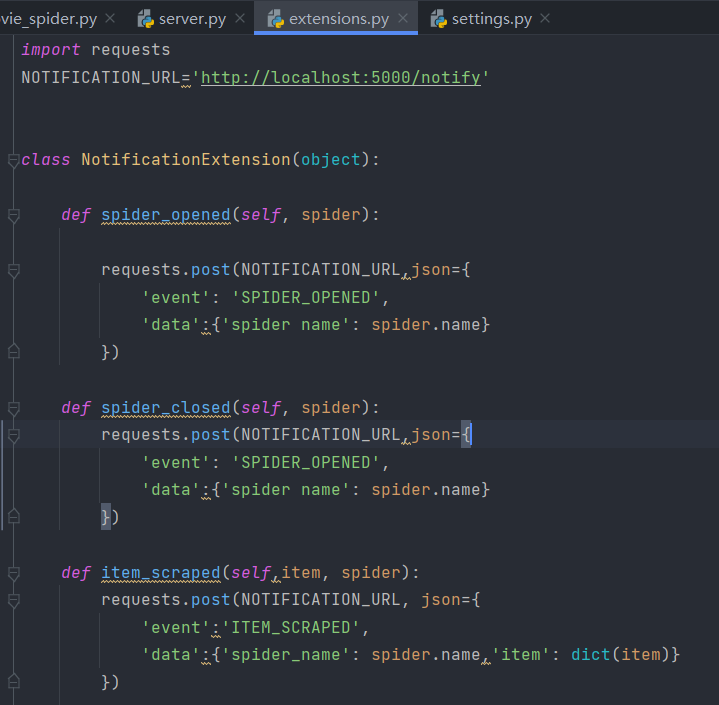
这里我们定义了一个NotificationExtension类,然后实现了3个方法,spider_opened、spider_closed和item_scraped,分别对应爬取开始、爬取结束和爬取到Item 的处理。接着调用了 requests 向刚才我们搭建的 HTTP 服务器发送了对应的事件,其中包含两个字段:一个是 event,代表事件的名称;另一个是 data,代表一些附加数据,如 Spider的名称、Item的具体内容等。
但仅仅这么定义其实还不够,现在启用这个Extension其实没有任何效果的,我们还需要将这些方法和对应的Scrapy信号关联起来,再在NotificationExtension类中添加如下类方法:
添加方法前可以先导入一下Scrapy中的signals对象:
from scrapy import signals
其中,from crawler 是一个类方法,第一个参数就是 cls 类对象,第二个参数 crawler 代表了Scrapy运行过程中全局的Crawler对象。
Crawler对象里有一个子对象叫作signals,通过调用signals对象的connect方法,我们可以将Scrapy运行过程中的某个信号和我们自定义的处理方法关联起来。这样在某个事件发生的时候,被关联的处理方法就会被调用。比如这里,connect方法第一个参数我们传入ext.spider_opened这个对象而ext是由cls类对象初始化的,所以ext.spider_opened就代表我们在NotificationExtension类中定义的spider_opened方法。connect方法的第二个参数我们传入了signals.spider_opened这个对象这就指定了spider_opened 方法可以被spider_opened信号触发。这样在Spider 开始运行的时候会产生signals.spider_opened信号,NotificationExtension类中定义的spider_opened方法就会被调用了。
完成如上定义之后,我们还需要开启这个Extension,在settings.py中添加如下内容即可。

我们成功启用了NotificationExtension这个Extension。下面我们来运行一下movie_spider:
scrapy crawl movie_spider
这时候爬取结果和Item Pipeline的使用这节的内容大致一样,不同的是日志中多了类似如下的几行:
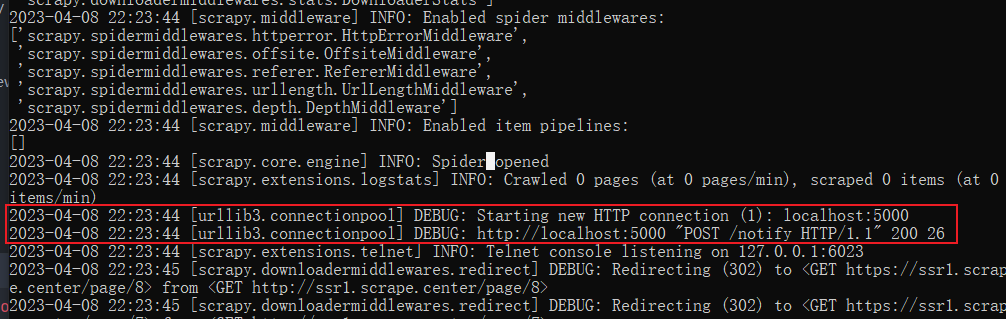
有了这样的日志,说明成功调用了requests的post方法完成了对服务器的请求。
这时候我们回到Flask服务器,看一下控制台的输出结果:
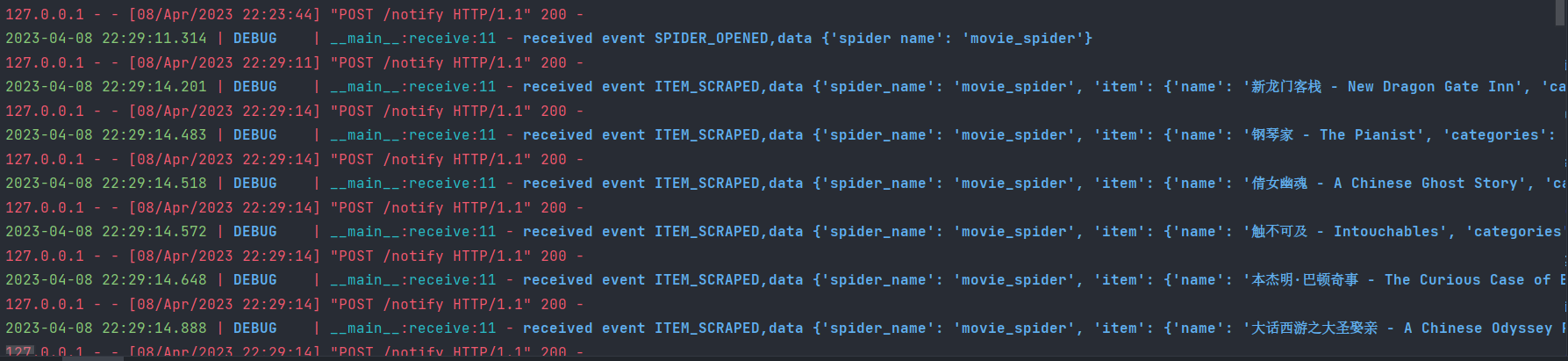
可以看到Flask服务器成功接收到了各个事件(SPIDER OPENED、ITEM SCRAPED、SPIDEROPENED)并输出了对应的数据,这说明在 Scrapy 爬取过程中,成功调用了 Extension 并在适当的时机将数据发送到服务器了,验证成功!
我们通过一个自定义的 Extension,成功实现了 Scrapy 爬取过程中和远程服务器的通信,远程服务器收到这些事件之后就可以对事件和数据做进一步的处理了。
本节通过一个Extension的样例体会到了Extension强大又灵活的功能,以后我们想实现一些自定义的功能可以借助于Extension来实现了。而对于整个scrapy框架基础到这里也就结束了,后面对于一些不理解的地方一定要仔细琢磨认真观察,多练多思考。