1. 赛题背景:
赛题数据由约62万条训练集、20万条测试集数据组成,共包含13个字段。其中uuid为样本唯一标识,eid为访问行为ID,udmap为行为属性,其中的key1到key9表示不同的行为属性,如项目名、项目id等相关字段,common_ts为应用访问记录发生时间(毫秒时间戳),其余字段x1至x8为用户相关的属性,为匿名处理字段。target字段为预测目标,即是否为新增用户。
朴素的数据特征挖掘(从baseline获取提示):
(1) 数值统计特征:频次,均值,最值 ...
(2) 数据预处理:拆分 "udmap" 为:key1 - key9
(3) 特征语义:拆分 "common_ts",挖掘更多时间语义信息
后续深入挖掘(从思维导图入手,进行试验):
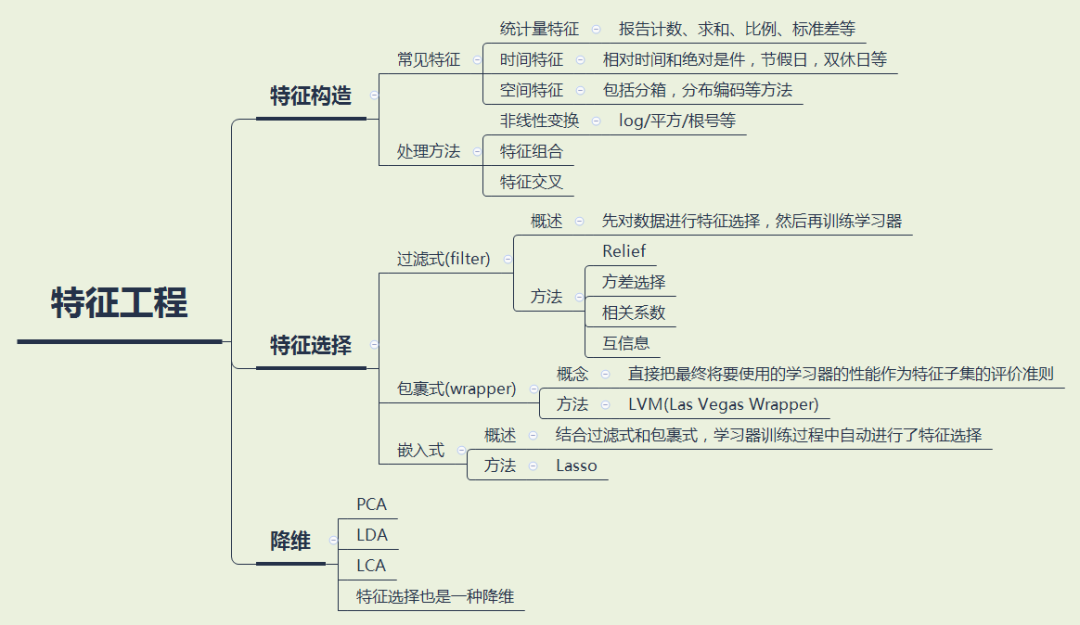
2. 模型选择:
(1) 深度学习 or 机器学习:选择 ”机器学习“;
(2) 逻辑回归 or 树模型:树模型,用于处理不均衡样本,生成决策规则(决策树,随机森林,boost系列)
3. 得分变化:(上分策略,赛后整理)
2 → 6 → 7 → 7.2 → 7.5 → 7.8
4. 后续想深入的问题:
(1) 模型集成;(2) 数据欠拟合