1 k8s集群介绍
1.1 k8s单master架构
单master节点的架构,通常只用于测试环境,生产环境绝对不允许;这是因为k8s集群master的节点是单点,一旦master节点宕机,将导致整个集群不可用;其次单master节点apiServer是性能瓶颈;从上图我们就可以看到,master节点所有组件和node节点中的kubelet和客户端kubectl、dashboard都会连接apiserver,同时apiserver还要负责往etcd中更新或读取数据,对客户端的请求做认证、准入控制等;很显然apiserver此时是非常忙碌的,极易成为整个K8S集群的瓶颈;所以不推荐在生产环境中使用单master架构;
1.2 k8s多master架构
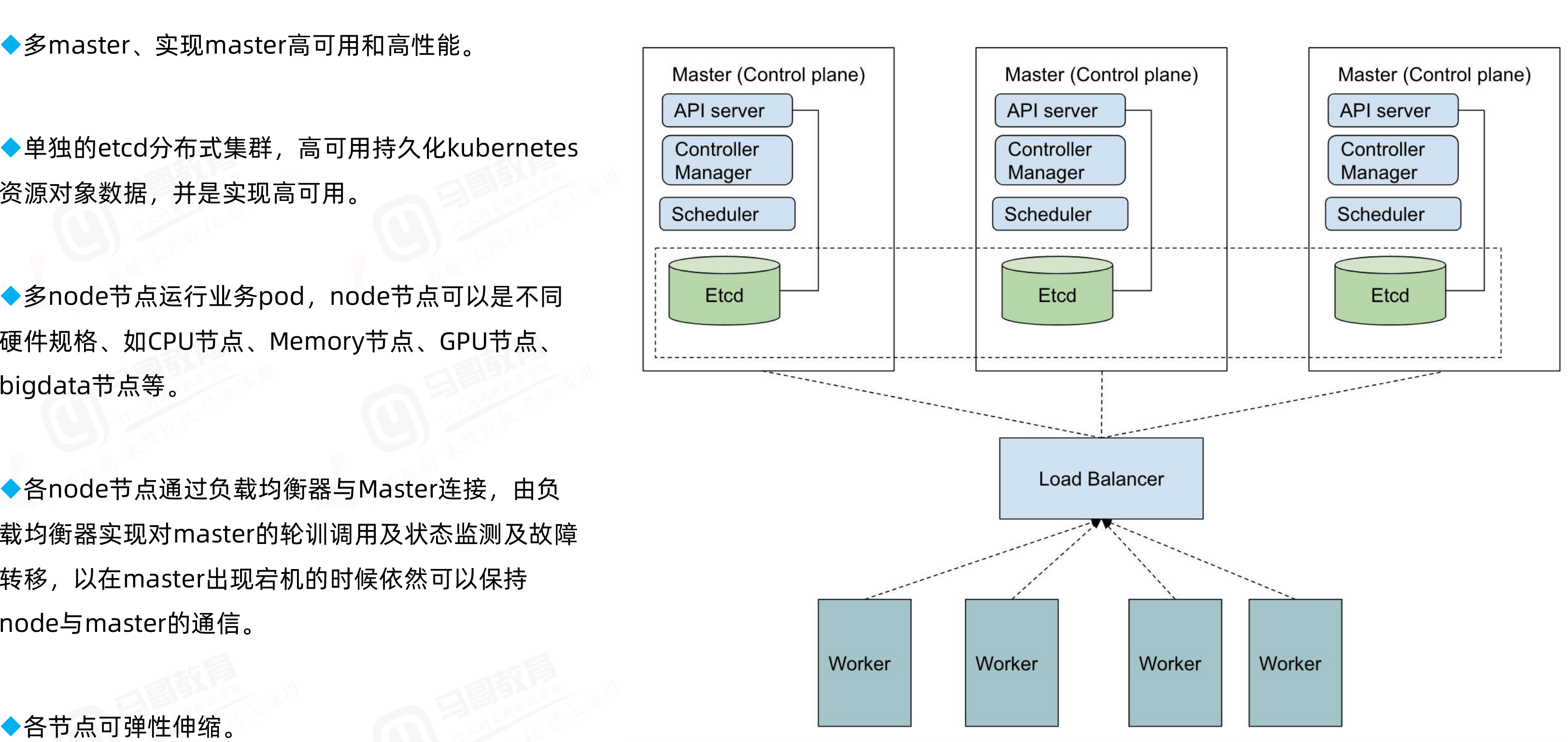
k8s高可用主要是对master节点组件高可用;其中apiserver高可用的逻辑就是通过启用多个实例来对apiserver做高可用;apiserver从某种角度讲它应该是一个有状态服务,但为了降低apiserver的复杂性,apiserver将数据存储到etcd中,从而使得apiserver从有状态服务变成了一个无状态服务;所以高可用apiserver我们只需要启用多个实例通过一个负载均衡器来反向代理多个apiserver,客户端和node的节点的kubelet通过负载均衡器来连接apiserver即可;对于controller-manager、scheduler这两个组件来说,高可用的逻辑也是启用多个实例来实现的,不同与apiserver,这两个组件由于工作逻辑的独特性,一个k8s集群中有且只有一个controller-manager和scheduler在工作,所以启动多个实例它们必须工作在主备模式,即一个active,多个backup的模式;它们通过分布式锁的方式实现内部选举,决定谁来工作,最终抢到分布式锁(k8s集群endpoint)的controller-manager、scheduler成为active状态代表集群controller-manager、scheduler组件工作,抢到锁的controller-manager和scheduler会周期性的向apiserver通告自己的心跳信息,以维护自己active状态,避免其他controller-manager、scheduler进行抢占;其他controller-manager、scheduler收到活动的controller-manager、scheduler的心跳信息后自动切换为backup状态;一旦在规定时间备用controller-manager、scheduler没有收到活动的controller-manager、scheduler的心跳,此时就会触发选举,重复上述过程;
2 部署k8s准备工作
服务器规划
K8S Master1+ansible 192.168.110.206
K8S Master2 192.168.110.207
Node1 192.168.110.208
Node2 192.168.110.209
etcd1+Harbor1 192.168.110.180
etcd2+Harbor2 192.168.110.181
harbor1+etcd3 192.168.110.183
harbor2 192.168.110.184
重新生成machine-id
cat /etc/machine-id
rm -rf /etc/machine-id && dbus-uuidgen --ensure=/etc/machine-id && cat /etc/machine-id

通过某一个虚拟机基于快照克隆出来的虚拟机,很有可能对应machine-id一样,可以通过上述命令将对应虚拟机的machine-id修改成不一样;
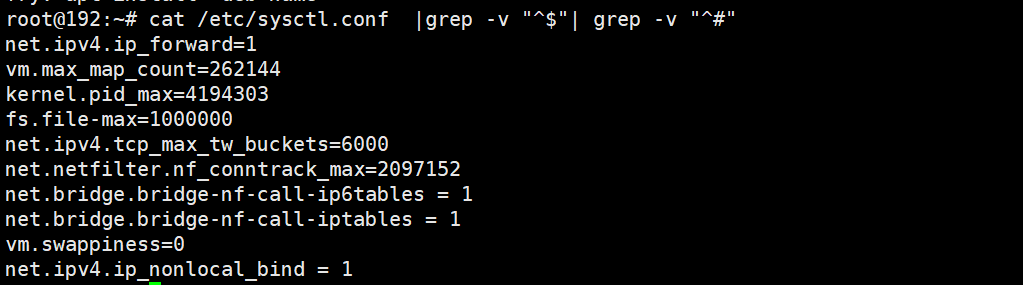
内核参数优化
cat /etc/sysctl.conf
系统资源限制
tail -10 /etc/security/limits.conf
</details>
root@deploy:~#
root soft core unlimited
root hard core unlimited
root soft nproc 1000000
root hard nproc 1000000
root soft nofile 1000000
root hard nofile 1000000
root soft memlock 32000
root hard memlock 32000
root soft msgqueue 8192000
root hard msgqueue 8192000
cat /etc/modules-load.d/modules.conf
ip_vs
ip_vs_lc
ip_vs_lblc
ip_vs_lblcr
ip_vs_rr
ip_vs_wrr
ip_vs_sh
ip_vs_dh
ip_vs_fo
ip_vs_nq
ip_vs_sed
ip_vs_ftp
ip_vs_sh
ip_tables
ip_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
xt_set
br_netfilter
nf_conntrack
overlay
禁用SWAP
swapoff -a
sed -i '/swap/s@^@#@' /etc/fstab
cat /etc/fstab

每个节点都做一下,然后把所有节点都重启;
基于keepalived及haproxy部署高可用负载均衡
两台haproxy服务器下载安装keepalived和haproxy
apt update && apt install keepalived haproxy -y
在ha01上创建/etc/keepalived/keepalived.conf并将配置文件复制给ha02
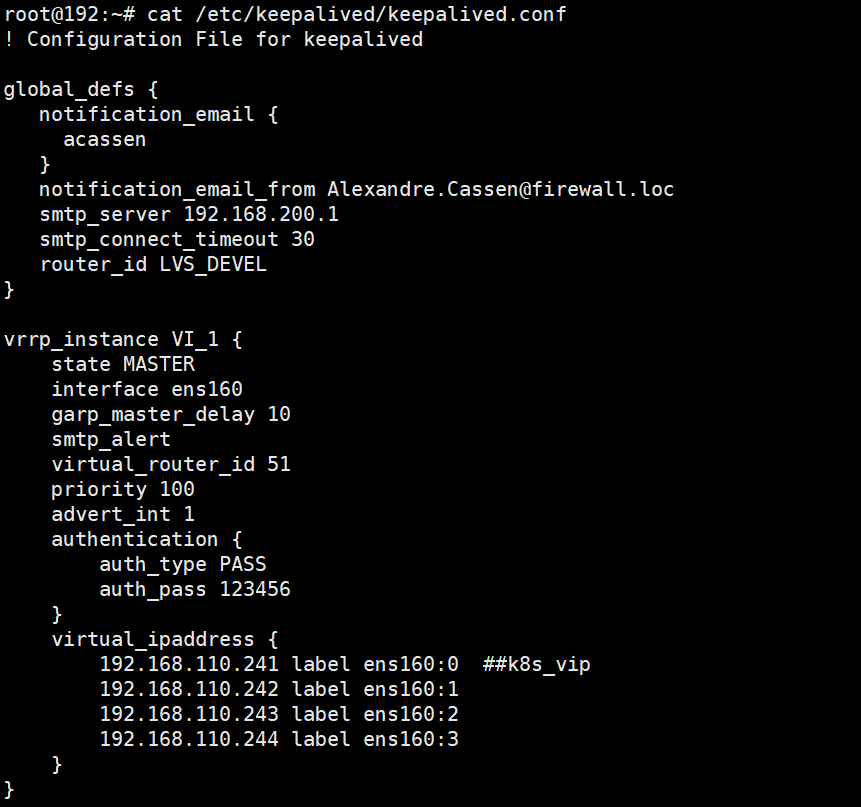
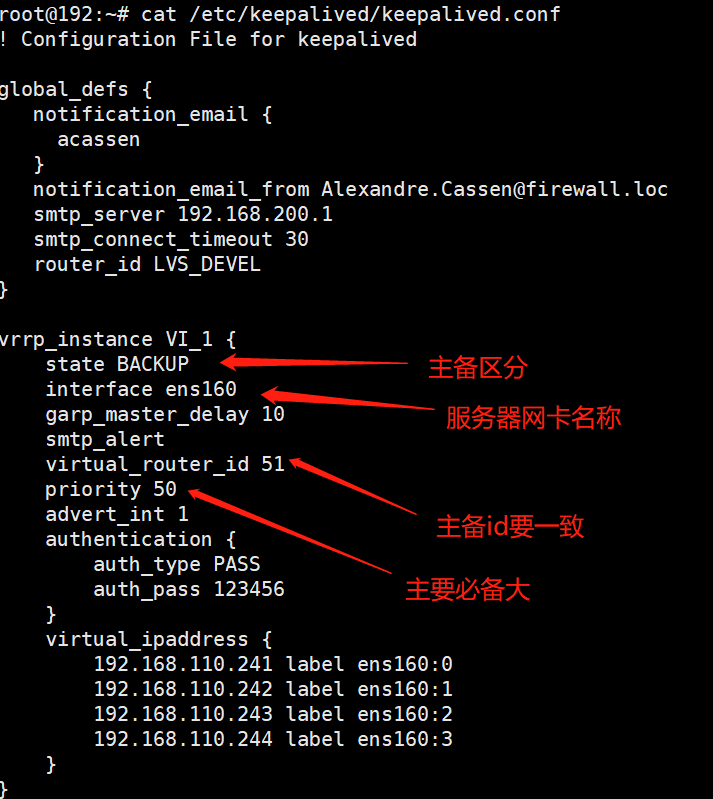
修改02配置文件
systemctl start keepalived
systemctl enable keepalived

启动服务后vip会漂到主节点

能够用集群其他主机ping vip说明vip是可用的,至此keepalived配置好了;
配置haproxy
cat /etc/haproxy/haproxy.cfg

在ha01和02上启动haproxy,并将haproxy设置为开机启动
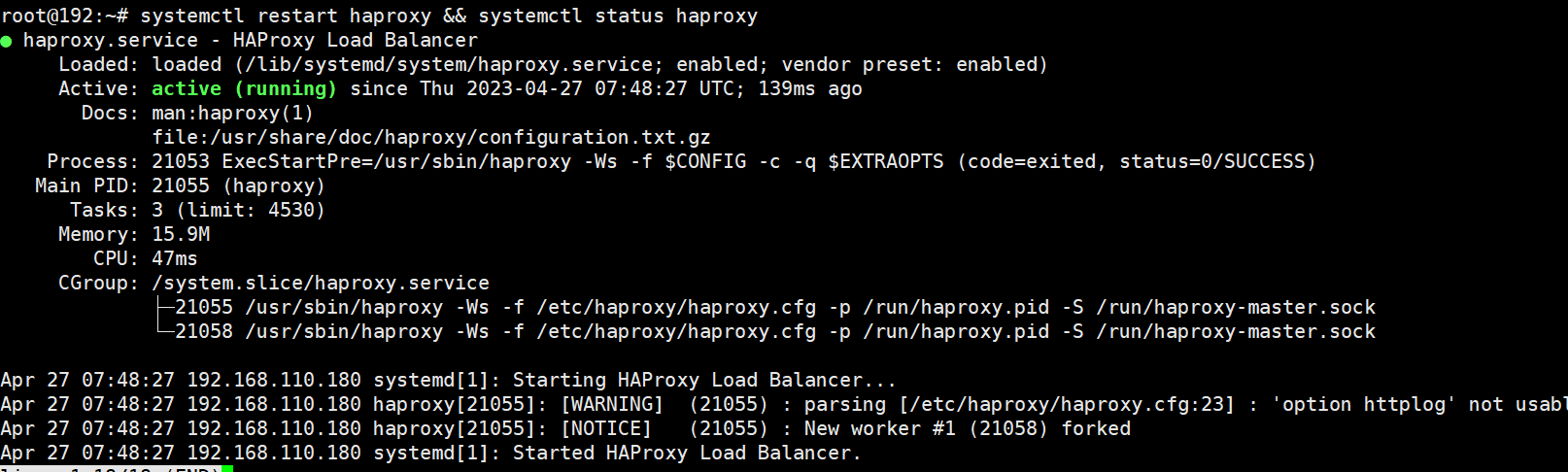
提示:现在不管vip在那个节点,对应请求都会根据vip迁移而随之迁移;至此基于keepalived及haproxy部署高可用负载均衡器就部署完成
3部署https harbor服务提供镜像的分发
在harbor服务器上配置docker-ce的源
在harbor服务器上安装docker和docker-compose 具体过程略过
下载harbor-offline-installer-v2.3.2.tgz二进制包
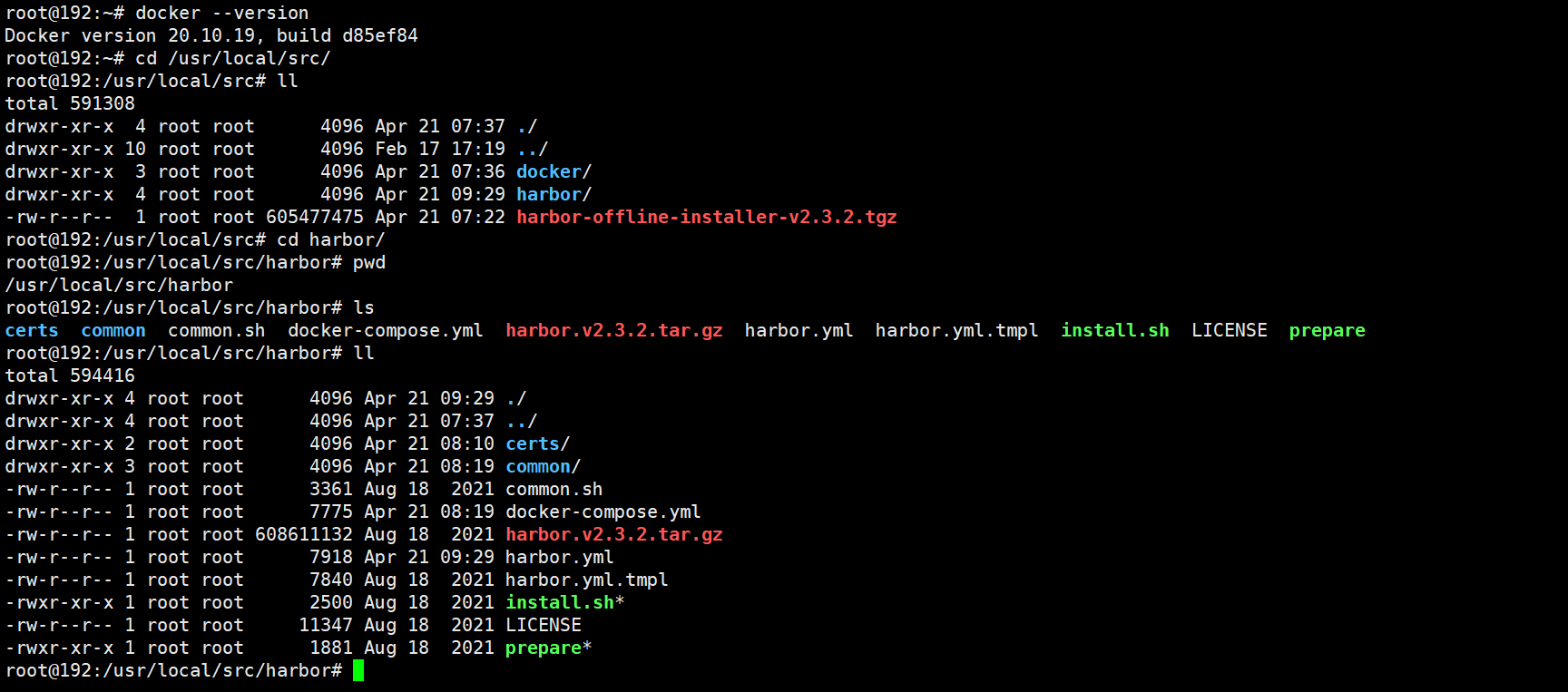
创建存放证书的目录certs并将申请好的证书放入

复制harbor配置模板harbor.yml.tmpl为harbor.yml
root@harbor:/app/certs# cd ..
root@harbor:/app# ls
certs harbor
root@harbor:/app# cd harbor/
root@harbor:/app/harbor# ls
LICENSE common.sh harbor.v2.8.0.tar.gz harbor.yml.tmpl install.sh prepare
root@harbor:/app/harbor# cp harbor.yml.tmpl harbor.yml
编辑harbor.yaml文件
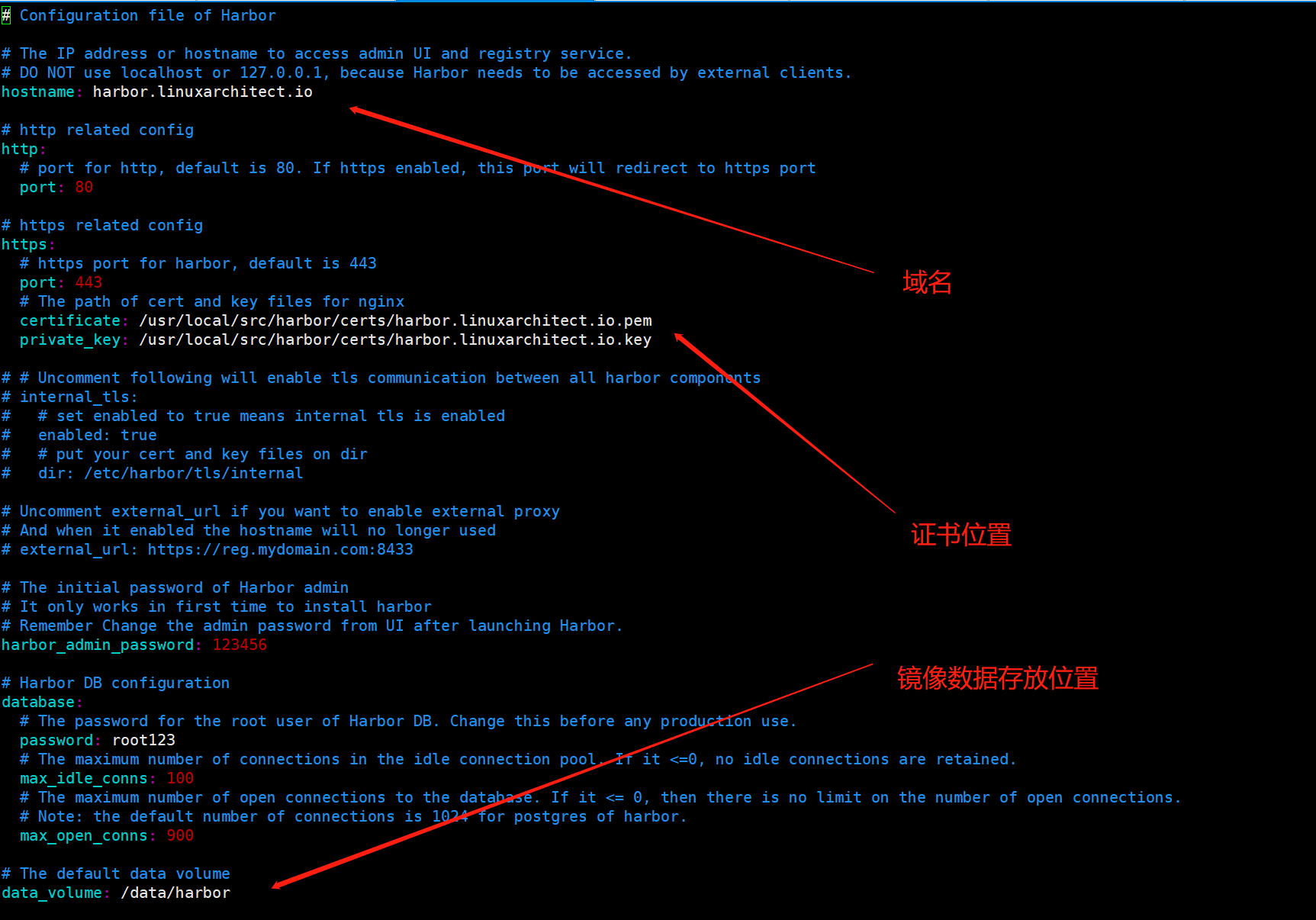
上述配置文件修改了hostname,这个主要用来指定证书中站点域名,这个必须和证书签发时指定的域名一样;其次是证书和私钥的路径以及harbor默认登录密码;
mkdir /data
为了避免数据丢失建议这个目录是挂载网络文件系统,如nfs;
执行harbor部署
./install.sh --with-notary --with-trivy
域名解析,将证书签发时的域名指向harbor服务器并验证
添加harbor开机自动启动
cat /usr/lib/systemd/system/harbor.service
[Unit]
Description=Harbor
After=docker.service systemd-networkd.service systemd-resolved.service
Requires=docker.service
Documentation=http://github.com/vmware/harbor
[Service]
Type=simple
Restart=on-failure
RestartSec=5
ExecStart=/usr/local/bin/docker-compose -f /app/harbor/docker-compose.yml up
ExecStop=/usr/local/bin/docker-compose -f /app/harbor/docker-compose.yml down
[Install]
WantedBy=multi-user.target
加载harbor.service重启harbor并设置harbor开机自启动
root@harbor:/app/harbor# systemctl daemon-reload
root@harbor:/app/harbor# systemctl restart harbor
root@harbor:/app/harbor# systemctl enable harbor
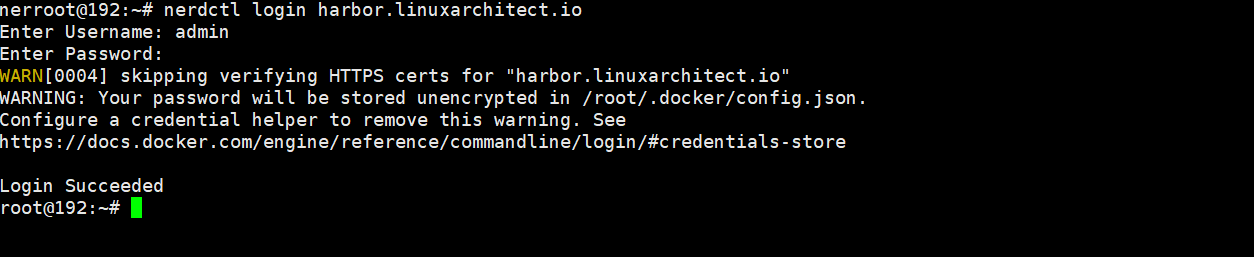
测试基于nerdctl可以登录https harbor并能实现进行分发
nerdctl登录harbor
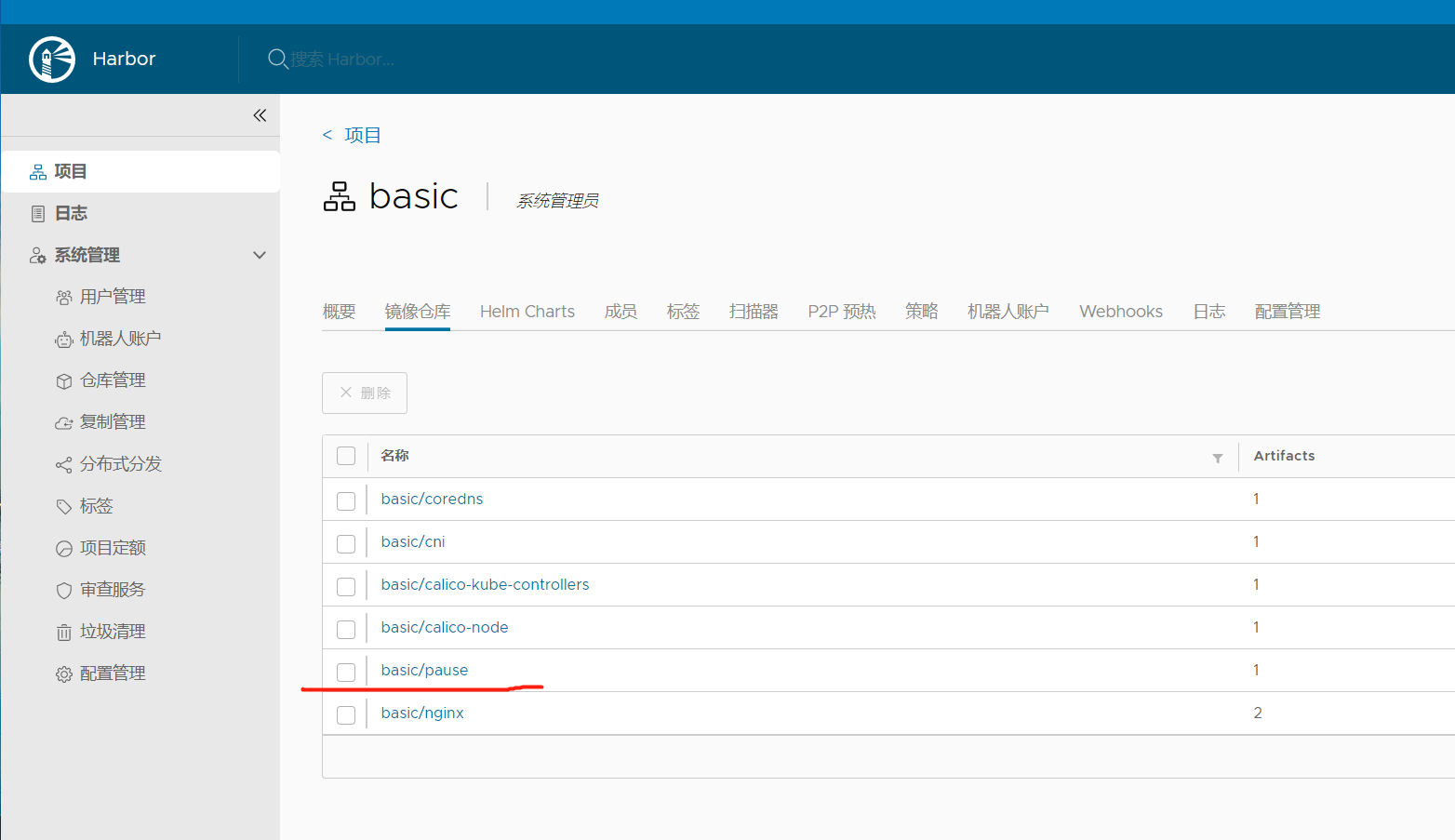
从node02本地向harbor上传镜像
root@k8s-node02:~# nerdctl pull harbor.linuxarchitect.io/basic/pause:3.9
root@k8s-node02:~# nerdctl images
4、基于kubeasz部署高可用kubernetes集群
部署节点部署环境初始化
项目地址 https://github.com/easzlab/kubeasz
本次我们使用kubeasz项目来部署二进制高可用k8s集群;项目地址:;该项目使用ansible-playbook实现自动化,提供一件安装脚本,也可以分步骤执行安装各组件;所以部署节点首先要安装好ansible,其次该项目使用docker下载部署k8s过程中的各种镜像以及二进制,所以部署节点docker也需要安装好,当然如果你的部署节点没有安装docker,它也会自动帮你安装;
部署节点配置docker源
apt-get update && apt-get -y install apt-transport-https ca-certificates curl software-properties-common && curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add - && add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable" && apt-get -y update
apt install ansible docker-ce -y
部署节点安装sshpass命令⽤于同步公钥到各k8s服务器 部署节点生成密钥对
apt install sshpass -y
ssh-keygen -t rsa-sha2-512 -b 4096
cat pub-key-scp.sh

sh pub-key-scp.sh 即可完成秘钥分发
下载kubeasz项目安装脚本
apt install git -y
export release=3.5.2
wget https://github.com/easzlab/kubeasz/releases/download/${release}/ezdown
编辑ezdown 并执行下载kubeasz项目及组件

chmod a+x ezdown
./ezdown -D
添加新集群
./ezctl new k8s-master01
编辑ansible hosts配置文件
vim k8s-master1/hosts

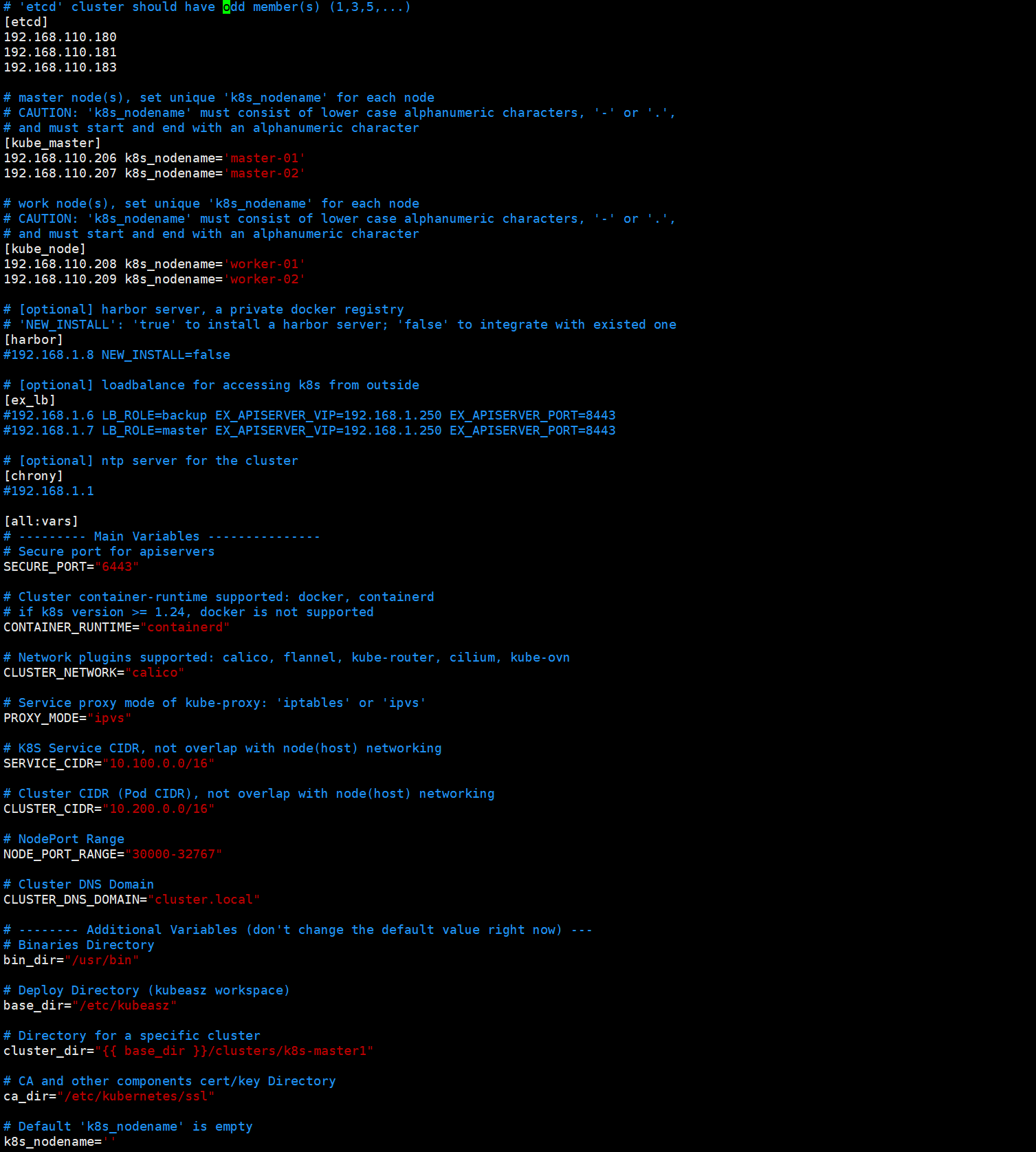
上述hosts配置文件主要用来指定etcd节点、master节点、node节点、vip、运行时、网络组件类型、service IP与pod IP范围等配置信息。
编辑cluster config.yml文件
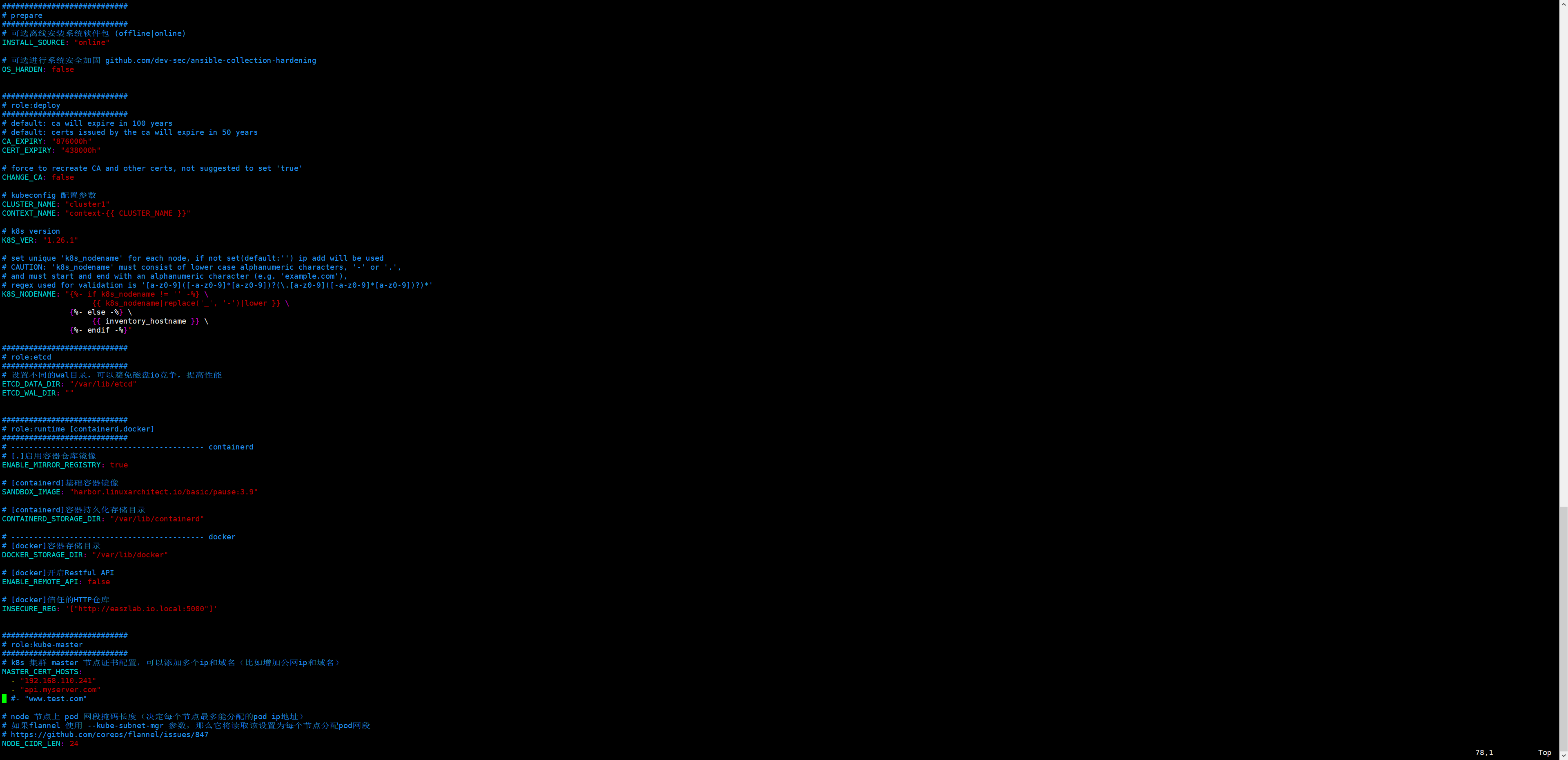


主要定义了CA和证书的过期时长、kubeconfig配置参数、k8s集群版本、etcd数据存放目录、运行时参数、masster证书名称、node节点pod网段子网掩码长度、kubelet根目录、node节点最大pod数量、网络插件相关参数配置以及集群插件安装相关配置;
这里需要注意一点,虽然我们没有自动安装coredns,但是这两个变量需要设置下,如果ENABLE_LOCAL_DNS_CACHE的值是true,下面的LOCAL_DNS_CACHE就写成对应coredns服务的IP地址;如果ENABLE_LOCAL_DNS_CACHE的值是false,后面的LOCAL_DNS_CACHE是谁的IP地址就无所谓了;
编辑系统基础初始化主机配置
注释掉上述ex_lb和chrony表示这两个主机我们自己定义,不需要通过kubeasz来帮我们初始化;即系统初始化,只针对master、node、etcd这三类节点来做;
准备CA和基础环境初始化
./ezctl setup k8s-master01 01
执行上述命令,反馈failed都是0,表示指定节点的初始化环境准备就绪,接下来我们就可以进行第二步部署etcd节点;
部署etcd集群
./ezctl setup k8s-master01 02
如果报错/usr/bin/python没有找到,导致不能获取到/etc/kubeasz/clusters/k8s-master01/ssl/etcd-csr.json信息;则需要在部署节点上将/usr/bin/python3软连接至/usr/bin/python;
ln -sv /usr/bin/python3 /usr/bin/python
验证etcd集群是否正常 需要在etcd服务器执行以下命令
root@k8s-etcd01:~# export NODE_IPS="192.168.110.180 192.168.110.181 192.168.110.183"
root@k8s-etcd01:~# for ip in ${NODE_IPS}; do ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health; done
https://192.168.110.180:2379 is healthy: successfully committed proposal: took = 32.64189ms
https://192.168.110.181:2379 is healthy: successfully committed proposal: took = 30.249623ms
https://192.168.110.183:2379 is healthy: successfully committed proposal: took = 32.747586ms
root@k8s-etcd01:~#
能够看到上面的健康状态成功,表示etcd集群服务正常;
部署容器运行时containerd
验证基础容器镜像
root@deploy:/etc/kubeasz# grep SANDBOX_IMAGE ./clusters/* -R
./clusters/k8s-cluster01/config.yml:SANDBOX_IMAGE: "harbor.ik8s.cc/baseimages/pause:3.9"
下载基础镜像到本地,然后更换标签,上传至harbor之上
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9
docker login harbor.linuxarchitect.io
docker push harbor.linuxarchitect.io/basic/pause:3.9
配置harbor镜像仓库域名解析-公司有DNS服务器进⾏域名解析
编辑/etc/kubeasz/roles/containerd/tasks/main.yml文件在block配置段里面任意找个地方添加

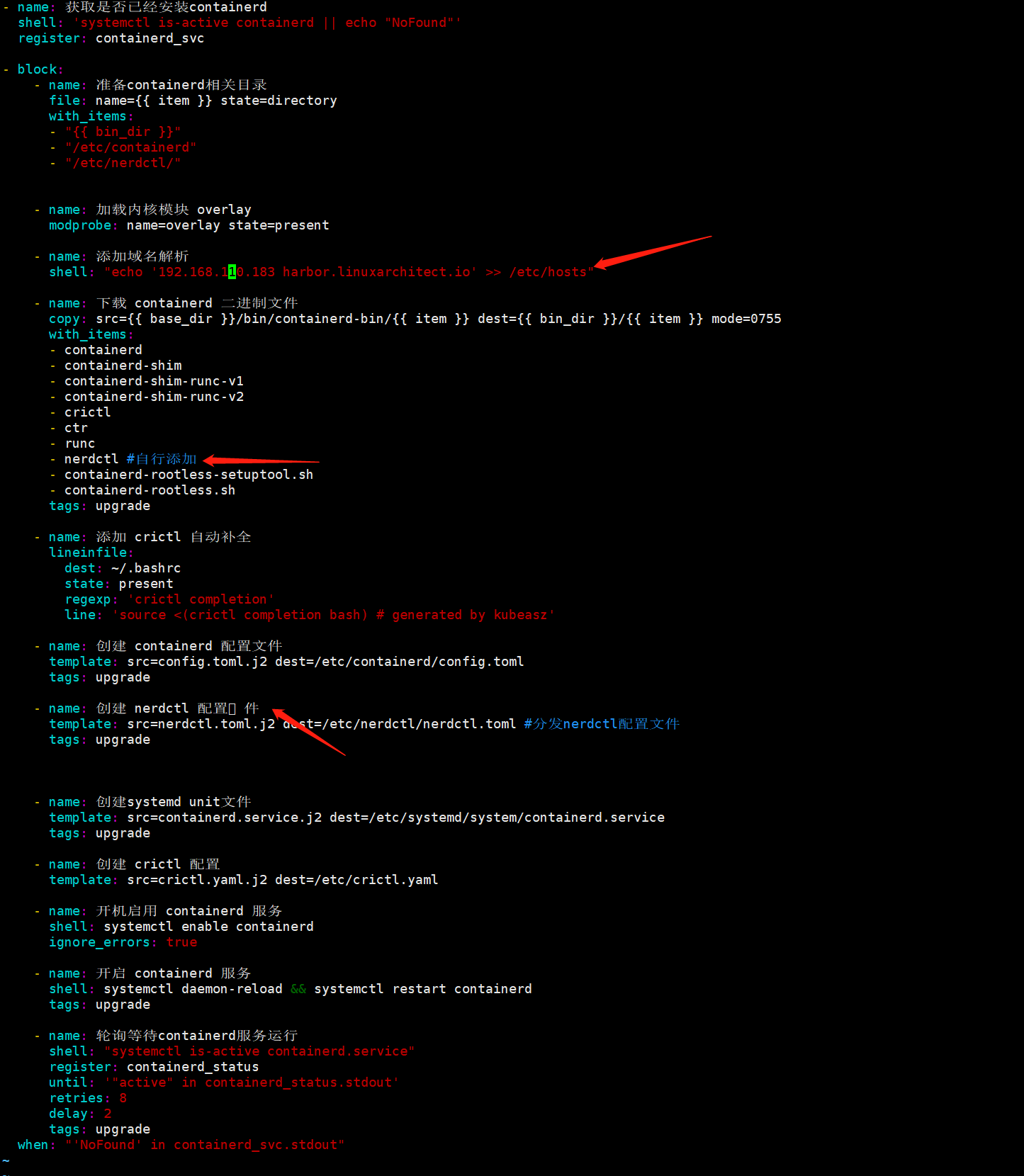
编辑/etc/kubeasz/roles/containerd/templates/config.toml.j2⾃定义containerd配置⽂件模板;

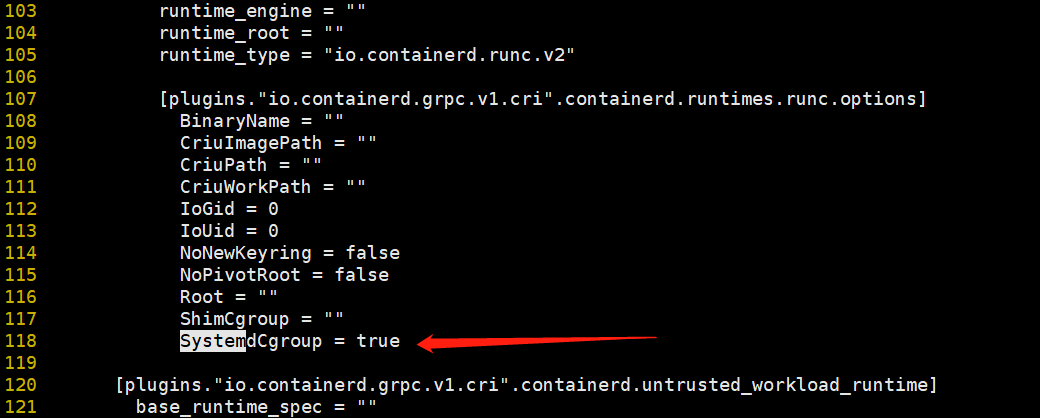
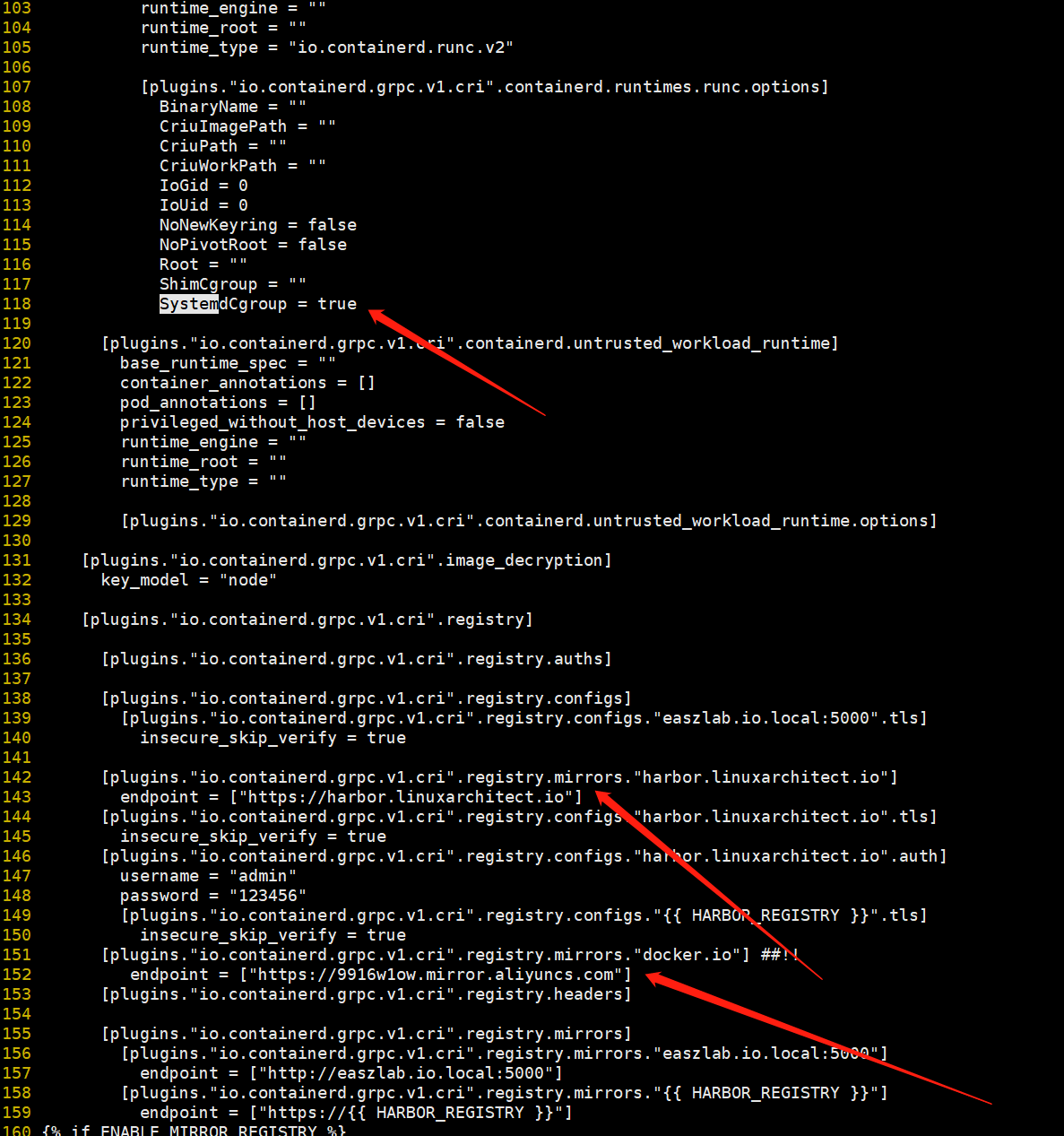
Systemcgroup这个参数在ubuntu2204上一定要改成true;否者会出现k8spod不断重启的现象;一般和kubelet保持一致;
这里可以根据自己的环境来配置相应的镜像加速地址,如上图
私有https/http镜像仓库配置下载认证
如果你的镜像仓库是一个私有(不是公开的仓库,即下载镜像需要用户名和密码的仓库)https/http仓库,添加上述配置containerd在下载对应仓库中的镜像,会拿这里配置的用户名密码去下载镜像;
配置nerdctl客户端
编辑/etc/kubeasz/roles/containerd/tasks/main.yml文件加上nerdctl配置相关任务;
在部署节点准备nerdctl工具二进制文件和依赖文件、配置文件
root@192:/etc/kubeasz/bin/containerd-bin# ll

这是原本nerdctl包 将其移动到/etc/kubeasz/bin/containerd-bin
编辑配置文件nerdctl.toml.j2
root@k8s-deploy:/etc/kubeasz/bin/containerd-bin# cat /etc/kubeasz/roles/containerd/templates/nerdctl.toml.j2
namespace = "k8s.io"
debug = false
debug_full = false
insecure_registry = true
执⾏部署容器运行时containerd
root@deploy:/etc/kubeasz# ./ezctl setup k8s-master01 03
能够在master或node节点上正常使用nerdctl上传镜像到harbor,从harbor下载镜像到本地,说明我们部署的容器运行时containerd就没有问题了;接下就可以部署k8s master节点;
部署k8s master节点
root@deploy:/etc/kubeasz# cat roles/kube-master/tasks/main.yml
上述kubeasz项目,部署master节点的任务,主要做了下载master节点所需的二进制组件,分发配置文件,证书密钥等文件、service文件,最后启动服务;如果我们需要自定义任务,可以修改上述文件来实现;
本文件可以默认 无需更改!!!
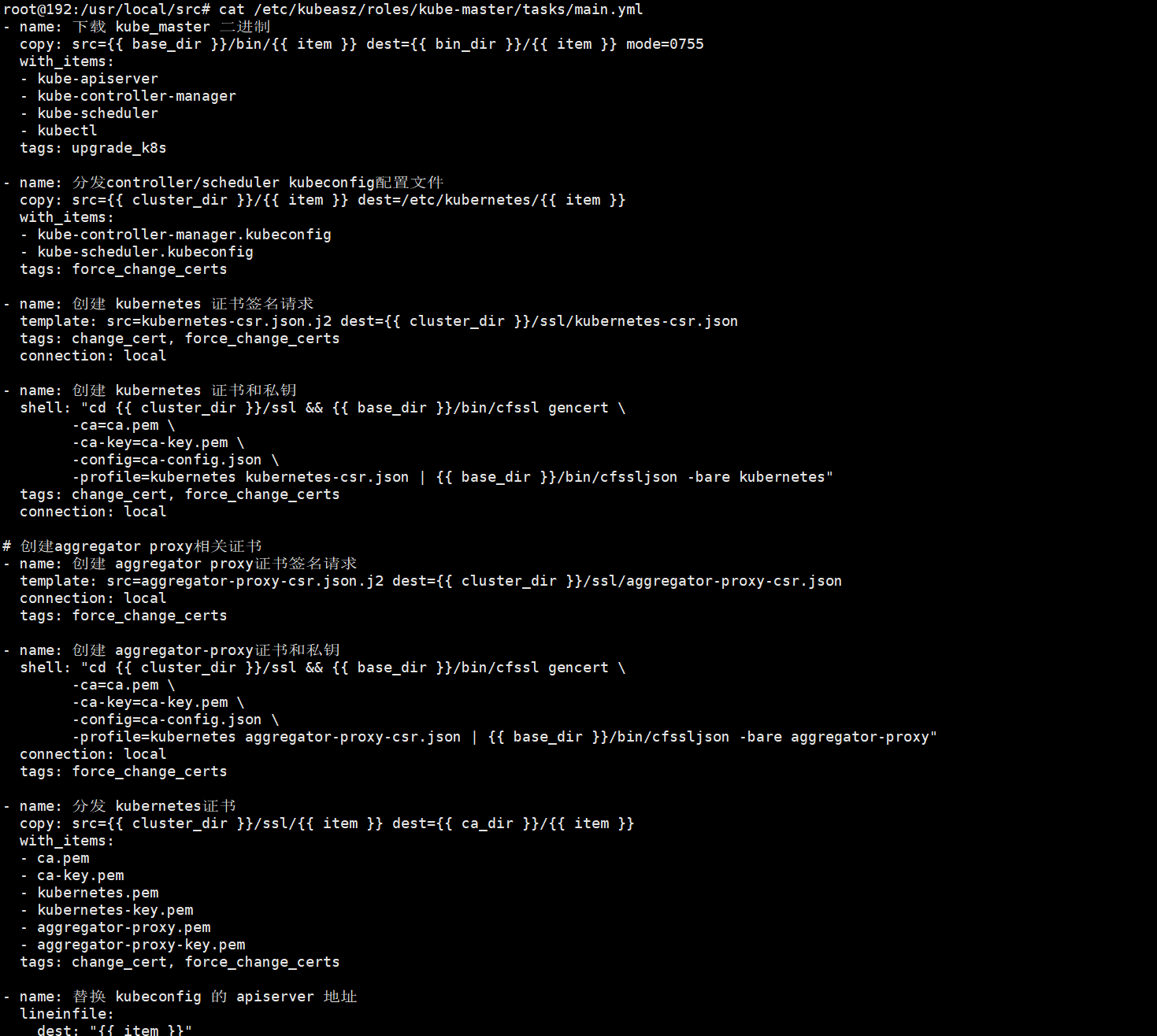
root@deploy:/etc/kubeasz# ./ezctl setup k8s-cluster01 04
检查master是否成功部署
kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.110.206 Ready,SchedulingDisabled master 2m6s v1.26.1
192.168.110.207 Ready,SchedulingDisabled master 2m6s v1.26.1
能够使用kubectl命令获取到节点信息,表示master部署成功;
部署k8s node节点
root@deploy:/etc/kubeasz# cat roles/kube-node/tasks/main.yml
无需更改~
上述是部署node节点任务,主要做了分发二进制文件,配置文件,配置kubelet、kubeproxy,启动服务;
执行部署node节点
root@deploy:/etc/kubeasz# ./ezctl setup k8s-cluster01 05
验证:在部署节点获取node信息

部署网络组件calico
查看calico所需镜像
root@deploy:/etc/kubeasz# docker images |grep calico
easzlab.io.local:5000/calico/kube-controllers v3.24.5 38b76de417d5 5 months ago 71.4MB
calico/kube-controllers v3.24.5 38b76de417d5 5 months ago 71.4MB
calico/cni v3.24.5 628dd7088041 5 months ago 198MB
easzlab.io.local:5000/calico/cni v3.24.5 628dd7088041 5 months ago 198MB
calico/node v3.24.5 54637cb36d4a 5 months ago 226MB
easzlab.io.local:5000/calico/node v3.24.5 54637cb36d4a 5 months ago 226MB
修改calico镜像标签为本地harbor地址
root@deploy:/etc/kubeasz# docker tag calico/kube-controllers:v3.24.5 harbor.harbor.linuxarchitect.io/basic/calico-kube-controllers:v3.24.5
root@deploy:/etc/kubeasz# docker tag calico/cni:v3.24.5 harbor.harbor.linuxarchitect.io/basic/calico-cni:v3.24.5
root@deploy:/etc/kubeasz# docker tag calico/node:v3.24.5 harbor.harbor.linuxarchitect.io/basic/calico-node:v3.24.5
上传calico所需镜像至本地harbor仓库

这样做的目的可以有效提高去外网下载calico镜像的时间;
修改配置yaml文件中的镜像地址为本地harbor仓库地址
root@deploy:/etc/kubeasz# grep "image:" roles/calico/templates/calico-v3.24.yaml.j2
image: harbor.ik8s.cc/baseimages/calico-cni:v3.24.5
image: harbor.ik8s.cc/baseimages/calico-node:v3.24.5
image: harbor.ik8s.cc/baseimages/calico-node:v3.24.5
image: harbor.ik8s.cc/baseimages/calico-kube-controllers:v3.24.5
执行部署calico网络插件
root@deploy:/etc/kubeasz# ./ezctl setup k8s-cluster01 06
验证calico pod是否正常运行


能够在master节点和node节点通过calicoctl 命令查询到其他节点信息,说明calico插件就部署好了;
复制部署节点上/root/.kube/config文件至master节点
root@k8s-deploy:/etc/kubeasz# scp /root/.kube/config 192.168.110.207:/root/.kube/
config 100% 6196 3.8MB/s 00:00
root@k8s-deploy:/etc/kubeasz#
这一步不是必须的,如果你要在master节点使用kubectl命令来管理集群,就把配置文件复制过去;
修改/root/.kube/config文件中apiserver地址为外部负载均衡地址
vim /root/.kube/config
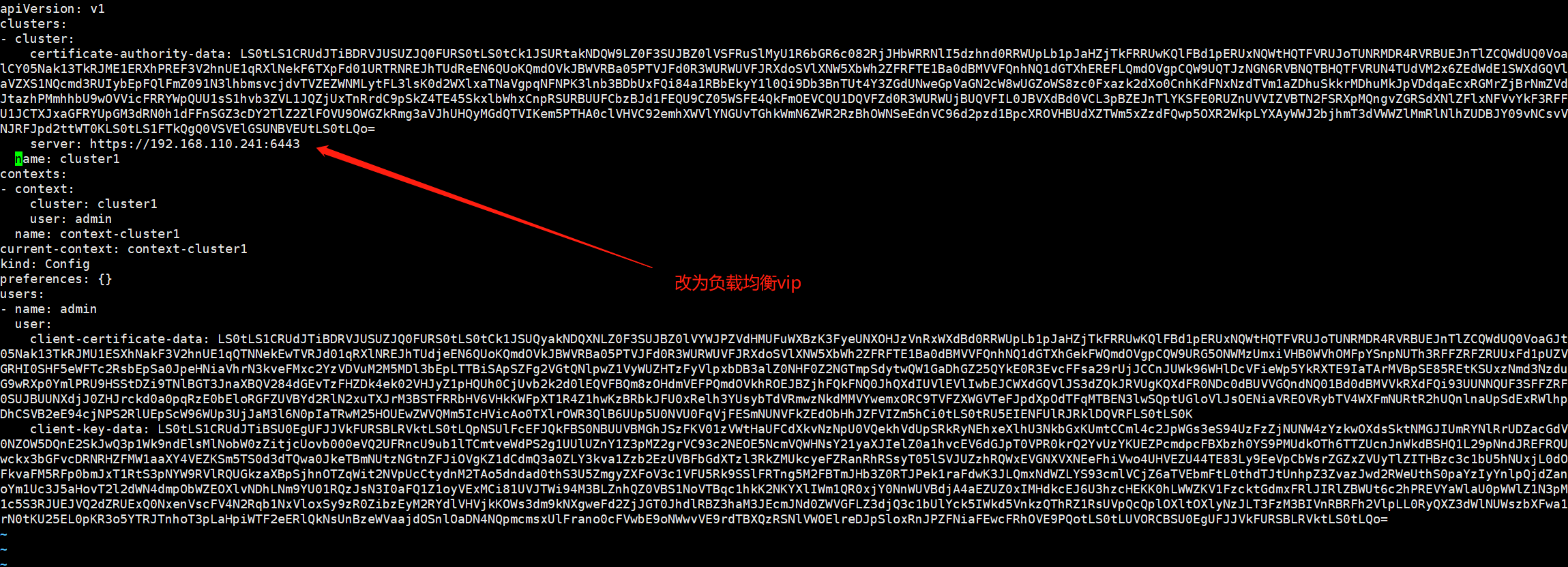
root@k8s-master01:~# kubectl run test1 --image=alpine sleep 36000
pod/test1 created
root@k8s-master01:~# kubectl run test2 --image=alpine sleep 36000
pod/test2 created
进入任意测试pod,ping其他两个pod,看看是否能够正常ping通?是否可以正常访问互联网?
可以看到pod和pod之间可以正常跨主机通信,也可以正常访问到外网,这里需要注意,现在集群还没有部署coredns,所以这里直接ping www.baidu.com是无法正常解析的;
集群节点伸缩管理
添加node节点
root@k8s-deploy:/etc/kubeasz# ./ezctl add-node k8s-master01 192.168.0.209
删除node节点使用 ezctl del-node k8s-cluster01
升级集群(建议跨小本号升级,如果跨大版本号升级请充分测试没有问题再升级)
升级前需提前下载好用于更新的master 组件二进制、node节点组件二进制以及客户端二进制
复制二进制文件至/etc/kubeasz/bin/
将官网下载好的1.24.5版二进制文件拷贝进去
root@deploy:/usr/local/src/kubernetes/server/bin# \cp kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy kubectl /etc/kubeasz/bin/
验证新二进制文件版本
root@deploy:/etc/kubeasz/bin# ./kube-apiserver --version
Kubernetes v1.26.4
root@deploy:/etc/kubeasz/bin# ./kube-controller-manager --version
Kubernetes v1.26.4
root@deploy:/etc/kubeasz/bin# ./kube-scheduler --version
Kubernetes v1.26.4
root@deploy:/etc/kubeasz/bin#
执行升级集群操作
root@deploy:/etc/kubeasz# ./ezctl upgrade k8s-master01
安装coredns组件
root@deploy:~# cat coredns-v1.9.4.yaml
查看coredns 所需镜像
root@deploy:~# cat coredns-v1.9.4.yaml|grep image:
image: coredns/coredns:1.9.4
部署节点下载镜像,修改标签,上传至harbor仓库

修改部署清单镜像地址为harbor仓库地址

root@deploy:~# kubectl apply -f coredns-v1.9.4.yaml
验证coredns的pod是否正常运行
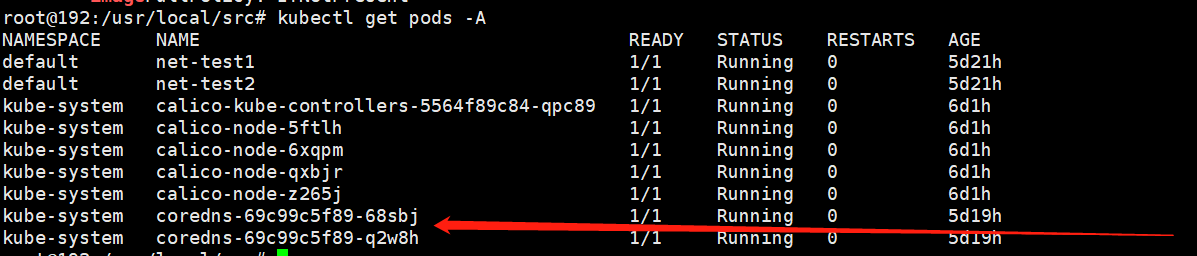
root@k8s-deploy:~# kubectl exec -it test -- sh
/ # cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 10.100.0.2
options ndots:5
/ # ping www.baidu.com
PING www.baidu.com (14.119.104.254): 56 data bytes
64 bytes from 14.119.104.254: seq=0 ttl=53 time=45.400 ms
^C
--- www.baidu.com ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 45.400/45.400/45.400 ms
/ # exit
root@k8s-deploy:~# kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 52m
kube-system kube-dns ClusterIP 10.100.0.2 <none> 53/UDP,53/TCP,9153/TCP 81s
部署coredns以后,现在容器里就可以正常解析域名;
部署官方dashboard和kubesphere(略)
至此 kubeasz搭建k8s高可用集群已完成~~