1.算法仿真效果
matlab2022a/vivado2019.2仿真结果如下:
matlab仿真:
0.5码率,H是4608×9216的矩阵。

FPGA仿真:
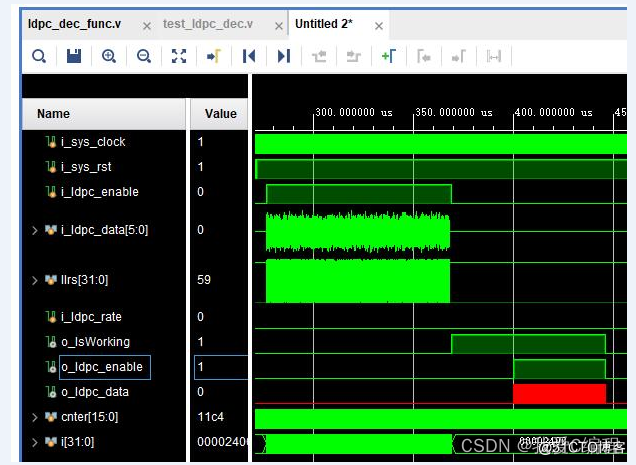
对比如下:

2.算法涉及理论知识概要
LDPC译码分为硬判决译码和软判决译码。
硬判决译码又称代数译码,主要代表是比特翻转(BF)译码算法,它的实现比较简单,但是译码性能很差。硬判决译码的基本假设是当校验方程不成立时,说明此时必定有比特位发生了错误,而所有可能发生错误的比特中不满足检验方程个数最多的比特发生错误的概率最大。在每次迭代时翻转发生错误概率最大的比特并用更新之后的码字重新进行译码。
软判决译码是一种基于概率论的译码算法,通常需要与迭代译码进行结合,才能体现成译码性能的优势,基本算法是置信传播(BP)译码算法,它的实现比代数译码方法的复杂度高很多,但译码性能非常好。
为了解决BP译码算法实现困难问题,在学术界牵起了优化算法的浪潮,对数域置信传播译码(LLR BP)算法、最小和(Min-Sum)译码算法、Normalized Min-Sum译码算法、Offset Min-Sum译码算法等相继涌现。
在迭代译码的过程中,信息调度方式分为两种:泛滥式调度和分层式调度。泛滥式调度的特点在于每一次译码迭代过程中,首先计算从变量节点到校验节点的所有软信息,然后计算从校验节点到变量节点的所有软信息。分层调度的特点是在计算每层软信息时,更新此次迭代中的相关的节点信息,用于下一层的软信息计算。
最小和译码(MS,Min-Sum)算法是以LLR BP算法译码为基础,对校验节点信息更新的表达式进行的简化,其余步骤均与LLR BP译码算法一致。
比较LLR BP译码算法和Min-Sum译码算法的校验节点信息更新过程,可以看到他们的主要区别在于LLR BP译码算法中的tanh(.)运算和加法运算在Min-Sum译码算法中被最小值和运算符号进行替换,MS译码简化了LLR BP译码算法,降低了译码算法的复杂度。
将其均匀划分为256个子矩阵,分别表示为H0,H1,…,H255,每个子矩阵大小是18×36,H的其余部分同样按此划分,划分完后的结果如图1所示。

其中最小和算法的译码过程如下所示:
基于最小和算法的译码器设计的基本思想是:根据密度进化理论优化量化译码器参数,使量化译码器能达到最高的阈值。
整个算法的流程按如下步骤进行:
第一:初始化各个变量节点的值,赋初值;
第二:判断迭代次数是否已经超过了预设的最大迭代次数,如果超过,则迭代结束;
第三:每次迭代,变量节点的信息进行更新;
第四:计算每个变量节点Vn上的L值
第五:对每个变量节点Vn,对L值进行判决,输出序列Vk,从而结束译码;
最小和算法在本质上和BP译码算法相似,此外,整个算法采用对数域进行。
以上就是整个译码算法的基本流程。
min-sum译码算法,和BP译码算法相似,即简化了原来的指数运算过程,从而减少译码器的计算量,min-sum算法来进行迭代更新, 此更新分为校验节点更新和变量节点更新。其迭代译码步骤分为两步。整个系统的总体结构如下所示:
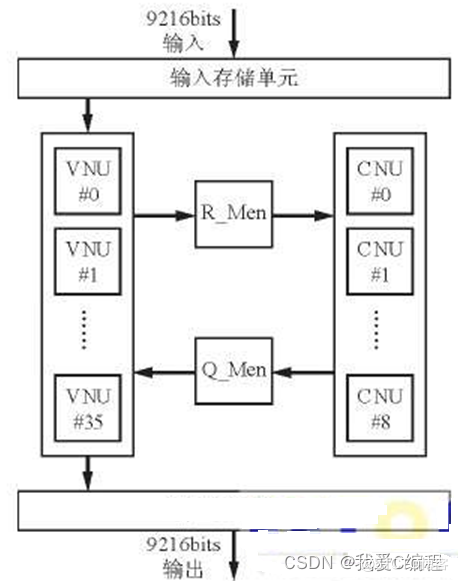
3.MATLAB/Verilog核心程序
for iteration=1:50
iteration
%horizontal step
%横向步骤:由信息节点的先验概率按置信传播算法得出各校验节点的后验概率。
for i=1:h1num %计算概率差
newh(h1i(i),h1j(i)).dqmn=newh(h1i(i),h1j(i)).qmn0-newh(h1i(i),h1j(i)).qmn1;
end
for i=1:rows
colind=find(h1i==i);%统计与校验节点相联系的第i行的数据位个数
colnum=length(colind);
for j=1:colnum
drmn=1;
for k=1:colnum
if k~=j
drmn=drmn*newh(i,h1j(colind(k))).dqmn;
end
end
newh(i,h1j(colind(j))).rmn0=(1+drmn)/2;
newh(i,h1j(colind(j))).rmn1=(1-drmn)/2;
end
end
%vertical step
%纵向步骤:由校验节点的后验概率推算出信息节点的后验概率。
for j=1:cols
rowind=find(h1j==j);
rownum=length(rowind);
for i=1:rownum
prod_rmn0=1;
prod_rmn1=1;
for k=1:rownum
if k~=j
prod_rmn0=prod_rmn0*newh(h1i(rowind(k)),j).rmn0;
prod_rmn1=prod_rmn1*newh(h1i(rowind(k)),j).rmn1;
end
end
const1=pl0(j)*prod_rmn0;
const2=pl1(j)*prod_rmn1;
newh(h1i(rowind(i)),j).alphamn=1/( const1 + const2 ) ;
newh(h1i(rowind(i)),j).qmn0=newh(h1i(rowind(i)),j).alphamn*const1;
newh(h1i(rowind(i)),j).qmn1=newh(h1i(rowind(i)),j).alphamn*const2;
%update pseudo posterior probability
%更新伪后验概率
const3=const1*newh(h1i(rowind(i)),j).rmn0;
const4=const2*newh(h1i(rowind(i)),j).rmn1;
alpha_n=1/(const3+const4);
newh(h1i(rowind(i)),j).qn0=alpha_n*const3;
newh(h1i(rowind(i)),j).qn1=alpha_n*const4;
%tentative decoding
%译码尝试,对信息节点的后验概率作硬判决
if newh(h1i(rowind(i)),j).qn1>0.5
vhat(j)=1;
else
vhat(j)=0;
end
end
end