什么是Xpah
官方:XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航
【XPath 使用路径表达式来选取 XML 文档中的节点或者节点集】
Xpath的缺点
Xpath 这种定位方式, webdriver会将整个页面的所有元素进行扫描以定位我们所需要的元素, 这是个非常费时的操作, 如果脚本中大量使用xpath做元素定位的话, 脚本的执行速度可能会稍慢。
Xpath在UI自动化中的应用场景
在Web UI自动化中,其实用Xpath的定位元素的优先级并不高,但它是万能的;所以如果用其他方式无法定位时,可以用Xpath进行定位
在App UI自动化中,Xpath是唯一可以定位元素的方式

Xpath常见的表达式
|
表达式
|
描述
|
|---|---|
| nodename | 选取此节点的所有子节点,类似 css 中的标签选择器 |
| / | 从根节点选取,也就是当前节点的最顶层(默认情况下当前节点是 html 最顶层,若从某元素开始,当前节点为此元素) |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,代表任意类型的标签 |
Xpath定位方式的简单例子
- 首先我们访问:https://www.baidu.com/
- 然后按F12,选中Elements,按Ctrl+F
- 将下面的表达式放进去,逐一验证匹配出来的元素是否一致(建议实操)
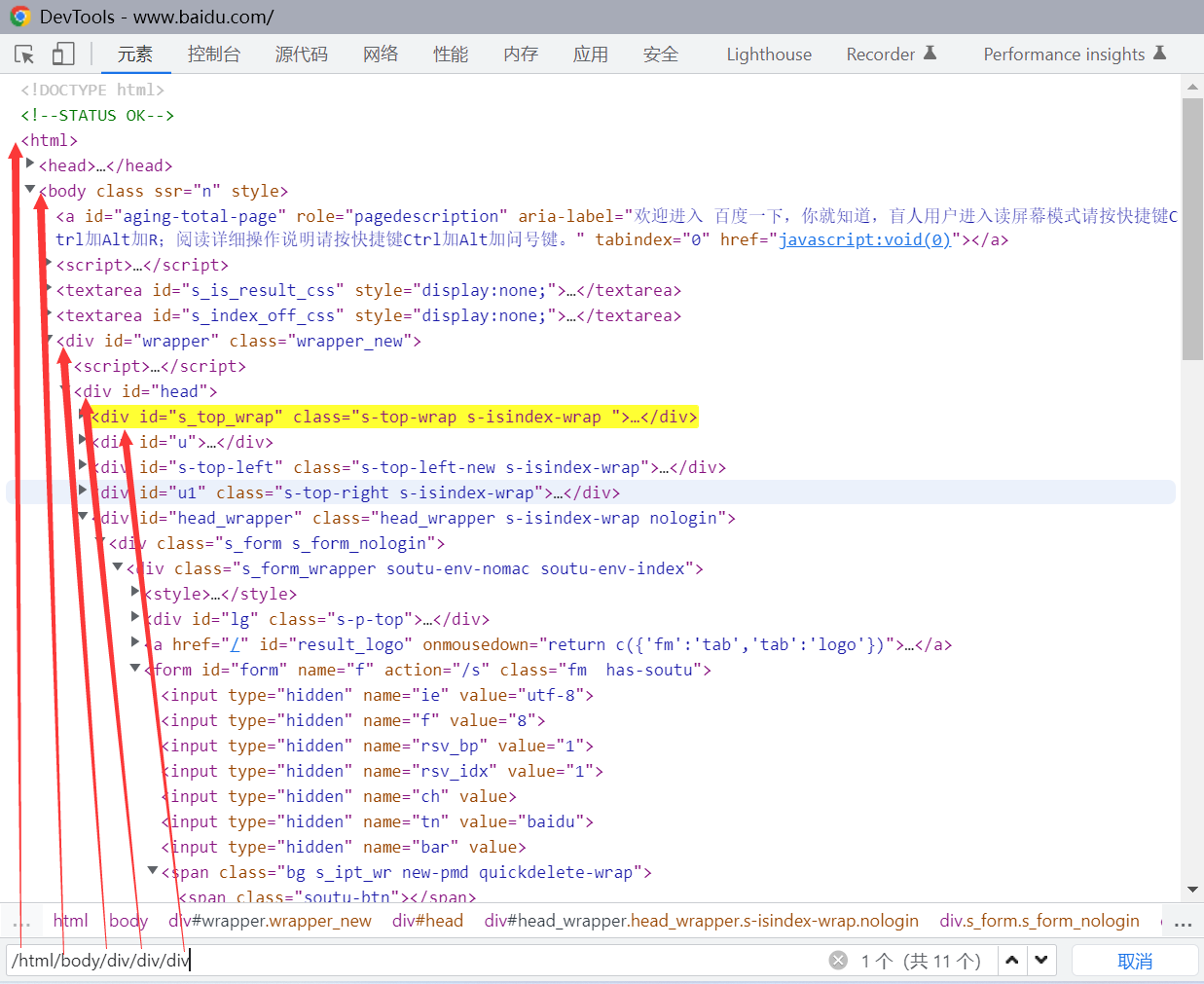
绝对路径定位
作用:从顶层 html 开始往下找,像文件夹一样写的完整路径;它是以 / 开头的,如: /html/body/div/div/div
缺点:一旦页面结构发生改变,路径也随之失效,必须重新定位。 所以不推荐使用绝对路径的写法
相对路径定位
作用:相对路径 以"//" 开头, 让xpath 从文档的任何元素节点开始解析(也就是说每个节点都作为起点找一下),推荐用这个
和绝对路径的区别:绝对路径 以 "/" 开头,让xpath 从文档的根节点开始解析
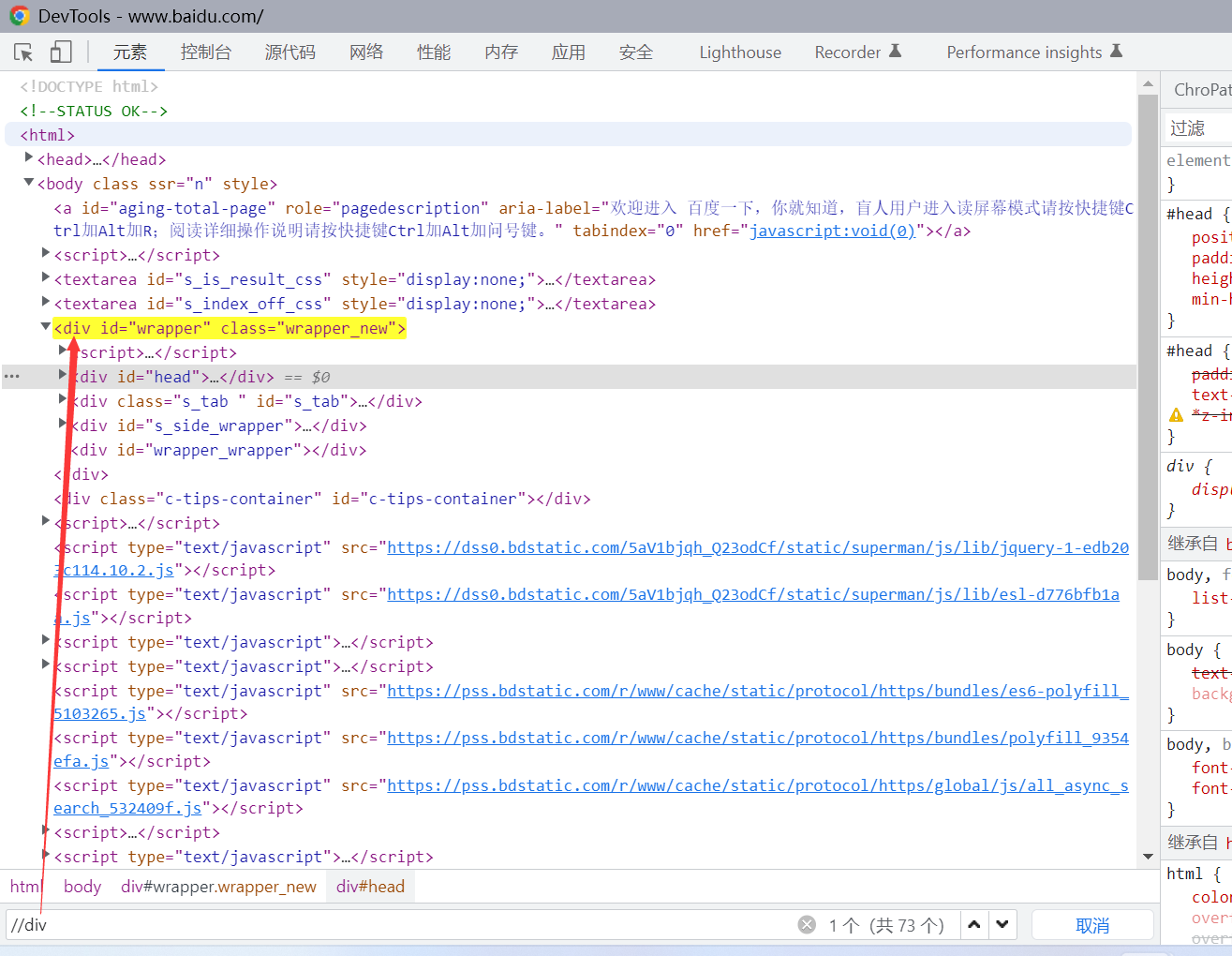
索引定位
跟Python的列表一样,通过[ 1 ]下标去找,注意!它是从1开始的
如: //input[2] ,表示任意节点下的第二个 input 标签
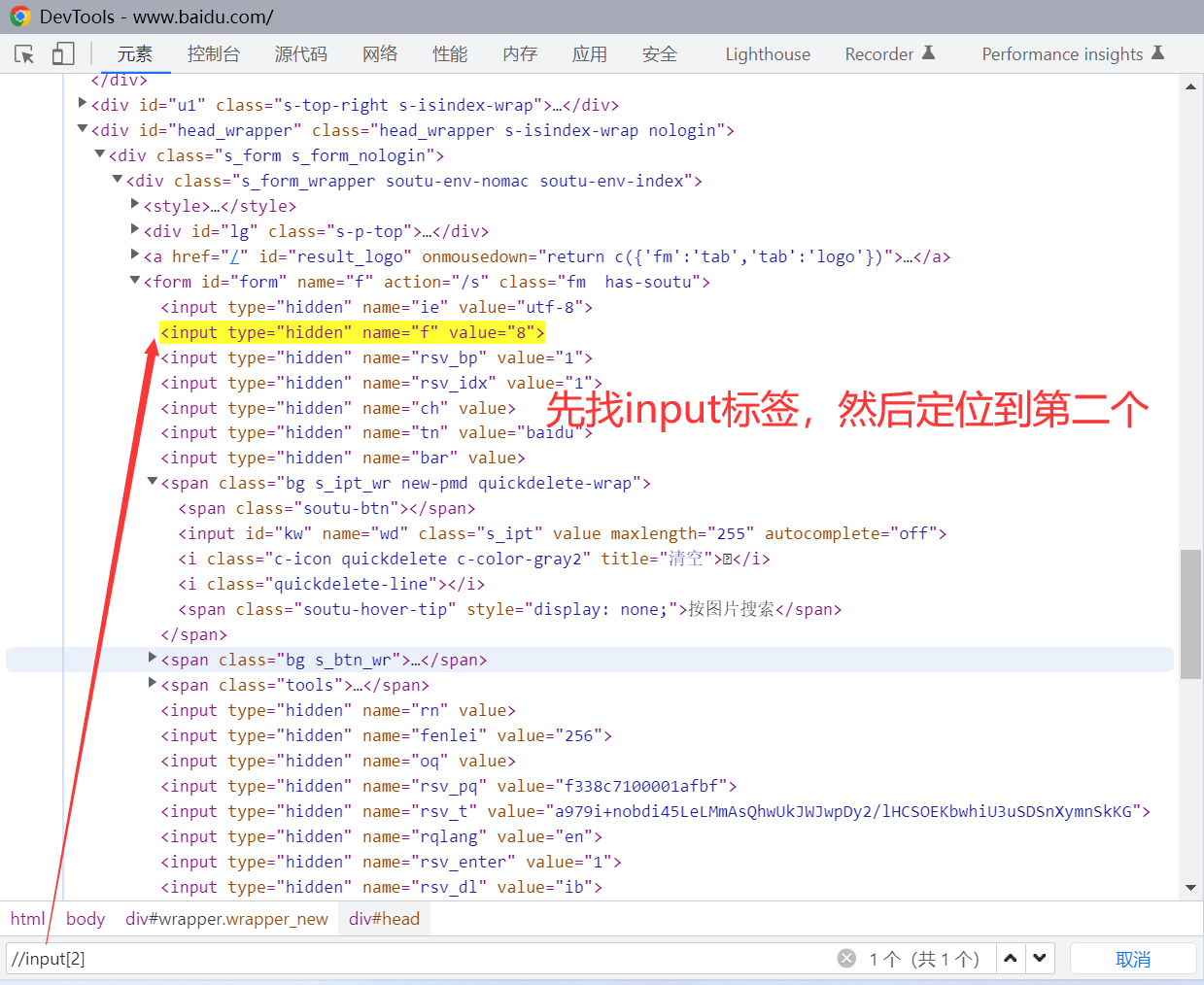
通过相对路径、标签、属性值、通配符定位
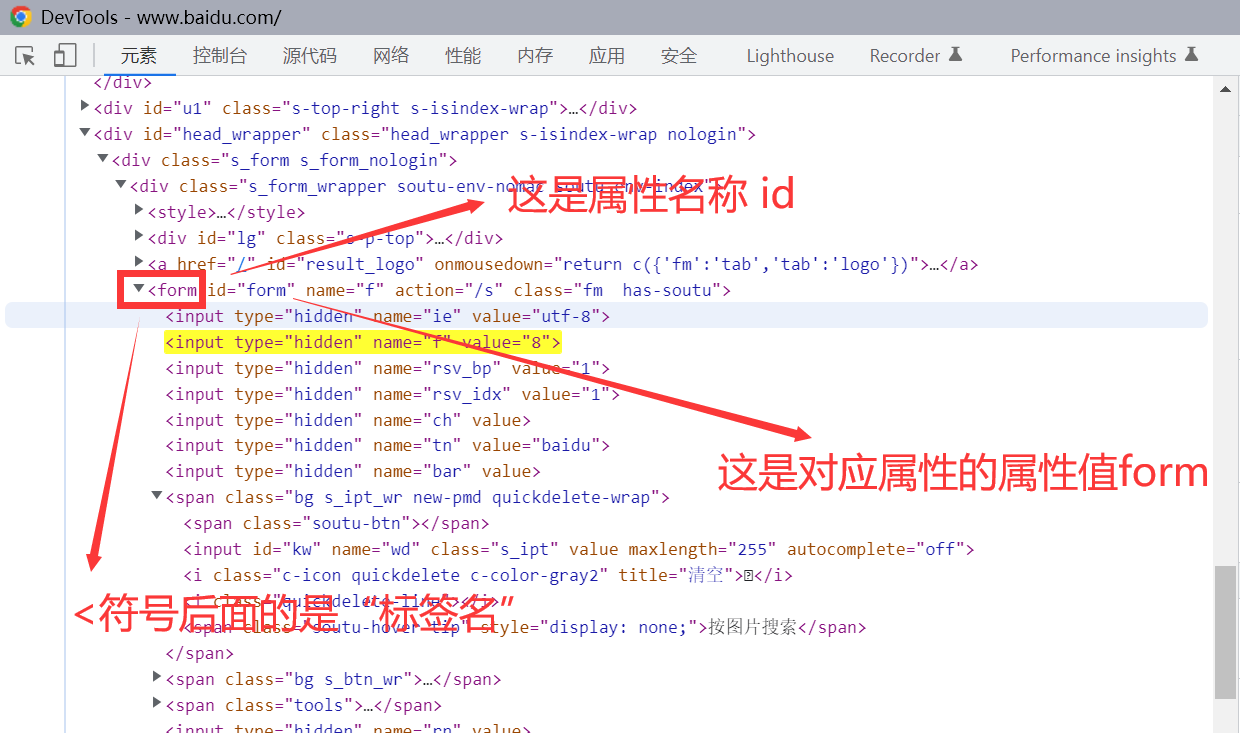
| Xpath路径表达式 | 解释 |
| 只通过绝对路径、标签定位 | |
| /html/body | 查找html节点下的body标签 |
| /html/body/div/div[@class="s_tab "] | 查找html节点下的body标签下的div标签下的class="s_tab "的div标签 |
| /html//div | 查找html节点下的div标签 |
| /html//div/ul//li | 查找html节点下的div标签下的ul标签下的li标签 |
| 通过相对路径、标签、属性值定位 | |
| //div[@class="s_tab "] | 查找全部节点中 class="s_tab " 的div标签 |
| //div[@class="s_tab_inner"] | 查找全部节点中 class="s_tab_inner" 的div标签 |
| //div[@class="s_tab_inner"]/b[@class="cur-tab"] | 先查找全部节点中 class="s_tab_inner" 的div标签,然后找下级节点中 class="cur-tab" 的b标签 |
| 通过标签、属性值、通配符、下标定位 | |
| //* | 代表任意类型的标签 |
| //*[@class="s-top-more"] | 查找class="s-top-more"的所有标签 |
| //*[@id="s-top-left"] | 查找id="s-top-left"的所有标签 |
| //*[@id="s-top-left"]/a[2] | 查找id="s-top-left"的所有标签后,找下一级节点中有a标签的元素,取第二个 |
| //*[@id="s-top-left"]//a[2] | 查找id="s-top-left"的所有标签后,找下级节点中有a标签的元素,取第二个 |
| 通过文本text()、部分文本定位 contains() | //标签名称[text()='文本名称'] //标签名称[contains(text(),'文本名称')] |
| //span[text()='设置'] | 找页面中文本为‘设置’的span标签 |
| //span[contains(text(),'设置')] | 找页面中文本含有‘设置’的span标签 |
Xpath一些常用函数和特殊写法
| 表达式 | 描述 |
| //title[@*] | 选取所有带有属性的 title 元素 |
| 条件表达式and、or、not | |
| //input[@id="su" and @class="bg s_btn"] | 找到id="su"和class="bg s_btn"的input元素 |
| //input[@id="su" or @class="bg s_btn"] | 找到id="su"或class="bg s_btn"的input元素 |
| //input[@id="su" and not(@class="bg s_btn1")] | 找到id="su"且class!="bg s_btn1"的input元素 |
| 模糊匹配函数starts-with、contains | |
| //*[starts-with(@id,"s")] | 找到id开头为 s 的任意元素 |
| //*[ends-with(@id,"s")] | 找到id结尾为 s 的任意元素(是xpath 2.0的语法,但是目前浏览器还不支持) |
| 定位函数position | |
| //*[contains(@id,"s")]/li[position()=3] | 找到第三个 li |
| //*[contains(@id,"s")]/li[position()<=2] | 找到前两个 li |
Xpath的其他定位方式-轴定位
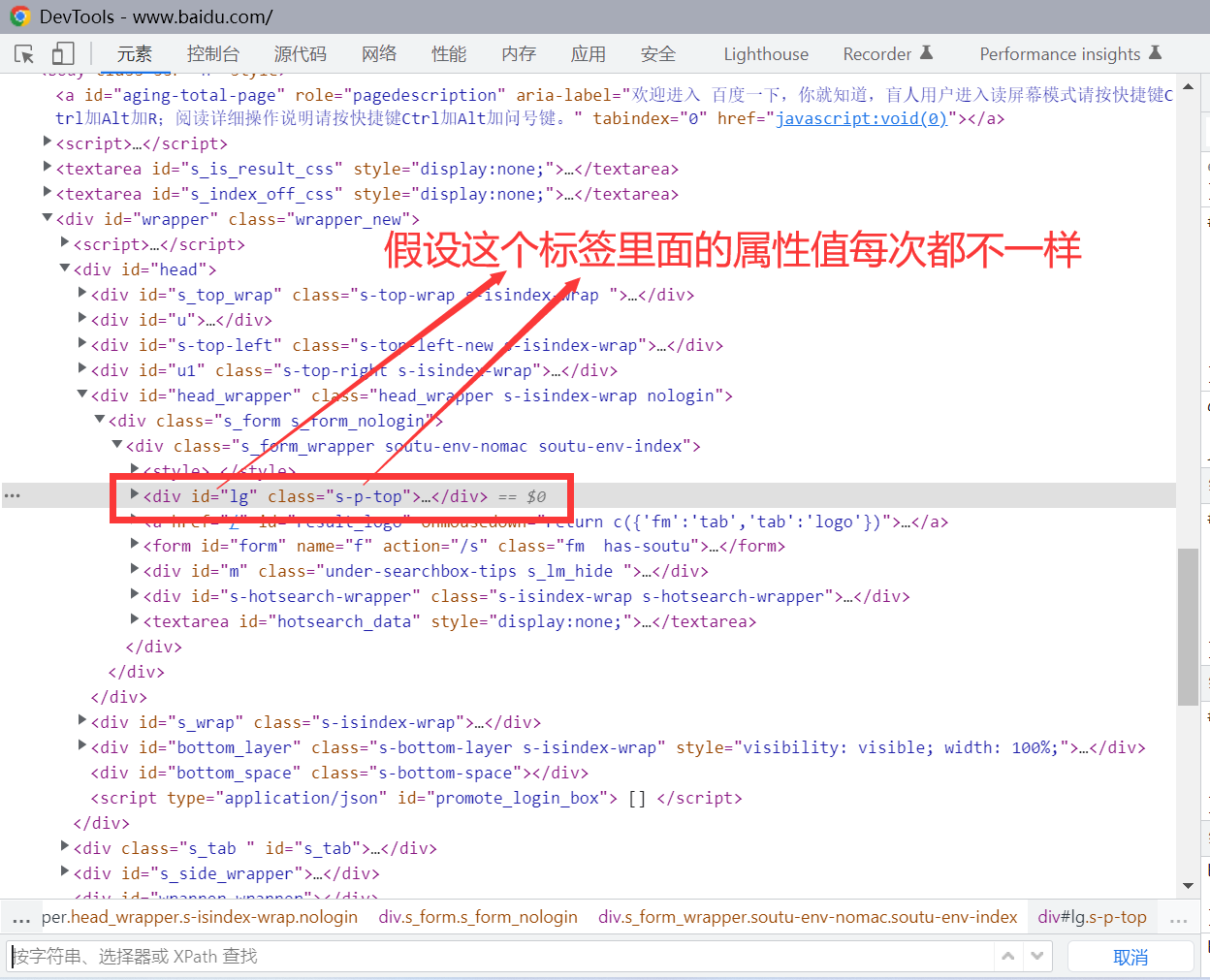
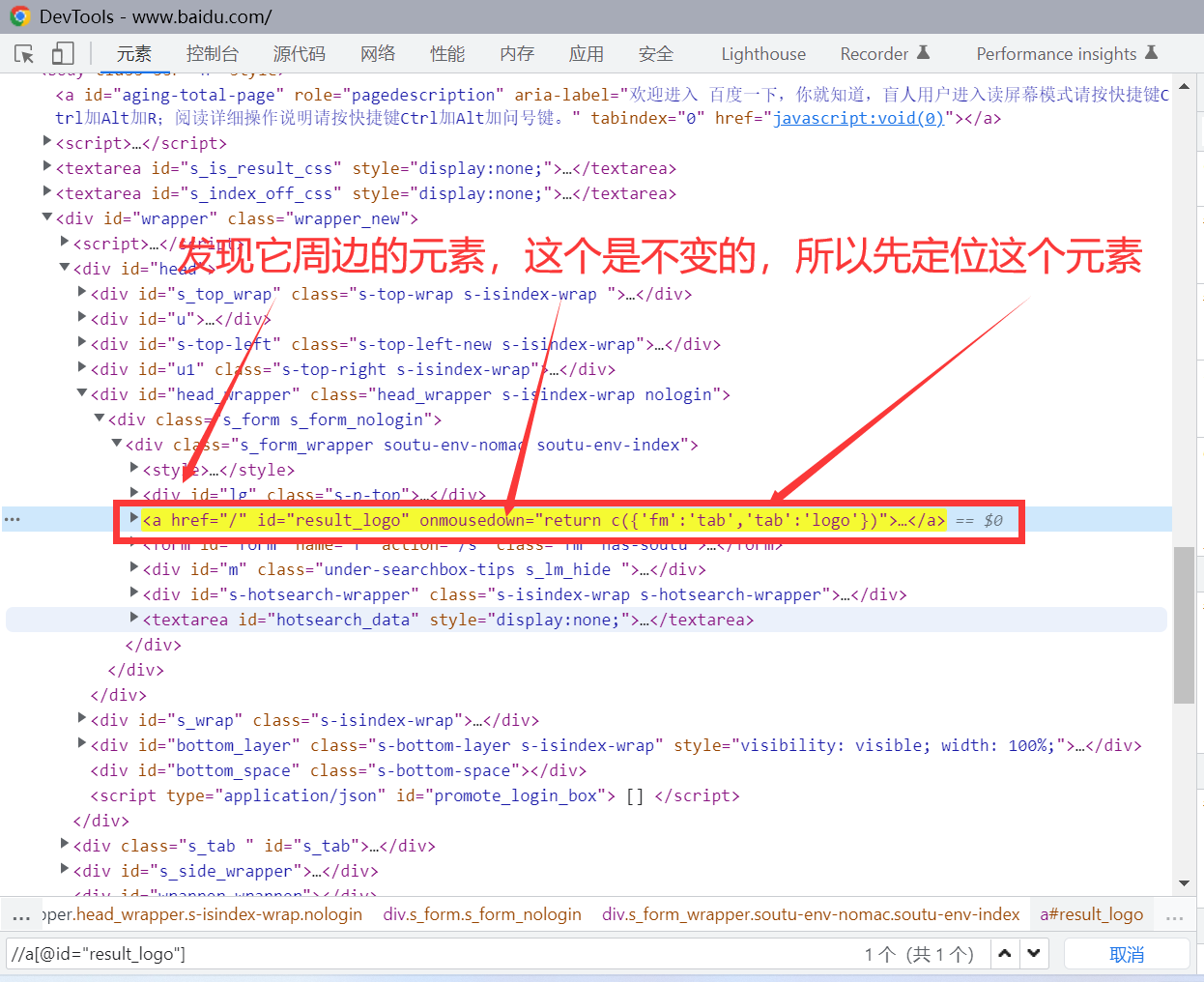
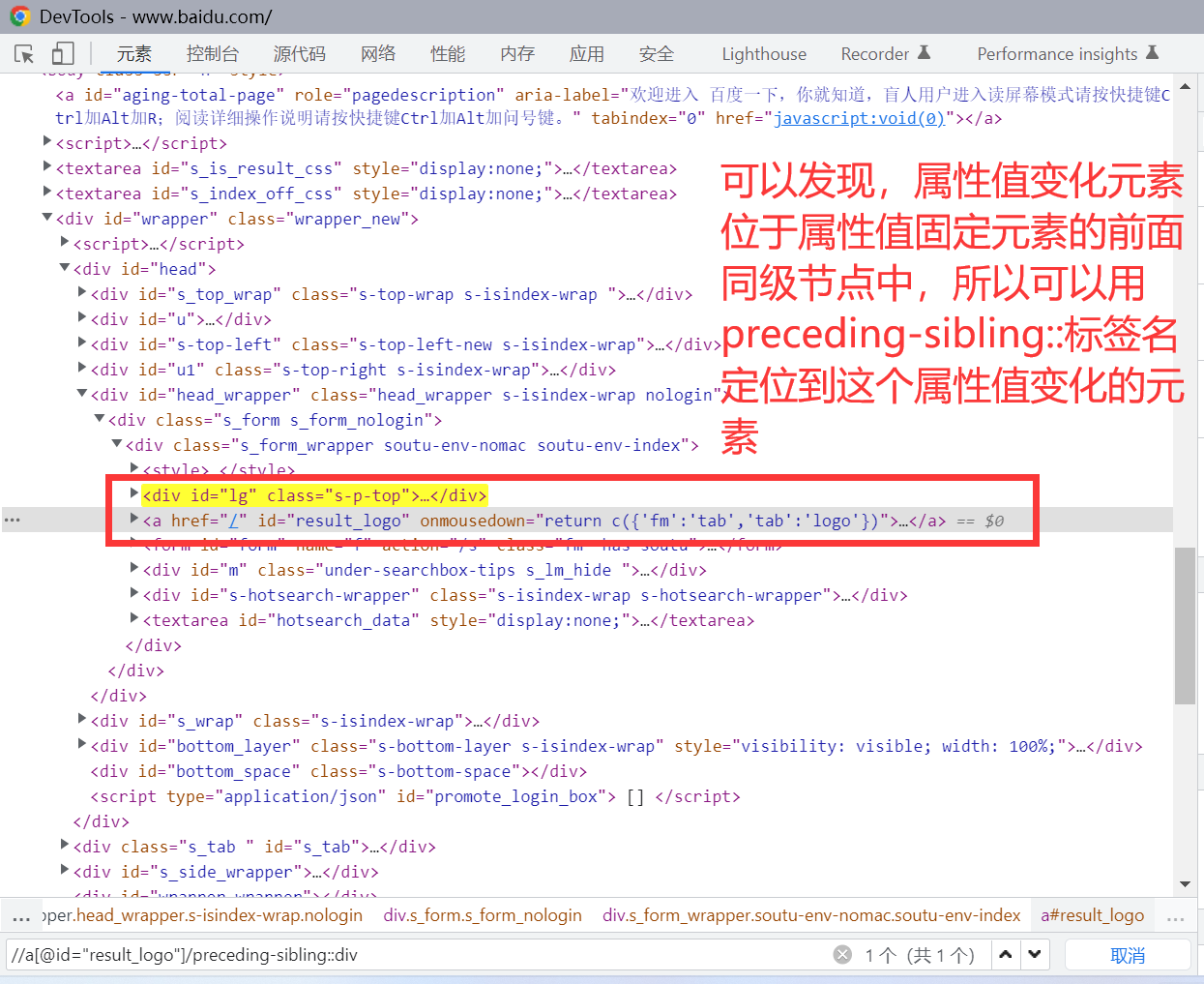
应用场景:定位某个元素时,它的属性值不是固定的,会变化的,这就需要这种定位
操作:先定位该元素周边某个属性值不变的元素,然后看这个不变的元素跟你定位的这个元素是什么关系(父级、子级、同级),写相应的xpath表达式
|
定位方式
|
描述
|
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等) |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身 |
| child | 选取当前节点的所有子元素【/可替代,略显多余】 |
| descendant | 选取当前节点的所有后代元素(子、孙等)【//可替代,略显多余】 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身 |
| following | 选取当前节点的结束标签之后的所有节点 |
| following-sibling | 选取当前节点之后的所有同级节点 |
| parent | 选取当前节点的父节点【../可替代,略显多余】 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点 |
| preceding-sibling | 选取当前节点之前的所有同级节点 |
实际例子