有序树、无序树的概念
有序树和无序树,树中结点的各子树从左到右是有次序的,不能互换,称该树为有序树,否则称为无序树。
树/二叉树的性质
树的性质

常用的只有第一个
二叉树的性质
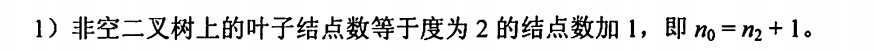
常用公式也只有这一个
二叉树的存储
一般分为顺序存储与链式存储
要求顺序存储能默写
顺序存储:
typedef struct TreeNode {
int data; //结点中的数据元素
bool isEmpty; //结点是否为空
} TreeNode;
//初始化顺序存储的二叉树,所有结点标记为"空"
void InitSqBiTree (TreeNode t[], int length) {
for (int i=0; i<length; i++){
t[i].isEmpty=true;
}
}
int main(){
TreeNode t[100]; //定义一棵顺序存储的二叉树
InitSqBiTree(t, 100); //初始化为空树
//...
}
//判断下标为 index 的结点是否为空
bool isEmpty(TreeNode t[], int length, int index){
if (index >= length || index < 1) return true; //下标超出合法范围
return t[index].isEmpty;
}
//找到下标为 index 的结点的左孩子,并返回左孩子的下标,如果没有左孩子,则返回 -1
int getLchild(TreeNode t[], int length, int index){
int lChild = index * 2; //如果左孩子存在,则左孩子的下标一定是 index * 2
if (isEmpty(t, length, lChild)) return -1; //左孩子为空
return lChild;
}
//找到下标为 index 的结点的右孩子,并返回右孩子的下标,如果没有右孩子,则返回 -1
int getRchild(TreeNode t[], int length, int index){
int rChild = index * 2 + 1; //如果右孩子存在,则右孩子的下标一定是 index * 2 + 1
if (isEmpty(t, length, rChild)) return -1; //右孩子为空
return rChild;
}
//找到下标为 index 的结点的父节点,并返回父节点的下标,如果没有父节点,则返回 -1
int getFather(TreeNode t[], int length, int index){
if (index == 1) return -1; //根节点没有父节点
int father = index / 2; //如果父节点存在,则父节点的下标一定是 index/2,整数除法会自动向下取整
if (isEmpty(t, length, father)) return -1;
return father;
}
线索二叉树
1、先序遍历的线索二叉树不能直接找到度为2的前驱
2、后序遍历的线索二叉树不能直接找到度为2的后继
树和图的存储
二叉树的存储一般采用链表或数组
一般的树的存储手段有三种
1、双亲表示法
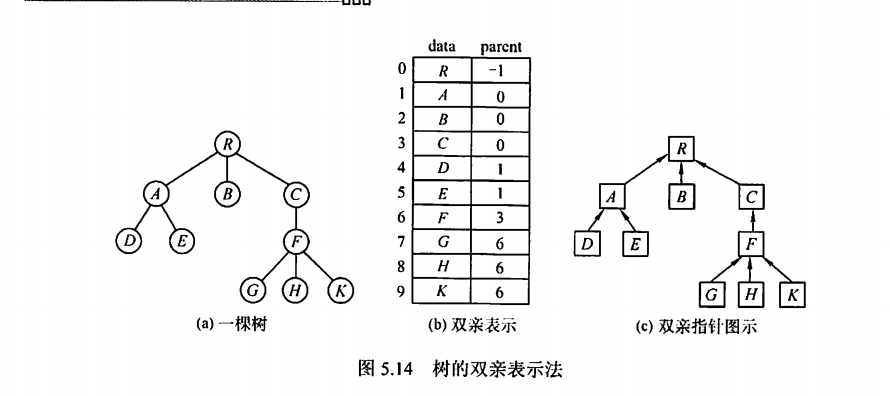
2、孩子表示法
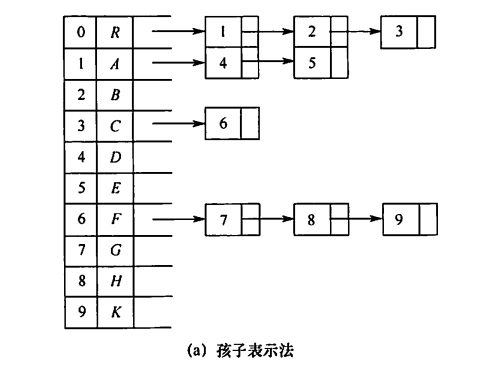
有点像邻接表
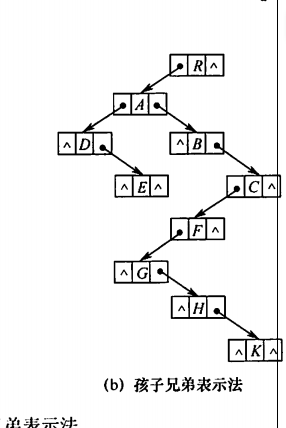
3、孩子兄弟表示法
哈夫曼树的一些性质
带权路径长度的概念
在许多应用中,树中结点常常被赋予一个表示某种意义的数值,称为该结点的权。从树的根到任意结点的路径长度(经过的边数)与该结点上权值的乘积,称为该结点的带权路径长度。树中所有叶结点的带权路径长度之和称为该树的带权路径长度,记为
\[\mathrm{WPL}=\sum_{i=1}^{n}w_{i}l_{i}
\]
其中带权路径长度(WPL)最小的二叉树称为哈夫曼树
哈夫曼树不一定是是一棵完全二叉树
树中一定没有度为1的结点
树中两个权值最小的结点一定是兄弟结点
树中任一非叶结点的权值一定不小于下一层任一结点的权值
计算机网络中A,B,C类网络的划分以及动态子网的划分,其思想与哈夫曼编码如出一辙
并查集
自从大纲改版还没考过,感觉今年很可能考,这是个重点!最次也要会默写朴素算法的并查集
代码如下(涉及了路径压缩、小树合并到大树等优化策略)
#include <stdio.h>
#define MAXSIZE 50
int UFSets[MAXSIZE];
void InitUFSets(int S[]){
for(int i=0;i<MAXSIZE;i++){
S[i] = -1;
}
}
int find(int S[],int x){
if(S[x] == -1) return x; // -1说明到底了
return find(S,S[x]);
}
int pathCompFind(int S[],int x){ // 路径压缩策略优化Find 操作
if(S[x] >= 0){
S[x] = find(S,S[x]);
return S[x];
}
return x;
}
bool UnionElem(int S[],int elem1,int elem2){ //王道书上是直接合并的root,而不是元素成员
int first = find(S,elem1);
int second = find(S,elem2);
if(first != second){
printf("%d -- %d\n",first,second);
S[second] = first;
return 1;
}
return 0;
}
bool UnionRoot(int S[],int Root1,int Root2){
if(Root1 == Root2) return 0; //比较两个根是否来自同一集合
S[Root2] = Root1; // 将根Root2连接到Root1上
return 1;
}
bool optUnionRoot(int S[],int Root1,int Root2){
if(Root1 == Root2) return 0;
if(S[Root2] > S[Root1]){ // Root2 结点数更少 // 因为初始化的时候S的值全为 -1 所以 若S[Root1]与S[Root2]相加后为更小的负数
//较小的树,树较大,这也是为什么 S[Root1] >= S[Root2]时 却把Root2合并到Root1中的原因
S[Root1] += S[Root2]; // 累加节点个数
S[Root2] = Root1;
}else{
S[Root2] += S[Root1];
S[Root1] = Root2;
}
return 1;
}
void debug(){
for(int i=0;i<MAXSIZE;i++){
printf("%d ",UFSets[i]);
}
puts("");
}
int main(){
InitUFSets(UFSets);
int arr[100] = {0,1,2,3,4,5,6,7,8,9};
for(int i=0;i<=10;i++){
UnionElem(UFSets,arr[i*2],arr[i*2+1]);
// 0 -- 1
// 2 -- 3
// 4 -- 5
// 6 -- 7
// 8 -- 9
}
UnionElem(UFSets,1,3);
UnionElem(UFSets,5,7);
// 0 -- 1
// 2 -- 3
// 4 -- 5
// 6 -- 7
// 8 -- 9
// 0 -- 2
// 4 -- 6
UnionElem(UFSets,1,6);
UnionElem(UFSets,2,7);
// debug();
return 0;
}
朴素算法代码如下
#define SIZE 13
int UFSets[SIZE]; //用一个数组表示并查集
//初始化并查集
void Initial(int S[]){
for(int i=0;i<SIZE;i++)
S[i]=-1;
}
//Find “查”操作,找x所属集合(返回x所属根结点)
int Find(int S[],int x){
while(S[x]>=0) //循环寻找x的根
x=S[x];
return x; //根的S[]小于0
}
//Union “并”操作,将两个集合合并为一个
void Union(int S[],int Root1,int Root2){
//要求Root1与Root2是不同的集合
if(Root1==Root2) return;
//将根Root2连接到另一根Root1下面
S[Root2]=Root1;
}
树、森林、二叉树遍历对应关系
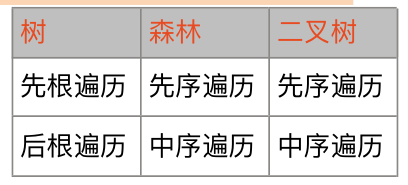
这里需要注意的是
- 树的后根遍历实际上就是树的中序遍历,只不过写法的问题
- 森林的中序遍历实际上是对森林后序遍历,其结果等价于对应二叉树的中序遍历,不知道为什么给起了一个中序遍历的名字,可能是其无法进行真正的中序遍历的原因吧
如图:
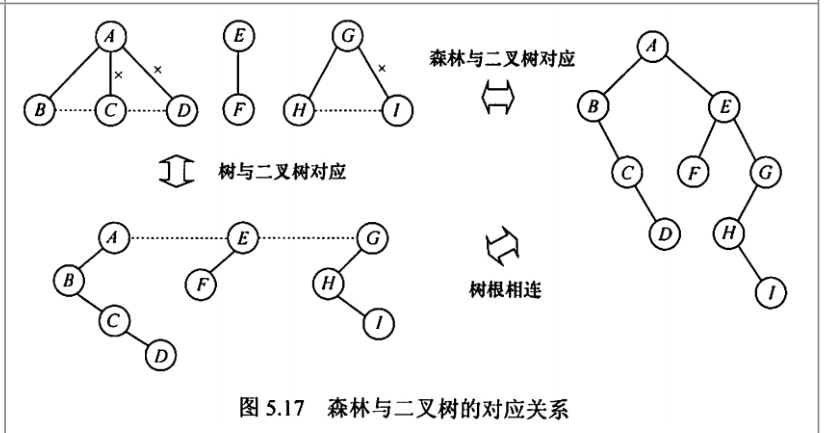
对森林中序遍历(实质上是后序遍历)可得到 BCDAFEHIG ,等价于对二叉树的中序遍历