Beyond Hello World, A Computer Vision Example
Start Coding
导入TensorFlow
import tensorflow as tf
print(tf.__version__)
从 tf.keras 数据集 API 中获取时尚 MNIST 数据并加载:
mnist = tf.keras.datasets.fashion_mnist
在该对象上调用 load_data 会得到两组列表,这两组列表分别是包含服装项目及其标签的图形的训练值和测试值。
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
打印一张训练图像和一个训练标签:
import numpy as np
np.set_printoptions(linewidth=200)
import matplotlib.pyplot as plt
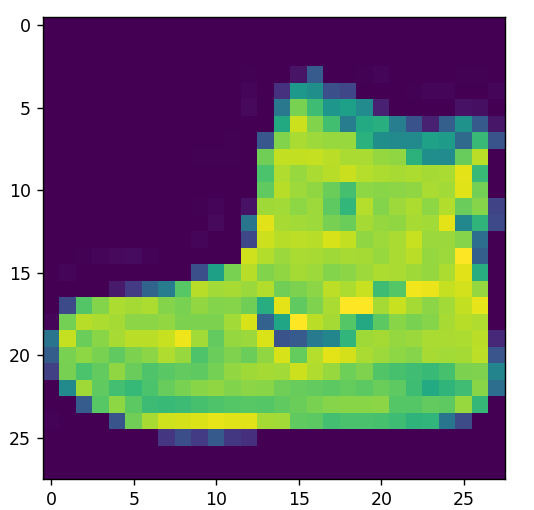
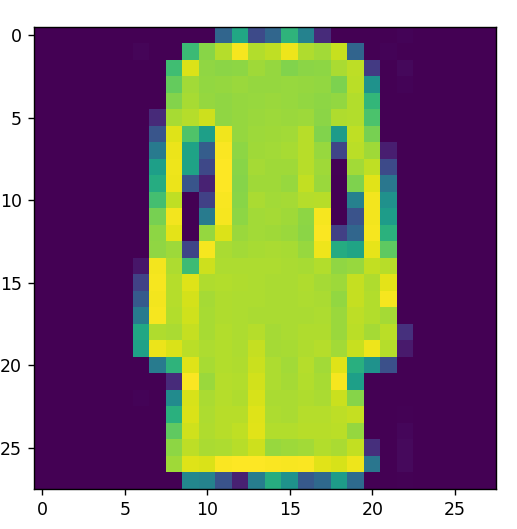
plt.imshow(training_images[0])
print(training_labels[0])
print(training_images[0])
plt.show()
index[0]: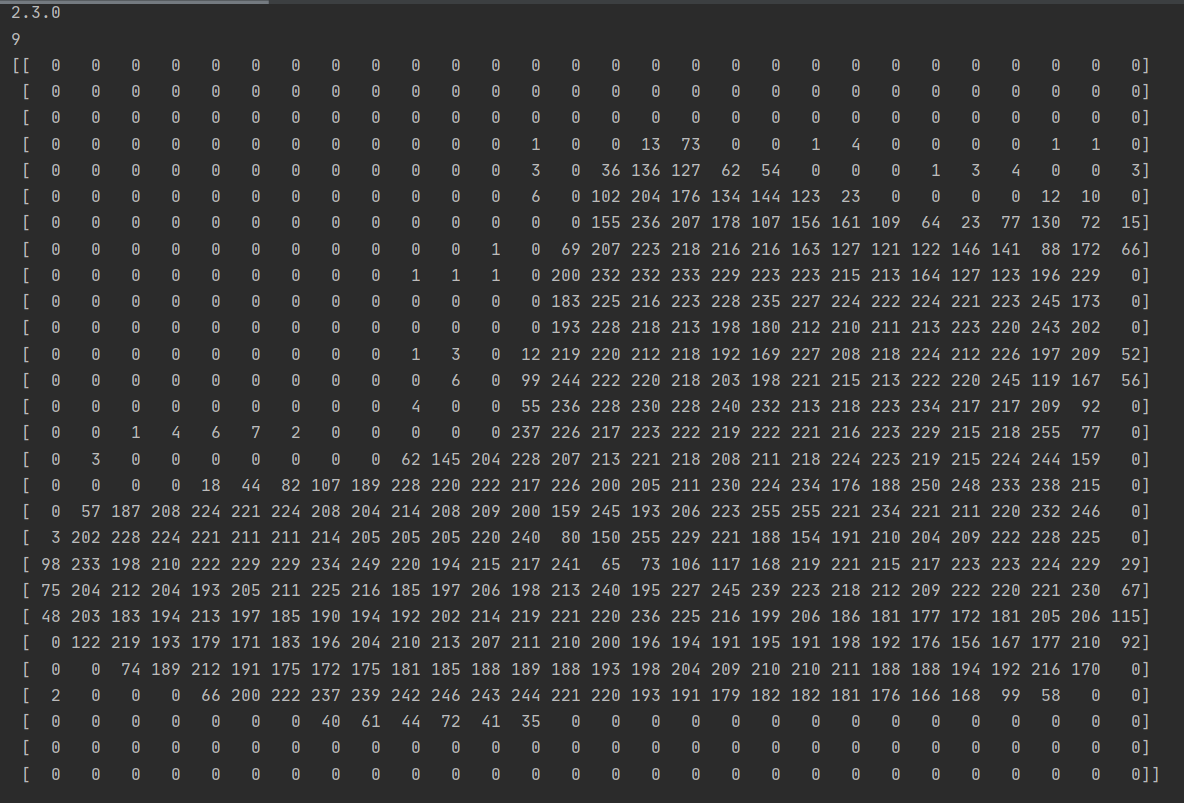
index[49]: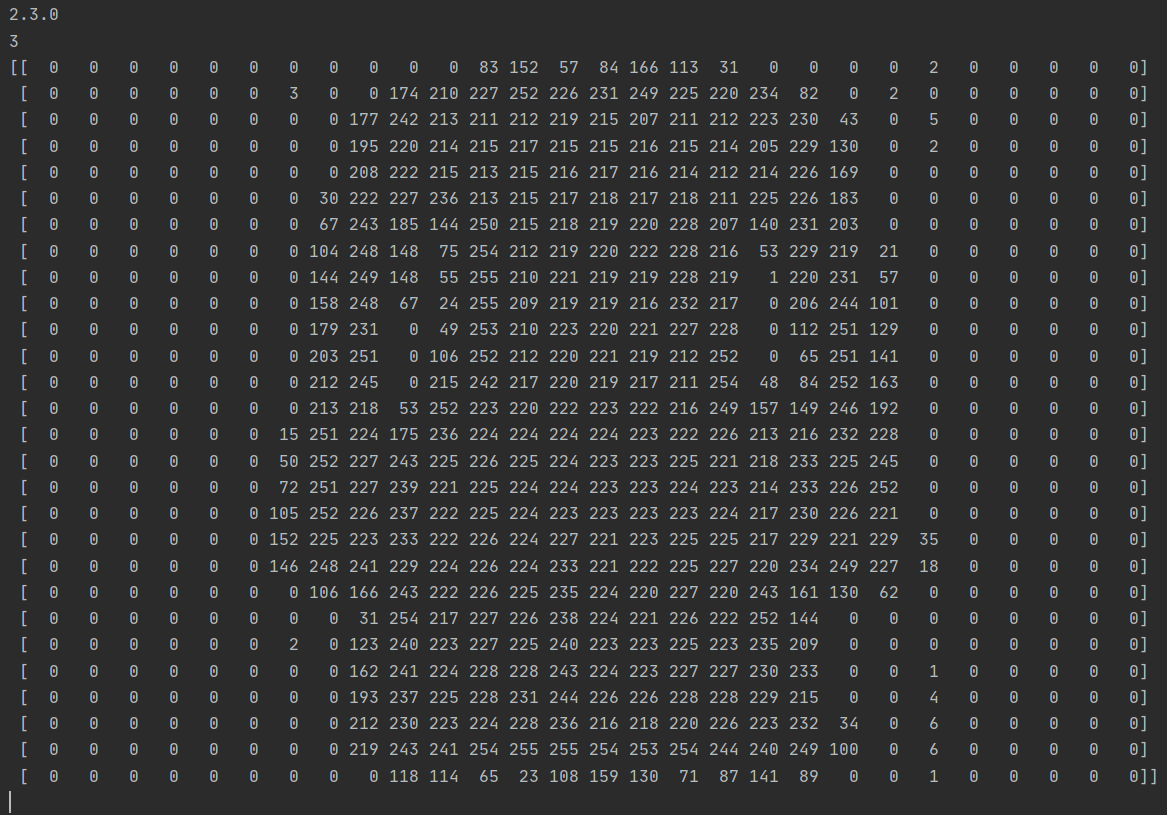
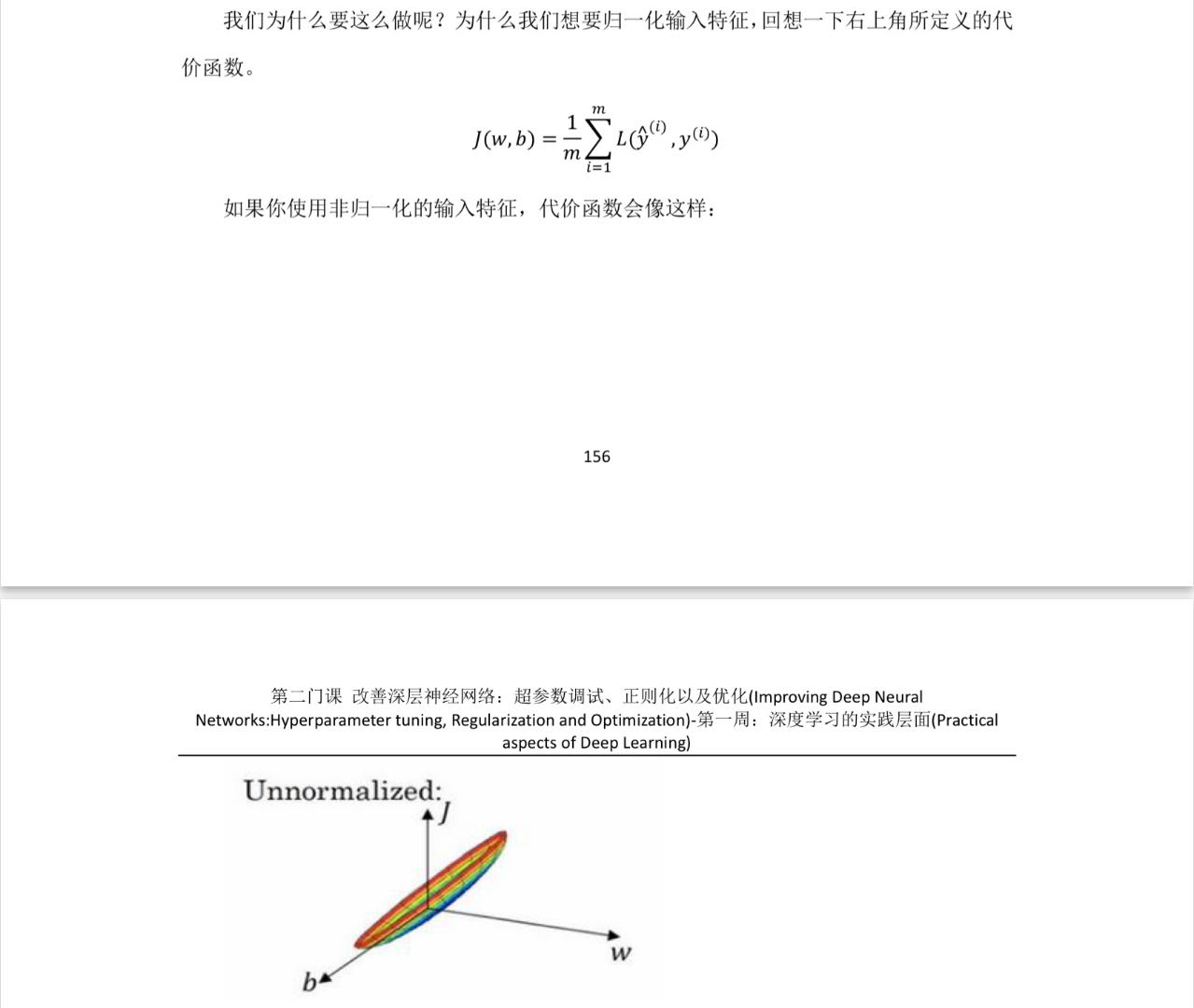
归一化处理:
training_images = training_images / 255.0
test_images = test_images / 255.0
这里把数据集分成了训练数据和测试数据,先用一组数据进行训练,然后再用另一组模型还没有见过的数据来测试分类效果。
设计模型
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
Sequential: 定义了神经网络中各层的序列
Flatten: 扁平化技术,将图像转化为一维数据集。
Dense: 增加一层神经元
每一层神经元都需要一个激活函数(activation function) 来告诉它们该做什么。这里用到的:
Relu 的有效含义是 "如果 X>0 则返回 X,否则返回 0"--因此它只会将 0 或更大的值传递给网络的下一层。(屏蔽负值)
Softmax 接收一组数值,并有效地选出最大值。(softmax分类器)
举例来说,如果最后一层的输出看起来像[0.1, 0.1, 0.05, 0.1, 9.5, 0.1, 0.05, 0.05, 0.05],它就会帮你省去在其中寻找最大值的麻烦,并将其转化为[0,0,0,0,1,0,0,0,0,0]--目的是节省大量编码!(这里的解释跟吴恩达说的hardmax有点像?但是原理就是选择概率最大类别的作为样本的类别)
模型定义完成后,接下来要做的就是构建模型。具体做法是,像之前一样用优化器和损失函数编译模型,然后调用 model.fit 来训练它,要求它将训练数据与训练标签进行拟合,也就是说,让它找出训练数据与实际标签之间的关系,这样,如果将来有类似训练数据的数据,它就能预测出这些数据会是什么样子。
model.compile(optimizer = tf.optimizers.Adam(),
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
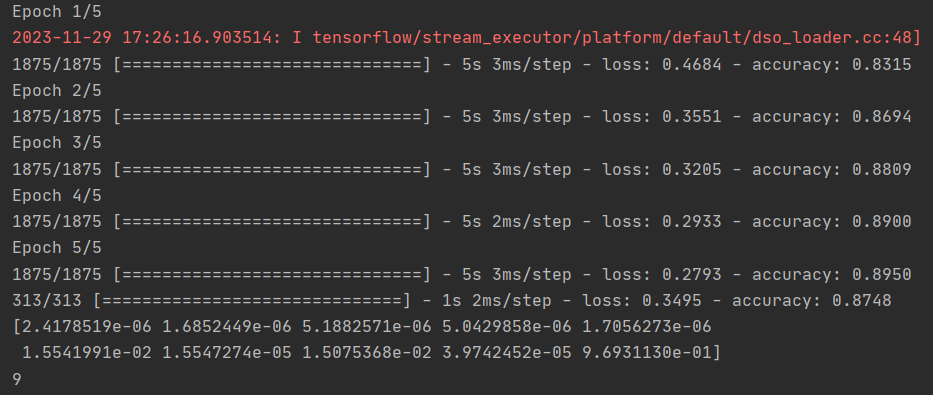
model.fit(training_images, training_labels, epochs=5)
训练完成后,你应该会在最后一个epoch结束时看到一个准确率值。它可能看起来像 0.9098。这说明神经网络对训练数据的分类准确率约为 91%。也就是说,它在图像和标签之间找出了一种模式匹配,这种模式匹配在 91% 的情况下有效。虽然不是很好,但考虑到它只训练了 5 个epoch,而且完成得相当快,还算不错。
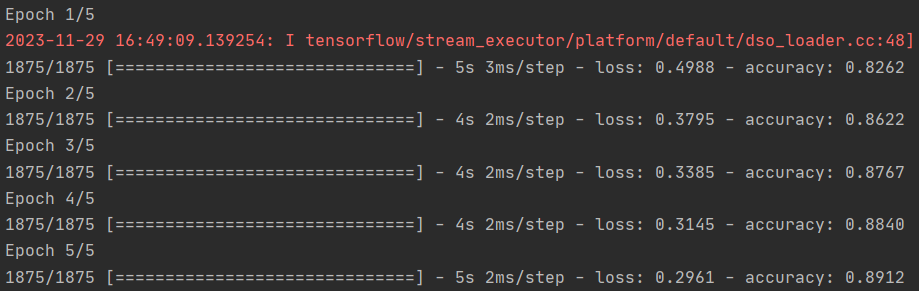
但是,它在处理未见过的数据时会怎样呢?这就是我们拥有测试图像的原因。我们可以调用 model.evaluate,输入两组数据,它就会报告每组数据的损失。让我们试一试:
model.evaluate(test_images, test_labels)
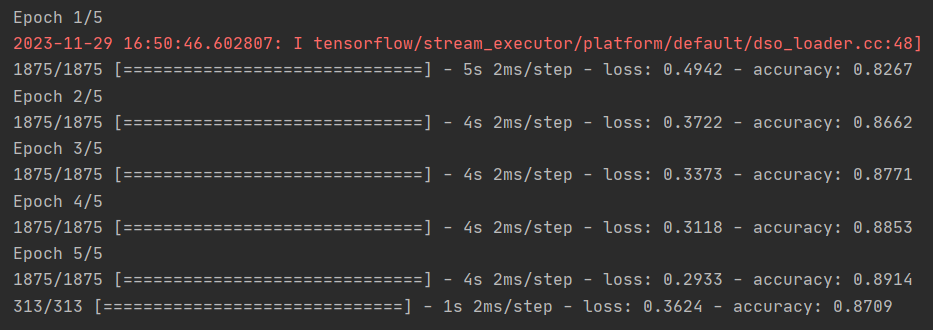
对我来说,返回的准确度约为 0.8838,这意味着它的准确度约为 88%。正如预期的那样,它处理看不见的数据的效果可能不如处理训练数据的效果好!当您学习本课程时,您将寻找改进的方法。
要进一步探索,请尝试下面的练习:
Exploration Exercises
Exercise 1:
第一个练习运行下面的代码: 它会为每个测试图像创建一组分类,然后打印分类中的第一个条目。运行后的输出结果是一个数字列表。你认为这是为什么,这些数字代表什么?
classifications = model.predict(test_images)
print(classifications[0])
提示:尝试运行 print(test_labels[0]) -- 你会得到一个 9。 这是否有助于你理解为什么这个列表看起来是这样的?
print(test_labels[0])

Q: 这个list代表了什么?
A: 这是该物品属于 10 个类别中每个类别的概率
该模型的输出是一个包含 10 个数字的列表。这些数字表示被分类的值是相应值的概率 (https://github.com/zalandoresearch/fashion-mnist#labels),即列表中的第一个值表示图像是 "0"(T 恤/上衣)的概率,下一个是 "1"(裤子)的概率等。请注意,它们的概率都非常低。
对于 9(踝靴),概率为 90%,也就是说,神经网络告诉我们这几乎肯定是9(踝靴)。
Q: 你怎么知道这份清单告诉你该物品是踝靴呢?
A: 列表中的第 10 个元素是最大的,踝靴的标号是 9
Exercise 2:
现在我们来看看模型中的各层。尝试使用 512 个神经元的密集层的不同值。你在损失、训练时间等方面得到了什么不同的结果?为什么会出现这种情况?
import tensorflow as tf
print(tf.__version__)
mnist = tf.keras.datasets.mnist
(training_images, training_labels) , (test_images, test_labels) = mnist.load_data()
training_images = training_images/255.0
test_images = test_images/255.0
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1024, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
model.compile(optimizer = 'adam',
loss = 'sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=5)
model.evaluate(test_images, test_labels)
classifications = model.predict(test_images)
print(classifications[0])
print(test_labels[0])
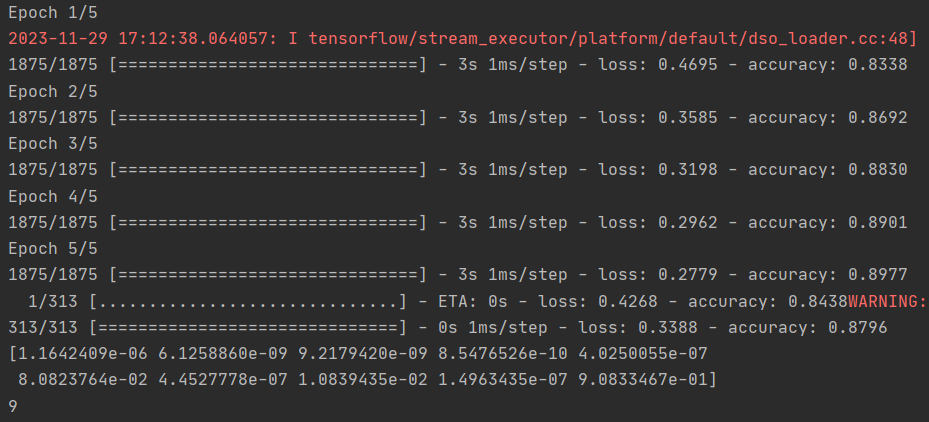
Q: 增加到 1024 个神经元 -- 有什么影响?
A: 培训时间更长,但更准确(0.8709-->0.8796?)
增加更多的神经元,我们就必须进行更多的计算,从而减慢计算速度,但在这种情况下,神经元的作用是好的--我们确实变得更准确了。但这并不意味着 "越多越好",你可能很快就会遇到收益递减规律!
Exercise 3:
如果去掉 Flatten() 层会发生什么情况?为什么会这样?
你会得到一个关于数据形状的错误(get an error about the shape of the data)。现在看来可能很模糊(vague),但它强化了一条经验法则,即网络中的第一层应与数据形状相同(it reinforces the rule of thumb that the first layer in your network should be the same shape as your data.)。现在,我们的数据是 28x28 的图像,而 28 个神经元组成 28 层是不可行的,因此将 28x28 的图像 "扁平化 "为 784x1 的图像更合理。 与其自己编写所有代码来处理这个问题,我们不如在开始时添加 Flatten() 层,以后将数组加载到模型中时,它们会自动为我们扁平化。
model = tf.keras.models.Sequential([#tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])

Exercise 4:
考虑最后(输出)层。为什么有 10 个?如果您的数目与 10 不同,会发生什么情况?例如,尝试使用 5 个网络来训练网络
一旦发现意外值,您就会收到错误消息。另一个经验法则是——最后一层中的神经元数量应该与您要分类的类别数量相匹配。在本例中,它是数字 0-9,因此共有 10 个,因此最后一层中应该有 10 个神经元。
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dense(5, activation=tf.nn.softmax)])
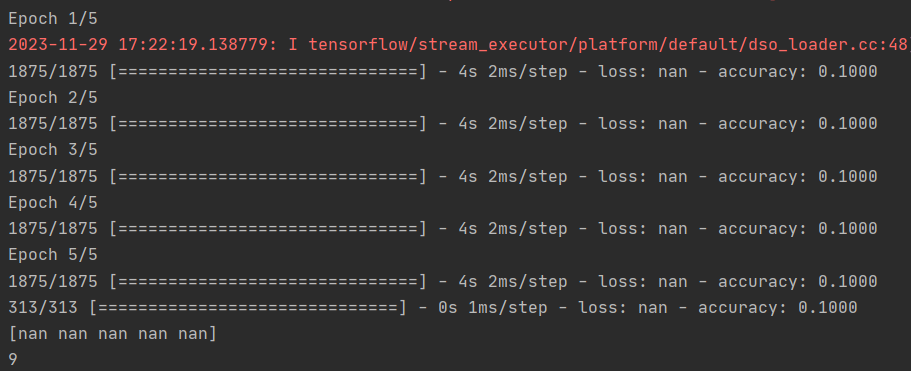
没报错?但是显然有问题
Exercise 5:
考虑网络中增加层数的影响。如果在 512 层和最后的 10 层之间再增加一层,会出现什么情况?
答案:影响不大--因为这是相对简单的数据。而对于复杂得多的数据(包括下一课将要介绍的要分类为花朵的彩色图像),通常需要额外的层。
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
Exercise 6:
考虑训练时间越长或越短的影响。为什么会这样?
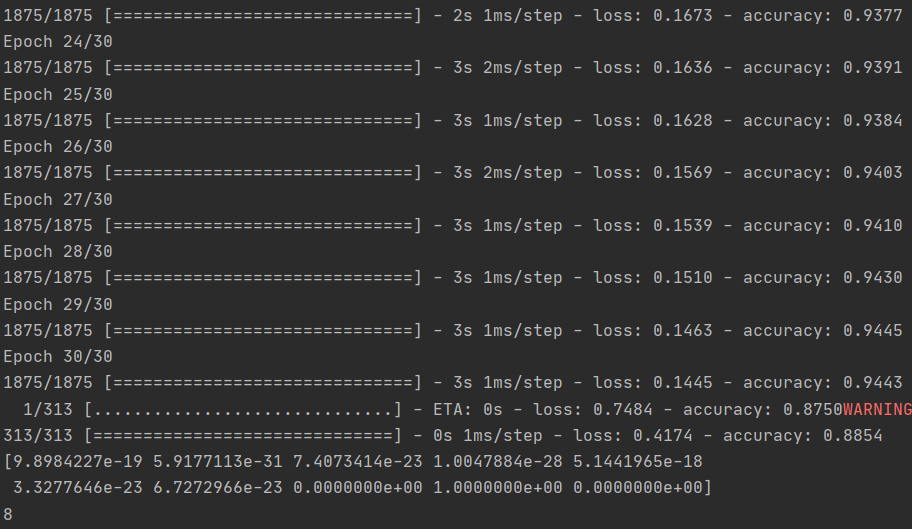
试试 15 个 epoch -- 你可能会得到一个损失比 5 个 epoch 好得多的模型 试试 30 个 epoch -- 你可能会发现损失值不再减少,有时还会增加。这是一种叫做 "过拟合"的副作用,你可以在[某处]了解到,这也是你在训练神经网络时需要注意的。如果不能改善损失,就没有必要浪费时间训练了,对吧!?
model.fit(training_images, training_labels, epochs=30)
Exercise 7:
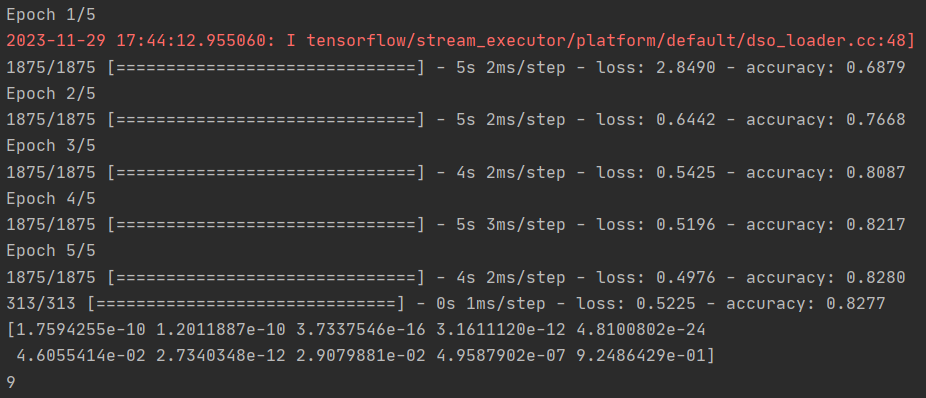
在训练之前,您对数据进行了规范化处理,将 0-255 的值转化为 0-1 的值。去掉这些会有什么影响?下面是完整的代码,你可以试一试。为什么会得到不同的结果?
import tensorflow as tf
print(tf.__version__)
mnist = tf.keras.datasets.mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images=training_images#/255.0
test_images=test_images#/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
model.fit(training_images, training_labels, epochs=5)
model.evaluate(test_images, test_labels)
classifications = model.predict(test_images)
print(classifications[0])
print(test_labels[0])
有归一化的:
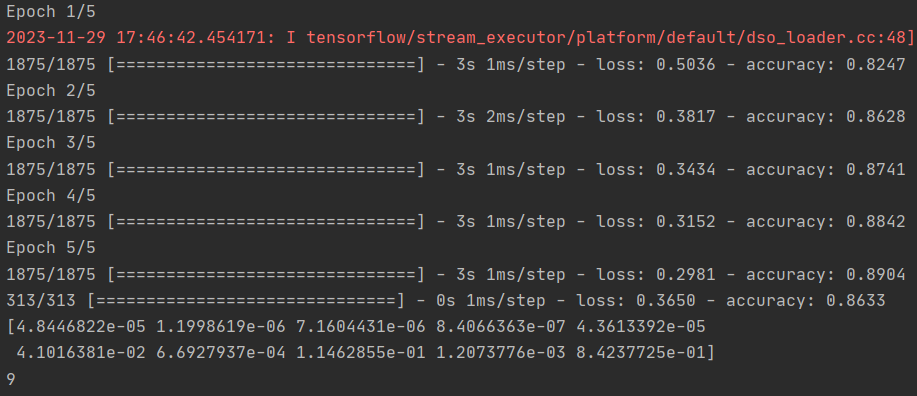
有归一化的训练更快结果更准。

Exercise 8:
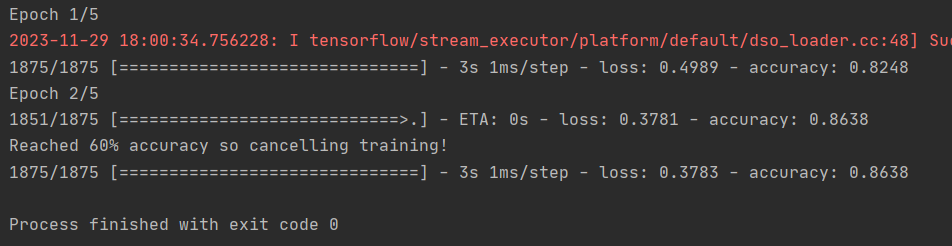
早些时候,当你进行额外的epochs训练时,你会遇到一个问题,那就是你的损失可能会发生变化。你可能会想 "如果能在达到预期值时停止训练不是更好吗?"也就是说,95% 的准确率可能对你来说已经足够了,如果你在 3 个历元后就达到了 95% 的准确率,那为什么还要坐着等它完成更多的历元呢....?就像其他程序一样......你需要回调!让我们看看它们的实际应用...
import tensorflow as tf
print(tf.__version__)
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs={}):
if(logs.get('loss')<0.4):
print("\nReached 60% accuracy so cancelling training!")
self.model.stop_training = True
#定义callbacks
callbacks = myCallback()
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images=training_images/255.0
test_images=test_images/255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy')
model.fit(training_images, training_labels, epochs=5, callbacks=[callbacks])#调用callbacks
[02 A Computer Vision Example.py](assets/02 A Computer Vision Example-20231129180257-ztew9j2.py)