1. Job 提交源码追踪
1.1 MR 程序入口方法
作为使用 Java 语言编写的 MapReduce 程序,其入口方法为 main 方法。在 main 方法中,使用了 ToolRunner 启动运行了 MapReduce 客户端主类,其逻辑实现定义在 run 方法中。
public static void main(String[] args) throws Exception {
// 1. 创建配置对象
Configuration config = new Configuration();
config.set("mapreduce.framework.name", "local");
// 2. 使用工具类 ToolRunner 提交作业
int status = ToolRunner.run(config, new WordCountDriver2(), args);
// 3. 退出客户端
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
// 1. 创建Job实例
Job job = Job.getInstance(getConf(), WordCountDriver2.class.getSimpleName());
// 2. 设置MR程序运行的主类
job.setJarByClass(WordCountDriver2.class);
// 3. 设置MR程序的Mapper类
job.setMapperClass(WordCountMapper.class);
// 4. 设置MR程序的Reducer类
job.setReducerClass(WordCountReducer.class);
// 5. 指定Map阶段输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 6. 指定Reduce阶段输出的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 7. 配置本次Job的输入/输出数据路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
Job 类允许用户配置作业,提交作业,控制作业执行以及查询作业状态。用户创建 MapReduce 应用程序,通过 Job 描述作业的各个方面,然后提交作业并监视其进度。通常,我们把定义描述 Job 所在的主类(含有 main 方法的类)称之为 MapReduce 程序的驱动类。
1.2 job.waitForCompletion
客户端的最后执行了 job.waitForCompletion() 方法,从名字上可以看出该方法的功能是等待 MR 程序执行完毕。进入该方法内部:
在判断状态 state 可以提交 Job 后,执行 submit() 方法。monitorAndPrintJob() 方法会不断的刷新获取 job 运行的进度信息,并打印。boolean 参数 verbose 为 true 表明要打印运行进度,为 false 就只是等待 job 运行结束,不打印运行日志。
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) { // 当 job 状态为 define 时
submit(); // 提交 job
}
if (verbose) { // verbose 值由用户指定
monitorAndPrintJob(); // 随着进度和任务的进行,实时监视作业和打印状态
} else {
int completionPollIntervalMillis // 从客户端根据轮询间隔(默认 5000ms)拉取完成状态信息
= Job.getCompletionPollInterval(cluster.getConf());
while (!isComplete()) {
try {
Thread.sleep(completionPollIntervalMillis);
} catch (InterruptedException ie) {
}
}
}
return isSuccessful(); // 检查作业是否成功完成,返回 true 表示成功。
}
/** Submit the job to the cluster and return immediately. */
public void submit() throws IOException, InterruptedException, ClassNotFoundException {
// 再次检查确保作业状态为 define
ensureState(JobState.DEFINE);
// 设置使用新API
setUseNewAPI();
// <======== 跟程序运行环境建立连接 ========>
connect();
// 获取Job提交器:根据运行环境分为Local提交器、Yarn提交器
final JobSubmitter submitter = getJobSubmitter(cluster.getFileSystem(), cluster.getClient());
status = ugi.doAs(new PrivilegedExceptionAction<JobStatus>() {
public JobStatus run() throws IOException, InterruptedException,
ClassNotFoundException {
// <======== 提交 Job ========>
return submitter.submitJobInternal(Job.this, cluster);
}
});
// 客户端提交 job 成功,状态更新为 running
state = JobState.RUNNING;
LOG.info("The url to track the job: " + getTrackingURL());
}
1.3 job.submit
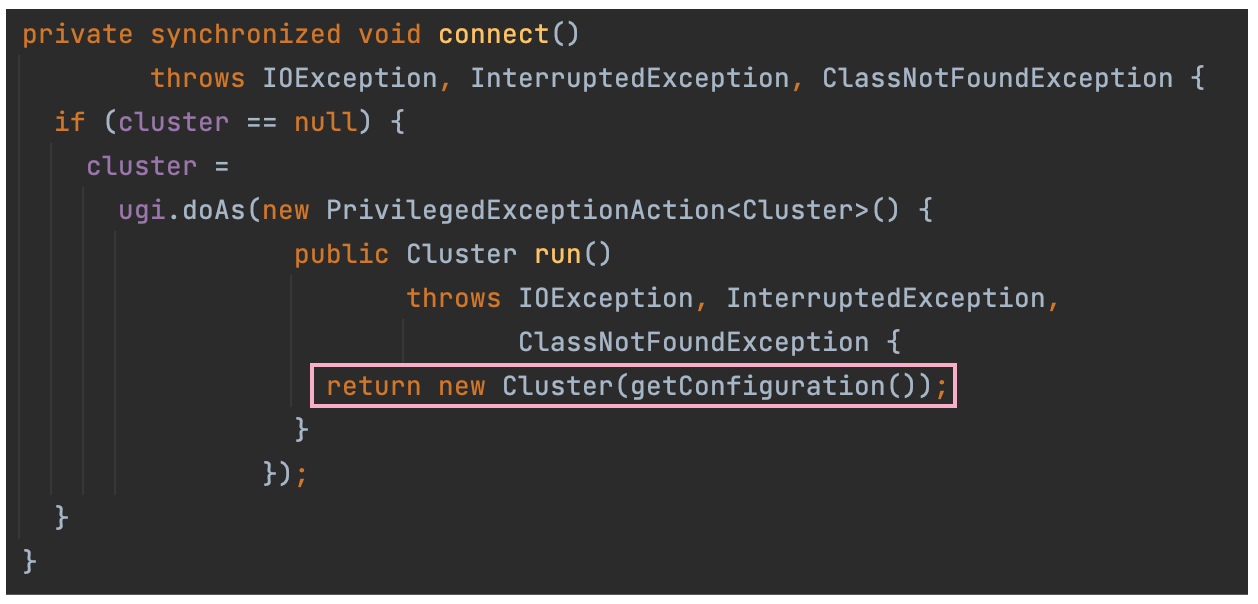
a. connect
MapReduce 作业提交时,连接集群是通过 Job 的 connect() 方法实现的,它实际上是构造集群 Cluster 实例 cluster。Cluster 为连接 MapReduce 集群的一种工具,提供了一种获取 MapReduce 集群信息的方法。
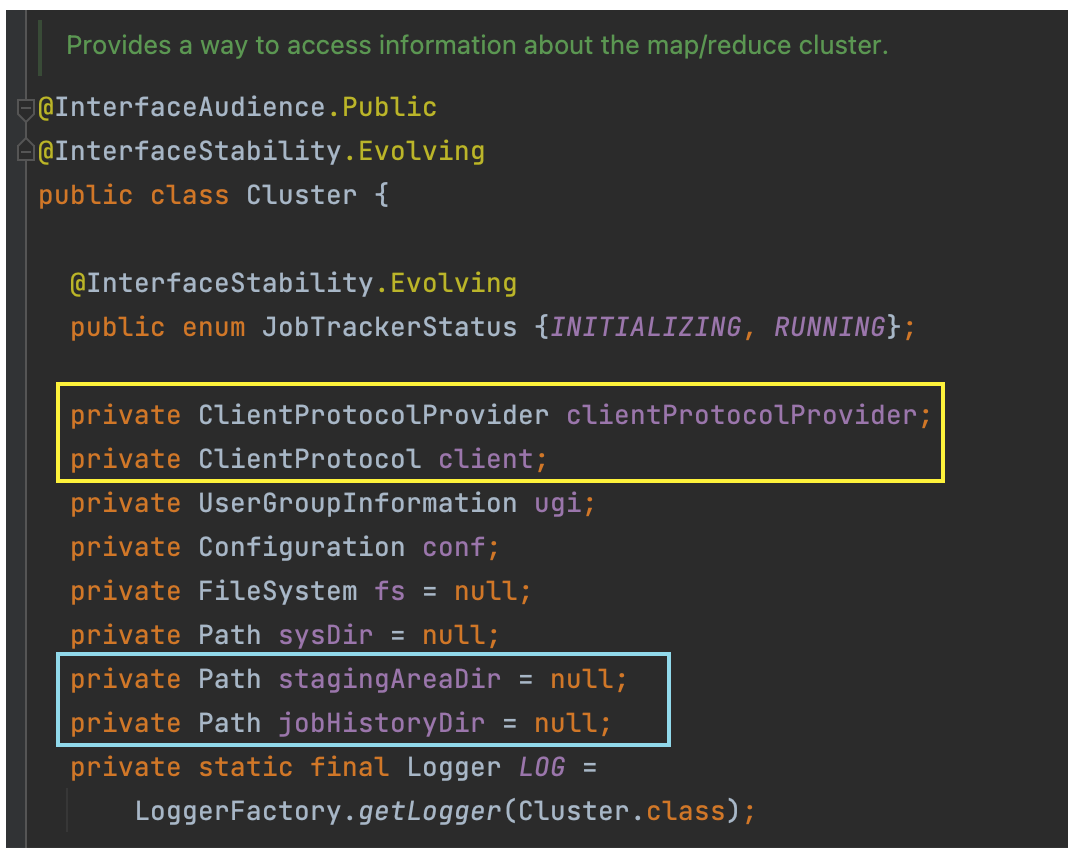
Cluster 类中最重要的两个成员变量是客户端通信协议提供者 ClientProtocolProvider、客户端通信协议 ClientProtocol,依托 ClientProtocolProvider 的 create() 方法产生。
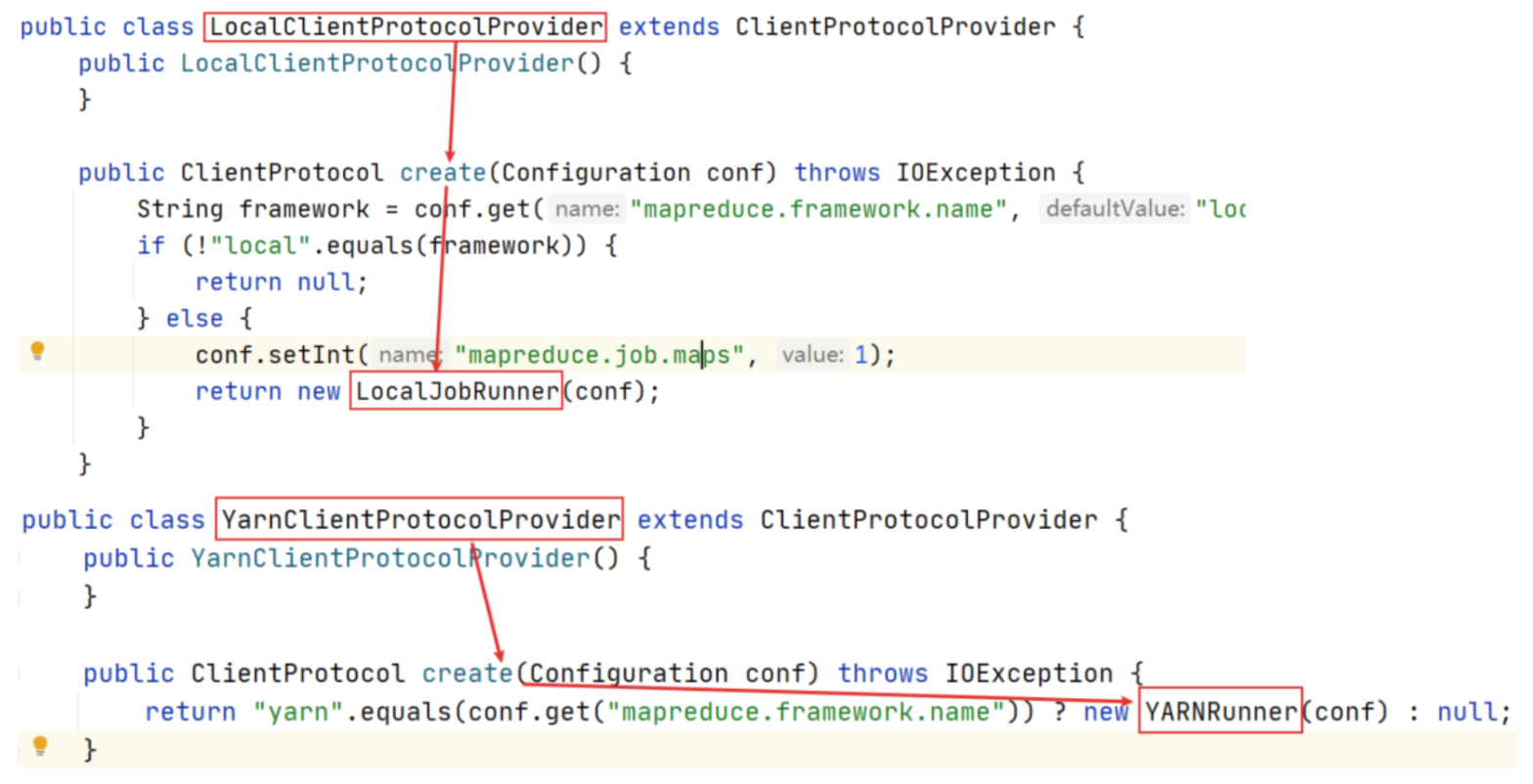
与集群进行通信的客户端通信协议,其实例叫做 client,有两种不同的具体实现:Yarn 模式的 YARNRunner、Local 模式的 LocalJobRunner。
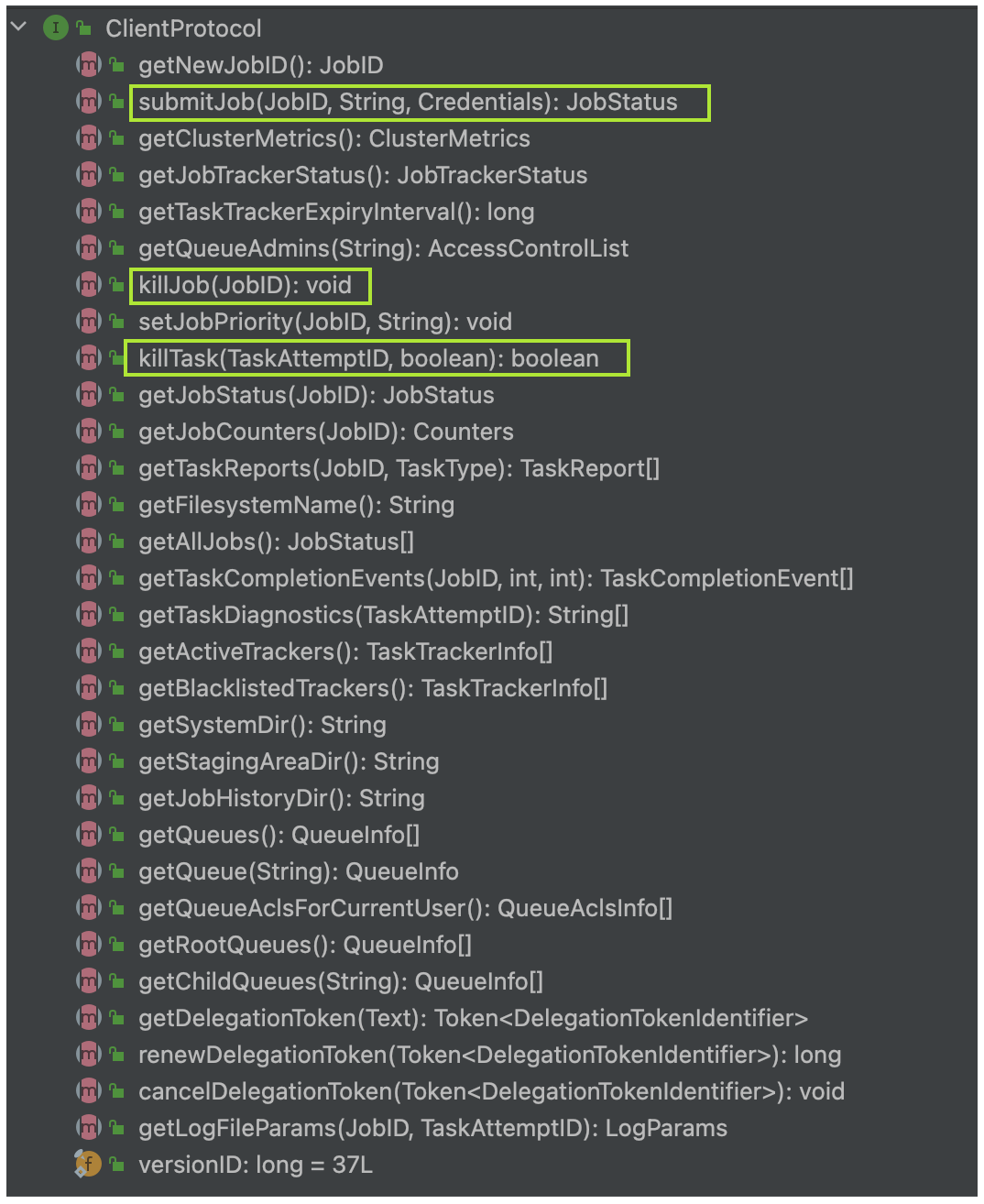
在 ClientProtocol 中,定义了很多方法,用户可以使用这些方法进行 Job 的提交、杀死或是获取一些程序状态信息。
在 Cluster 的构造方法中,完成了初始化的动作。
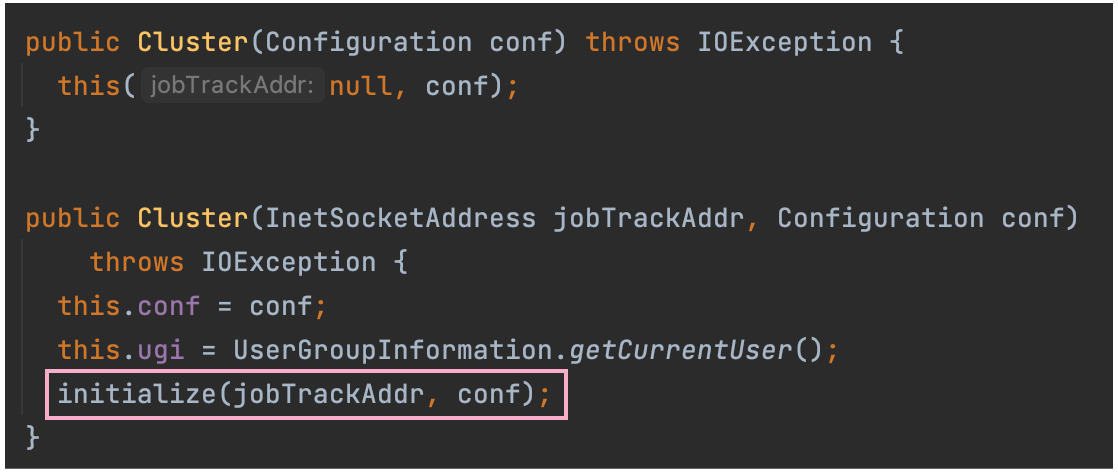
在 Cluster 类的构造方法中,调用了 initialize 初始化方法。依次取出每个 ClientProtocolProvider,通过其 create() 方法构造 ClientProtocol 实例。如果配置文件没有配置 YARN 信息,则构建 LocalRunner,MR任务本地运行;如果配置文件有配置 YARN 信息,则构建 YarnRunner,MR 任务在 YARN 集群上运行。
ClientProtocol clientProtocol = null;
if (jobTrackAddr == null) {
clientProtocol = provider.create(conf);
} else {
clientProtocol = provider.create(jobTrackAddr, conf);
}
b. ClientProtocolProvider
上面 create() 方法时提到了两种 ClientProtocolProvider 实现类。
ClientProtocolProvider 抽象类的实现共有 YarnClientProtocolProvider、LocalClientProtocolProvider 两种,前者为 Yarn 模式,而后者为 Local 模式。
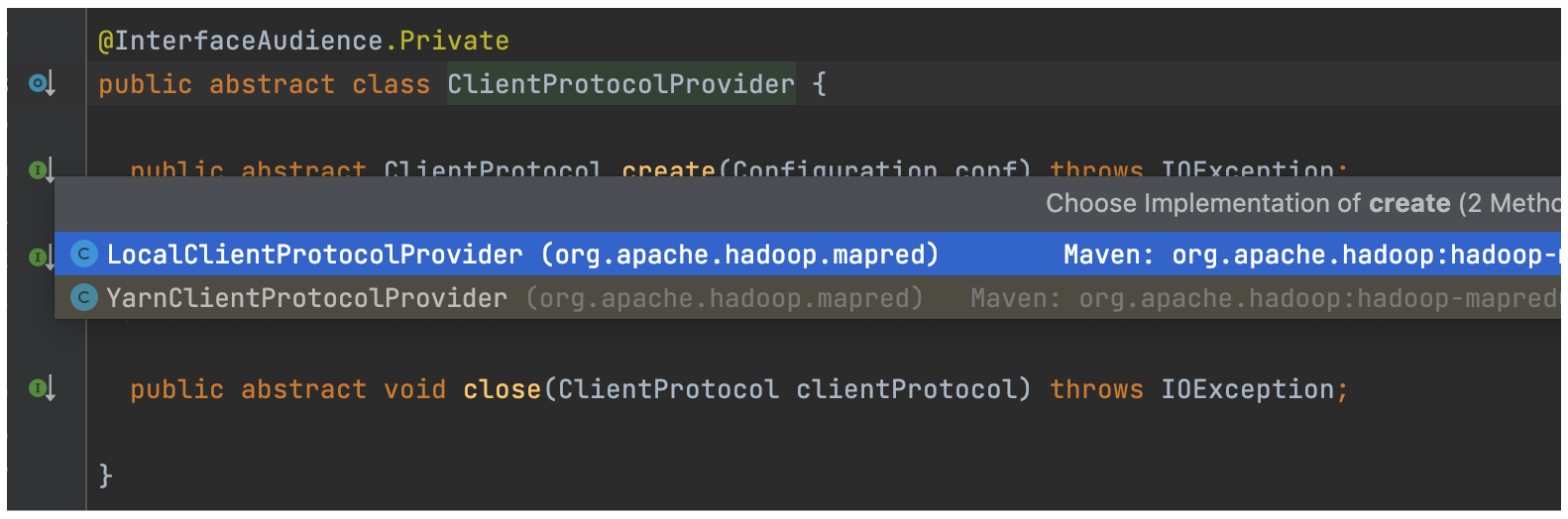
Cluster 中客户端通信协议 ClientProtocol 实例,要么是 Yarn 模式下的 YARNRunner,要么就是 Local 模式下的 LocalJobRunner。
1.4 submitter.submitJobInternal
在 submit() 方法的最后,调用了提交器 submitter.submitJobInternal() 方法进行任务的提交。它是提交 Job 的内部方法,实现了提交 Job 的所有业务逻辑。
JobSubmitter 的类一共有 4 个类成员变量,分别为:
- 文件系统 FileSystem 实例 jtFs:用于操作作业运行需要的各种文件等;
- 客户端通信协议 ClientProtocol 实例 submitClient:用于与集群交互,完成作业提交、作业状态查询等;
- 提交作业的主机名 submitHostName;
- 提交作业的主机地址 submitHostAddress。
如下方法实现了提交作业的全逻辑。包括输出规范性检测、作业属性参数设置、作业准备区创建与准备资源提交(依赖资源、job.split、job.xml)、最终提交作业等。
JobStatus submitJobInternal(Job job, Cluster cluster) throws ClassNotFoundException, InterruptedException, IOException {
// validate the jobs output specs 检查作业的输出规范的有效性
// ===> 比如检查输出路径是否配置并且是否存在。正确情况是已经配置且不存在
checkSpecs(job);
Configuration conf = job.getConfiguration();
addMRFrameworkToDistributedCache(conf);
// ===> 获取作业准备区路径,用于作业及相关资源的提交存放,比如:jar、切片信息、配置信息等
// 默认是 /tmp/hadoop-yarn/staging/提交作业用户名/.staging
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
//configure the command line options correctly on the submitting dfs
InetAddress ip = InetAddress.getLocalHost();
// 记录提交作业的主机IP、主机名
if (ip != null) {
submitHostAddress = ip.getHostAddress();
submitHostName = ip.getHostName();
conf.set(MRJobConfig.JOB_SUBMITHOST,submitHostName);
conf.set(MRJobConfig.JOB_SUBMITHOSTADDR,submitHostAddress);
}
// ===> 与运行集群通信,将获取的jobID设置到Job
JobID jobId = submitClient.getNewJobID();
job.setJobID(jobId);
// ===> 创建最终作业准备区路径,jobStagingArea后接/jobID
Path submitJobDir = new Path(jobStagingArea, jobId.toString());
JobStatus status = null;
try {
// 设置一些作业参数
conf.set(MRJobConfig.USER_NAME,
UserGroupInformation.getCurrentUser().getShortUserName());
conf.set("hadoop.http.filter.initializers",
"org.apache.hadoop.yarn.server.webproxy.amfilter.AmFilterInitializer");
conf.set(MRJobConfig.MAPREDUCE_JOB_DIR, submitJobDir.toString());
LOG.debug("Configuring job " + jobId + " with " + submitJobDir
+ " as the submit dir");
// get delegation token for the dir 获得路径的授权令牌
TokenCache.obtainTokensForNamenodes(job.getCredentials(),
new Path[] { submitJobDir }, conf);
populateTokenCache(conf, job.getCredentials());
// generate a secret to authenticate shuffle transfers
if (TokenCache.getShuffleSecretKey(job.getCredentials()) == null) {
KeyGenerator keyGen;
try {
keyGen = KeyGenerator.getInstance(SHUFFLE_KEYGEN_ALGORITHM);
keyGen.init(SHUFFLE_KEY_LENGTH);
} catch (NoSuchAlgorithmException e) {
throw new IOException("Error generating shuffle secret key", e);
}
SecretKey shuffleKey = keyGen.generateKey();
TokenCache.setShuffleSecretKey(shuffleKey.getEncoded(), job.getCredentials());
}
if (CryptoUtils.isEncryptedSpillEnabled(conf)) {
conf.setInt(MRJobConfig.MR_AM_MAX_ATTEMPTS, 1);
LOG.warn("Max job attempts set to 1 since encrypted intermediate data spill is enabled");
}
// ===> 拷贝作业相关的资源文件到 submitJobDir 作业准备区,比如:-libjars,-files,-archives
copyAndConfigureFiles(job, submitJobDir);
// ===> 创建文件 job.xml 用于保存作业的配置信息
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
// Create the splits for the job todo
LOG.debug("Creating splits at " + jtFs.makeQualified(submitJobDir));
// ===> 生成本次作业的输入切片信息,并把切片信息写入作业准备区 submitJobDir
int maps = writeSplits(job, submitJobDir);
conf.setInt(MRJobConfig.NUM_MAPS, maps);
LOG.info("number of splits:" + maps);
int maxMaps = conf.getInt(MRJobConfig.JOB_MAX_MAP, MRJobConfig.DEFAULT_JOB_MAX_MAP);
if (maxMaps >= 0 && maxMaps < maps) {
throw new IllegalArgumentException("The number of map tasks " + maps + " exceeded limit " + maxMaps);
}
// write "queue admins of the queue to which job is being submitted" to job file. 队列信息
String queue = conf.get(MRJobConfig.QUEUE_NAME, JobConf.DEFAULT_QUEUE_NAME);
AccessControlList acl = submitClient.getQueueAdmins(queue);
conf.set(toFullPropertyName(queue, QueueACL.ADMINISTER_JOBS.getAclName()), acl.getAclString());
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a different job.
TokenCache.cleanUpTokenReferral(conf);
if (conf.getBoolean(
MRJobConfig.JOB_TOKEN_TRACKING_IDS_ENABLED,
MRJobConfig.DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED)) {
// Add HDFS tracking ids
ArrayList<String> trackingIds = new ArrayList<String>();
for (Token<? extends TokenIdentifier> t :
job.getCredentials().getAllTokens()) {
trackingIds.add(t.decodeIdentifier().getTrackingId());
}
conf.setStrings(MRJobConfig.JOB_TOKEN_TRACKING_IDS,
trackingIds.toArray(new String[trackingIds.size()]));
}
// Set reservation info if it exists
ReservationId reservationId = job.getReservationId();
if (reservationId != null) {
conf.set(MRJobConfig.RESERVATION_ID, reservationId.toString());
}
// 把作业配置信息写入作业准备区的job.xml文件中
writeConf(conf, submitJobFile);
// Now, actually submit the job (using the submit name)
printTokens(jobId, job.getCredentials());
// ===> 到这里,终于进行真正的作用提交了(分为两种模式提交程序,本地模式运行提交任务、YARN模式运行提交任务)
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
if (status != null) {
return status;
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (jtFs != null && submitJobDir != null)
jtFs.delete(submitJobDir, true);
}
}
}
2. Map 阶段执行流程
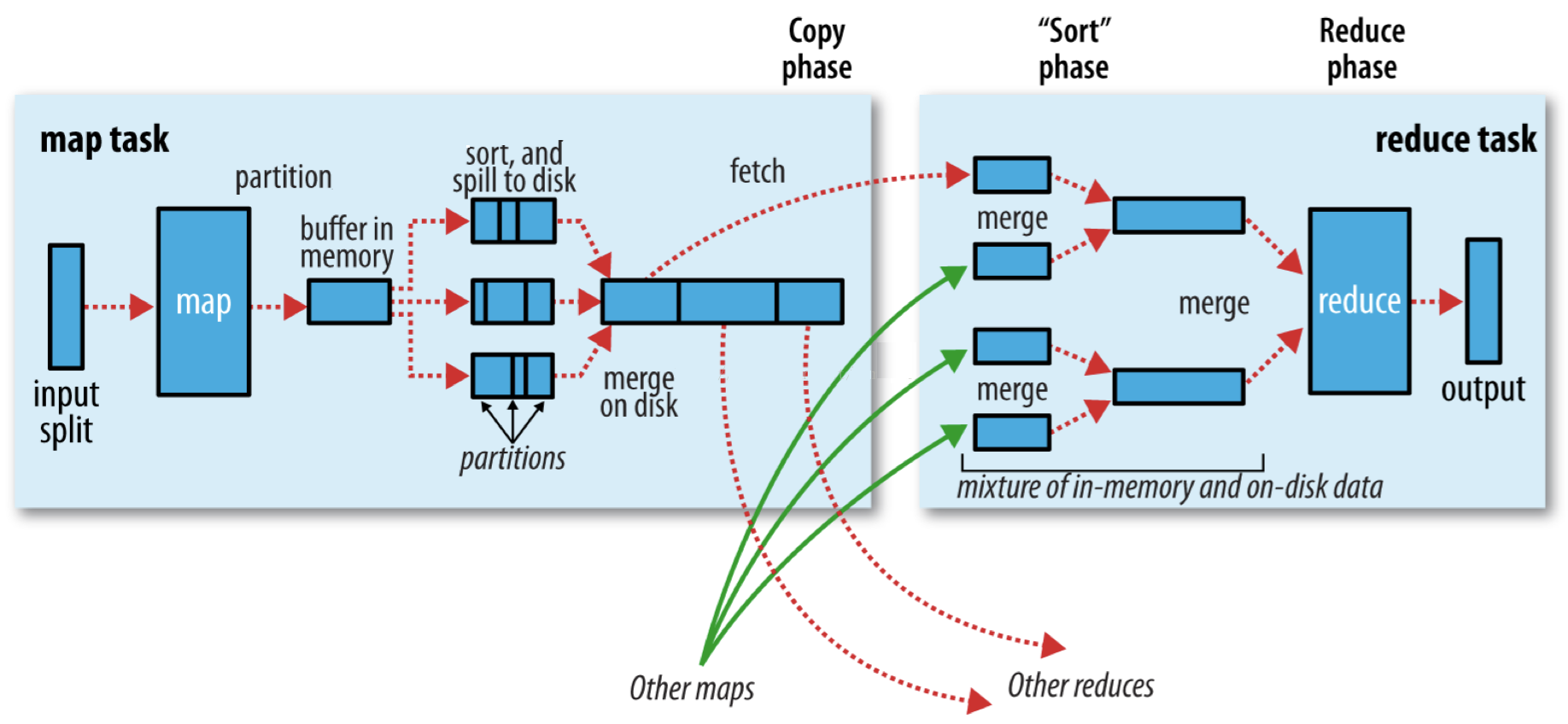
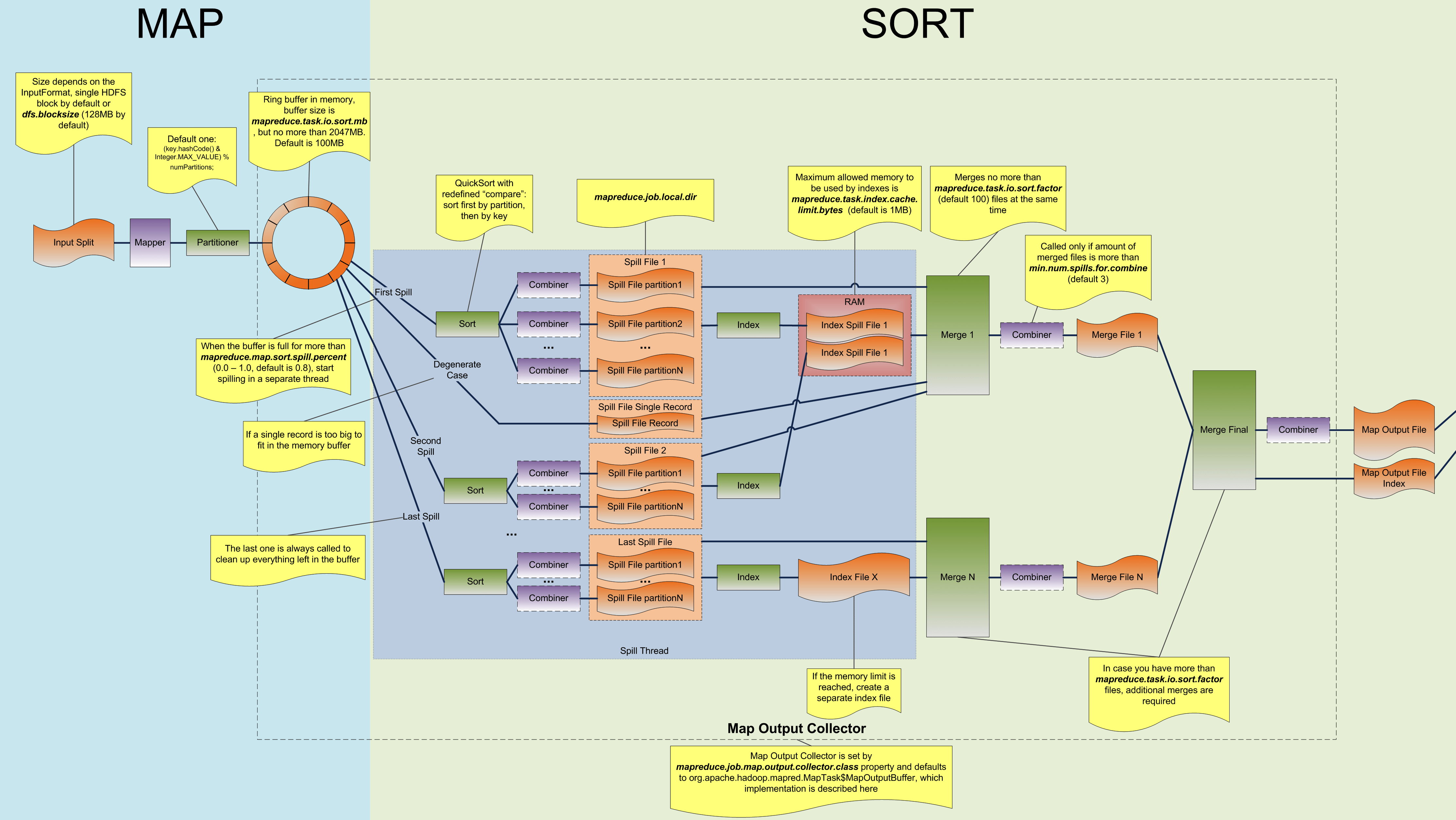
Map 阶段流程简述:
input File 通过 split 被逻辑切分为多个 split 文件,通过 Record 按行读取内容给 map(用户自己实现的)进行处理。
数据被 map 处理结束之后交给 OutputCollector 收集器,对其结果 key 进行分区(默认使用 hash 分区),然后写入 buffer;
每个 mapTask 都有一个内存缓冲区,存储着 map 的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘;
当整个 mapTask 结束后再对磁盘中这个 mapTask 产生的所有临时文件做合并,生成最终的正式输出文件,然后等待 reduceTask 来拉数据。
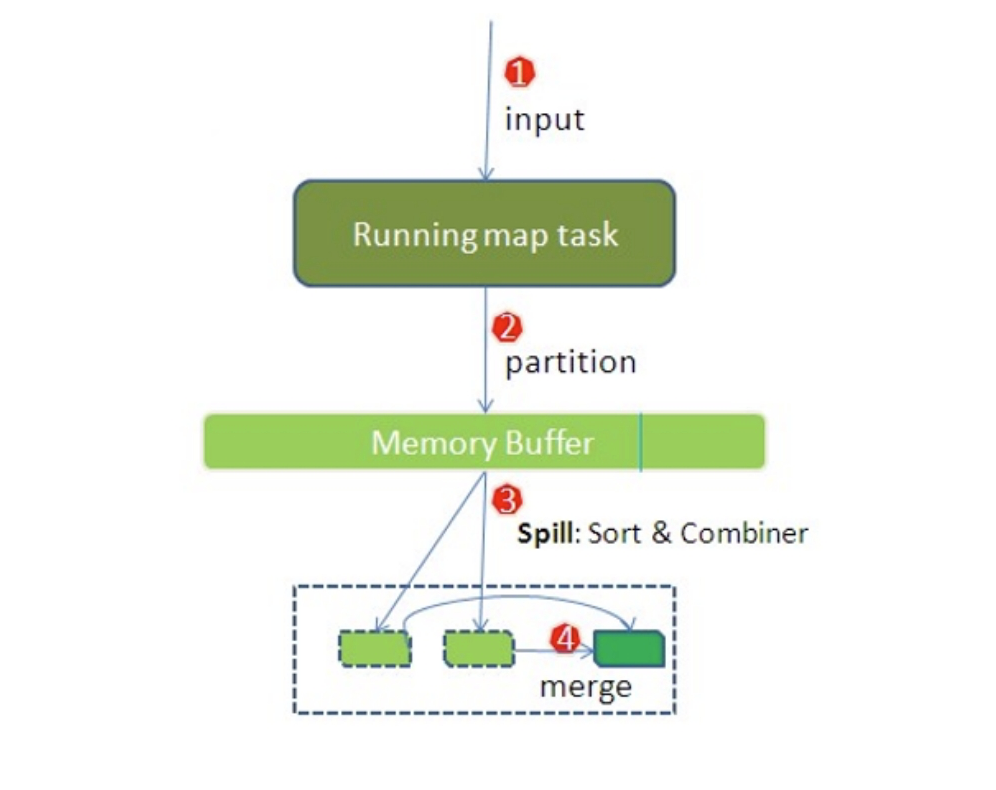
2.1 MapTask 执行流程
在 MapReduce 程序中,初登场的 task 叫做 maptask。MapTask 类作为 maptask 的一个载体,调用其 run() 方法开启 map 任务。在 run() 方法中,有如下两个重要的代码段:
(1)map 阶段的任务划分
// 判断当前的 task 是否为 maptask
if (isMapTask()) {
// If there are no reducers then there won't be any sort. Hence the map
// phase will govern the entire attempt's progress.
// 如果 reducetask 的个数为 0,也就意味着程序没有 reducer 阶段。mapper的
// 输出就是程序最终的输出。这样的话,就没有必要进行shuffle了。
if (conf.getNumReduceTasks() == 0) {
// map阶段占据整个maptask任务的100%
mapPhase = getProgress().addPhase("map", 1.0f);
} else {
// If there are reducers then the entire attempt's progress will be
// split between the map phase (67%) and the sort phase (33%).
// 如果有reducetask的话,map阶段占据67%,sort阶段占据33%
// 为什么要sort?因为要shuffle给reducetask
mapPhase = getProgress().addPhase("map", 0.667f);
sortPhase = getProgress().addPhase("sort", 0.333f);
}
}
(2)运行 Mapper
// 在提交任务的时候,MR框架会自己进行选择使用什么API。默认情况下,使用的都是新的API,除非特别指定了使用old API。
if (useNewApi) {
runNewMapper(job, splitMetaInfo, umbilical, reporter);
} else {
runOldMapper(job, splitMetaInfo, umbilical, reporter);
}
a. runNewMapper 准备部分
默认情况下,框架使用 new API 来运行,所以将执行 runNewMapper()。
runNewMapper() 内第一大部分代码我们称之为 maptask 运行的准备部分,其主要逻辑是创建 maptask 运行时需要的各种依赖:
- Input Split 切片信息
- InputFormat、LineRecordReader 读取数据组件
- Mapper 处理数据组件
- OutputCollector 输出收集器
- taskContext、mapperContext 上下文对象
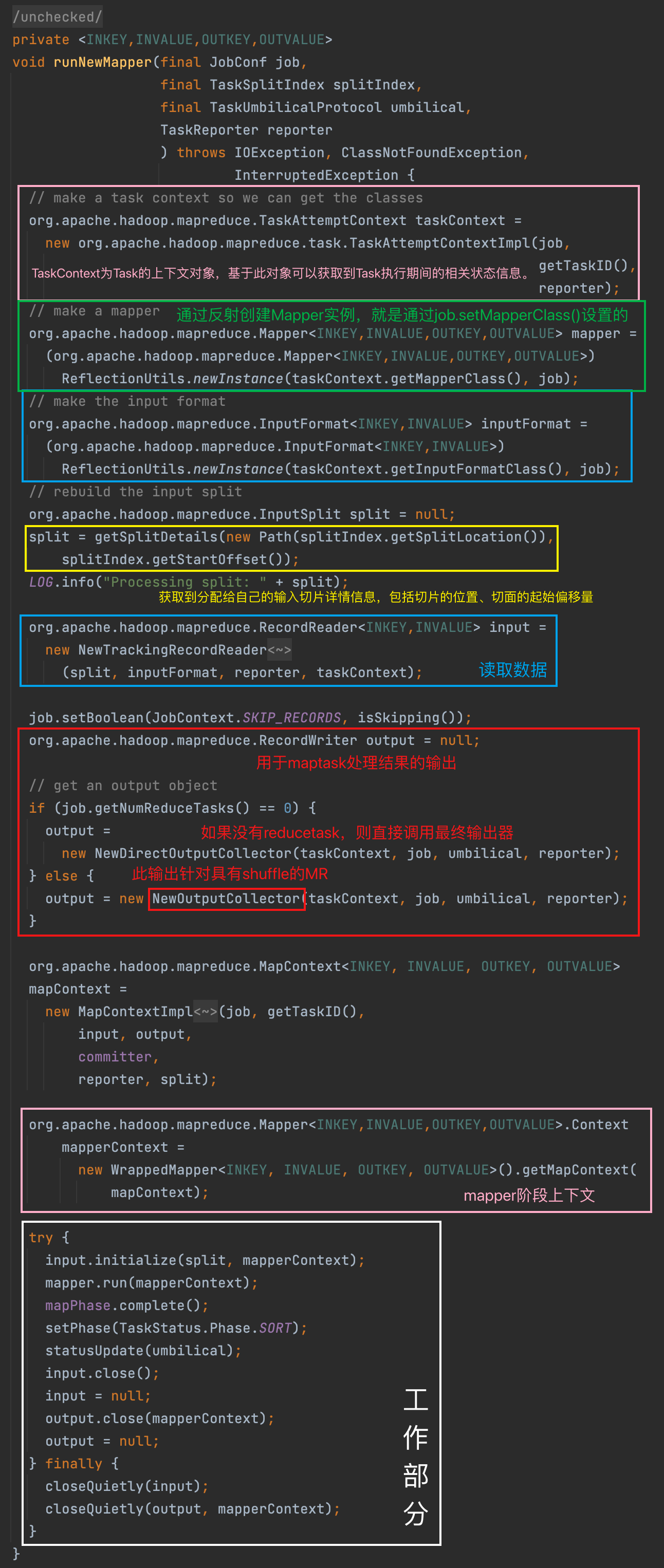
b. runNewMapper 工作部分
runNewMapper() 内第二大部分代码我们称之为 maptask 工作干活的部分,其主要逻辑是:如何从切片读取数据、如何调用 map 处理数据、如何调用 OutputCollector 收集输出的数据。
(1)input.initialize(split, mapperContext)
描述如何从切片读取数据。默认实现逻辑位于 LineRecorderReader 中。核心逻辑:打开文件定位切片的位置,判断文件是否压缩,如果切片不是第一个切片那么读取数据的时候舍去第一行数据不要读取。
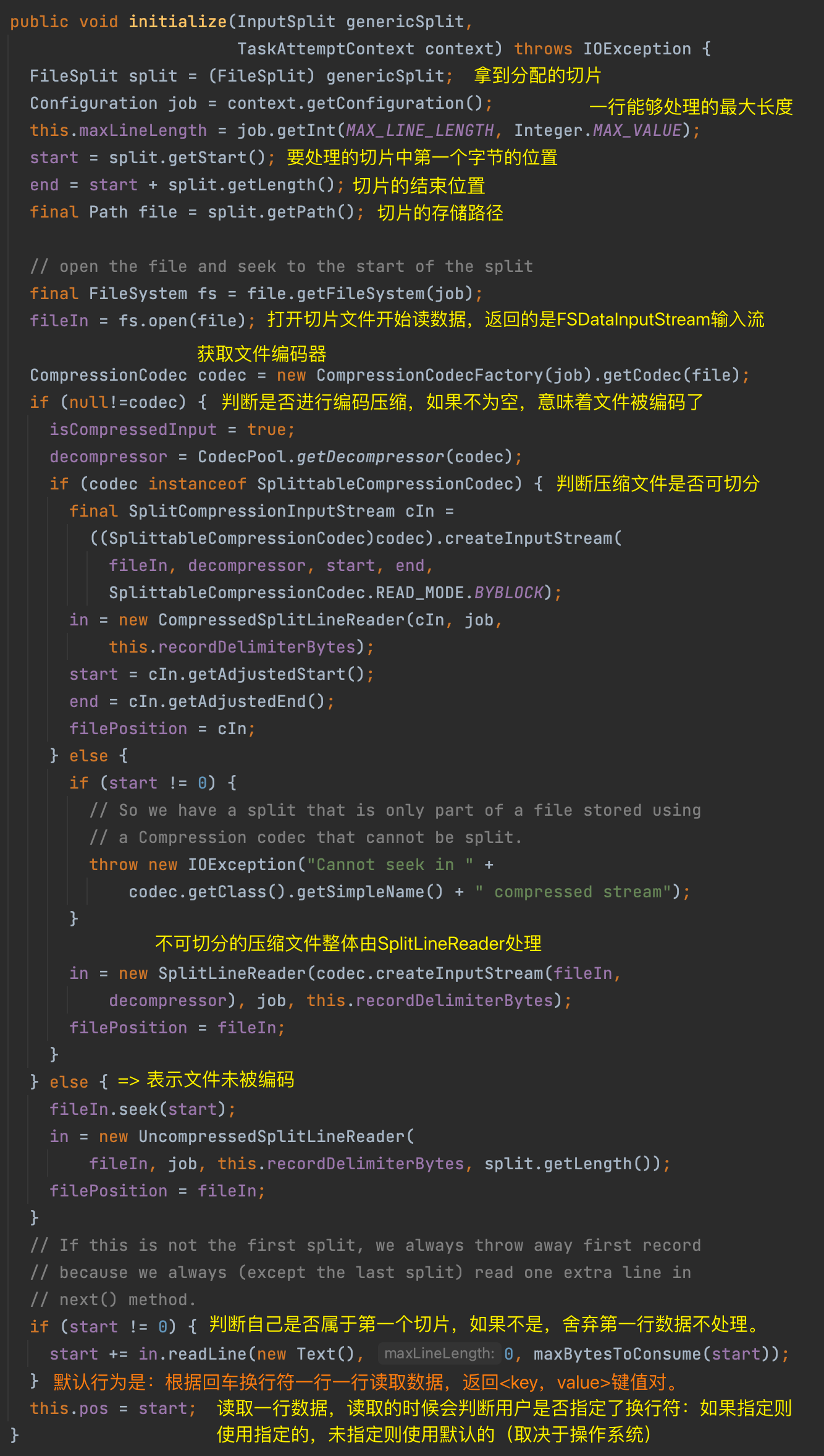
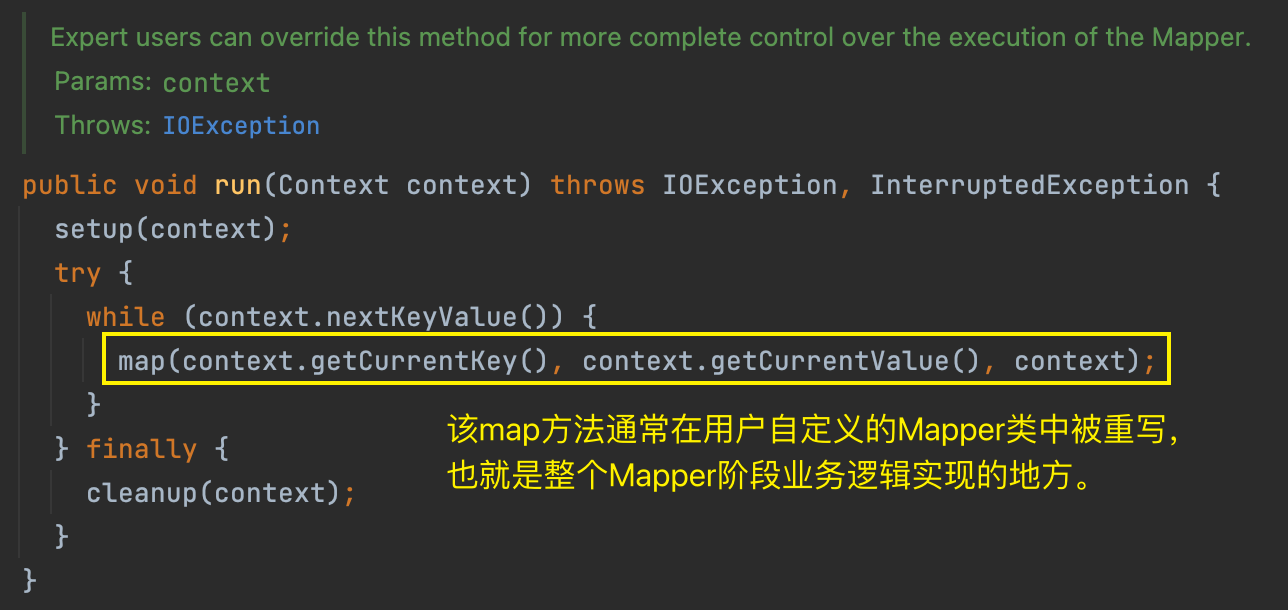
(2)mapper.run(mapperContext)
描述了每当 LineRecordReader 读取一行数据返回 kv 键值对,就调用一次用户编写的 map() 方法进行一次业务逻辑处理。
(3)如何调用 OutputCollector 收集 map 输出的结果
createSortingCollector() 创建 map 输出收集器是最复杂的一部分,因为和后续环形缓冲区操作有关。

进入 createSortingCollector() 方法:

2.2 InputFormat
整个 MapReduce 以 InputFormat 开始,其负责读取待处理的数据。默认的实现叫做 TextInputFormat。
InputFormat 核心逻辑体现在两个方面:
- 如何读取待处理目录下的文件?一个一个读?一起读?
- 读取数据的行为是什么以及返回什么样的结果?一行一行读?按字节读?
a. getSplits
maptask 的并行度问题,指的是 map 阶段有多少个并行的 task 共同处理任务。
map 阶段并行度由客户端在提交 Job 时决定,即客户端提交 Job 之前会对待处理数据进行逻辑切片。切片完成会形成切片规划文件(job.split),每个逻辑切片最终对应启动一个 maptask。
逻辑切片机制由 FileInputFormat 实现类的 getSplits() 方法完成。
首先需要计算出 split size 切片大小,其计算方法如下:split size = block size = 128M
然后以 split size 逐个遍历待处理的文件,形成逻辑规划文件。默认情况下,有多少个 split 就对应启动多少个 MapTask。

在 getSplits() 中,创建了一个集合 splits,用于保存最终的切片信息,集合中的每个元素就是一个切片的具体信息。生成的切片信息在客户端提交 Job 时,也就是 JobSubmitter. writeSplits() 方法中,把所有切片信息进行排序,大的切片在前,然后序列化到一个文件中,此文件叫做逻辑切片文件(job.split),提交到作业准备区路径下。
在进行逻辑切片的时候,假如说一个文件恰好是 129M 大小,那么根据默认的逻辑切片规则将会形成一大一小两个切片(0~128、128~129),并且将启动两个 MapTask。这明显对资源的利用效率不高。因此在设计中,MapReduce 时刻会进行 bytesRemaining 剩下文件大小,如果剩下的不满足 bytesRemaining/splitSize > SPLIT_SLOP(1.1),那么将不再继续 split,而是剩下的所有作为一个切片整体。
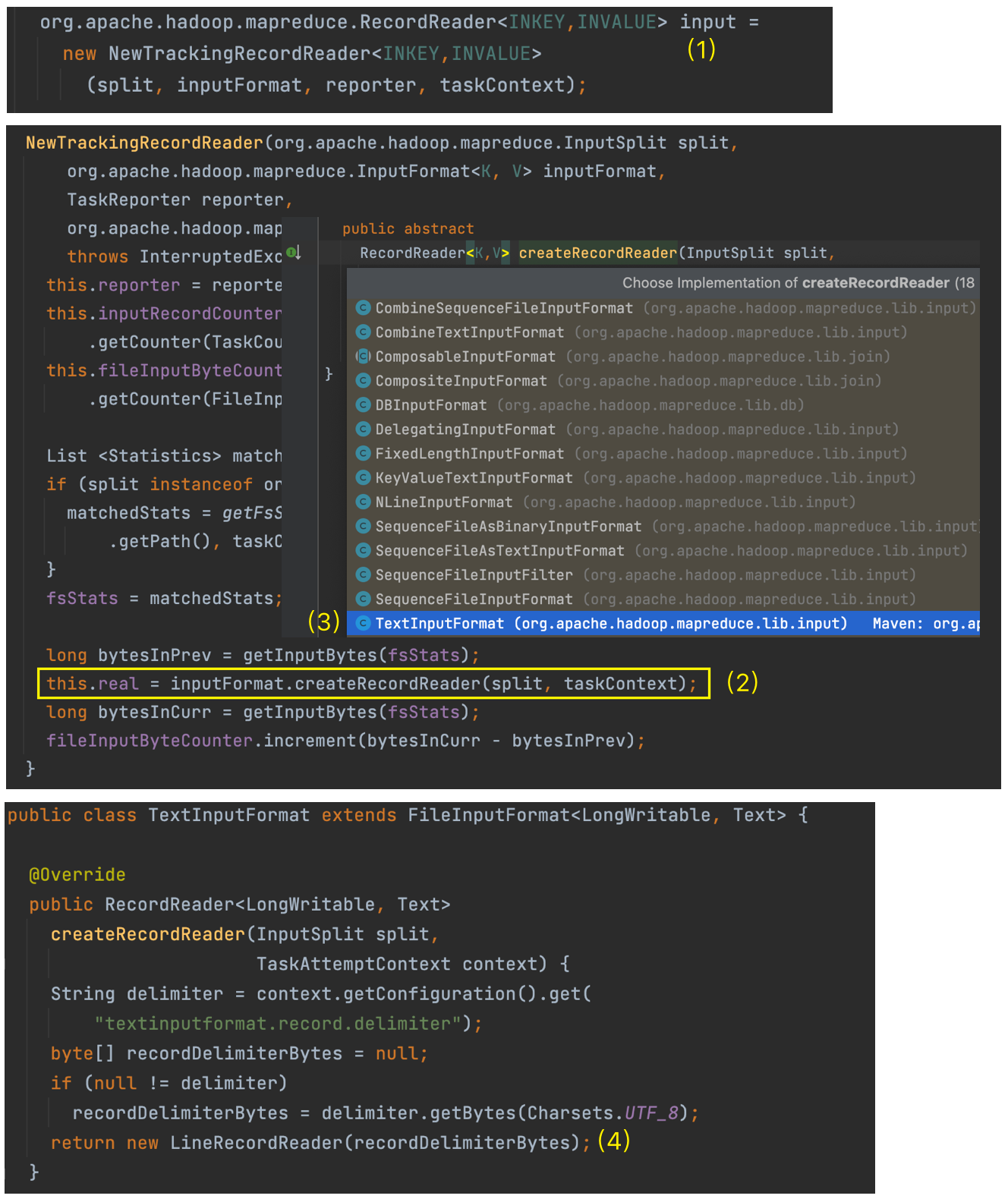
b. createRecordReader
最终负责读取切片数据的是 RecordReader 类,默认实现是 LineRecordReader。其名字已经透露出来其读取数据的行为是:一行一行按行读取数据。
在 LineRecordReader 中,核心的方法有: initialize() 初始化、nextKeyValue() 读取数据。
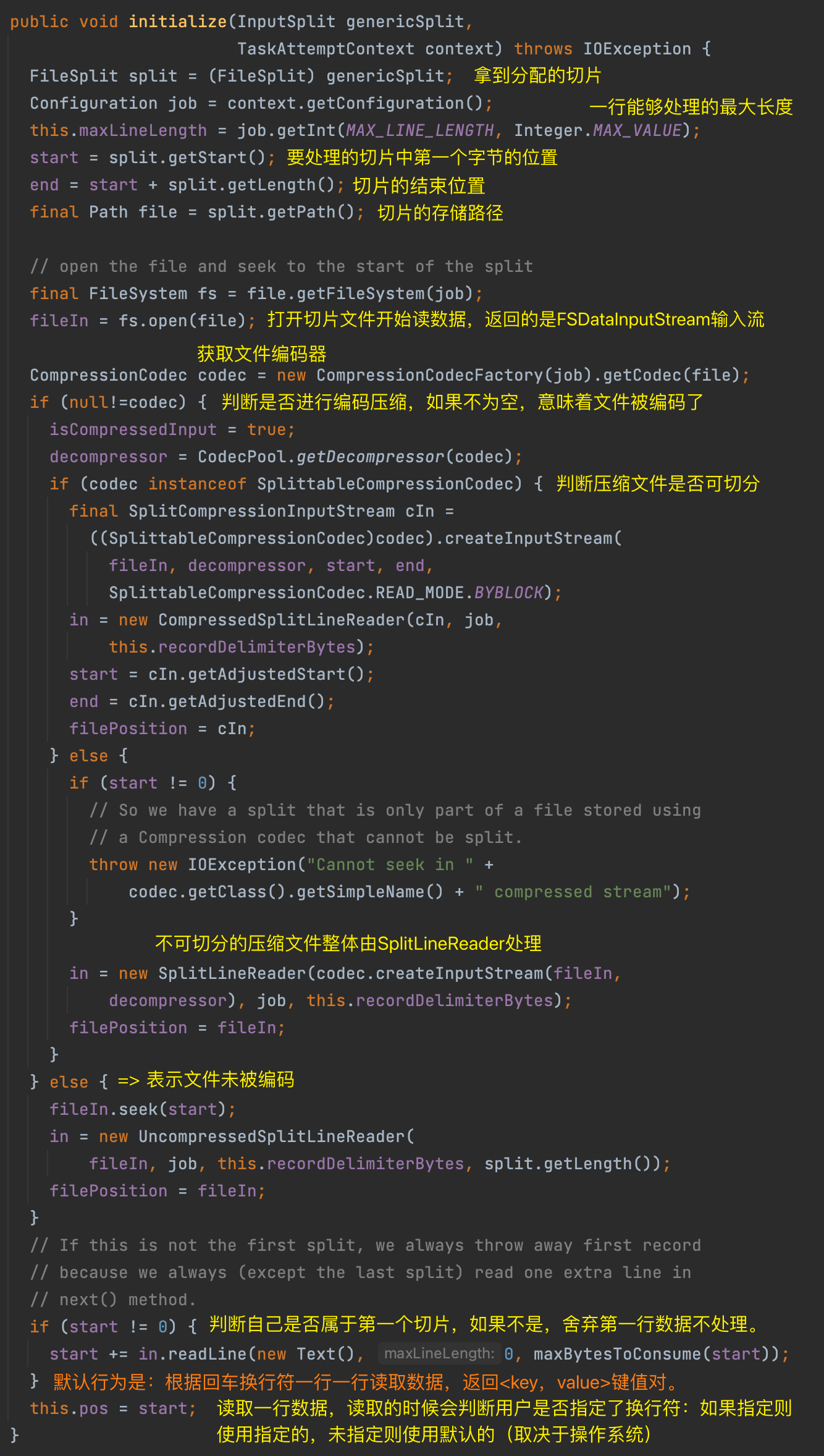

由于文件在 HDFS 上进行存储的时候,物理上会进行分块存储,这可能会导致文件内容的完整性被破坏。为了避免这个问题,在实际读取 split() 数据的时候,每个 maptask 会进行读取行为的调整,具体来说:
- 每个 maptask 都多处理下一个 split() 的第一行数据;
- 除了第一个,其余每个 maptask 都舍去自己的第一行数据不处理。
2.3 Mapper
Mapper 中有 3 个方法,分别是 setup() 初始化方法、map() 方法、cleanup() 扫尾清理方法。而 maptask 的业务处理核心是在 map() 方法中定义的。用户可以在自定义的 Mapper 中重写父类的 map() 方法逻辑。
对于 map() 方法,如果用户不重写,父类中也有默认实现逻辑。其逻辑为:输入什么,原封不动的输出什么,也就意味着不对数据进行任何处理。
此外还要注意,map() 方法的调用周期、次数取决于父类中 run() 方法。当 LineRecordReader.nextKeyValue() 返回 true 时,意味着还有数据,LineRecordReader 每读取一行数据,返回一个 kv 键值对,就调用一次 map 方法。
因此得出结论:map 阶段默认情况下是基于行处理输入数据的。
2.4 OutputCollector
map 最终调用 context.write() 方法将结果输出。
至于输出的数据到哪里,取决于 MR 程序是否有 reduce 阶段?
- 如果有 reduce 阶段,则创建输出收集器 OutputCollector 对结果收集;
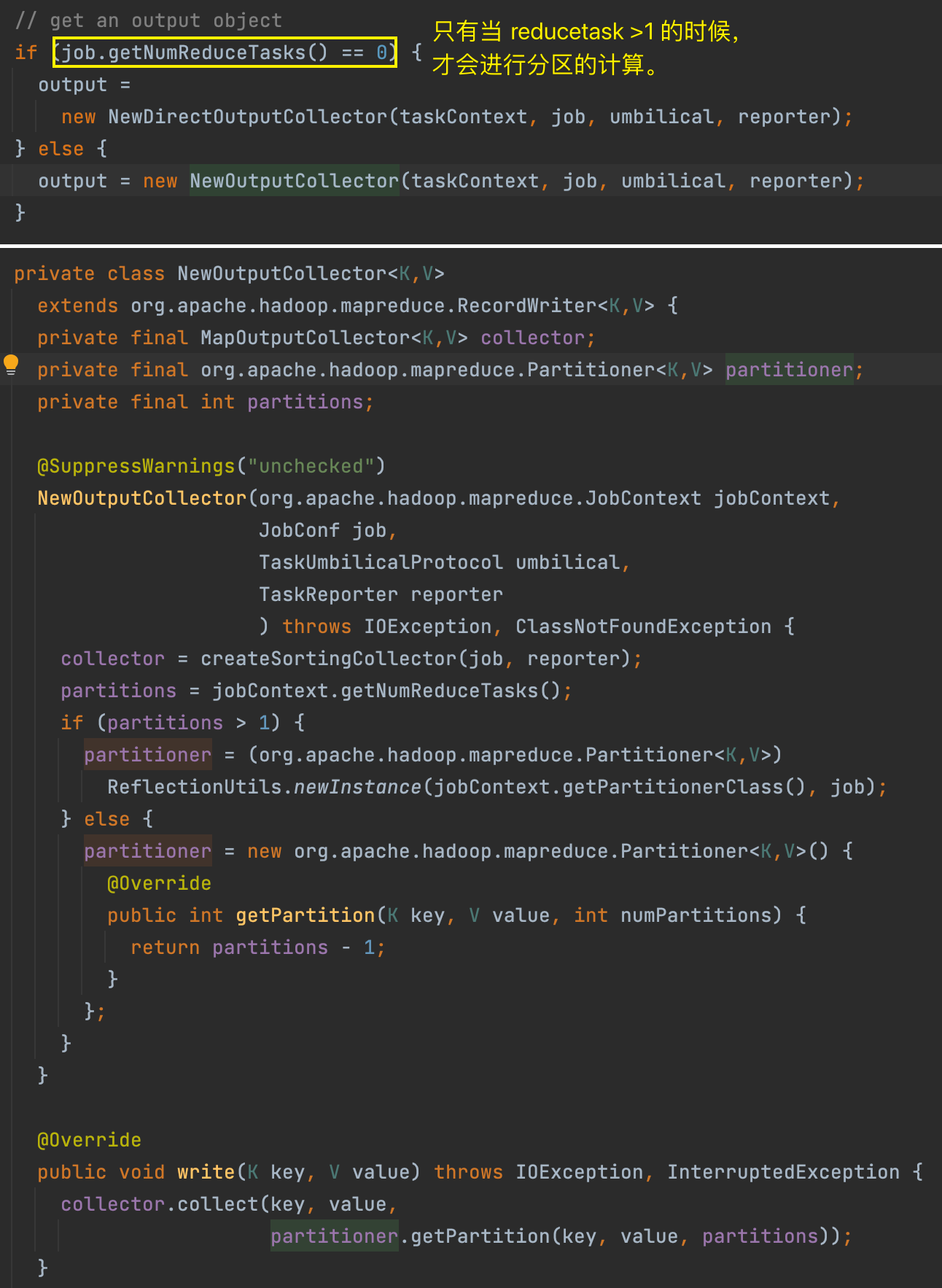
- 如果无 reduce 阶段,则创建 OutputFormat,默认实现是 TextOutputFormat,直接将处理的结果输出到指定目录文件中。
我们关注的重点当然是带有 reduce 阶段的 MR 程序,否则程序到此就结束了。进入 NewOutputCollector 构造方法,核心方法是 createSortingCollector()。此外还确定了程序是否需要进行分区以及分区的实现类是什么。
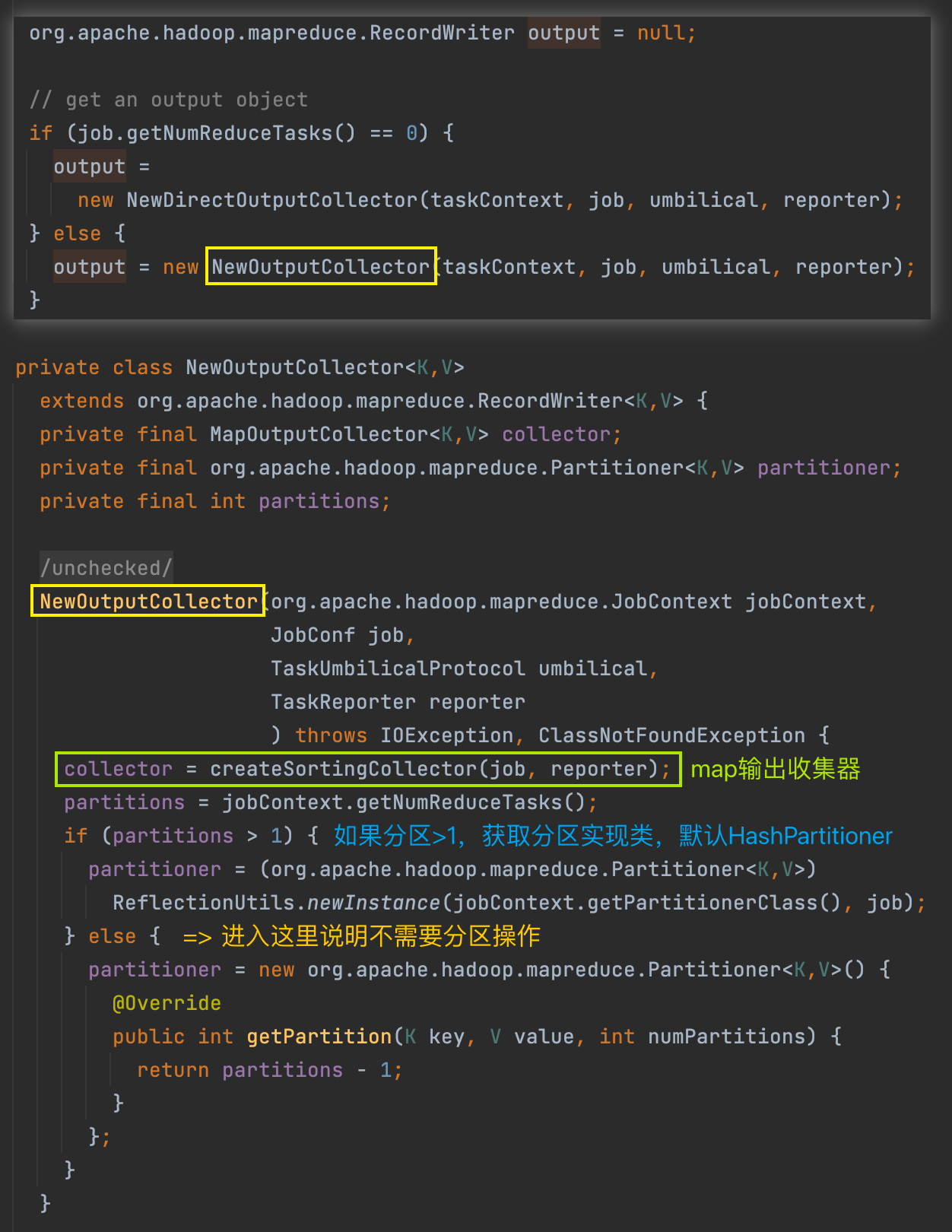
在 createSortingCollector() 方法内部,核心是创建具体的输出收集器 MapOutputBuffer,也就是口语中俗称的 map 输出的内存缓冲区。即在有 reduce 阶段的情况下,map 的输出结果不是直接写入磁盘的,还是先写入内存的缓冲区中。
当创建好 MapOutputBuffer 之后,在返回给 MapTask 之前对其进行了 init 初始化。

a. Partitioner
在 MR 程序的 map 阶段 context.write(...) 打上断点,追踪一下输出的数据进行了哪些操作。
不断进入发现,最终调用的是 MapTask 中的 write() 方法,该方法会把输出的数据 kv 通过收集器写入了环形缓冲区,在写入之前这里还进行了数据分区计算。
默认的分区器在 JobContextImpl 中定义,是 HashPartitioner。
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
// 为了避免hashcode值为负数,通过和Integer最大值进行与计算修正hashcode为正。
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
b. Circular Buffer
环形缓冲区(Circular buffer)的环形是一个抽象概念。缓冲区的作用是批量收集 Mapper 的输出结果,减少磁盘 IO 的影响。想一下,一个一个写和一个批次一个批次写,哪种效率高?
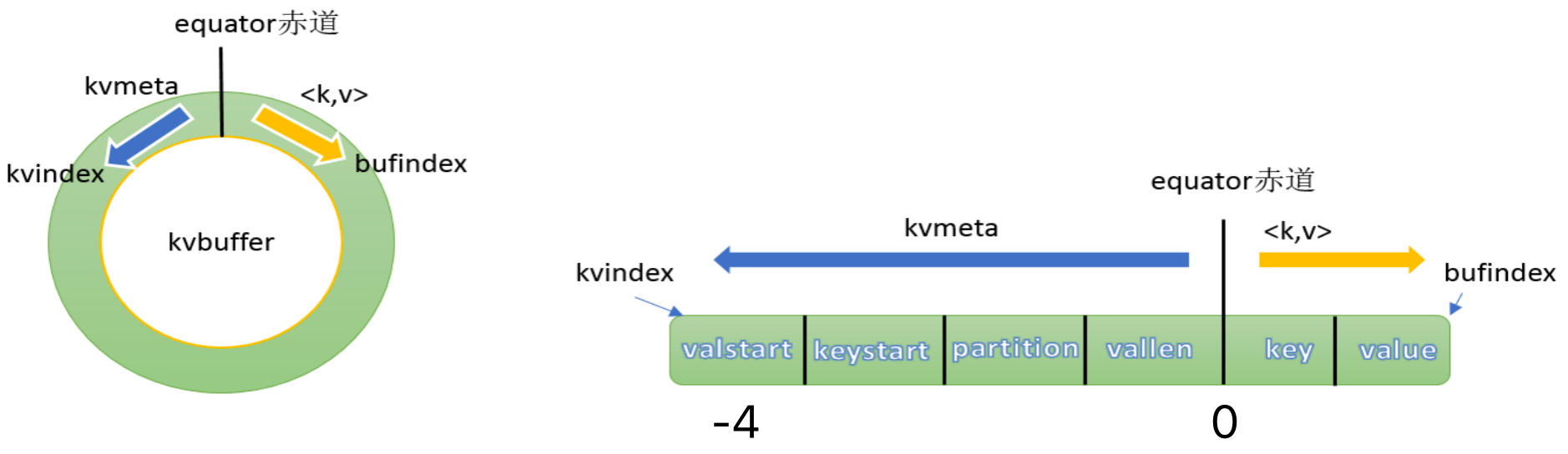
环形缓冲区本质是 byte[] 数组,里面存放着 key、value 的序列化数据和 key、value 的元数据信息。
private IntBuffer kvmeta; // 【存储元数据信息】metadata overlay on backing store
int equator; // 【分割标识】因为meta数据和key value内容都存放在同一个环形缓冲区,所以需要分隔开
byte[] kvbuffer; // 【内存缓冲区的核心】存储k/v序列化之后的数据
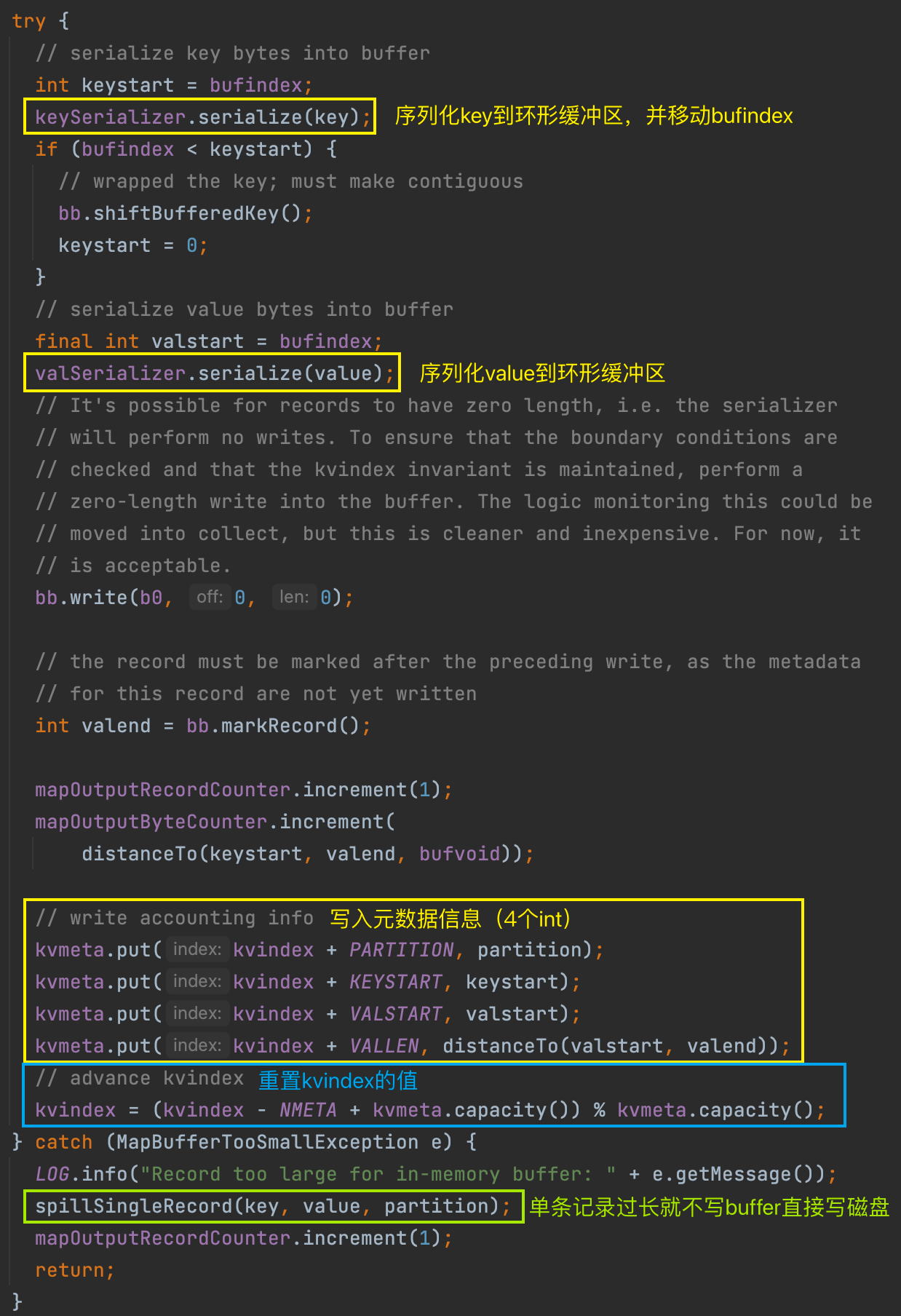
每个 key/value 都对应一个元数据,元数据由 4 个 int 组成:value 的起始位置、key 的起始位置、partition、value 的长度。
/**
* 一个key/value键值对对应一条元数据,一条元数据由4个int组成。
* 第一个存放value的起始位置(VALSTART)
* 第二个存放key的起始位置(KEYSTART)
* 第三个存放partition(PARTITION)
* 第四个存放value的长度(VALLEN)
* 以此类推,然后下面4个int是下一个kv的元数据。
*/
private static final int VALSTART = 0; // val offset in acct
private static final int KEYSTART = 1; // key offset in acct
private static final int PARTITION = 2; // partition offset in acct
private static final int VALLEN = 3; // length of value
key/value 序列化的数据和元数据在环形缓冲区中的存储是由「equator(赤道)」分隔的。是相邻不重叠的两个区域。
key/value 按照索引递增的方向存储,meta 则按照索引递减的方向存储,将其数组抽象为一个环形结构之后,以 equator 为界,key/value 顺时针存储,meta 逆时针存储。数据的索引叫做 bufindex,元数据的索引叫做 kvindex。
环形缓冲区是有大小限制,默认是 100MB。由参数 mapreduce.task.io.sort.mb 控制。
kvindex 每次都是向下跳 4 个“格子”,然后再向上一个格子一个格子地填充四元组的数据。比如 kvindex 初始位置是 -4,当第一个写完之后,(kvindex+0) 的位置存放 value 的起始位置、(kvindex+1) 的位置存放 key 的起始位置、(kvindex+2) 的位置存放 partition 的值、(kvindex+3) 的位置存放 value 的长度,然后 kvindex 跳到 -8 位置。
初始化
在 MapTask 中创建 OutputCollector(实现是 MapOutputBuffer)的时候,对环形缓冲区进行了初始化的动作:collector.init(context)。
初始化的过程中,主要是构造环形缓冲区的抽象数据结构。包括不限于:设置缓冲区大小、溢出比、初始化 kvbuffer/kvmeta、设置 equator 标识分界线、构造排序的实现类、Combiner、压缩编码等。

数据收集
Mapper 的 map() 方法处理完数据之后,是调用 context.write() 方法将结果进行输出。debug 不断进入发现,最终调用的是 MapTask 中的 write() 方法。
@Override
public void write(K key, V value) throws IOException, InterruptedException {
collector.collect(key, value, partitioner.getPartition(key, value, partitions));
}
在 write() 方法中,调用 collector.collect() 向环形缓冲区中写入数据,数据写入之前也进行了分区 partition 计算。在有 reduce 阶段的情况下,collector 的实现是 MapOutputBuffer。
收集数据到环形缓冲区核心逻辑有:序列化 key 到字节数组、序列化 value 到字节数组、写入该条数据的元数据(起始位置、partition、长度)、更新 kvindex。
c. Spill、Sort
Spill 溢写
环形缓冲区虽然可以减少 IO 次数,但是总归有容量限制,不能把所有数据一直写入内存,数据最终还是要落入磁盘上存储的,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。
这个“从内存往磁盘写数据”的过程被称为 Spill,中文可译为「溢写」。
这个溢写是由单独线程来完成,不影响往缓冲区继续写数据。整个缓冲区有个溢写的比例 spill.percent(默认 0.8),也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),spill 线程启动。
spill 线程是由 startSpill() 方法唤醒的,在进行 spill 操作的时候,map 向 buffer 的写入操作并没有阻塞,剩下 20M 可以继续使用。
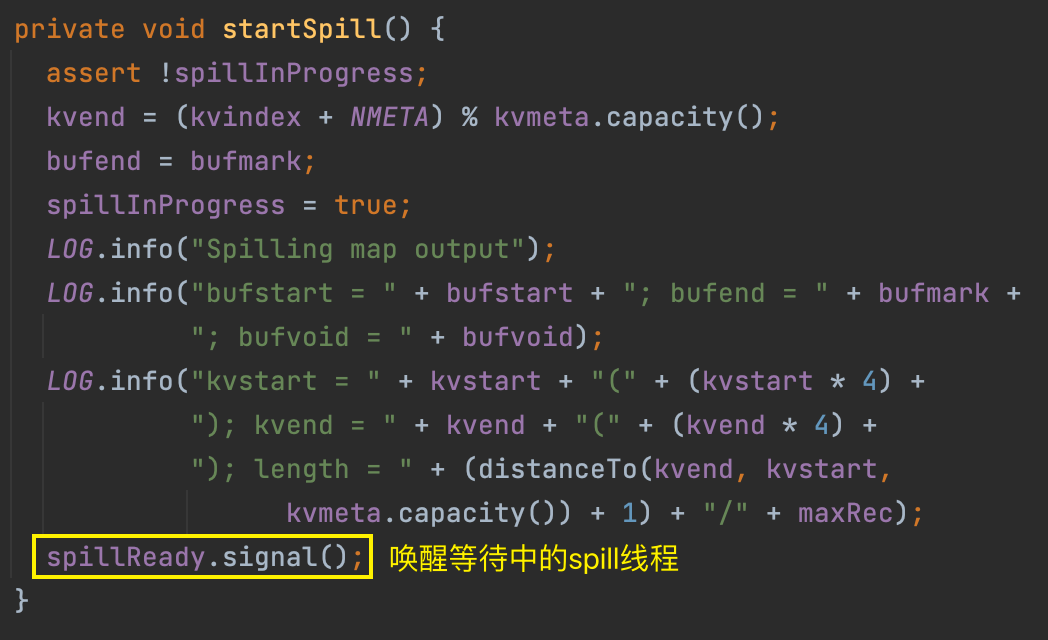
溢写的线程叫做 SpillThread,查看其 run() 方法,run() 中主要是 sortAndSpill()。
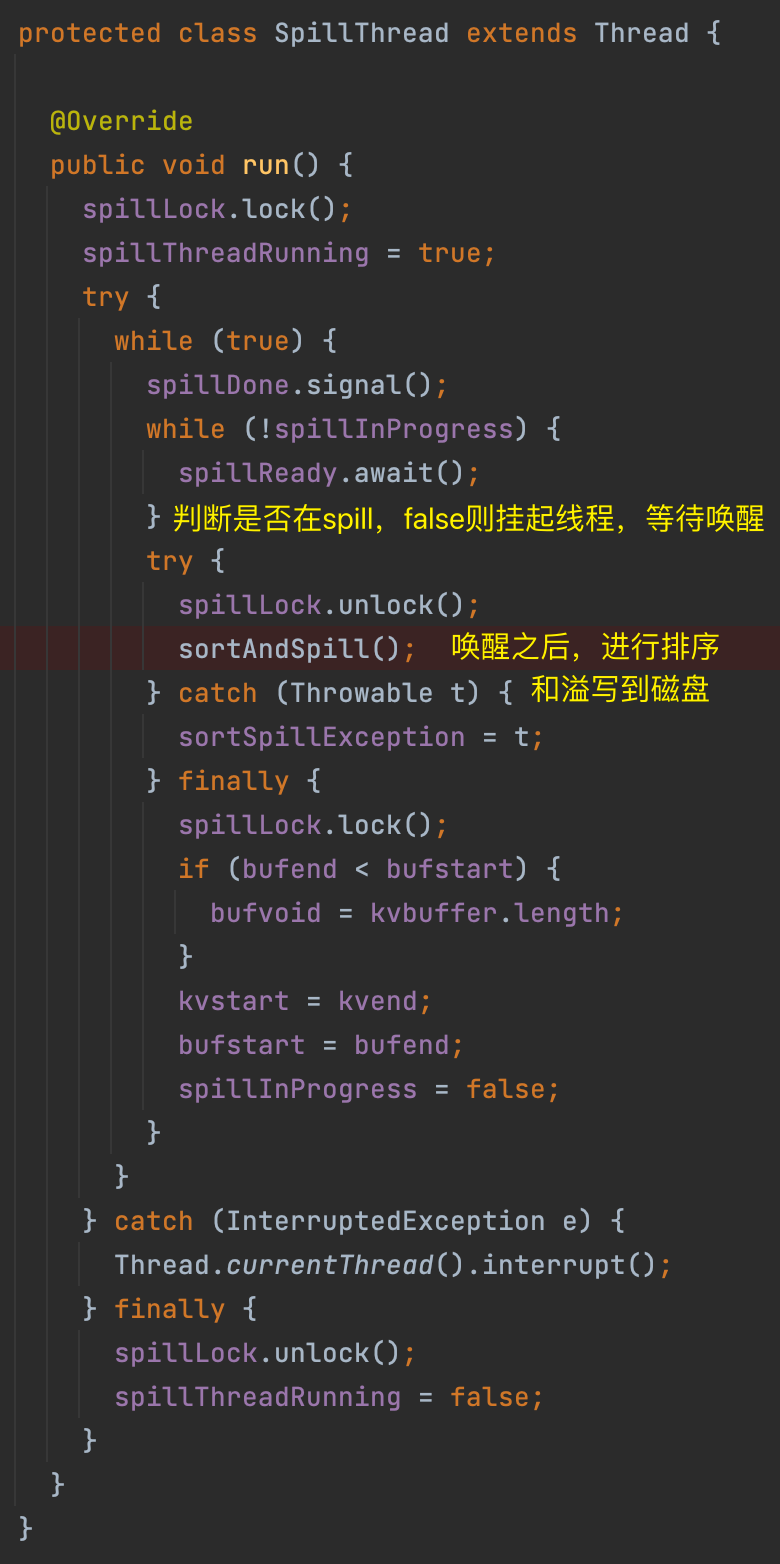
创建溢写记录(索引)、溢写文件(该文件位于机器的本地文件系统,而不是 HDFS)。
SpillThread 输出的每个 spill 文件都有一个索引,其中包含有关每个文件中分区的信息:分区的开始位置和结束位置。这些索引存储在内存中,叫做 SpillRecord 溢写记录,可使用内存量为 mapreduce.task.index.cache.limit.bytes,默认情况下等于 1MB。
在 spill 的同时,Mapper 往 buffer 的写操作并没有停止,依然在调用 collect。满足条件继续 spill,以此往复。
Sort 排序
在溢写的过程中,会对 kvmeta 元数据进行排序。排序规则是 MapOutputBuffer.compare()。
sorter.sort(MapOutputBuffer.this, mstart, mend, reporter);
先对 partition 进行排序,其次对 key 值排序。这样,数据首先按分区排序,然后在每个分区内按 key 对数据再排序。
Spill 线程根据排过序的 kvmeta 逐个分区的把数据溢出到磁盘临时文件中,一个 partition 对应的数据写完之后顺序地写下个 partition,直到把所有的 partition 遍历完。

d. Merge
每次 spill 都会在磁盘上生成一个临时文件,如果 map 的输出结果真的很大,有多次这样的 spill 发生,磁盘上相应的就会有多个临时文件存在。这样将不利于 reducetask 处理数据。
当 Mapper 和最后一次溢出都结束时,溢出线程终止,合并(merge)阶段开始。在合并阶段,会将所有溢出文件合并在一起以确保最终一个 maptask 对应一个输出结果文件。
默认情况下,一个合并过程最多可以处理 100 个溢出文件(负责此操作的参数是 mapreduce.task.io.sort.factor,默认 10)。如果超过,将进行多次 merge 合并。
最终一个 maptask 的结果是一个输出文件,其中包含 map 的所有输出数据以及索引文件,索引文件描述了 ReduceTask 的分区开始-停止信息,以便能够轻松获取与其将运行的相关分区数据。
2.5 Combiner
Combiner(规约)的作用就是对 map 端的输出先做一次局部合并,以减少在 map 和 reduce 节点之间的数据传输量,以提高网络 IO 性能,是 MapReduce 的一种优化手段之一。默认情况下不开启。
当 Job 设置了 Combiner,可能会在 spill 和 merge 的两个阶段执行。
spill 时 Combiner 执行情况源码:

merge 时 Combiner 执行情况源码(MapTask 中搜 mergeParts() 方法):

3. Reduce 阶段执行流程
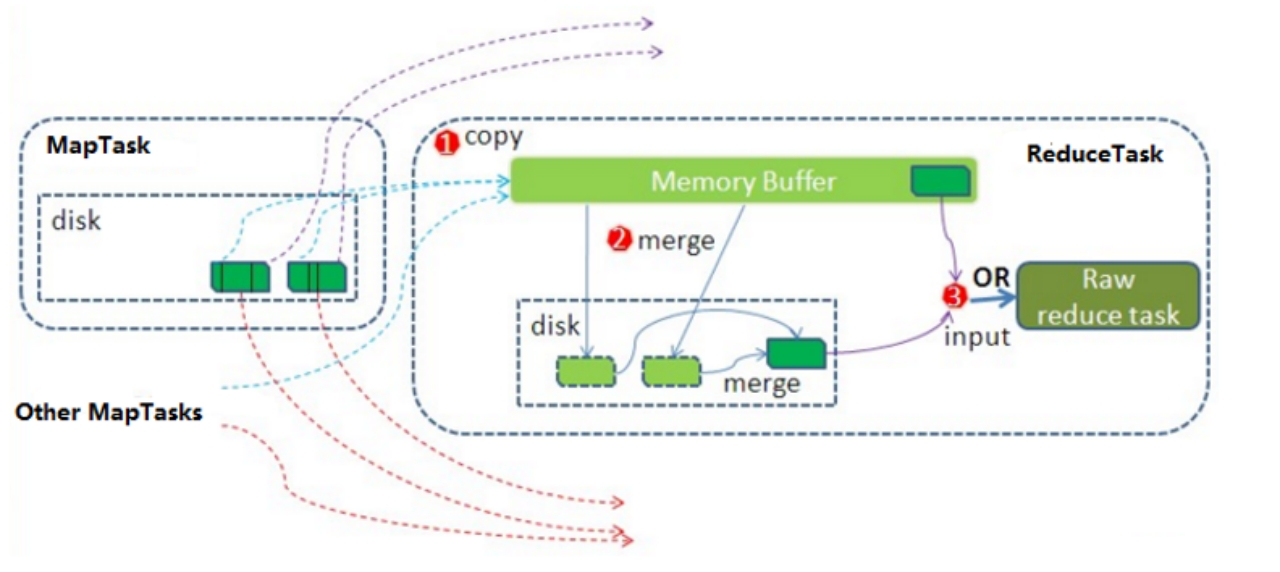
3.1 ReduceTask 执行流程
ReduceTask 类作为 reducetask 的一个载体,调用的就是里面的 run() 方法,然后开启 reduce 任务。
(1)任务划分
整个 reducetask 分为 3 个阶段:copy 拉取数据、sort 排序数据、reduce 处理数据。
(2)shuffle 操作
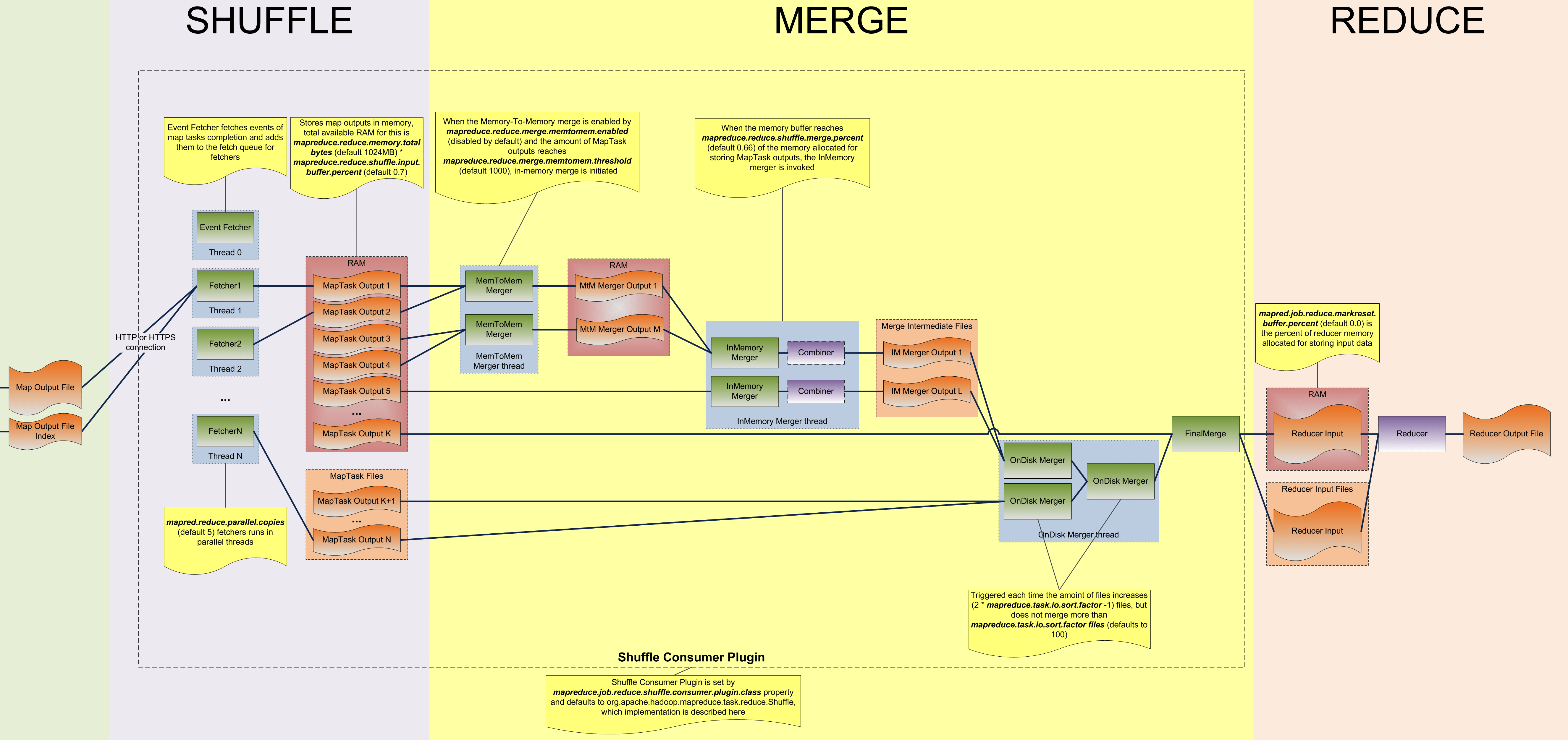
整个 shuffle 操作过程除了 shuffle 核心任务之外,还创建了 reducetask 工作相关的一些组件。
对于 MapReduce 程序来说,MapTask 输出的结果并不会主动发送给各个 ReduceTask。因此需要各个 ReduceTask 主动到各个 Map 端拉取属于自己分区的数据。从拉取数据开始到 reduce() 方法处理数据之前,称之为 reduce 端的 shuffle 操作。包括 copy、merge、sort。
在 ReduceTask#run() 中跟 shuffle 相关的操作,除了 shuffle 核心任务之外还创建了 reducetask 工作相关的一些组件,包括但不限于:
- codec 解编码器
- CombineOutputCollector 输出收集器
- shuffleConsumerPlugin(负责 reduce 端 shuffle 插件)
- shuffleContext 上下文对象
- GroupingComparator 分组比较器
(3)执行 Reducer
shuffle 完的结果将进入到 Reducer 进行最终的 reduce 处理。
3.2 Shuffle
a. init
注意 ShuffleConsumerPlugin 是一个接口,默认的实现只有一个 Shuffle.class,其完整定义了整个 reduce 阶段 shuffle 的完整过程。
在 ReduceTask 类中,和 ShuffleConsumerPlugin 相关的操作就两个方法:init 初始化、run 运行。
初始化的过程中,核心逻辑就是创建 MergeManagerImpl 类。在 MergeManagerImpl 类中,核心的有:确定 shuffle 时的一些条件、是否允许内存到内存合并、启动两个 merge 线程,分别为 inMemoryMerger 和 onDiskMerger,分别将内存中的数据 merge 到磁盘和将磁盘中的数据进行。

(1)shuffle 条件

(2)启动 MemToMemMerge
因为 fetch 来数据首先放入在内存中的,正常情况下在内存中对数据进行合并是最快的,可惜的是,默认情况下,是不开启内存到内存的合并的。

(3)启动 inMemoryMerger/onDiskMerger

b. run
注意 ShuffleConsumerPlugin 是一个接口,默认的实现只有一个 Shuffle.class。

(1)eventFetcher 线程

(2)fetchers 线程

c. copy
reduce 进程启动一些数据 copy 线程(Fetcher),通过 HTTP 方式请求 maptask 获取属于自己的文件。如果是本地模式运行,启动一个 fetcher 线程拉取数据,否则启动 5 个线程并发拉取。

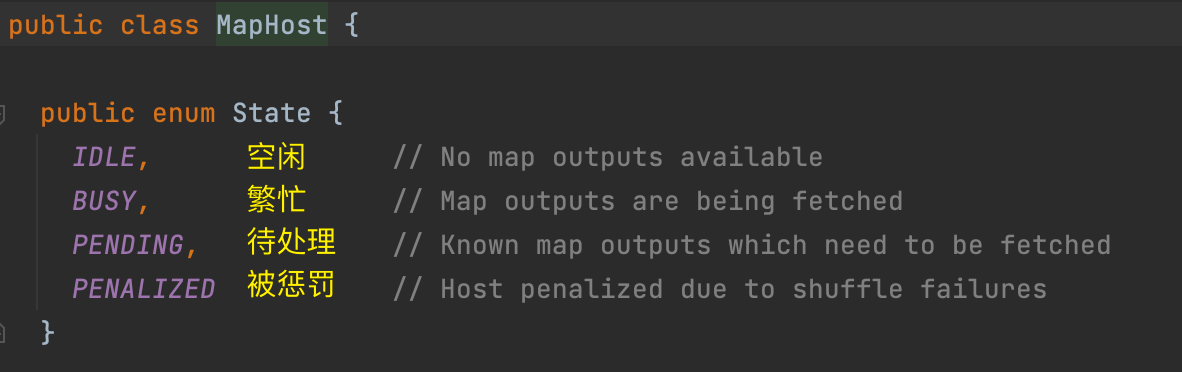
(1)MapHost 类
MapHost 类用于标记 MapTask 任务状态,记下 MapTask host 信息。
(2)Fetcher.run()
获得所有 maptask 处于 PENDING 待处理状态的主机。然后进入核心方法 copyFromHost(),从 map 拉取数据。
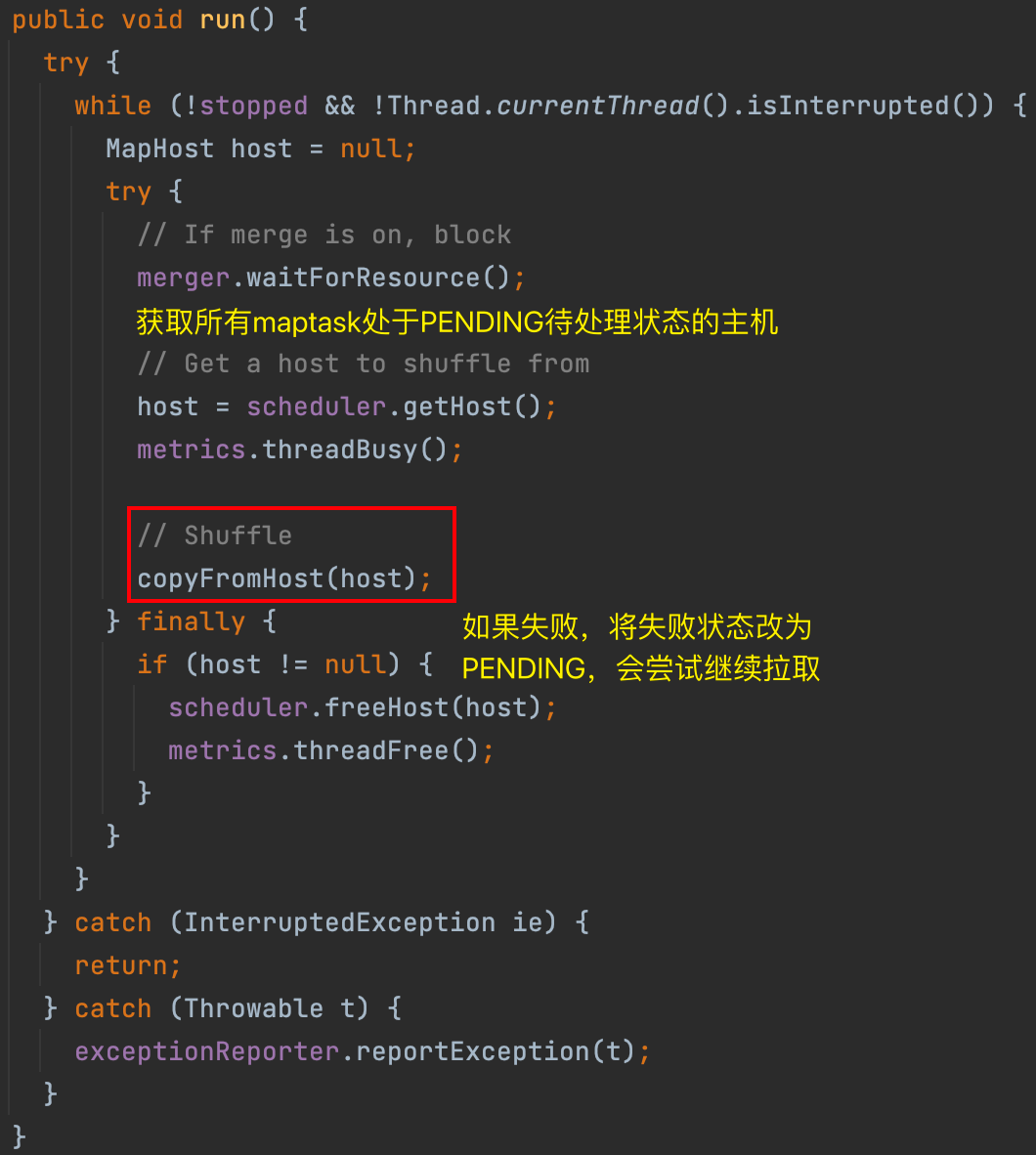
copyFromHost()
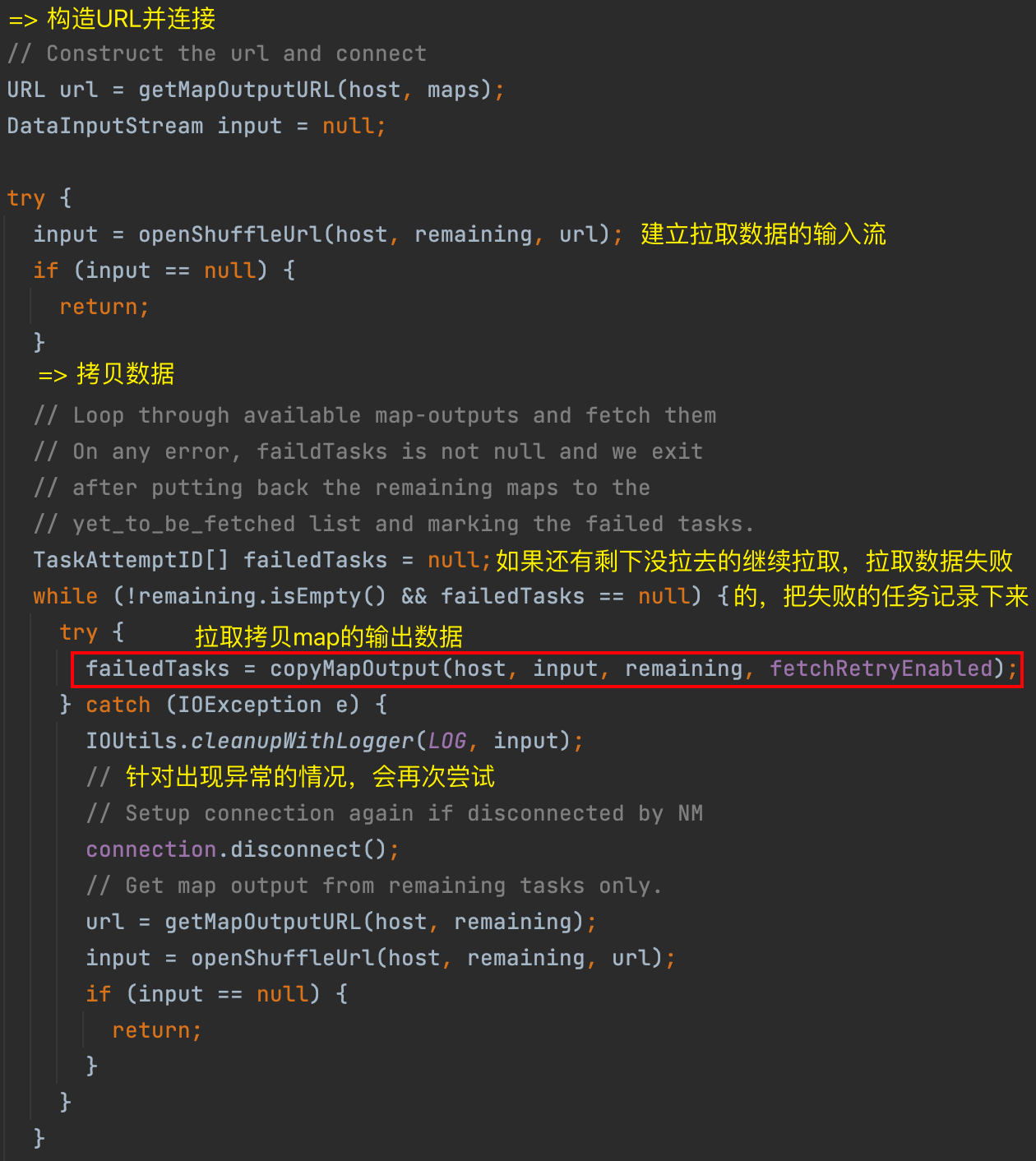
copyMapOutput()
// 首先进行判断copy过来的数据放置在哪里?优先内存,超过限制放置磁盘。
mapOutput = merger.reserve(mapId, decompressedLength, id);
// 因此获得的mapOutput就有两种具体的实现。通过mapOutput.shuffle()开始拉取数据。
mapOutput.shuffle(host, is, compressedLength, decompressedLength, metrics, reporter);
// 不断追踪下去,最终是两种不同的实现:
// - InMemoryMapOutput 把copy来的数据放置到reducetask内存中
// - OnDiskMapOutput 把copy来的数据放置到磁盘上
d. merge
在启动 Fetcher 线程 copy 数据过程中已经启动了两个 merge 线程,分别为 inMemoryMerger 和 onDiskMerger,分别将内存中的数据 merge 到磁盘和将磁盘中的数据进行 merge。
可以从 Shuffle. init => createMergeManager => new MergeManagerImpl 中确定。

当所有的 Fetcher 拉取数据结束之后,会进行最终一次合并,最终合并的所有数据保存在 kvIter。可以在 Shuffle 类的 run() 中发现。
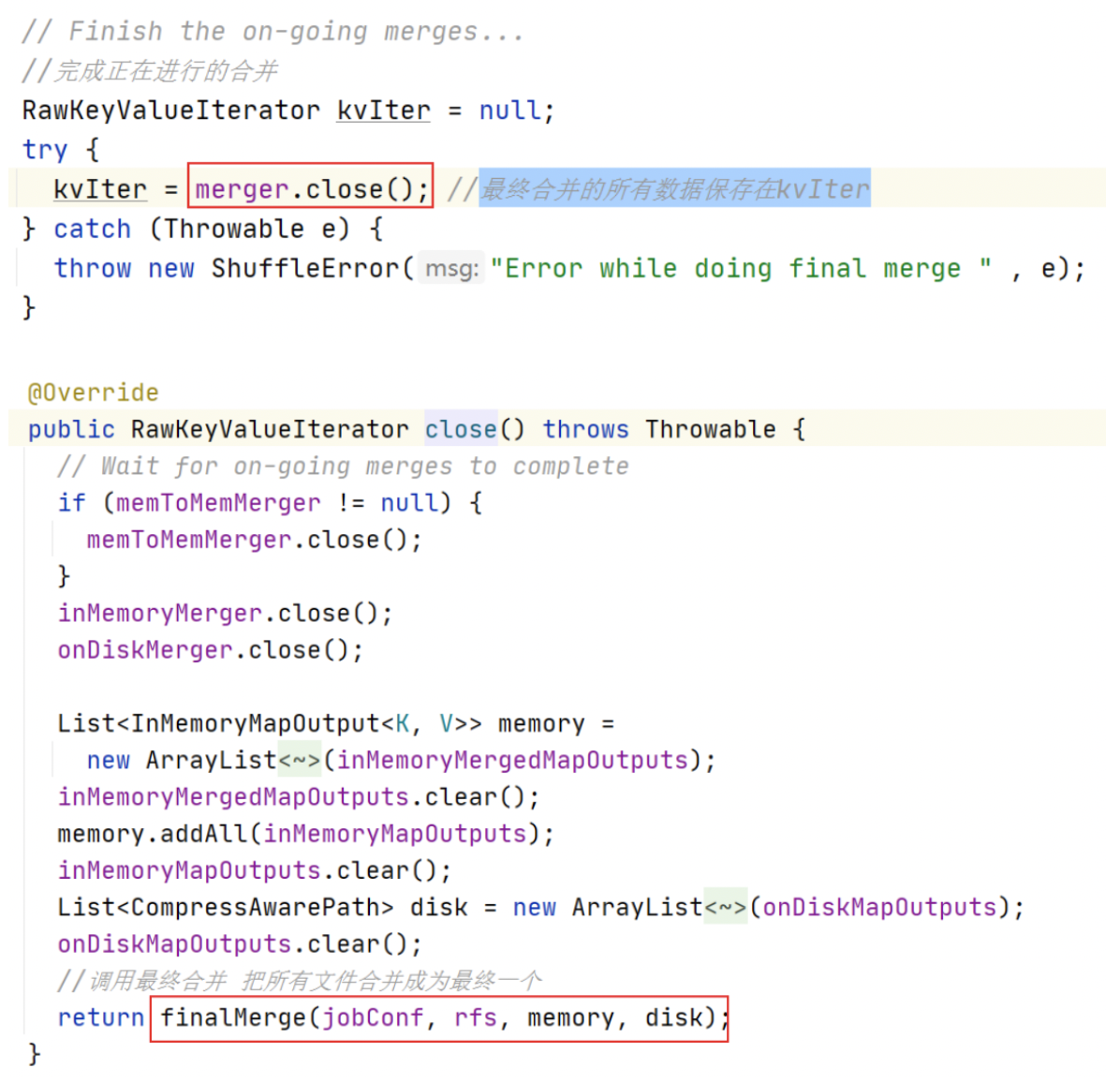
e. sort
在合并的过程中,会对数据进行 sort 排序,默认情况下是 key 的字典序(WritableComparable),如果用户设置比较器,则以用户设置的为准。

3.3 Reducer
当合并排序结束之后,进入到 reduce 阶段。
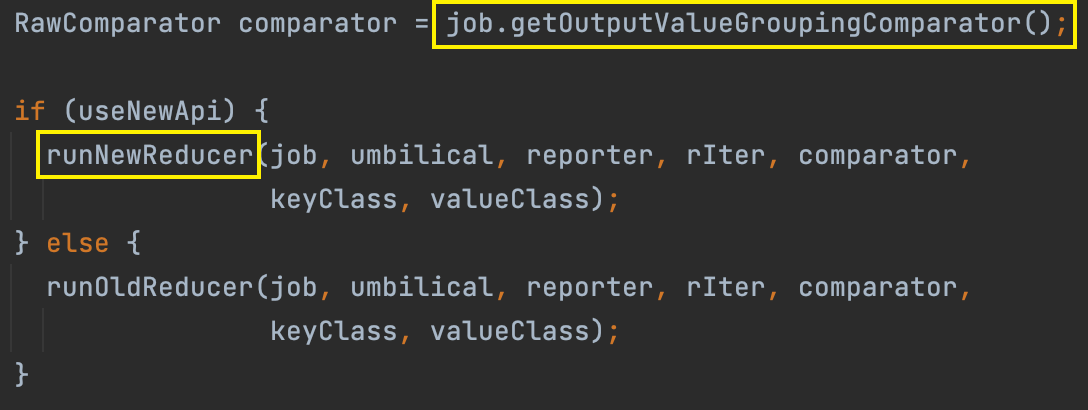
a. run
在 runNewReducer() 方法的最后,调用了 Reducer.run() 方法运行 Reducer。

首先在 Reduce.run() 中调用 context.nextKey() 决定是否进入 while,然后调用 nextKeyValue() 将 key/value 的值从 input 中读出,其次通过 context.getValues() 将 Iterator 传入 reduce() 中,在 reduce() 中通过 Iterator.hasNext() 查看此 key 是否有下个 value,然后通过 Iterator.next() 调用 nextKeyValue() 去 input 中读取 value。
然后循环迭代 Iterator,读取 input 中相同 key 的 value。也就是说 reduce() 中相同 key 的 value 值在 Iterator.next() 中通过 nextKeyValue() 读取的,每调用一次 next() 就从 input 中读一个 value。
通俗理解:key 相同的被分为一组,一组中所有的 value 会组成一个 Iterable。key 则是当前的 value 与之对应的 key。
b. reduce
对于 reduce() 方法,如果用户不重写,父类中也有默认实现逻辑。其逻辑为:输入什么,原封不动的输出什么,也就意味着不对数据进行任何处理。

通常会基于业务需求重新父类的 reduce() 方法。
3.4 OutputFormat
reduce 阶段的最后是通过调用 context.write() 方法将数据写出的。
负责输出数据的组件叫做 OutputFormat,默认实现是 TextOutPutFormat。而真正负责写数据的组件叫做 LineRecordWriter,write() 方法就定义在其中,这一点和输入组件很是类似。
LineRecordWriter 的行为是一次输出写一行,再有输出换行写。在构造 LineRecordWriter 时,已经设置了输出的 key/value 之间是以 \t 制表符分割的。
4. Shuffle
Shuffle 的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。而在 MapReduce 中,Shuffle 更像是洗牌的逆过程,指的是将 map 端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便 reduce 端接收处理。
Shuffle 是什么?
Shuffle 是 Mapreduce 的核心,它分布在 Mapreduce 的 map 阶段和 reduce 阶段。
- 广义上的 shuffle 指的是 map 方法产生输出开始,这样就包括:Partition、Spill、Sort、Merge|Copy、Merge、Sort;
- 狭义上的 shuffle 指的是 maptask 结束产生中间结果开始,这样就只包括 reduce 阶段的 Copy、Merge、Sort。
Shuffle 子过程概述:
- 【Collect】将 MapTask 的结果输出到默认大小为 100M 的环形缓冲区,保存的是 key/value,Partition 分区信息等。
- 【Spill】当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了 Combiner,还会将有相同分区号和 key 的数据进行排序。
- 【Merge】把所有溢出的临时文件进行一次合并操作,以确保一个 MapTask 最终只产生一个中间数据文件。
- 【Copy】ReduceTask 启动 Fetcher 线程到已经完成 MapTask 的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
- 【Merge】在 ReduceTask 远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
- 【Sort】在对数据进行合并的同时,会进行排序操作,由于 MapTask 阶段已经对数据进行了局部的排序,ReduceTask 只需保证 Copy 的数据的最终整体有效性即可。
Shuffle 的弊端:
- shuffle 阶段过程繁琐、琐碎,涉及了多个阶段的任务交接;
- shuffle 中频繁进行数据内存到磁盘、磁盘到内存、内存再到磁盘的过程,效率极低;
- shuffle 阶段大量的数据从 map 阶段输出,发送到 reduce 阶段,这一过程中可能会涉及到大量的网络 IO。