这次来学习深度学习吧!
1 训练前
1.1 神经元与神经网络
神经元是神经网络的基本单位, 模拟了生物神经元的工作机制. 每个神经元接受一组输入, 将这些输入与其权重相乘, 然后对所有的乘积求和, 并加上一个偏置. 最后, 将得到的结果传递给激活函数.
神经网络由多个神经元组成, 这些神经元按层次结构排列: 输入层, 一个或多个隐藏层和输出层. 神经网络可以学习从输入到输出的映射, 这通常涉及大量的数据和迭代训练.
1.2 激活函数
是一个非线性函数, 用于确定神经元的输出. 由于激活函数的非线性特性, 多层神经网络能够捕捉并学习非线性关系. 常见的激活函数包括:
- ReLU
- Sigmoid
- Softmax
- Tanh
1.3 层
输入层是神经网络的第一层, 负责接收特征数据. 它不进行任何计算, 只是传递数据.
输出层是神经网络的最后一层, 负责生成最终的预测或分类结果. 输出层的神经元数量取决于任务类型.
在输入层和输出层之间的层称为隐藏层. 这些层的神经元执行计算, 并使用激活函数来确定其输出. 神经网络可以有多个隐藏层, 这使得网络能够学习更复杂的表示.
全连接层 (dense) 指的是每一个神经元与前一层的所有神经元都连接.
1.4 损失函数与优化器
也称为代价函数或目标函数, 损失函数量化模型预测的结果与实际标签之间的差异. 它为模型提供了一个明确的反馈, 告诉模型它的预测有多差. 常见的损失函数包括:
- 均方误差
- 交叉熵
- Hinge Loss
一旦我们有了损失函数来度量模型的误差, 我们就需要一种方法来调整模型的权重和偏置, 以减少这种误差. 这就是优化器的作用, 优化器使用损失函数的梯度来决定如何更新模型的参数. 常见的优化器包括:
- 梯度下降
- 随机梯度下降
- Momentum
- Adam
- RMSProp
- Adagrad
1.5 批次, 轮次与迭代
批次 (Batch) 是数据集的一个子集, 用于在模型上进行一次前向和后向传播.
轮次 (Epoch) 是整个数据集完整地通过神经网络一次的过程.
迭代 (Step / Iteration) 通常是指模型在一个批次上的一次前向和后向传播.
如果数据集有 1000 个样本, 且选择的批次大小为 100, 则每个轮次需要 10 次迭代.
这些需要手动设定并可能影响模型的训练效率和最终性能的参数称为超参数.
2 训练中
2.1 过拟合
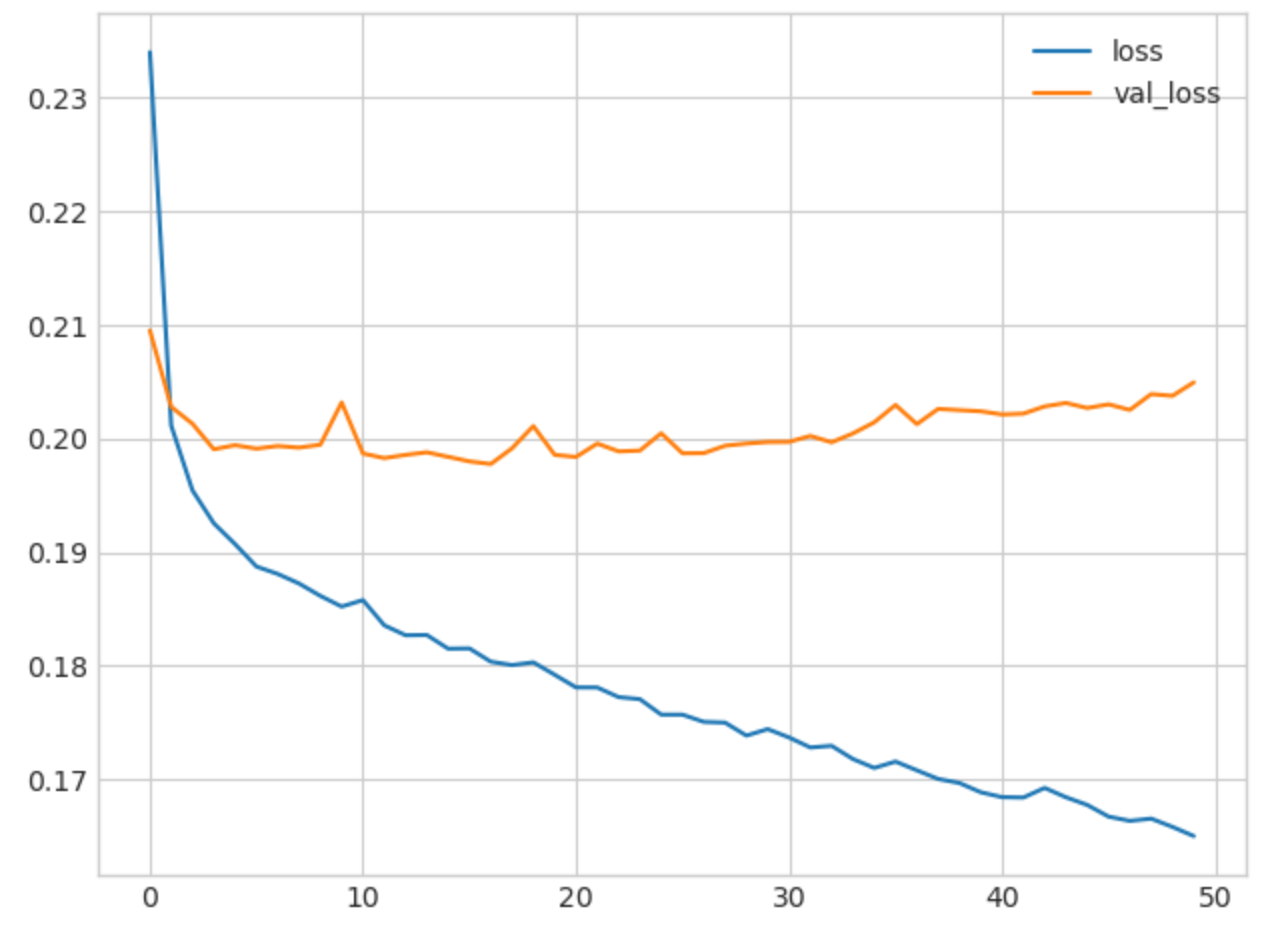
如图, 像这种损失函数变化缓慢甚至不减反增的情况表明出现了过拟合, 通常采用提前终止的方法.
early_stopping = callbacks.EarlyStopping(
min_delta=0.001, # minimium amount of change to count as an improvement
patience=5, # how many epochs to wait before stopping
restore_best_weights=True,
)
2.2 随机失活与批标准化
Dropout 是一种正则化技巧, 其在训练过程中随机 "丢弃" 神经元, 从而减少过拟合.
layers.Dropout(rate=0.3)
Batch Normalization 用于规范化前一层的输出, 使其具有近似的均值和方差, 以便提高训练的稳定性, 这可以应对数据复杂收敛值过大的情况.
layers.BatchNormalization()
3 实例
3.1 二分类
Hotel Cancellations
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
hotel = pd.read_csv('../input/dl-course-data/hotel.csv')
X = hotel.copy()
y = X.pop('is_canceled')
X['arrival_date_month'] = \
X['arrival_date_month'].map(
{'January':1, 'February': 2, 'March':3,
'April':4, 'May':5, 'June':6, 'July':7,
'August':8, 'September':9, 'October':10,
'November':11, 'December':12}
)
features_num = [
"lead_time", "arrival_date_week_number",
"arrival_date_day_of_month", "stays_in_weekend_nights",
"stays_in_week_nights", "adults", "children", "babies",
"is_repeated_guest", "previous_cancellations",
"previous_bookings_not_canceled", "required_car_parking_spaces",
"total_of_special_requests", "adr",
]
features_cat = [
"hotel", "arrival_date_month", "meal",
"market_segment", "distribution_channel",
"reserved_room_type", "deposit_type", "customer_type",
]
transformer_num = make_pipeline(
SimpleImputer(strategy="constant"), # there are a few missing values
StandardScaler(),
)
transformer_cat = make_pipeline(
SimpleImputer(strategy="constant", fill_value="NA"),
OneHotEncoder(handle_unknown='ignore'),
)
preprocessor = make_column_transformer(
(transformer_num, features_num),
(transformer_cat, features_cat),
)
# stratify - make sure classes are evenlly represented across splits
X_train, X_valid, y_train, y_valid = \
train_test_split(X, y, stratify=y, train_size=0.75)
X_train = preprocessor.fit_transform(X_train)
X_valid = preprocessor.transform(X_valid)
input_shape = [X_train.shape[1]]
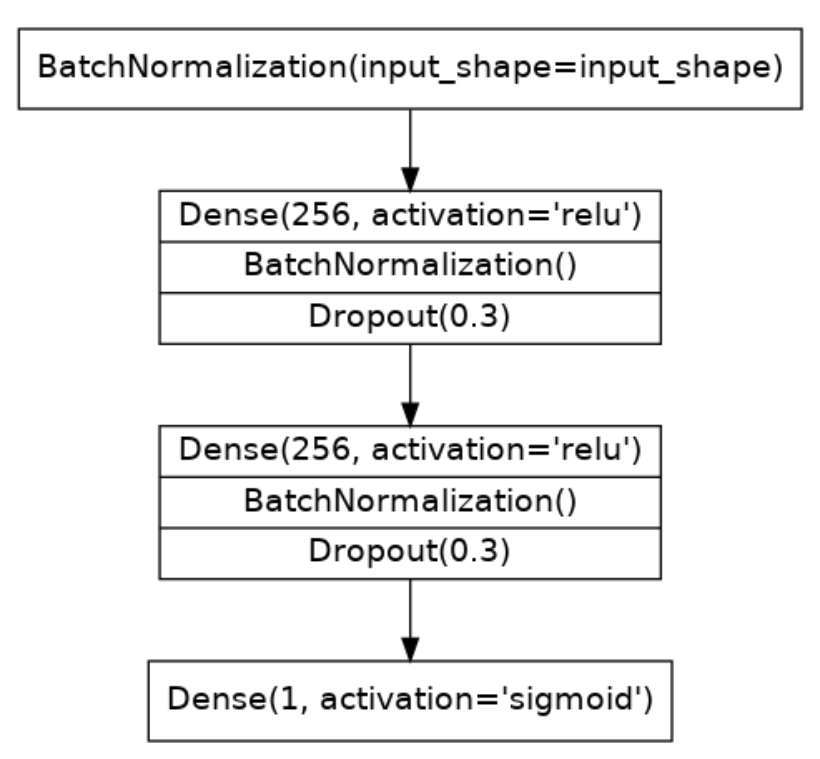
构建层
model = keras.Sequential([
layers.BatchNormalization(input_shape=input_shape),
layers.Dense(256, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(rate=0.3),
layers.Dense(256, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(rate=0.3),
layers.Dense(1, activation='sigmoid'),
])
构建损失函数与优化器
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)
训练
early_stopping = keras.callbacks.EarlyStopping(
patience=5,
min_delta=0.001,
restore_best_weights=True,
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=200,
callbacks=[early_stopping],
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot(title="Cross-entropy")
history_df.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot(title="Accuracy")

完整代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
hotel = pd.read_csv('../input/dl-course-data/hotel.csv')
X = hotel.copy()
y = X.pop('is_canceled')
X['arrival_date_month'] = \
X['arrival_date_month'].map(
{'January':1, 'February': 2, 'March':3,
'April':4, 'May':5, 'June':6, 'July':7,
'August':8, 'September':9, 'October':10,
'November':11, 'December':12}
)
features_num = [
"lead_time", "arrival_date_week_number",
"arrival_date_day_of_month", "stays_in_weekend_nights",
"stays_in_week_nights", "adults", "children", "babies",
"is_repeated_guest", "previous_cancellations",
"previous_bookings_not_canceled", "required_car_parking_spaces",
"total_of_special_requests", "adr",
]
features_cat = [
"hotel", "arrival_date_month", "meal",
"market_segment", "distribution_channel",
"reserved_room_type", "deposit_type", "customer_type",
]
transformer_num = make_pipeline(
SimpleImputer(strategy="constant"), # there are a few missing values
StandardScaler(),
)
transformer_cat = make_pipeline(
SimpleImputer(strategy="constant", fill_value="NA"),
OneHotEncoder(handle_unknown='ignore'),
)
preprocessor = make_column_transformer(
(transformer_num, features_num),
(transformer_cat, features_cat),
)
# stratify - make sure classes are evenlly represented across splits
X_train, X_valid, y_train, y_valid = \
train_test_split(X, y, stratify=y, train_size=0.75)
X_train = preprocessor.fit_transform(X_train)
X_valid = preprocessor.transform(X_valid)
input_shape = [X_train.shape[1]]
from tensorflow import keras
from tensorflow.keras import layers
model = keras.Sequential([
layers.BatchNormalization(input_shape=input_shape),
layers.Dense(256, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(rate=0.3),
layers.Dense(256, activation='relu'),
layers.BatchNormalization(),
layers.Dropout(rate=0.3),
layers.Dense(1, activation='sigmoid'),
])
model.compile(
optimizer='adam',
loss='binary_crossentropy',
metrics=['binary_accuracy'],
)
early_stopping = keras.callbacks.EarlyStopping(
patience=5,
min_delta=0.001,
restore_best_weights=True,
)
history = model.fit(
X_train, y_train,
validation_data=(X_valid, y_valid),
batch_size=512,
epochs=200,
callbacks=[early_stopping],
)
history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot(title="Cross-entropy")
history_df.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot(title="Accuracy")
- Learning 机器 Machine gt IIlearning机器machine gt learning机器machine learning机器machine iii learning机器machine comp clustering algorithm learning machine learning project machine eecs collaboration differential learning machine learning machine bigdataaiml-ml-models bigdataaiml learning machine python in adversarial patterns learning machine