1. RNN 怎么学习
1.1 Loss Function
如果要做learning的话,你要定义一个cost function来evaluate你的model是好还是不好,选一个parameter要让你的loss 最小.那在Recurrent Neural Network里面,你会怎么定义这个loss呢,下面我们先不写算式,先直接举个例子.
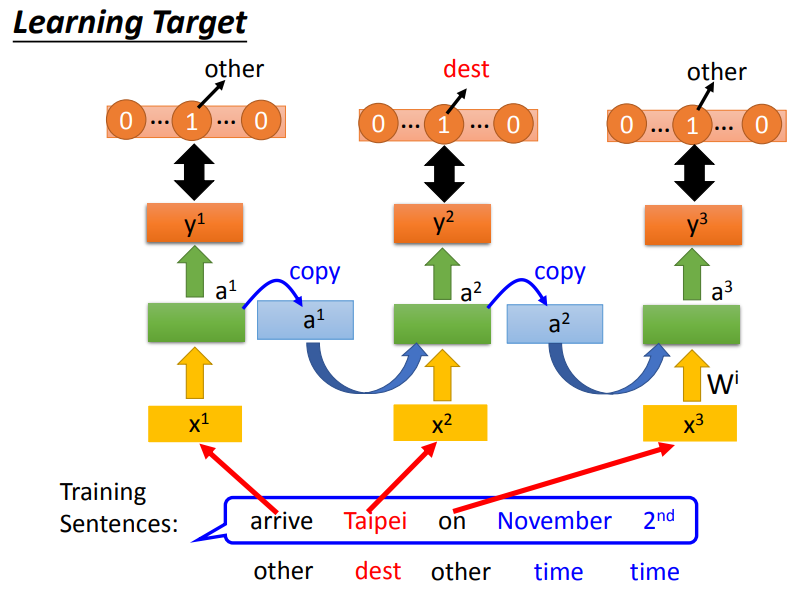
如下图所示,这是一个Slot Filling的例子,我们要将输出的y与映射到slot的reference vector做cross entropy.例如,Taipei对应到的slot是dest,那reference vector在dest上的值为1,其余的值都为0.RNN的输出与reference vector的cross entropy的和就是要minimize的对象.注意:句子里面的词语必须按照语序输入,不能打乱语序!
1.2 Training
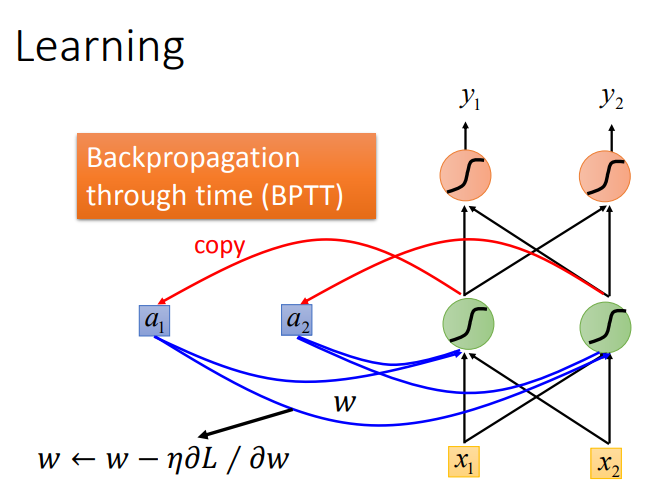
有了这个loss function以后,对于training,也是用梯度下降来做.也就是说我们现在定义出了loss function(L).我要update这个neural network里面的某个参数w,就是计算对w的偏微分,偏微分计算出来以后,就用GD的方法去update里面的参数。在讲feedforward neural network的时候,我们说GD用在feedforward neural network里面你要用一个有效率的算法叫做Backpropagation.那Recurrent Neural Network里面,为了要计算方便,所以也有开发一套算法是Backpropagation的进阶版,叫做BPTT.它跟Backpropagation其实是很类似的,只是Recurrent Neural Network它是在time sequence上运作,所以BPTT它要考虑时间上的information.
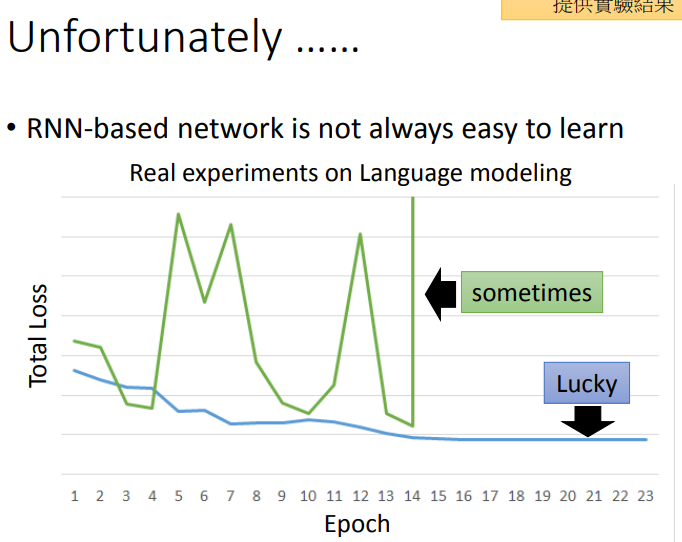
如下图所示,RNN的Training是比较困难的,我们希望随着Epoch地增加,loss跟图中蓝色线一样慢慢下降,但是很不幸的是我们在训练过程中会出现绿色线的结果.
为什么会这样呢?如下图所示,RNN的error surface(Total Loss对参数变化)是非常崎岖的,这里的意思就是loss在某些地方比较平坦,在某些地方又比较陡峭。假如把橙色点当作起始点,用Gradient Descent调整参数,然后更新参数,可能会得到loss猛增的结果。最坏的情况是一脚踩在悬崖上,由于之前一直处在平坦区域,gradient很小,那么就会把learning rate调的比较大,因此踩在悬崖上时gradient变得很大,就会整个飞出去,可能会变成\(NaN\).
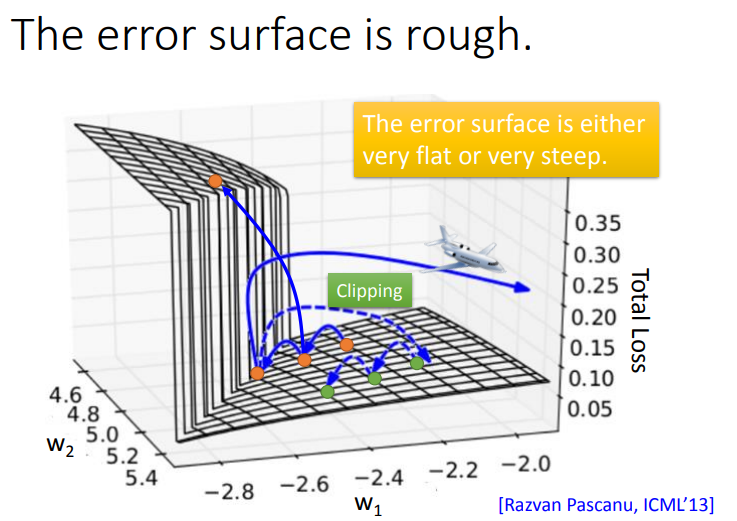
这种问题怎么解决的呢?RNN的创作者使用了Clipping来解决这个问题.Clipping就是当gradient大于某个threshold时,就让\(gradient = threshold\).
1.2.1 Why RNN has the trait?
那么,为什么RNN会有这种奇特的特性?我们用一个直观方法来了解.把某一个参数做小小的变化,看它对network output的变化有多大,你就可以测出这个参数的gradient的大小.
举一个简单的例子.只有一个neuron,这个neuron是linear.input没有bias,input的weight是1,output的weight也是1,transition的weight是w.也就是说从memory接到neuron的input的weight是w.
现在我假设给neural network的输入是(1,0,0,0),那这个neural network的output会长什么样子呢?比如说,neural network在最后一个时间点(1000个output值是\(w^{999}\))

当w从1变到1.01后,y^1000从1变到了20000,此时L对w的微分值很大,所以需要较小的Learning rate;当w从0.99变到0.01后,y^1000从0变到了0,此时L对w的微分值很小,所以需要较大的Learning rate.这样导致设置learning rate很麻烦,你的error surface很崎岖,你的gardient是时大时小的,在非常小的区域内,gradient有很多的变化.
从这个例子你可以看出来说,为什么RNN会有问题.RNN training的问题其实来自它把同样的东西在transition的时候反复使用.所以这个w只要一有变化,它完全由可能没有造成任何影响,一旦造成影响,影响都是天崩地裂的(所以gradient会很大,gradient会很小).
1.2.2 How can RNN solve the problem?
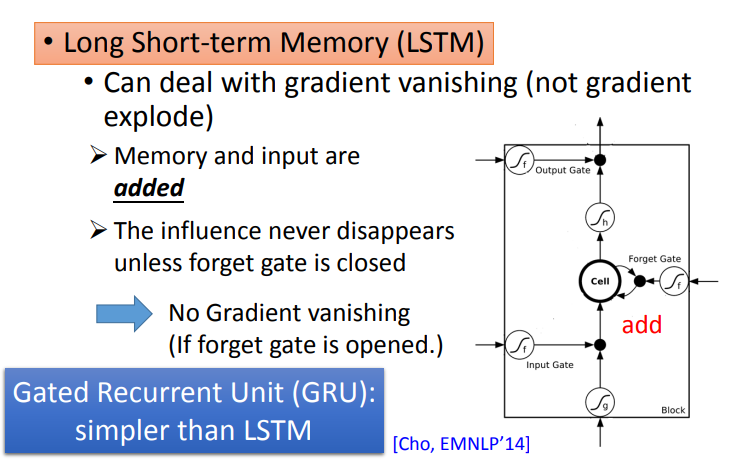
- Recurrent Network Neural 4.3 RNNrecurrent network neural 4.3 neural-network deep-neural-network-driven deep-neural-network-driven autonomous cdeepfuzz programming network basics neural l-layer network课程neural 神经网络 神经network neural 1b-watching-notes neural-network watching network network neural classification network neural oneapi