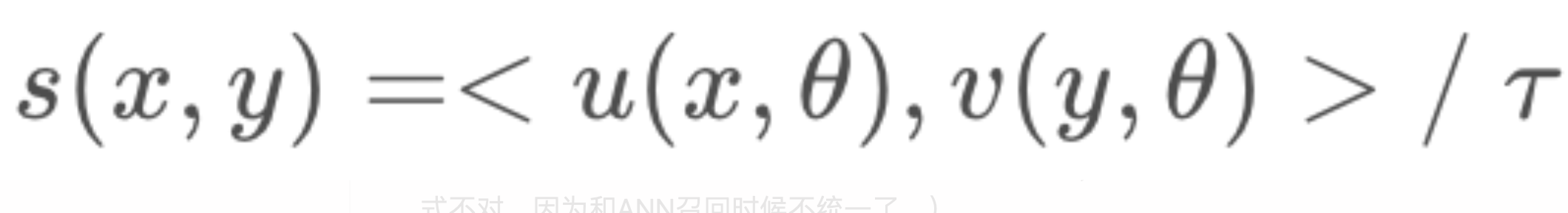来自谷歌的论文《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》
参考:
- 会议presentation
- 谷歌最新双塔DNN召回模型——应用于YouTube大规模视频推荐场景
- 论文《Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations》:更详细一点
- 背景和动机
整个召回系统采用的是双塔结构,即分别构建请求侧的Embedding和视频侧的Embedding,两个塔的输出就为各自的embedding向量,最终模型的输出为两个Embedding内积后的结果。
Batch softmax CE loss:
两个embedding内积相似度:
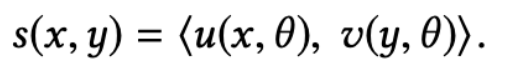
对模型输出进行softmax:

基于softmax函数的输出和用户偏好的权重(观看视频的时长),损失函数采用加权对数似然函数的形式:

由于全量的视频库数量巨大,所以上述softmax在计算的时候需要对全量视频集合进行采样。传统的做法是训练所需的负样本从固定的集合中采样得到,但是论文中的做法是对实时流中的数据采样出一个batch,训练的负样本即这个batch中的负样本,但是会遇到以下问题:
- 训练数据是遵循幂律分布的,会导致在sampled softmax loss相比softmax loss引入巨大的偏差:热门的item因为有更大的概率在一个batch内出现,所以会总被当成负样本导致过度惩罚。推荐系统会因此错失流行但是相关的一些item。
- 解决办法
参考sampled softmax 模型中的 logQ 去偏,我们对每个logits进行了纠正,其中\(p_j\)是每个item的估计采样概率(item j在一个随机batch内被采样到的概率)。
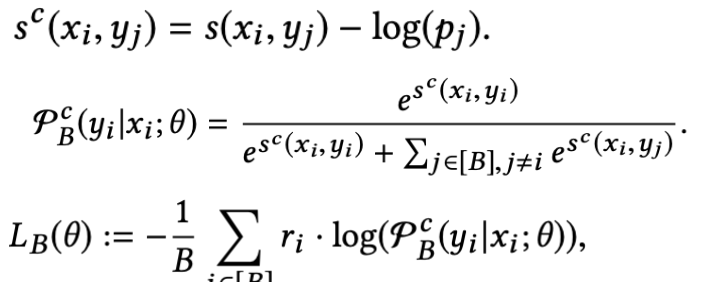
- 这里引入\(p_j\)的作用是:降低热门商品的得分,提高冷门样本的得分。
训练用SGD:

关键的挑战是:item集合是动态的,item的频率也是动态的,因此本文最大的贡献是在一个动态集合中预估item的频率。
- 采样概率修正
-
这部分主要对采样概率进行估计,这里的核心思想是假设某视频连续两次被采样的平均间隔为B,那么该视频的采样概率即为1/B。
-
为了估计\(p_j\),作者维护了两个列表:A和B,\(A[j]\)记录了上一次采样到j的时刻t,\(B[j]\)则表示j被采样的次数,假设在时刻t采样到j,那么利用A辅助更新B:

上式中的函数h()是一个hash函数,他将某个视频的id映射到具体的索引上,然后利用该索引从矩阵B和矩阵A中分别得到该商品对应的平均采样间隔和上一次该商品被采样的时刻,从而进行梯度更新。

-
解决hash冲突问题:
为了提升频率预估的准确率,作者也提出来可以使用多个数组和多个hash函数进行改进:

- 其他
-
标准化:经验上发现对embedding的标准化能够提升模型训练的稳定性,增强召回模型表现:
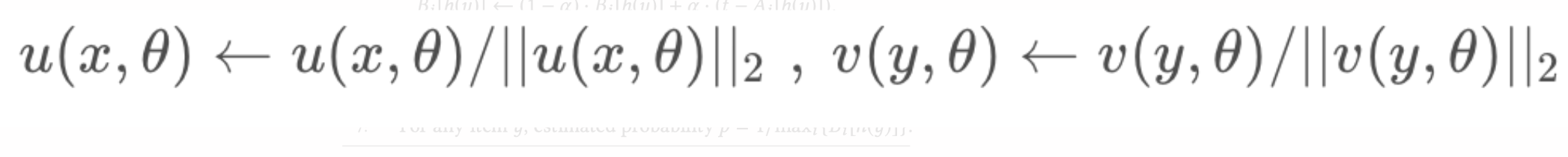
-
温度超参:在相似度内积之后除一个温度系数,可以增加预测的稳定性: