
参考链接:https://leetcode.cn/problems/reformat-department-table/solutions/343480/guan-yu-group-byyu-sumde-pei-he-by-xxiao053/
这是一道经典的行转列问题,先看一下大佬给的链接,讲述group by原理的。https://blog.csdn.net/u014717572/article/details/80687042
为什么不能select * from Table group by id,为什么不能使用*,而是某一个列或者某一个列的聚合函数呢,group by多个字段可以怎么很好的理解呢?
在SQL中,GROUP BY用于对结果集合进行分组。然而,使用GROUP BY时候,我们必须确保选择的列是聚合列或者包含在GROUP BY子句中。在常规的SQL操作中,SELECT *会选择表中所有列,但是如果我们使用了GROUP BY,就必须明确指定哪些列是聚合列。
假设我们有表1,表明为test:

我们执行以下SQL语句:
SELECT name FROM test GROUP BY name
我们可以得到如下结果:

为了更好理解group by多个列和聚合函数的应用。我们在思考过程中,由表1到表2增加一个虚构的中间表:虚拟表3。下面说一下如何思考上边SQL的执行情况:
1. FROM test:该句执行后,应该结果和表1一样
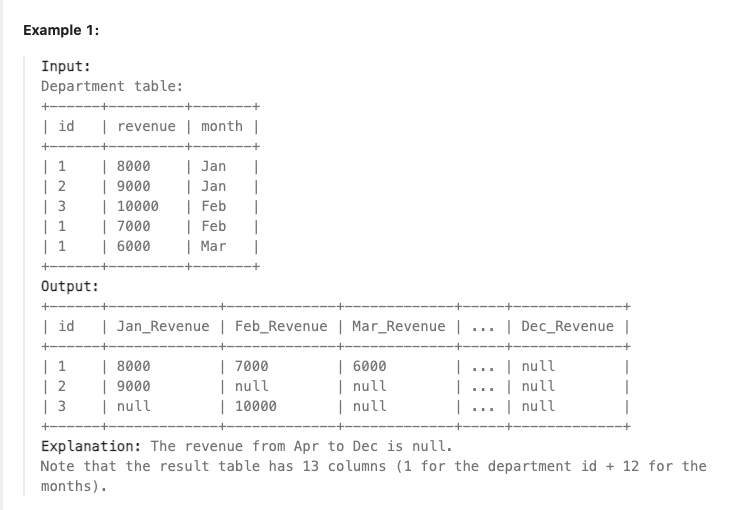
2. FROM test GROUP BY name:该句执行后,我们想象生成了虚拟表3,如下图所示,生成过程是这样的,group by name,那么找name那一列,具有相同name值的行,合并成一行,如对于name值为aa的,那么<1 aa 2>和<2 aa 3>两行合并成一行,所有id的值和number值写到一个单元格里边。
3. 接下来就要针对虚拟表3执行Select语句了:
(1)如果执行select *的话,那么返回的结果应该就是虚拟表3,可是id和number中有的单元格里边的内容是多个值的,而关系数据库就是基于关系的,单元格中是不允许有多个值的,所以执行select *会报错。
(2)我们再看name列,每个单元格只有一个数据,所以我们select name的话,就没有报错。为什么name列每个单元格只有一个值呢,因为我们就是用name列来group by的。
(3)对于id和number中的单元格有多个数据怎么办呢?答案就是使用聚合函数,聚合函数用来输入多个数据,输出一个数据。例如count(id),sum(number),而每个聚合函数的输入就是每一个多数据的单元格。
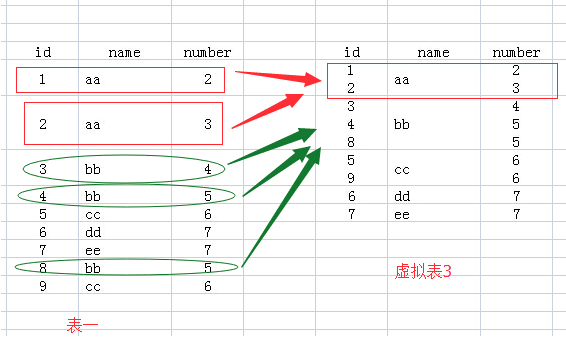
(4)例如我们执行select name, sum(number) from test group by name,那么sum就对虚拟表3的number列的每个单元格进行sum操作,例如对name为aa的那一行的number列执行sum操作,即2+3返回5,最后执行的结果如下:
(5)group by多个字段应该怎么理解呢:比如group by name, number。我们可以把name和number看成一个整体字段,以他们整体来进行分组。

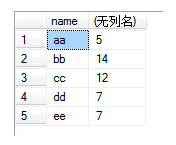
(6)接下来就可以配合select和聚合函数进行操作了,比如执行select name, sum(id) from test group by name, number,结果如下图:
接下来我们看一下本题怎么解决。先写出答案:
SELECT id, SUM(CASE WHEN month='Jan' THEN revenue END) AS Jan_Revenue, SUM(CASE WHEN month='Feb' THEN revenue END) AS Feb_Revenue, SUM(CASE WHEN month='Mar' THEN revenue END) AS Mar_Revenue, SUM(CASE WHEN month='Apr' THEN revenue END) AS Apr_Revenue, SUM(CASE WHEN month='May' THEN revenue END) AS May_Revenue, SUM(CASE WHEN month='Jun' THEN revenue END) AS Jun_Revenue, SUM(CASE WHEN month='Jul' THEN revenue END) AS Jul_Revenue, SUM(CASE WHEN month='Aug' THEN revenue END) AS Aug_Revenue, SUM(CASE WHEN month='Sep' THEN revenue END) AS Sep_Revenue, SUM(CASE WHEN month='Oct' THEN revenue END) AS Oct_Revenue, SUM(CASE WHEN month='Nov' THEN revenue END) AS Nov_Revenue, SUM(CASE WHEN month='Dec' THEN revenue END) AS Dec_Revenue FROM department GROUP BY id ORDER BY id;
group by id会使department表按照id分组,生成一张虚拟表(假想中的表),如下:

在虚拟表中,所有id=1的revenue或者month数据都写在了同一个单元格中,如8000、7000、6000都是写在同一单元格内的。真正的表是不能这样写的,所以这种写法只存在于虚拟表中,帮助我们理解。
接下来我们看一下case when的原理
当一个单元格中有多个数据时,case when只会提取第一个数据。
以CASE WHEN month='Feb' THEN revenue END 为例,当id=1时,它只会提取month对应单元格里的第一个数据,即Jan,它不等于Feb,所以找不到Feb对应的revenue,所以返回NULL。(可以试试把我上面答案里的sum()统统去掉,执行结果与预期不一样。错就错在当id=1时,Feb_Revenue和Mar_Revenue的值变成了NULL)
那该如何解决单元格内含多个数据的情况呢?答案就是使用聚合函数,聚合函数就用来输入多个数据,输出一个数据的。如SUM()或MAX(),而每个聚合函数的输入就是每一个多数据的单元格。
以SUM(CASE WHEN month='Feb' THEN revenue END) 为例,当id=1时,它提取的Jan、Feb、Mar,从中找到了符合条件的Feb,并最终返回对应的revenue的值,即7000。