功能说明
free 命令显示系统使用和空闲的内存情况,包括物理内存、交互区内存(swap)和内核缓冲区内存,共享内存将被忽略。
语法
free [参数]。
参数
-
-b:以Byte为单位显示内存使用情况。
-
-k:以KB为单位显示内存使用情况。
-
-m:以MB为单位显示内存使用情况。
-
-h:以适于人类可读方式显示内存信息。-h与其他命令最大不同是-h选项会在数字后面加上适于人类可读的单位。
-
-g:以GB为单位显示内存使用情况。
-
-o:不显示缓冲区调节列。
-
-s:<间隔秒数>持续观察内存使用状况。
-
-t:显示内存总和列。
-
-V:显示版本信息。

如果加上 -h 选项,输出的结果会友好很多:

有时我们需要持续的观察内存的状况,此时可以使用 -s 选项并指定间隔的秒数:
free -h -s 3
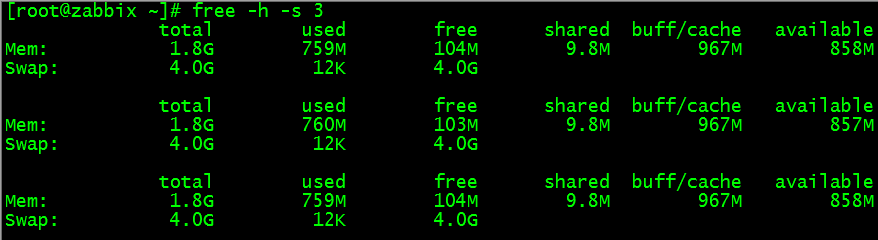
上面的命令每隔 3 秒输出一次内存的使用情况,直到你按下 ctrl + c。
由于 free 命令本身比较简单,所以本文的重点会放在如何通过 free 命令了解系统当前的内存使用状况。
基本概念
下面先解释一下输出的内容:
第一列
-
Mem 行(第二行)是内存的使用情况。
-
Swap 行(第三行)是交换空间的使用情况。
第一行
-
total 列显示系统总的可用物理内存和交换空间大小。
-
used 列显示已经被使用的物理内存和交换空间。
-
free 列显示还有多少物理内存和交换空间可用使用。
-
shared 列显示被共享使用的物理内存大小。
-
buff/cache 列显示被 buffer 和 cache 使用的物理内存大小。
-
available 列显示还可以被应用程序使用的物理内存大小。
buff/cache
从字面上和语义来看,buffer名为缓冲,cache名为缓存。
我们知道各种硬件存在制作工艺上的差别,所以当两种硬件需要交互的时候,肯定会存在速度上的差异,而且只有交互双方都完成才可以各自处理别的其他事务。
假如现在有两个需要交互的设备A和B,A设备用来交互的接口速率为1000M/s,B设备用来交互的接口速率为500M/s,那他们彼此访问的时候都会出现以下两种情况(以A来说):
-
A从B取一个1000M的文件结果需要2s,本来需要1s就可以完成的工作,却还需要额外等待1s,B设备把剩余的500M找出来,这等待B取出剩下500M的空闲时间内(1s)其他的事务还干不了。
-
A给B一个1000M的文件结果也需要2s,本来需要也就1s就可以完成的工作,却由于B,1s内只能拿500M,剩下的500M还得等下一个1sB来取,这等待下1s的时间还做不了其他事务。
那有什么方法既可以让A在‘取’或‘给’B的时候既能完成目标任务又不浪费那1s空闲等待时间去处理其他事务呢?我们知道产生这种结果主要是因为B跟不上A的节奏,但即使这样A也得必须等B处理完本次事务才能干其他活(单核cpu来说),除非你有三头六臂。
那有小伙伴可能会问了,能不能在A和B之间加一层区域比如说ab,让ab既能跟上A的频率也会照顾B的感受。
没错,我们确实可以这样设计来磨合接口速率上的差异,你可以这样想象,在区域ab提供了两个交互接口一个是a接口另一个是b接口,a接口的速率接近A,b接口的速率最少等于B,然后我们把ab的a和A相连,ab的b和B相连,ab就像一座桥把A和B链接起来,并告知A和B通过他都能转发给对方,文件可以暂时存储,最终拓扑大概如下:

现在我们再来看上述两种情况。
-
对于第一种情况A要B
当A从B取一个1000M的文件,他把需求告诉了ab,接下来ab通过b和B进行文件传送,由于B本身的速率,传送第一次ab并没有什么用,对A来说不仅浪费了时间还浪费了感情。
ab这家伙很快感受到了A的不满,所以在第二次传送的时候,ab背着B偷偷缓存了一个一模一样的文件,而且只要从B取东西,ab都会缓存一个拷贝下来放在自己的大本营。
如果下次A或者其他C来取B的东西,ab直接就给A或C一个货真价实的赝品,然后把它通过a接口给了A或C,由于a的速率相对接近A的接口速率,所以A觉得不错为他省了时间,最终和ab的a成了好朋友。
说白了此时的ab提供的就是一种缓存能力,即cache,绝对的走私!因为C取的是A执行的结果。
所以在这种工作模式下,怎么取得的东西是最新的也是我们需要考虑的,一般就是清cache。例如cpu读取内存数据,硬盘一般都提供一个内存作为缓存来增加系统的读取性能。
-
对于第二种情况A给B
当A发给B一个1000M的文件,因为A知道通过ab的a接口就可以转交给B,而且通过a接口要比通过B接口传送文件需要等待的时间更短,所以1000M通过a接口给了ab。
站在A视图上他认为已经把1000M的文件给了B,但对于ab并不立即交给B,而是先缓存下来,除非B执行sync命令,即使B马上要,但由于b的接口速率最少大于B接口速率,所以也不会存在漏洞时间。
但最终的结果是A节约了时间就可以干其他的事务,说白了就是推卸责任,哈哈而ab此时提供的就是一种缓冲的能力,即buffer,它存在的目的适用于当速度快的往速度慢的输出东西。例如内存的数据要写到磁盘,cpu寄存器里的数据写到内存。
看了上面这个例子,那我们现在看一下在计算机领域,在处理磁盘IO读写的时候,cpu、memory、disk基于这种模型给出的一个实例。
我们先来一幅图(图片来自网络,我觉得看N篇文档不如瞄此一图):
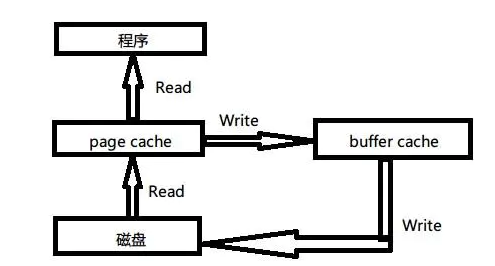
page cache:文件系统层级的缓存,从磁盘里读取的内容是存储到这里,这样程序读取磁盘内容就会非常快,比如使用grep和find等命令查找内容和文件时,第一次会慢很多,再次执行就快好多倍,几乎是瞬间。但如上所说,如果对文件的更新不关心,就没必要清cache,否则如果要实施同步,必须要把内存空间中的cache clean下。
buffer cache:磁盘等块设备的缓冲,内存的这一部分是要写入到磁盘里的。这种情况需要注意,位于内存buffer中的数据不是即时写入磁盘,而是系统空闲或者buffer达到一定大小统一写到磁盘中,所以断电易失,为了防止数据丢失所以我们最好正常关机或者多执行几次sync命令,让位于buffer上的数据立刻写到磁盘里。
free 与 available
在 free 命令的输出中,有一个 free 列,同时还有一个 available 列。这二者到底有何区别?
free 是真正尚未被使用的物理内存数量。至于 available 就比较有意思了,它是从应用程序的角度看到的可用内存数量。
Linux 内核为了提升磁盘操作的性能,会消耗一部分内存去缓存磁盘数据,就是我们介绍的 buffer 和 cache。所以对于内核来说,buffer 和 cache 都属于已经被使用的内存。
当应用程序需要内存时,如果没有足够的 free 内存可以用,内核就会从 buffer 和 cache 中回收内存来满足应用程序的请求。所以从应用程序的角度来说,available = free + buffer + cache。
请注意,这只是一个很理想的计算方式,实际中的数据往往有较大的误差。
交换空间(swap space)
swap space 是磁盘上的一块区域,可以是一个分区,也可以是一个文件。所以具体的实现可以是 swap 分区也可以是 swap 文件。
当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务,而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,这就是常说的换出和换入。
交换空间可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。
现在的机器一般都不太缺内存,如果系统默认还是使用了 swap 是不是会拖累系统的性能?
理论上是的,但实际上可能性并不是很大。并且内核提供了一个叫做 swappiness 的参数,用于配置需要将内存中不常用的数据移到 swap 中去的紧迫程度。这个参数的取值范围是 0~100,0 告诉内核尽可能的不要将内存数据移到 swap 中,也即只有在迫不得已的情况下才这么做,而 100 告诉内核只要有可能,尽量的将内存中不常访问的数据移到 swap 中。
在 ubuntu 系统中,swappiness 的默认值是 60。如果我们觉着内存充足,可以在 /etc/sysctl.conf 文件中设置 swappiness:
vm.swappiness=10
如果系统的内存不足,则需要根据物理内存的大小来设置交换空间的大小。具体的策略网上有很丰富的资料,这里笔者不再赘述。
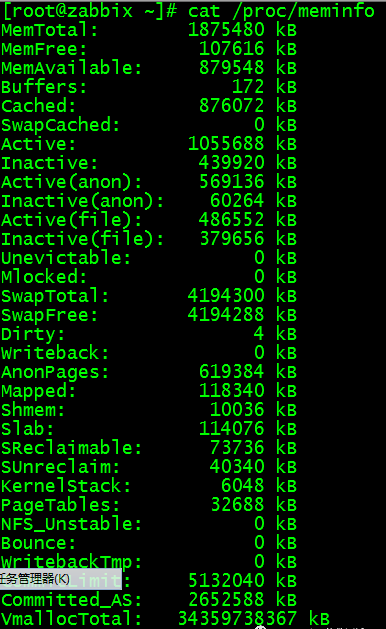
/proc/meminfo 文件
其实 free 命令中的信息都来自于 /proc/meminfo 文件。/proc/meminfo 文件包含了更多更原始的信息,只是看起来不太直观:
总结
free 命令是一个既简单又复杂的命令,简单是因为这个命令的参数少,输出结果清晰,说它复杂则是因为它背后是比较晦涩的操作系统中的概念,如果不清楚这些概念,即便看了 free 命令的输出也 get 不到多少有价值的信息。