
# -*- coding: utf-8 -*-
# 代码11-1
import os
import pandas as pd
# 修改工作路径到指定文件夹
#os.chdir("D:/chapter11/demo")
os.chdir("D:\\大三下\\大数据实验课\\data\\Unit11")
# 第一种连接方式
# from sqlalchemy import create_engine
# engine = create_engine('mysql+pymysql://root:123@192.168.31.140:3306/test?charset=utf8')
# sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
# 第二种连接方式
import pymysql as pm
con = pm.connect(host='localhost',user='root',password='123456',database='test',charset='utf8')
data = pd.read_sql('select * from all_gzdata',con=con)
con.close() #关闭连接
# 保存读取的数据
data.to_csv("D:\\大三下\\大数据实验课\\data\\Unit11\\all_gzdata.csv", index=False, encoding='utf-8')
网页类型设计
# 代码11-2 网页类型设计
import pandas as pd
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
# 分析网页类型
counts = [i['fullURLId'].value_counts() for i in sql] #逐块统计
counts = counts.copy()
counts = pd.concat(counts).groupby(level=0).sum() # 合并统计结果,把相同的统计项合并(即按index分组并求和)
counts = counts.reset_index() # 重新设置index,将原来的index作为counts的一列。
counts.columns = ['index', 'num'] # 重新设置列名,主要是第二列,默认为0
counts['type'] = counts['index'].str.extract('(\d{3})') # 提取前三个数字作为类别id
counts_ = counts[['type', 'num']].groupby('type').sum() # 按类别合并
counts_.sort_values(by='num', ascending=False, inplace=True) # 降序排列
counts_['ratio'] = counts_.iloc[:,0] / counts_.iloc[:,0].sum()
print(counts_)

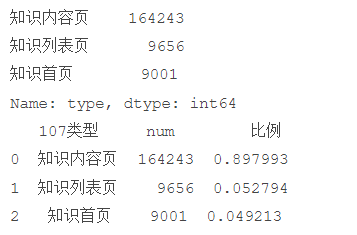
# 代码11-3 知识类型内部统计
# 因为只有107001一类,但是可以继续细分成三类:知识内容页、知识列表页、知识首页
def count107(i): #自定义统计函数
j = i[['fullURL']][i['fullURLId'].str.contains('107')].copy() # 找出类别包含107的网址
j['type'] = None # 添加空列
j['type'][j['fullURL'].str.contains('info/.+?/')]= '知识首页'
j['type'][j['fullURL'].str.contains('info/.+?/.+?')]= '知识列表页'
j['type'][j['fullURL'].str.contains('/\d+?_*\d+?\.html')]= '知识内容页'
return j['type'].value_counts()
# 注意:获取一次sql对象就需要重新访问一下数据库(!!!)
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
counts2 = [count107(i) for i in sql] # 逐块统计
counts2 = pd.concat(counts2).groupby(level=0).sum() # 合并统计结果
print(counts2)
#计算各个部分的占比
res107 = pd.DataFrame(counts2)
# res107.reset_index(inplace=True)
res107.index.name= '107类型'
res107.rename(columns={'type':'num'}, inplace=True)
res107['比例'] = res107['num'] / res107['num'].sum()
res107.reset_index(inplace = True)
print(res107)
# 代码11-4 统计带“?”的数据
def countquestion(i): # 自定义统计函数
j = i[['fullURLId']][i['fullURL'].str.contains('\?')].copy() # 找出类别包含107的网址
return j
# 注意获取一次sql对象就需要重新访问一下数据库
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)
counts3 = [countquestion(i)['fullURLId'].value_counts() for i in sql]
counts3 = pd.concat(counts3).groupby(level=0).sum()
print(counts3)
# 求各个类型的占比并保存数据
df1 = pd.DataFrame(counts3)
df1['perc'] = df1['fullURLId']/df1['fullURLId'].sum()*100
df1.sort_values(by='fullURLId',ascending=False,inplace=True)
print(df1.round(4))

# 代码11-5 统计199类型中的具体类型占比
def page199(i): #自定义统计函数
j = i[['fullURL','pageTitle']][(i['fullURLId'].str.contains('199')) &
(i['fullURL'].str.contains('\?'))]
j['pageTitle'].fillna('空',inplace=True)
j['type'] = '其他' # 添加空列
j['type'][j['pageTitle'].str.contains('法律快车-律师助手')]= '法律快车-律师助手'
j['type'][j['pageTitle'].str.contains('咨询发布成功')]= '咨询发布成功'
j['type'][j['pageTitle'].str.contains('免费发布法律咨询' )] = '免费发布法律咨询'
j['type'][j['pageTitle'].str.contains('法律快搜')] = '快搜'
j['type'][j['pageTitle'].str.contains('法律快车法律经验')] = '法律快车法律经验'
j['type'][j['pageTitle'].str.contains('法律快车法律咨询')] = '法律快车法律咨询'
j['type'][(j['pageTitle'].str.contains('_法律快车')) |
(j['pageTitle'].str.contains('-法律快车'))] = '法律快车'
j['type'][j['pageTitle'].str.contains('空')] = '空'
return j
# 注意:获取一次sql对象就需要重新访问一下数据库
#engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)# 分块读取数据库信息
#sql = pd.read_sql_query('select * from all_gzdata limit 10000', con=engine)
counts4 = [page199(i) for i in sql] # 逐块统计
counts4 = pd.concat(counts4)
d1 = counts4['type'].value_counts()
print(d1)
d2 = counts4[counts4['type']=='其他']
print(d2)
# 求各个部分的占比并保存数据
df1_ = pd.DataFrame(d1)
df1_['perc'] = df1_['type']/df1_['type'].sum()*100
df1_.sort_values(by='type',ascending=False,inplace=True)
print(df1_)


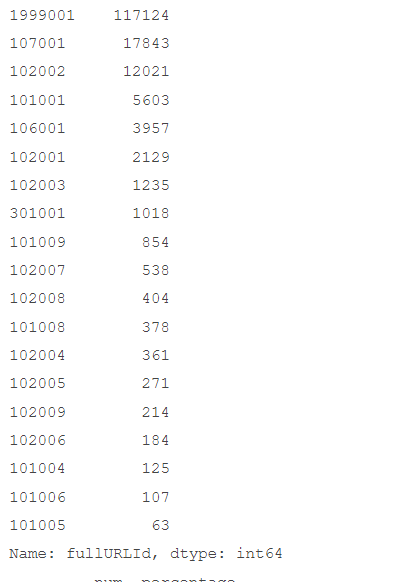
# 代码11-6 统计无目的浏览用户中各个类型占比
def xiaguang(i): #自定义统计函数
j = i.loc[(i['fullURL'].str.contains('\.html'))==False,
['fullURL','fullURLId','pageTitle']]
return j
# 注意获取一次sql对象就需要重新访问一下数据库
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)# 分块读取数据库信息
counts5 = [xiaguang(i) for i in sql]
counts5 = pd.concat(counts5)
xg1 = counts5['fullURLId'].value_counts()
print(xg1)
# 求各个部分的占比
xg_ = pd.DataFrame(xg1)
xg_.reset_index(inplace=True)
xg_.columns= ['index', 'num']
xg_['perc'] = xg_['num']/xg_['num'].sum()*100
xg_.sort_values(by='num',ascending=False,inplace=True)
xg_['type'] = xg_['index'].str.extract('(\d{3})') #提取前三个数字作为类别id
xgs_ = xg_[['type', 'num']].groupby('type').sum() #按类别合并
xgs_.sort_values(by='num', ascending=False,inplace=True) #降序排列
xgs_['percentage'] = xgs_['num']/xgs_['num'].sum()*100
print(xgs_.round(4))
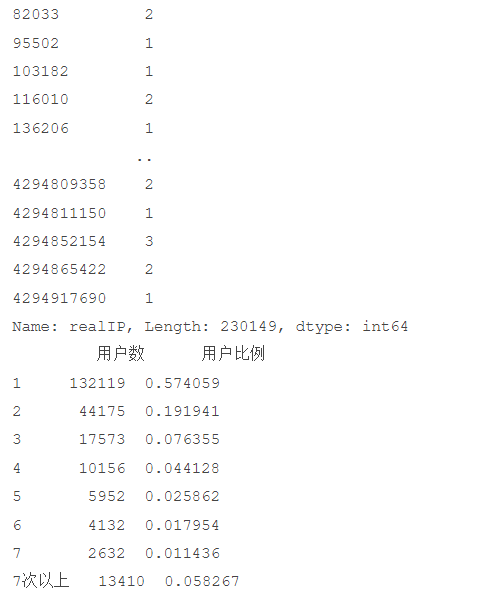
# 代码11-7 统计用户浏览网页次数的情况
# 统计点击次数
engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize = 10000)# 分块读取数据库信息
counts1 = [i['realIP'].value_counts() for i in sql] # 分块统计各个IP的出现次数
counts1 = pd.concat(counts1).groupby(level=0).sum() # 合并统计结果,level=0表示按照index分组
print(counts1)
counts1_ = pd.DataFrame(counts1)
counts1_
counts1['realIP'] = counts1.index.tolist()
counts1_[1]=1 # 添加1列全为1
hit_count = counts1_.groupby('realIP').sum() # 统计各个“不同点击次数”分别出现的次数
# 也可以使用counts1_['realIP'].value_counts()功能
hit_count.columns=['用户数']
hit_count.index.name = '点击次数'
# 统计1~7次、7次以上的用户人数
hit_count.sort_index(inplace = True)
hit_count_7 = hit_count.iloc[:7,:]
time = hit_count.iloc[7:,0].sum() # 统计点击次数7次以上的用户数
hit_count_7 = hit_count_7.append([{'用户数':time}], ignore_index=True)
hit_count_7.index = ['1','2','3','4','5','6','7','7次以上']
hit_count_7['用户比例'] = hit_count_7['用户数'] / hit_count_7['用户数'].sum()
print(hit_count_7)
# 代码11-8 分析浏览一次的用户行为
# 初始化数据库连接:
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/test?charset=utf8')
sql = pd.read_sql('all_gzdata', engine, chunksize=1024 * 5)
# 分块统计各个IP的点击次数
result = [i['realIP'].value_counts() for i in sql]
click_count = pd.concat(result).groupby(level=0).sum()
click_count = click_count.reset_index()
click_count.columns = ['realIP', 'times']
# 筛选出来点击一次的数据
click_one_data = click_count[click_count['times'] == 1]
# 这里只能再次读取数据 因为sql是一个生成器类型,所以在使用过一次以后,就不能继续使用了。必须要重新执行一次读取。
sql = pd.read_sql('all_gzdata', engine, chunksize=1024 * 5)
# 取出这三列数据
data = [i[['fullURLId', 'fullURL', 'realIP']] for i in sql]
data = pd.concat(data)
# 和并数据 我以click_one_data为基准 按照realIP合并过来,目的方便查看点击一次的网页和realIP
merge_data = pd.merge(click_one_data, data, on='realIP', how='left')
# 点击一次的数据统计 写入数据库 以方便读取 校准无误 写入后就可以注释掉此句代码
#erge_data.to_sql('click_one_count', engine, if_exists='append')
print(merge_data)
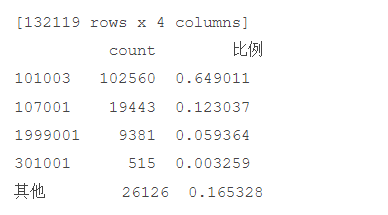
# 统计排名前4和其他的网页类型
URL_count_4 = URL_count.iloc[:4,:]
time = hit_count.iloc[4:,0].sum() # 统计其他的
URLindex = URL_count_4.index.values
URL_count_4 = URL_count_4.append([{'count':time}], ignore_index=True)
URL_count_4.index = [URLindex[0], URLindex[1], URLindex[2], URLindex[3],
'其他']
URL_count_4['比例'] = URL_count_4['count'] / URL_count_4['count'].sum()
print(URL_count_4)
# 代码11-9 统计单用户浏览次数为一次的网页
# 在浏览1次的前提下, 得到的网页被浏览的总次数
fullURL_count = pd.DataFrame(real_one.groupby("fullURL")["fullURL"].count())
fullURL_count.columns = ["count"]
fullURL_count["fullURL"] = fullURL_count.index.tolist()
fullURL_count.sort_values(by='count', ascending=False, inplace=True) # 降序排列
# 网页类型ID统计
fullURLId_count = merge_data['fullURLId'].value_counts()
fullURLId_count = fullURLId_count.reset_index()
fullURLId_count.columns = ['fullURLId', 'count']
fullURLId_count['percent'] = fullURLId_count['count'] / fullURLId_count['count'].sum() * 100
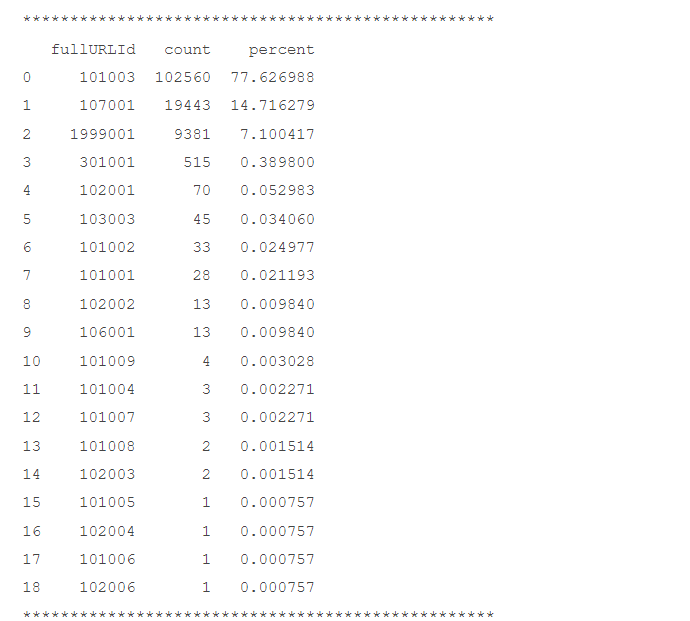
print('*****' * 10)
print(fullURLId_count)
# 用户点击一次 浏览的网页统计
fullURL_count = merge_data['fullURL'].value_counts()
fullURL_count = fullURL_count.reset_index()
fullURL_count.columns = ['fullURL', 'count']
fullURL_count['percent'] = fullURL_count['count'] / fullURL_count['count'].sum() * 100
print('*****' * 10)
print(fullURL_count)
# 代码11-10 删除不符合规则的网页
import os
import re
import pandas as pd
import pymysql as pm
from random import sample
# 修改工作路径到指定文件夹
os.chdir("D:\\大三下\\大数据实验课\\data\\Unit1\\FileRecv")
# 读取数据
con = pm.connect(host='localhost',user='root',password='123456',database='test',charset='utf8')
data = pd.read_sql('select * from all_gzdata',con=con)
con.close() # 关闭连接
# 取出107类型数据
index107 = [re.search('107',str(i))!=None for i in data.loc[:,'fullURLId']]
data_107 = data.loc[index107,:]
# 在107类型中筛选出婚姻类数据
index = [re.search('hunyin',str(i))!=None for i in data_107.loc[:,'fullURL']]
data_hunyin = data_107.loc[index,:]
# 提取所需字段(realIP、fullURL)
info = data_hunyin.loc[:,['realIP','fullURL']]
# 去除网址中“?”及其后面内容
da = [re.sub('\?.*','',str(i)) for i in info.loc[:,'fullURL']]
info.loc[:,'fullURL'] = da # 将info中‘fullURL’那列换成da
# 去除无html网址
index = [re.search('\.html',str(i))!=None for i in info.loc[:,'fullURL']]
index.count(True) # True 或者 1 , False 或者 0
info1 = info.loc[index,:]print(info1)
# 代码11-11 还原翻译网址
# 找出翻页和非翻页网址
index = [re.search('/\d+_\d+\.html',i)!=None for i in info1.loc[:,'fullURL']]
index1 = [i==False for i in index]
info1_1 = info1.loc[index,:] # 带翻页网址
info1_2 = info1.loc[index1,:] # 无翻页网址
# 将翻页网址还原
da = [re.sub('_\d+\.html','.html',str(i)) for i in info1_1.loc[:,'fullURL']]
info1_1.loc[:,'fullURL'] = da
# 翻页与非翻页网址合并
frames = [info1_1,info1_2]
info2 = pd.concat(frames)
# 或者
info2 = pd.concat([info1_1,info1_2],axis = 0) # 默认为0,即行合并
# 去重(realIP和fullURL两列相同)
info3 = info2.drop_duplicates()
# 将IP转换成字符型数据
info3.iloc[:,0] = [str(index) for index in info3.iloc[:,0]]
info3.iloc[:,1] = [str(index) for index in info3.iloc[:,1]]print(info3)
len(info3)

# 代码11-12 筛选浏览次数不满两次的用户
# 筛选满足一定浏览次数的IP
IP_count = info3['realIP'].value_counts()
# 找出IP集合
IP = list(IP_count.index)
count = list(IP_count.values)
# 统计每个IP的浏览次数,并存放进IP_count数据框中,第一列为IP,第二列为浏览次数
IP_count = pd.DataFrame({'IP':IP,'count':count})print(IP_count)
# 筛选出浏览网址在n次以上的IP集合
n = 2
index = IP_count.loc[:,'count']>n
IP_index = IP_count.loc[index,'IP']
print(IP_index)

# 代码11-13 划分数据集 # 划分IP集合为训练集和测试集 index_tr = sample(range(0,len(IP_index)),int(len(IP_index)*0.8)) # 或者np.random.sample index_te = [i for i in range(0,len(IP_index)) if i not in index_tr] IP_tr = IP_index[index_tr] IP_te = IP_index[index_te] # 将对应数据集划分为训练集和测试集 index_tr = [i in list(IP_tr) for i in info3.loc[:,'realIP']] index_te = [i in list(IP_te) for i in info3.loc[:,'realIP']] data_tr = info3.loc[index_tr,:] data_te = info3.loc[index_te,:]print(len(data_tr)) IP_tr = data_tr.iloc[:,0] # 训练集IP url_tr = data_tr.iloc[:,1] # 训练集网址 IP_tr = list(set(IP_tr)) # 去重处理 url_tr = list(set(url_tr)) # 去重处理 len(url_tr)