\(\mathcal{KMP算法}\)
实际上,完全没必要从\(S\)的每一个字符开始,暴力穷举每一种情况,\(Knuth、Morris\)和\(Pratt\)对该算法进行了改进,称为KMP算法。
而\(KMP\)的精髓在于,对于每次失配之后,我都不会从头重新开始枚举,而是根据我已经得知的数据,从某个特定的位置开始匹配;而对于模式串的每一位,都有唯一的“特定变化位置”,这个在失配之后的特定变化位置可以帮助我们利用已有的数据不用从头匹配,从而节约时间。
特点:1. \(i\) 不回退 2. \(j\) 回退的位置有讲究
\(\mathcal{实现流程}\)
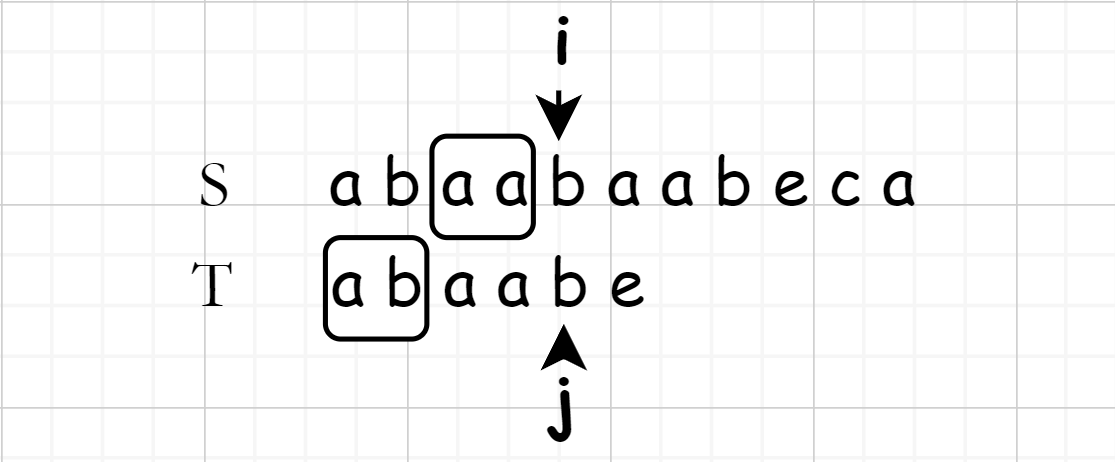
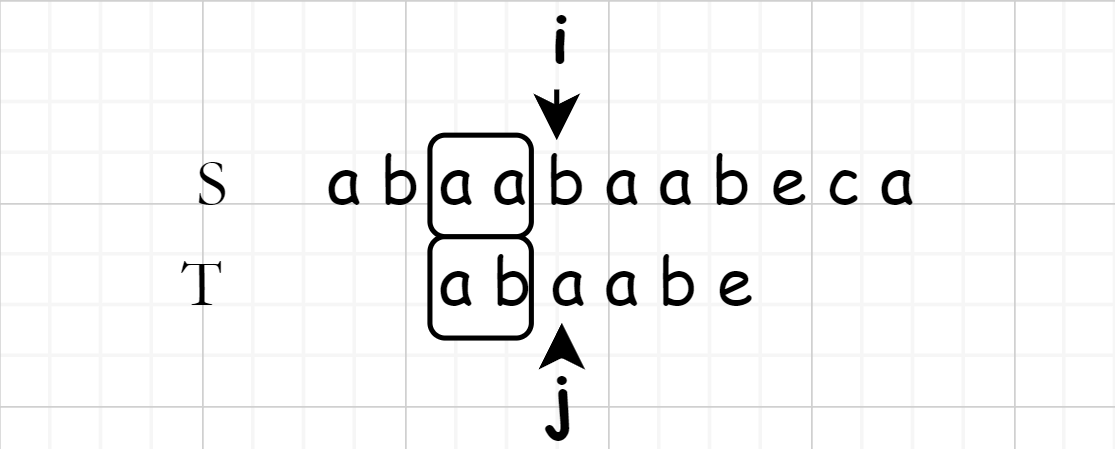
为了清楚地表述目的, \(T\) 与 \(S\) 失配前的部分作为 \(T'\) 来表述,此时寻找下一个开始匹配的标志头。而找到下一个标志头的方式为:
找到 \(T'\) 的最长相同前缀与后缀
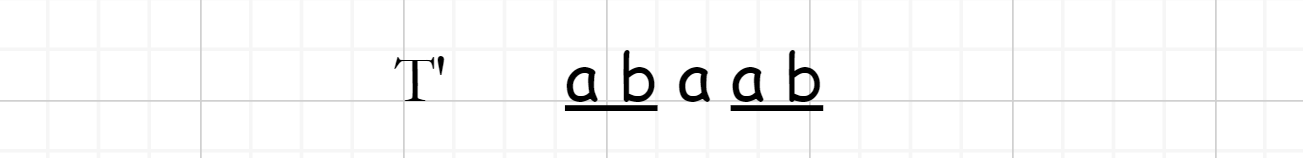

\(\color{red}{这样找所有的前缀和后缀比较,是不是也是暴力穷举??那该怎么办呢??}\)
\(\color{red}{ans:当然是要用到动态规划递推啦。}\)





