2023-2024-1 20232408 《网络空间安全导论》第五周学习总结
教材内容总结
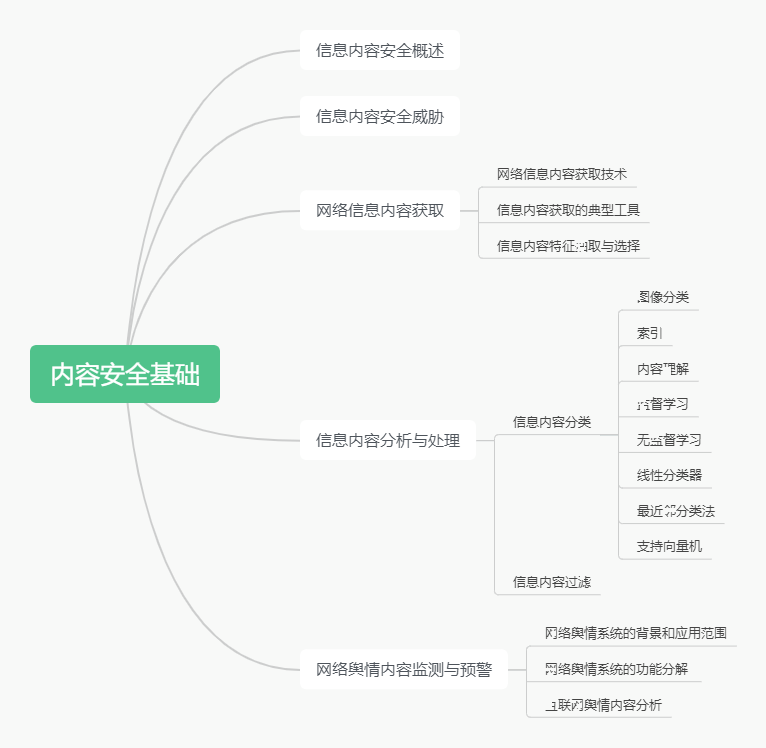
本周学习的内容是内容安全基础。这一块的重点是信息内容安全的各个方面,有着不得不应对的危险,也有适应危险挑战的工具与技术。我们在这一章学习了如何进行网络信息内容获取、信息内容分析与处理、网络舆情内容监测与预警以及内容中心网络及安全。社会需要内容的安全来确保信息的真实,网络需要内容的安全以确认信息的秘密,内容安全与网络安全、系统安全等各个层面的安全一样,构成了我们现在广义上的网络空间安全。内容安全,我感觉有点密码学的意思,因为我们之前所作的很多努力都是在防止内容被窃取和获得我们想要的信息;处理、分析信息的能力也是我们每个学习技术的学生应该掌握的本领。
教材学习过程中的问题和解决过程
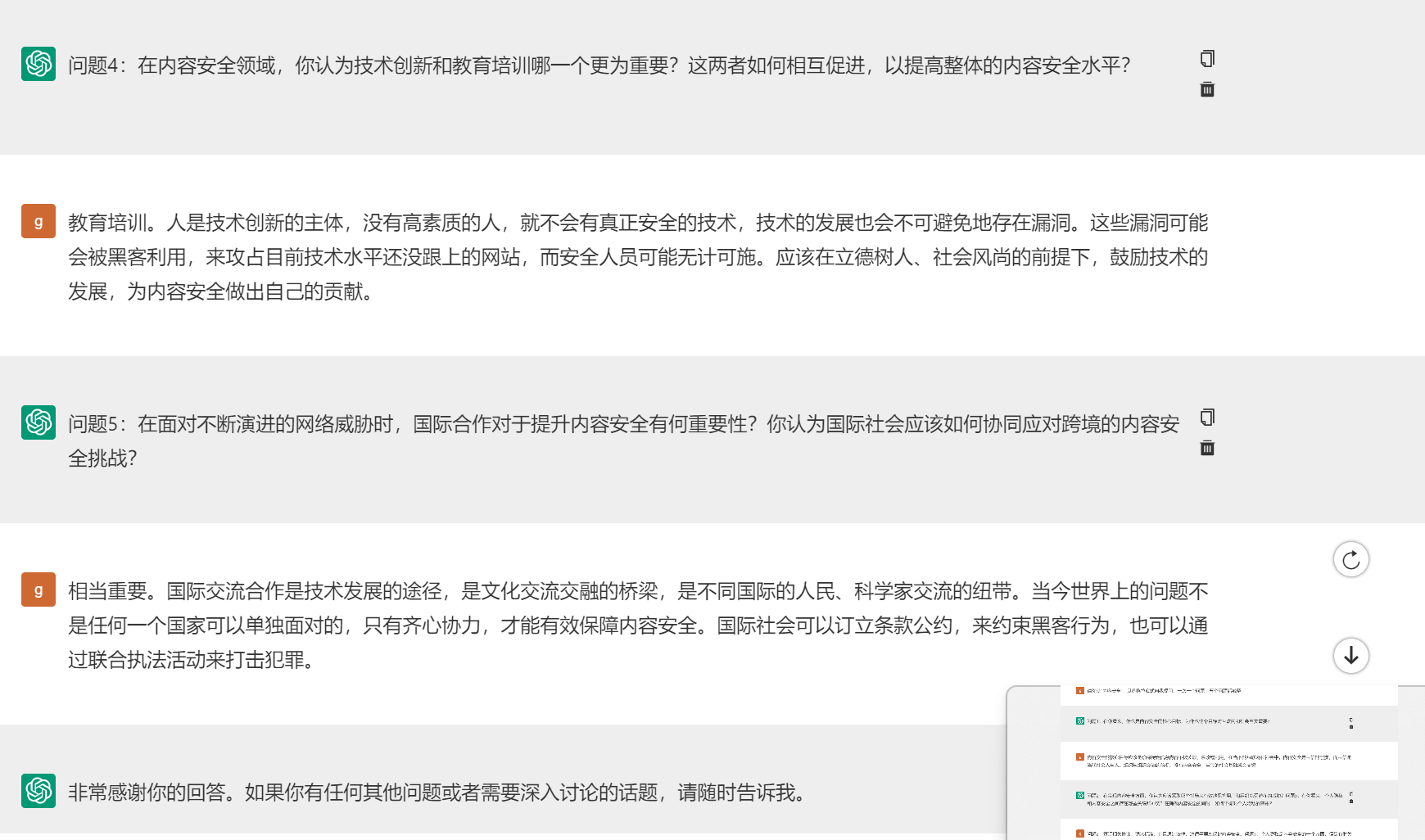
1.具体有哪些内容安全工具,以及爬虫应该利用什么手段使得爬取的目标网站内容具有可筛选性。
所获得的答案:
Web 应用防火墙 (WAF):
功能: 通过检测和阻止针对 Web 应用程序的常见攻击,如SQL注入、跨站脚本(XSS)等,保护网站免受攻击。
例子: ModSecurity、Cloudflare WAF。
恶意软件扫描器:
功能: 检测和阻止网站上的恶意软件,以防止用户受到恶意软件感染的风险。
例子: Sucuri、Wordfence。
内容过滤工具:
功能: 筛选和阻止不当或敏感内容,确保用户不会受到不良内容的侵害。
例子: Symantec Content Analysis、McAfee Web Gateway。
SSL
证书管理工具:
功能: 确保网站使用安全的 SSL 证书,提供加密通信,防止中间人攻击。
例子: Let's Encrypt、DigiCert。
安全信息与事件管理 (SIEM) 工具:
功能: 实时监控、分析和响应与安全事件相关的信息,帮助发现潜在的安全威胁。
例子: Splunk、LogRhythm。
关于如何“深度爬取”这一块,得到以下答案:
robots.txt 文件遵守:
爬虫应遵守网站的 robots.txt 文件,该文件规定了哪些页面可以被爬取,哪些不可以。这是一种基本的爬虫礼仪。
定制爬虫规则:
针对特定网站,定制爬虫规则,只爬取目标页面而忽略不需要的内容。这可以通过设置爬虫的深度、范围和排除规则来实现。
使用正则表达式或XPath选择器:
利用正则表达式或XPath选择器,只选择和提取所需内容,忽略其他无关的信息。
利用元数据和标签:
分析目标网站的HTML结构,利用页面的元数据和标签,以有针对性地提取所需内容。
用户代理设置:
设置适当的用户代理,模拟正常用户的访问,避免被网站识别为恶意爬虫。
限制请求频率:
控制爬取速度,避免对目标网站造成过大的访问压力,也有助于遵守网站的使用条款。
基于AI的学习
截图如下:


思考与感悟
我们一直在强调各种各样形式的安全,本质其实是为了保障内容安全。内容安全是保障现代社会信任的基础与前提,没有内容安全,就没有人与人的信任,现代社会也就失去了基础。所以,我们肩上的担子无比沉重,使命无比光荣!