翻译:https://zhuanlan.zhihu.com/p/425059903
作者:挂枝儿
来源:知乎
本文源自:
主要介绍Python近年新出的协程特性,关于一些基础知识可以参考之前写的:
如果之前对python 协程特性没了解的话,本篇应该会看的很懵逼。
今天这篇主要介绍关于协程非阻塞请求aiohttp.
首先有一个背景知识就是大部分IO相关的库并非天生支持协程(因为这要求他们从socket层就能够支持线程非阻塞的模式),比如我们的requestes库就不支持。 那咋办呢? 用Aiohttp!
1. Aiohttp的底层原理 - Asynchronous context managers
下面的这段socket 网络请求代码使用的原理与aiohttp相同:
1. 我们使用异步context manager管理网络通信(注意在异步代码中,我们的context manager必须实现的方法是__aenter__以及__aexit__)
import asyncio import socket from types import TracebackType from typing import Optional, Type class ConnectedSocket: _connection = None def __init__(self, server_socket): self.server_socket = server_socket async def __aenter__(self): print('Entering context manager, waiting for connection') loop = asyncio.get_event_loop() connection, address = await loop.sock_accept(self.server_socket) self._connection = connection print('Accepted a connection') return self._connection async def __aexit__(self, exc_type: Optional[Type[BaseException]], exc_val: Optional[BaseException], exc_tb: Optional[TracebackType]): print('Exiting context manager') self._connection.close() print('Closed connection') async def main(): loop = asyncio.get_event_loop() server_socket = socket.socket() server_address = ('localhost', 8000) server_socket.setblocking(False) server_socket.bind(server_address) server_socket.listen() async with ConnectedSocket(server_socket) as connection: data = await loop.sock_recv(connection, 1024) print(data) asyncio.run(main()) >>> Entering context manager, waiting for connection Accepted a connection b'test\r\n' Exiting context manager Closed connection
2. 如何使用 aiohttp:
装库就不多说了:
pip install -Iv aiohttp==3.6.2
在aiohttp中有一个很重要的概念是Session。可以把它理解为在浏览器中新开一个窗口,我们可以在这个窗口中再多开多个web,网站也可能会给你送cookies让你存着。同时在一个窗口中你可以维护很多后续支持被“回收”的窗口(connection pooling)。 在Aiohttp的应用中,connection pooling对于性能有很大的影响。
一般来说我们为了 好好利用connection pooling,大部分aiohttp的应用在整个运行阶段只会维护一个session。aiohttp中的session对象支持对任意多数量的网页进行网络请求(such as GET, PUT and POST.)。我们可以使用async with语句来创建session,来看代码:
首先有个之前章节里的辅助函数:
import functools import time from typing import Callable, Any def async_timed(): def wrapper(func: Callable) -> Callable: @functools.wraps(func) async def wrapped(*args, **kwargs) -> Any: print(f'starting {func} with args {args} {kwargs}') start = time.time() try: return await func(*args, **kwargs) finally: end = time.time() total = end - start print(f'finished {func} in {total:.4f} second(s)') return wrapped return wrapper
然后看这次的代码:
import asyncio import aiohttp from aiohttp import ClientSession from util import async_timed @async_timed() async def fetch_status(session: ClientSession, url: str) -> int: async with session.get(url) as result: return result.status @async_timed() async def main(): async with aiohttp.ClientSession() as session: url = 'http://www.example.com' status = await fetch_status(session, url) print(f'Status for {url} was {status}') asyncio.run(main()) >>> Status for http://www.example.com was 200
其实还是挺绕的,我们首先通过async with创建一个aiohttp.ClientSession(),然后再通过async with通过这个session中的get方法去得到结果。注意这里对于结果的处理我们也是在async with语句中完成的。
如何配置aiohttp的time out 特性。
使用requests的时候我们会配置timeout,aiohttp也有这种特性。aiohttp的默认timeout时间为5分钟显然太久。我们手动配置timeout时长既可以在session维度,也可以在request维度。来看代码:
import asyncio import aiohttp from aiohttp import ClientSession async def fetch_status(session: ClientSession, url: str) -> int: # time out limit. ten_millis = aiohttp.ClientTimeout(total=.01) # setting timeout limit at requests level, overriding the session level timeout. async with session.get(url, timeout=ten_millis) as result: return result.status async def main(): # time out limit. session_timeout = aiohttp.ClientTimeout(total=1, connect=.1) # setting the session level timeout limit. async with aiohttp.ClientSession(timeout=session_timeout) as session: await fetch_status(session, 'https://example.com') asyncio.run(main())
基础就介绍到这里,刚刚的代码都是但线程的,显然不会有性能的增长,接下来我们见识一下aiohttp真正的威力:
aiohttp的真正威力:
我们首先回顾一下怎么使用协程创建任务:
import asyncio async def main() -> None: task_one = asyncio.create_task(delay(1)) task_two = asyncio.create_task(delay(2)) await task_one await task_two
这种方式对于个位数的请求任务是没问题的,但网络请求相关的代码动不动就有几百个请求,怎么搞定呢?来看代码。
import asyncio from util import async_timed, delay async def delay(delay_seconds: int) -> int: print(f'sleeping for {delay_seconds} second(s)') await asyncio.sleep(delay_seconds) print(f'finished sleeping for {delay_seconds} second(s)') return delay_seconds @async_timed() async def main() -> None: delay_times = [3, 3, 3] [await asyncio.create_task(delay(seconds)) for seconds in delay_times] asyncio.run(main())
task基础
接下来要介绍一下tasks的概念。 task让asyncio会真正的并行执行起来。一旦我们创建一个task对象,我们就可以继续去执行其他代码块让task自己慢慢run。
我们通过asyncio.create_task来创建任务,创建完毕后就可以通过await 关键字等他的结果。来看代码:
import asyncio from util import delay async def main(): sleep_for_three = asyncio.create_task(delay(3)) print(type(sleep_for_three)) # <class '_asyncio.Task'> result = await sleep_for_three print(result) asyncio.run(main())
有一个重点是创建出来的任务一般在代码的某个阶段一定会跟上await关键字,因为如果不这样,我们创建的任务会被event loop清理掉。
来看看如何同时执行多个任务:
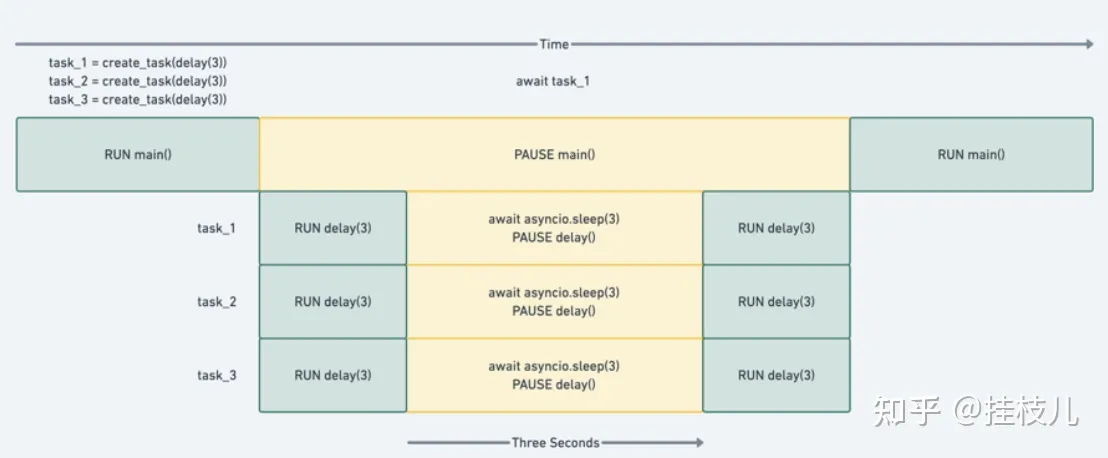
import asyncio from util import delay async def main(): sleep_for_three = asyncio.create_task(delay(3)) sleep_again = asyncio.create_task(delay(3)) sleep_once_more = asyncio.create_task(delay(3)) await sleep_for_three await sleep_again await sleep_once_more asyncio.run(main())
上面代码的执行顺序如下图:
如何停止任务、设定任务的timeout
停止任务很简单,使用cancel方法然后catch住CancelledExceptin即可,来看个代码:
import asyncio from asyncio import CancelledError from util import delay async def main(): long_task = asyncio.create_task(delay(10)) seconds_elapsed = 0 while not long_task.done(): print('Task not finished, checking again in a second.') await asyncio.sleep(1) seconds_elapsed = seconds_elapsed + 1 if seconds_elapsed == 5: long_task.cancel() try: await long_task except CancelledError: print('Our task was cancelled') asyncio.run(main())
设定timeout也不难,使用asyncio.wait_for即可:
import asyncio from util import delay async def main(): delay_task = asyncio.create_task(delay(2)) try: result = await asyncio.wait_for(delay_task, timeout=1) print(result) except asyncio.exceptions.TimeoutError: print('Got a timeout!') print(f'Was the task cancelled? {delay_task.cancelled()}') asyncio.run(main()) >>> sleeping for 2 second(s) Got a timeout! Was the task cancelled? True
Running requests concurrently with gather
说回如何使用aiohttp,我们使用asyncio.gather、这个方法输入为多个awiatibles然后将其包装成tasks,运行完成后给我们返回结果在列表中。来看代码示例:
import asyncio import aiohttp from aiohttp import ClientSession from chapter_04 import fetch_status from util import async_timed @async_timed() async def main(): async with aiohttp.ClientSession() as session: urls = ['https://example.com' for _ in range(1000)] requests = [fetch_status(session, url) for url in urls] status_codes = await asyncio.gather(*requests) print(status_codes) asyncio.run(main())
注意:虽然列表中的结果完成顺序不一定按照传入的顺序完成,但返回的结果list中,结果的顺序与输入的顺序能够保证是一致的。
如何使用gather处理错误。
请求过程当中肯定会遇到报错(网络不会一直稳定),所以asyncio.gather提供了2个处理错误的参数:
return_exceptions声明我们是否希望处理运行过程中awaitables。
- 当
return_exceptions=False时,gather方法会将错误扔回,只要我们能够处理那么不会影响其他协程的运行 - 当
return_exceptions=True时,不会将错误仍会,而是直接将错误码附在结果中
来看代码示例,在请求列表中我们加入一个无效url
@async_timed() async def main(): async with aiohttp.ClientSession() as session: urls = ['https://example.com', 'python://example.com'] tasks = [fetch_status_code(session, url) for url in urls] status_codes = await asyncio.gather(*tasks) print(status_codes) >>> starting <function main at 0x107f4a4c0> with args () {} starting <function fetch_status_code at 0x107f4a3a0> starting <function fetch_status_code at 0x107f4a3a0> finished <function fetch_status_code at 0x107f4a3a0> in 0.0004 second(s) finished <function main at 0x107f4a4c0> in 0.0203 second(s) finished <function fetch_status_code at 0x107f4a3a0> in 0.0198 second(s) Traceback (most recent call last): File "gather_exception.py", line 22, in <module> asyncio.run(main()) AssertionError Process finished with exit code 1
以上处理方式有一个潜在的问题在于如果代码中有多个问题。我们永远只能看到第一个,所以我们改成True再看看:
@async_timed() async def main(): async with aiohttp.ClientSession() as session: urls = ['https://example.com', 'python://example.com'] tasks = [fetch_status_code(session, url) for url in urls] results = await asyncio.gather(*tasks, return_exceptions=True) exceptions = [res for res in results if isinstance(res, Exception)] successful_results = [res for res in results if not isinstance(res, Exception)] print(f'All results: {results}') print(f'Finished successfully: {successful_results}') print(f'Threw exceptions: {exceptions}') >>> All results: [200, AssertionError()] Finished successfully: [200] Threw exceptions: [AssertionError()]
基础介绍完毕,来说说gather方法的一些缺陷:
- 对于失败任务的处理不是特别友好
- 在得到所有结果之前整个代码块处于阻塞状态,必须等所有结果都跑完才能继续往下运行。(这种情况在一个请求需要1秒,另一个请求需要20秒的情况就很蛋疼)
所以我们再往下继续看相对更好的处理方式:
gather的兄弟as_completed
gather一定要等所有函数return才能继续往下,而as_completed就不用,他会返回一个futures的迭代器,我们可以通过迭代这个list来check当前任务运行是否完成。来看个代码实例:
import asyncio import aiohttp from aiohttp import ClientSession from util import async_timed from chapter_04 import fetch_status @async_timed() async def main(): async with aiohttp.ClientSession() as session: fetchers = [fetch_status(session, 'https://www.example.com', 1), fetch_status(session, 'https://www.example.com', 1), fetch_status(session, 'https://www.example.com', 10)] for finished_task in asyncio.as_completed(fetchers): print(await finished_task) asyncio.run(main()) >>> starting <function fetch_status at 0x10dbed4c0> starting <function fetch_status at 0x10dbed4c0> starting <function fetch_status at 0x10dbed4c0> finished <function fetch_status at 0x10dbed4c0> in 1.1269 second(s) 200 finished <function fetch_status at 0x10dbed4c0> in 1.1294 second(s) 200 finished <function fetch_status at 0x10dbed4c0> in 10.0345 second(s) 200 finished <function main at 0x10dbed5e0> in 10.0353 second(s)
as_completed也支持timeout设定:
import asyncio import aiohttp from aiohttp import ClientSession from util import async_timed from chapter_04 import fetch_status @async_timed() async def main(): async with aiohttp.ClientSession() as session: fetchers = [fetch_status(session, 'https://example.com', 1), fetch_status(session, 'https://example.com', 10), fetch_status(session, 'https://example.com', 10)] for done_task in asyncio.as_completed(fetchers, timeout=2): try: result = await done_task print(result) except asyncio.TimeoutError: print('We got a timeout error!') for task in asyncio.tasks.all_tasks(): print(task) asyncio.run(main()) >>> starting <function main at 0x109c7c430> with args () {} 200 We got a timeout error! We got a timeout error! finished <function main at 0x109c7c430> in 2.0055 second(s) <Task pending name='Task-2' coro=<fetch_status_code()>> <Task pending name='Task-1' coro=<main>> <Task pending name='Task-4' coro=<fetch_status_code()>>
wait ,比gather和as_completed更精细化的工具:
除了刚刚提到的gather和as_completed,wait能够提供更精细化的管控。
- 支持我们能够根据我们的需求(比如什么时候希望函数运行完成)提供结果。
- 函数结果非常友好的会返回2个set,一个已完成的任务,一个未完成的任务。
默认条件下 wait的表现形式与gather十分类似,在所有任务完成前不返回结果:
import asyncio import aiohttp from aiohttp import ClientSession from util import async_timed from chapter_04 import fetch_status @async_timed() async def main(): async with aiohttp.ClientSession() as session: fetchers = [fetch_status(session, 'https://example.com'), fetch_status(session, 'https://example.com')] done, pending = await asyncio.wait(fetchers) print(f'Done task count: {len(done)}') print(f'Pending task count: {len(pending)}') for done_task in done: result = await done_task print(result) asyncio.run(main()) >>> starting <function main at 0x10124b160> with args () {} Done task count: 2 Pending task count: 0 200 200 finished <function main at 0x10124b160> in 0.4642 second(s)
在处理错误时wait和gather的表现略有不同,所以我们需要通过相对更蛋疼的方式去处理,直接看代码把懒得打字了:
import asyncio import logging @async_timed() async def main(): async with aiohttp.ClientSession() as session: good_request = fetch_status(session, 'https://www.example.com') bad_request = fetch_status(session, 'python://bad') fetchers = [asyncio.create_task(good_request), asyncio.create_task(bad_request)] done, pending = await asyncio.wait(fetchers) print(f'Done task count: {len(done)}') print(f'Pending task count: {len(pending)}') for done_task in done: # result = await done_task will throw an exception if done_task.exception() is None: print(done_task.result()) else: logging.error("Request got an exception", exc_info=done_task.exception()) asyncio.run(main()) >>> starting <function main at 0x10401f1f0> with args () {} Done task count: 2 Pending task count: 0 200 finished <function main at 0x10401f1f0> in 0.12386679649353027 second(s) ERROR:root:Request got an exception Traceback (most recent call last): AssertionError
Using done_task.exception() will let us check to see if we have an exception. If we don’t have one, then we can proceed to get the result from done_task with theresultmethod. It would also be safe to donresult = await done_task here, though might throw an exception which may not be what we want. If exception is not None then we know that the awaitable had an exception and we can handle that as we like. Here we just print out the exception’s stack trace. Running this will yield output similar to the following, we’ve removed the verbose traceback for brevity:
我们可以通过wait的参数return_when=asyncio.FIRST_EXCEPTION 来获得更灵活的错误处理方式。在这个场景下如果没有错误,那么他的行为和刚刚基本一致。如果有错误,那么回返回done、pending2个类型的任务List .在done list中最起码有一个是刚刚出现错误的task。来看代码:
import aiohttp import asyncio import logging from chapter_04 import fetch_status from util import async_timed @async_timed() async def main(): async with aiohttp.ClientSession() as session: fetchers = [asyncio.create_task(fetch_status(session, 'python://bad.com')), asyncio.create_task(fetch_status(session, 'https://www.example.com', delay=3)), asyncio.create_task(fetch_status(session, 'https://www.example.com', delay=3))] done, pending = await asyncio.wait(fetchers, return_when=asyncio.FIRST_EXCEPTION) print(f'Done task count: {len(done)}') print(f'Pending task count: {len(pending)}') for done_task in done: if done_task.exception() is None: print(done_task.result()) else: logging.error("Request got an exception", exc_info=done_task.exception()) for pending_task in pending: pending_task.cancel() asyncio.run(main()) >>> starting <function main at 0x105cfd280> with args () {} Done task count: 1 Pending task count: 2 finished <function main at 0x105cfd280> in 0.0044 second(s) ERROR:root:Request got an exception
最后,如果我们希望能够第一时间获取结果来进行处理,我们可以使用return_when=asyncio.FIRST_COMPLETD来进行处理,来看代码:
import asyncio import aiohttp from chapter_04 import fetch_status from util import async_timed @async_timed() async def main(): async with aiohttp.ClientSession() as session: url = 'https://www.example.com' pending = [asyncio.create_task(fetch_status(session, url)), asyncio.create_task(fetch_status(session, url)), asyncio.create_task(fetch_status(session, url))] while pending: done, pending = await asyncio.wait(pending, return_when=asyncio.FIRST_COMPLETED) print(f'Done task count: {len(done)}') print(f'Pending task count: {len(pending)}') for done_task in done: print(await done_task) asyncio.run(main())
这里巧妙的地方就在于使用轮询的方式持续对跑完的结果进行处理:
starting <function main at 0x10d1671f0> with args () {}
Done task count: 1
Pending task count: 2
200
Done task count: 1
Pending task count: 1
200
Done task count: 1
Pending task count: 0
200
finished <function main at 0x10d1671f0> in 0.1153 second(s)