过载保护
令牌桶算法
存放固定容量令牌的桶,按照固定速率往桶里添加令牌
https://pkg.go.dev/golang.org/x/time/rate
漏桶算法
作为计量工具(The Leaky Bucket Algorithm as a Meter)时,可以用于流量整形(Traffic Shaping)和流量控制(TrafficPolicing)
https://pkg.go.dev/go.uber.org/ratelimit
令牌桶和漏桶有什么区别和本质原理
令牌桶可以接受突增流量进行处理,漏桶是固定速率进行请求,对于突增流量会被丢弃。
本质原理:
漏斗桶/令牌桶确实能够保护系统不被拖垮, 但不管漏斗桶还是令牌桶, 其防护思路都是设定一个指标, 当超过该指标后就阻止或减少流量的继续进入,当系统负载降低到某一水平后则恢复流量的进入。但其通常都是被动的,其实际效果取决于限流阈值设置是否合理,但往往设置合理不是一件容易的事情
令牌桶和漏桶算法的缺点:太被动, 不能快速适应流量变化
集群增加机器或者减少机器限流阈值是否要重新设置?
设置限流阈值的依据是什么?
人力运维成本是否过高?
当调用方反馈429时, 这个时候重新设置限流, 其实流量高峰已经过了重新评估限流是否有意义?
自适应限流:根据系统当前的负载自动丢弃流量
计算系统临近过载时的峰值吞吐作为限流的阈值来进行流量控制,达到系统保护
服务器临近过载时,主动抛弃一定量的负载,目标是自保。
计算系统最大吞吐
利特尔法则
最大可以接受请求数量 = latency(处理时间) * 最大成功数量
CPU: 使用一个独立的线程采样,每隔 250ms 触发一次。在计算均值时,使用了简单滑动平均去除峰值的影响。
指数加权移动平均法(EWMA)
https://www.cnblogs.com/jiangxinyang/p/9705198.html
Inflight: 当前服务中正在进行的请求的数量。
Pass&RT: 最近5s,pass 为每100ms采样窗口内成功请求的数量,rt 为单个采样窗口中平均响应时间
使用 CPU 的滑动均值(CPU > 800)作为启发阈值,一旦触发进入到过载保护阶段,算法为:(pass* rt) < inflight
限流效果生效后,CPU 会在临界值(800)附近抖动,如果不使用冷却时间,那么一个短时间的 CPU 下降就可能导致大量请求被放行,严重时会打满 CPU。
在冷却时间后,重新判断阈值(CPU > 800 ),是否持续进入过载保护。
具体代码:
https://github.com/go-kratos/kratos/blob/v1.0.x/pkg/ratelimit/bbr/bbr.go
func (l *BBR) shouldDrop() bool {
if l.cpu() < l.conf.CPUThreshold {
prevDrop, _ := l.prevDrop.Load().(time.Duration)
if prevDrop == 0 {
return false
}
if time.Since(initTime)-prevDrop <= time.Second {
inFlight := atomic.LoadInt64(&l.inFlight)
return inFlight > 1 && inFlight > l.maxFlight()
}
l.prevDrop.Store(time.Duration(0))
return false
}
inFlight := atomic.LoadInt64(&l.inFlight)
drop := inFlight > 1 && inFlight > l.maxFlight()
if drop {
prevDrop, _ := l.prevDrop.Load().(time.Duration)
if prevDrop != 0 {
return drop
}
l.prevDrop.Store(time.Since(initTime))
}
return drop
}
func (l *BBR) maxFlight() int64 {
return int64(math.Floor(float64(l.maxPASS()*l.minRT()*l.winBucketPerSec)/1000.0 + 0.5))
}
这里除以 1000 也是让我想了一会的
一个窗口是100ms,使用 最大窗口通过的 (请求数量 * 窗口最小耗时 * 窗口数量) 这等于 1s内 10个窗口的最大请求数量
请求数量 * 窗口最小耗时 = 一个窗口最大可以接受的请求数量
然后 * 窗口数量 / 1000 等于一个窗口内最大的 吞吐数量
限流
限流是指在一段时间内,定义某个客户或应用可以接收或处理多少个请求的技术。
通过限流,你可以过滤掉产生流量峰值的客户和微服务,或者可以确保你的应用程序在自动扩展(Auto Scaling)失效前都不会出现过载的情况
令牌桶、漏桶 针对单个节点,无法分布式限流
为什么需要分布式限流?
保护下游服务和自身不会被突增的流量打死,比如服务日常可以处理1w流量,增加到2w出发自保护,但是一下子到10w的话,下游服务db和rpc服务承担不住,直接挂了。
每次心跳后,异步批量获取 quota,可以大大减少请求 redis 的频次,获取完以后本地消费,基于令牌桶拦截
如何基于单个节点按需申请,并且避免出现不公平的现象?
初次使用默认值,一旦有过去历史窗口的数据,可以基于历史窗口数据进行 quota 请求
最大最小公平分享”(Max-Min Fairness)。
直观上,公平分享分配给每个用户想要的可以满足的最小需求,然后将没有使用的资源均匀的分配给需要‘大资源’的用户
熔断
断路器(Circuit Breakers)
服务依赖的资源出现大量错误
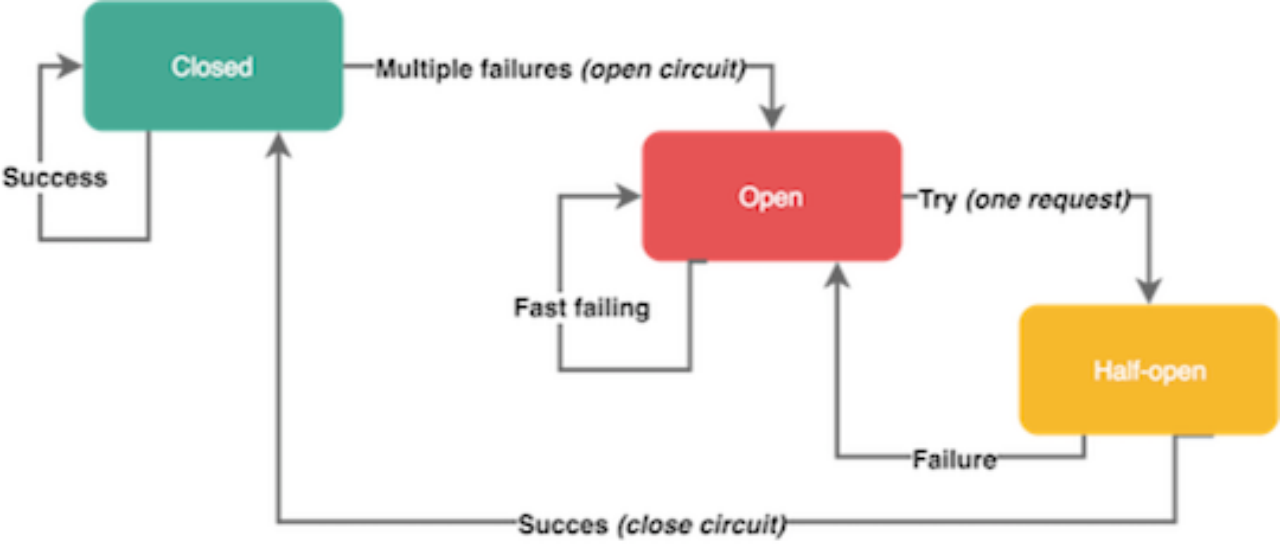
触发熔断以后很快很多请求都会失败,对用户影响比较大, 所以是想让部分失败,丢弃部分请求,不要一下子打死
Google SRE
max(0, (requests - K*accepts) / (requests + 1))
代码位置:
https://github.com/go-kratos/kratos/blob/v1.0.x/pkg/net/netutil/breaker/sre_breaker.go
func (b *sreBreaker) Allow() error {
success, total := b.summary()
k := b.k * float64(success)
if log.V(5) {
log.Info("breaker: request: %d, succee: %d, fail: %d", total, success, total-success)
}
// check overflow requests = K * success
if total < b.request || float64(total) < k {
if atomic.LoadInt32(&b.state) == StateOpen {
atomic.CompareAndSwapInt32(&b.state, StateOpen, StateClosed)
}
return nil
}
if atomic.LoadInt32(&b.state) == StateClosed {
atomic.CompareAndSwapInt32(&b.state, StateClosed, StateOpen)
}
dr := math.Max(0, (float64(total)-k)/float64(total+1))
drop := b.trueOnProba(dr)
if log.V(5) {
log.Info("breaker: drop ratio: %f, drop: %t", dr, drop)
}
if drop {
return ecode.ServiceUnavailable
}
return nil
}
限流 - 客户端流控 退让
https://github.com/go-kratos/kratos/blob/v1.0.x/pkg/net/netutil/backoff.go
限流-gutter
基于熔断的 gutter kafka ,用于接管自动修复系统运行过程中的负载,这样只需要付出10%的资源就能解决部分系统可用性问题。
经常使用 failover 的思路,但是完整的 failover 需要翻倍的机器资源,平常不接受流量时,资源浪费。高负载情况下接管流量又不一定完整能接住。所以这里核心利用熔断的思路,是把抛弃的流量转移到 gutter 集群,如果 gutter 也接受不住的流量,重新回抛到主集群,最大力度来接受。
总结
分布式限流
自适用保护自己
客户端的熔断
立体式的防御增加可用性