一、实战背景
- 如今的营销已经远远不同于过去了,那个一张传单一则广告的时代结束了,这是个大数据的时代。
- 一个时代有一个时代的生存法则,那些没有适应时代的企业,即使曾经是个庞然大物,今天也几乎不见踪影。
- 在航空公司这个特殊的领域,国内竞争还是很严峻的,一个顾客的流失造成的损失是4-5个新顾客的流入所不能弥补的,分析用户(特别是会员用户)相关信息,建立模型,发现流失用户特征,制定针对性营销策略,挽留用户是企业生存的重要一环。
- 本项目基于大数据样本进行挖掘建模,根据用户特征建立模型发现用户流失特征及其原因分析。
二、分析
- 其实,作为航空公司,客户流失是不可避免的,因为有些用户乘机频率非常低,这部分用户是偶然用户,他们的流失没有太大的挽留价值。
- 再者,那些会员用户才是研究的重点,愿意入会的,一定是有频繁乘机体验的,这部分人要么是商务精英要么是比较富裕的人,这几类人都是颇具头脑的。但是,即使这样还是流失了,那就是航空公司给出的服务问题了,这类人是重点研究对象。
三、处理过程
当前,有一个比较尴尬的问题,什么样的顾客可以定义为流失呢?样本数据中根本没有这一项。我们不妨这样定义:
| 客户类型 | 定义方式 |
| 已流失客户 | 第二年飞行次数与第一年飞行次数比例小于50% |
| 准流失客户 | 第二年飞行次数与第一年飞行次数比例在[50%,90%)内 |
| 未流失客户 | 第二年飞行次数与第一年飞行次数比例大于90% |
- 通过上面的定义,解决了这个问题,以一种相对合理的方式定义了用户类型。
- 当然,实际处理时还需要选取客户的关键属性建立模型,如会员卡级别、客户类型(如上定义)、平均乘机时间间隔、平均折扣率、积分兑换次数、非乘机积分总和、单位里程票价和单位里程积分等。
- 任然采用数据挖掘领域常用的82开进行训练测试样本分布。
四、数据获取
- 数据给出(特征过多)
五、数据探索
- 首先声明,表头均没有使用中文,均为航空公司报表专业术语,观测窗口使用两年(06年4月到08年3月),请了解后再阅读本博客,这里不做赘述了。
- 经过初步的数据探索,我得到了一个分析表,记录数目,各列的平均值、四分位数、标准差、极值等;
- 为数据预处理定下了基本的基调,首先,有几列数据几乎所有记录都为0,这是没有意义的。(在数据挖掘领域中没有对比的数据是没有任何意义的,因为所有数据都是为了建模服务的)
import pandas as pd if __name__ == '__main__': data = pd.read_csv('../extra/data.csv') data.drop(['MEMBER_NO'], axis=1, inplace=True) data.describe().to_csv('../extra/data_explored.csv') data.to_excel('../extra/data.xls')
六、数据预处理
- 在数据预处理的第一步就出现了一个不算问题的问题,就是由于Excel解析csv以及编码的一些问题,我看到的表格是错位的,我数据处理第一步就直接数据流导出去成为一个新的xls文件,对于xls文件Excel的解析没有问题,现在,最基本的,我们可视化判断没有了阻碍。(保留最开始的数据是数据分析的基本原则之一)
- 然后,发现第一列用户编号是用户的唯一标识,然而这对于建模是没有意义的,必须剔除第一列。
- 选取合适属性构造了需要的六个属性LRFMCK模型,并进行标准化数据。


""" 进行了数据清洗,属性规约,数据变换等基本预处理操作 """ import pandas as pd def clean(fileName): ''' 数据清洗,去除空记录 :param fileName: :return: ''' cleanedFile = './extra/data_cleaned.csv' data = pd.read_excel(fileName) # 非空保留 data = data[data['SUM_YR_1'].notnull() & data['SUM_YR_2'].notnull()] # 只保留票价非零的,或者平均折扣率与总飞行公里数同时为0的记录。 index1 = data['SUM_YR_1'] != 0 index2 = data['SUM_YR_2'] != 0 index3 = (data['SEG_KM_SUM'] == 0) & (data['avg_discount'] == 0) data = data[index1 | index2 | index3] data.to_csv(cleanedFile) def change(fileName): ''' 取出需要的属性列 :param fileName: :return: ''' changedFile = './extra/data_changed.csv' data = pd.read_csv(fileName, encoding='utf-8') data = data[['LOAD_TIME', 'FFP_DATE', 'LAST_TO_END', 'FLIGHT_COUNT', 'avg_discount', 'SEG_KM_SUM', 'LAST_TO_END', 'P1Y_Flight_Count', 'L1Y_Flight_Count']] data.to_csv(changedFile, encoding='utf-8') def LRFMCK(fileName): ''' 经过计算得到我的指标数据 :param fileName: :return: ''' data = pd.read_csv(fileName) # 其中K为标签标示用户类型 data2 = pd.DataFrame(columns=['L', 'R', 'F', 'M', 'C', 'K']) time_list = [] import datetime for i in range(len(data['LOAD_TIME'])): str1 = data['LOAD_TIME'][i].split('/') str2 = data['FFP_DATE'][i].split('/') temp = datetime.datetime(int(str1[0]), int(str1[1]), int(str1[2])) - datetime.datetime(int(str2[0]), int(str2[1]), int(str2[2])) time_list.append(temp.days) data2['L'] = pd.Series(time_list) data2['R'] = data['LAST_TO_END'] data2['F'] = data['FLIGHT_COUNT'] data2['M'] = data['SEG_KM_SUM'] data2['C'] = data['avg_discount'] temp = data['L1Y_Flight_Count'] / data['P1Y_Flight_Count'] for i in range(len(temp)): if temp[i] >=0.9: # 未流失客户 temp[i] = 'A' elif 0.5 < temp[i] < 0.9: # 已经流失客户 temp[i] = 'B' else: temp[i] = 'C' data2['K'] = temp data2.to_csv('./extra/data_changed2.csv', encoding='utf-8') def standard(): ''' 标准差标准化 :return: ''' data = pd.read_csv('./extra/data_changed2.csv', encoding='utf-8').iloc[:, 1:6] zscoredfile = './extra/data_standard.csv' # 简洁的语句实现了标准化变换,类似地可以实现任何想要的变换 data = (data - data.mean(axis=0)) / (data.std(axis=0)) data.columns = ['Z' + i for i in data.columns] data2 = pd.read_csv('./extra/data_changed2.csv', encoding='utf-8') data['K'] = data2['K'] data.to_csv(zscoredfile, index=False) if __name__ == '__main__': # dataFile = './extra/data.xls' # clean(dataFile) # change('./extra/data_cleaned.csv') # LRFMCK('./extra/data_changed.csv') standard()
七、数据挖掘建模
- 流失用户的分析,并且判断用户会不会流失,这是一个分类问题,我们使用决策树建模。
1、安装库
- 安装以下库:

-
还需要下载:pydotplus
-
背景说明:
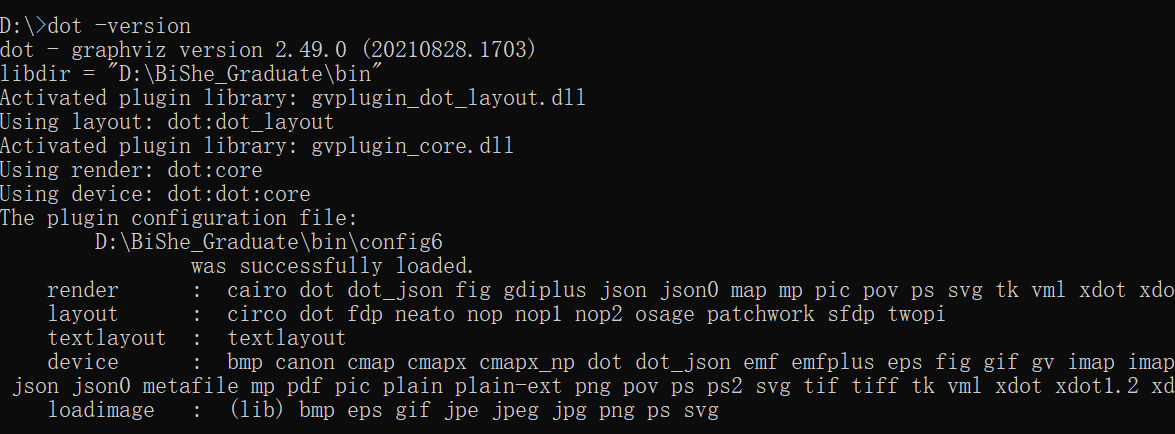
通过pip安装了GraphViz模块后,在对着sklearn的决策树文档操作输出决策树模型结果时,报错了:InvocationException: GraphViz’s executables not found解决流程:
1、下载安装GraphViz(这是一个独立软件)
https://graphviz.gitlab.io/_pages/Download/Download_windows.html

2、下载完后解压缩后,复制bin文件夹的路径。将GraphViz安装目录的bin目录放到环境变量的path路径中
windows下:
运行下边这个语句
import os os.environ["PATH"] += os.pathsep + 'D:/BiShe_Graduate/bin' #注意修改你的路径
3、验证是否安装并配置成功。
win+R输入cmd进入windows命令行界面,输入dot -version,如果显示graphviz的相关版本信息,则安装配置成功
2、开始建模
step1:写重要的功能函数,便于主函数调用(复用)
import pandas as pd from sklearn import tree from sklearn.model_selection import train_test_split import pydotplus # from sklearn.externals.six import StringIO from six import StringIO def getDataSet(fileName): # 读取数据 data = pd.read_csv(fileName) dataSet = [] for item in data.values: dataSet.append(list(item[:5])) label = list(data['K']) return dataSet, label def divide(dataSet, labels): ''' 分类数据,按比例拆开 :param dataSet: :param labels: :return: ''' train_data, test_data, train_label, test_label = train_test_split(dataSet, labels, test_size=0.2) return train_data, test_data, train_label, test_label
step2:导入画图工具GraphViz
import os os.environ["PATH"] += os.pathsep + 'D:/BiShe_Graduate/bin' #注意修改你的路径
step3:主函数
观察data_standard.csv

- 原数据表的第一列用户编号是用户的唯一标识,然而这对于建模是没有意义的,第一列被剔除。
- 再选取合适属性构造了需要的六个属性LRFMCK模型,并进行标准化数据,得到data_standard.csv。
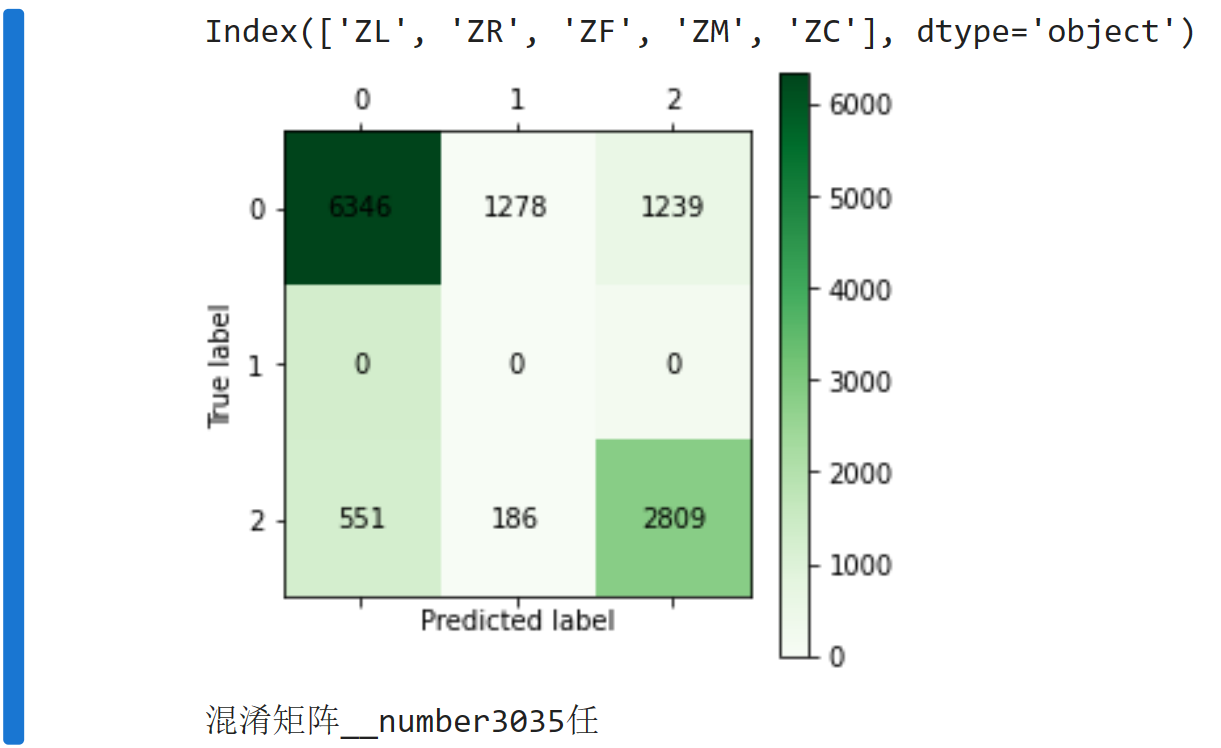
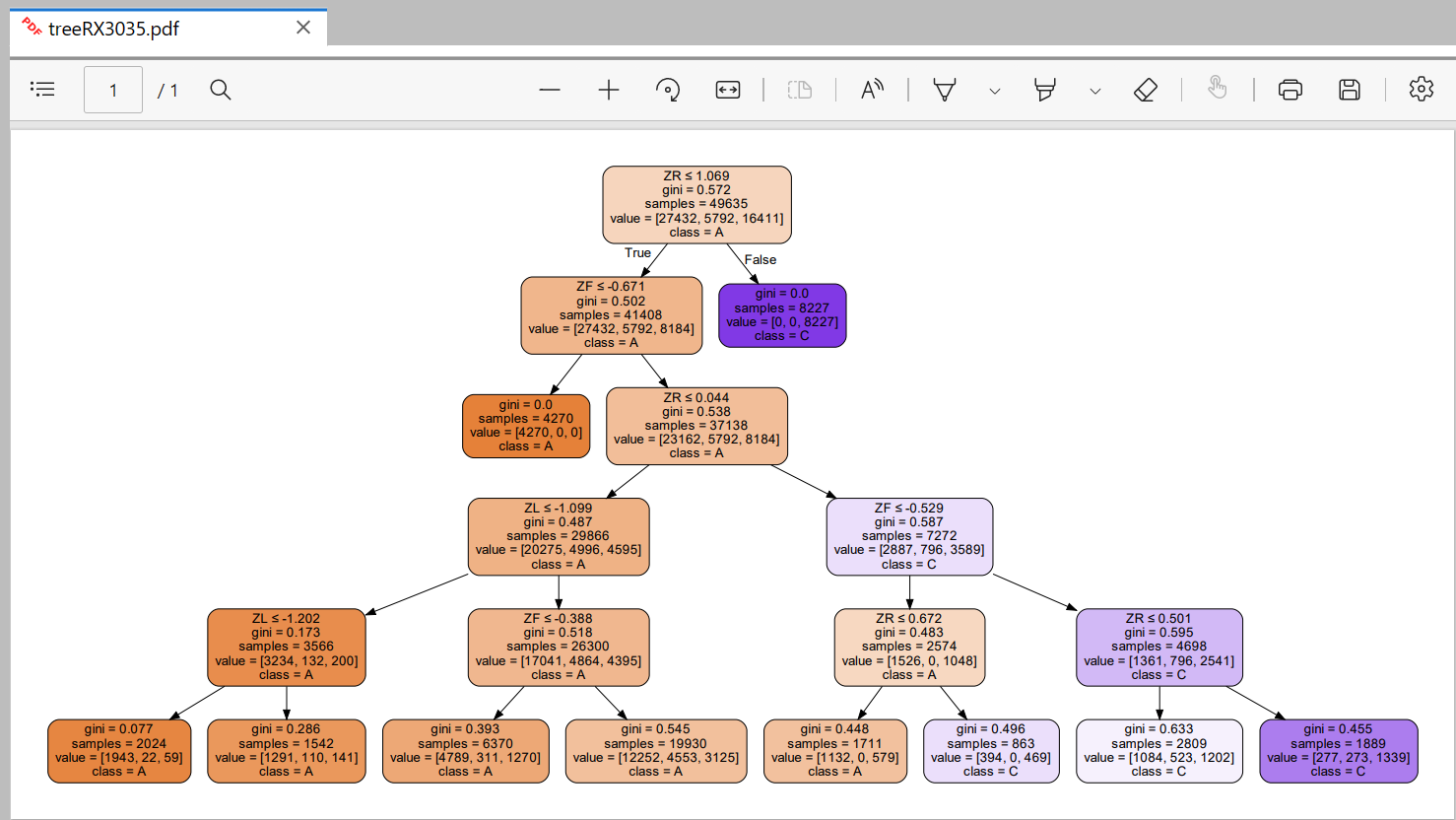
if __name__ == '__main__': data, label = getDataSet('../extra/data_standard.csv') train_data, test_data, train_label, test_label = divide(data, label) clf = tree.DecisionTreeClassifier(max_depth=5) clf = clf.fit(train_data, train_label) # 可视化 dataLabels = ['ZL', 'ZR', 'ZF', 'ZM', 'ZC', ] data_list = [] data_dict = {} for each_label in dataLabels: for each in data: data_list.append(each[dataLabels.index(each_label)]) data_dict[each_label] = data_list data_list = [] lenses_pd = pd.DataFrame(data_dict) print(lenses_pd.keys()) dot_data = StringIO() tree.export_graphviz(clf, out_file=dot_data, feature_names=lenses_pd.keys(), class_names=clf.classes_, filled=True, rounded=True, special_characters=True) graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) graph.write_pdf("treeRX3035.pdf") from cm_plot import * cm_plot(test_label, clf.predict(test_data)).show() print("混淆矩阵__number3035任")
并生成![]()
八、后续处理
- 通过分类预测现有用户是否流失倾向是无比重要的,发现流失可能性进行相应营销比较必要,这里决策树预测准确率还算可以,在深度合适(发现4-5)预测准确率达到85%左右,对于营销需求是达到了。
九、补充说明
- 参考书《Python数据分析与挖掘》
- 本案例使用决策树建模